
初學機器學習
初學機器學習
概念
從大量資料中進行學習的演算法,目的不是找到一個通用的學習演算法或者絕對好的學習演算法,而是關注資料的分佈與通過機器學習獲取的經驗是否能更好的與“真實世界”相關
分類
1、無監督學習
根據提供的含有很多特徵的資料集,進行分類、計算等學習,得到對這些資料集的有用的結構性質
2、監督學習
與無監督學習相比,在提供的資料集中多了標籤或者目標等人為的一些提示
學習過程的挑戰
容量指模型擬合各種函式的能力
1、過擬合(overfitting)
容量高就出現過擬合
2、欠擬合(underfitting)
容量低就出現欠擬合
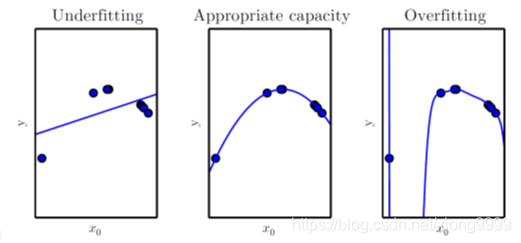
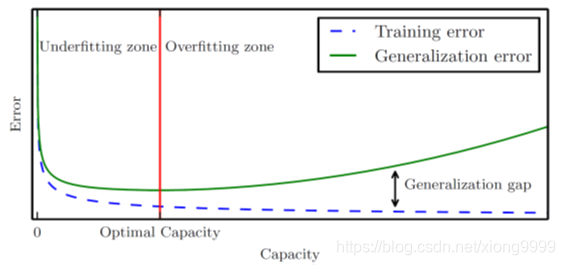
需要找到最佳的容量
相關推薦
初學機器學習
初學機器學習 概念 分類 1、無監督學習 2、監督學習 學習過程的挑戰 1、過擬合(overfitting) 2、欠擬合(underfitti
研究生初學機器學習的幾點建議
通過我自己的這大半年的接觸和了解,結合找工作需要現對於如何入門機器學習提幾點自己的看法。如果你以後要想幹演算法工程師、機器學習工程師,資料探勘工程師。那麼請你好好看一下我下面說的話。 =============================================
【機器學習_5】Anaconda:初學Python、入門機器學習的首選
Anaconda是一個用於科學計算的Python發行版,提供了包管理與環境管理的功能,可以很方便地解決多版本python並存、切換以及各種第三方包安裝問題。 整合包功能: NumPy:提供了矩陣運算的功能,其一般與Scipy、matplotlib一起使用,Python建立的所有更高層工具的基礎,不提供高階資
機器學習之文字挖掘(初學1)
一. 這裡是基於對網頁進行文字提取 #coding:utf-8 from lxml import etree,html import chardet #HTML檔案路徑,以及讀取檔案 path = 'C:/Users/zs/Desktop/learning.html'
機器學習第三練:為慈善機構尋找捐助者
alt earch .get 變量 照相 標簽 log 比較 random 這個任務同樣是在Jupyter Notebook中完成, 項目目的是通過前面的所有特征列,當然去掉序號列,然後預測最後一列,收入‘income‘,究竟是大於50K,還是小於等於50K. 第一
機器學習筆記(Washington University)- Regression Specialization-week five
ril ... des stl it is idg evaluate date lec 1. Feature selection Sometimes, we need to decrease the number of features Efficiency: With f
【機器學習算法-python實現】PCA 主成分分析、降維
pre gre text iss 主成分分析 int 找到 nts 導入 1.背景 PCA(Principal Component Analysis),PAC的作用主要是減少數據集的維度,然後挑選出基本的特征。 PCA的主要思想是移動坐標軸,找
機器學習筆記(Washington University)- Regression Specialization-week six
lar fec space cti different only similar ant var 1. Fit locally If the true model changes much, we want to fit our function locally to di
機器學習-KMeans聚類 K值以及初始類簇中心點的選取
src 常用 趨勢 試圖 重復執行 很大的 一個點 3.4 選擇 【轉】http://www.cnblogs.com/kemaswill/archive/2013/01/26/2877434.html 本文主要基於Anand Rajaraman和Jeffrey David
機器學習公開課筆記第九周之大數據梯度下降算法
機器學習 nbsp gradient min 三種 依次 再看 獲得 mini 一,隨機梯度下降法(Stochastic Gradient Descent) 當訓練集很大且使用普通梯度下降法(Batch Gradient Descent)時,因為每一次\(\theta\)
機器學習筆記(四)機器學習可行性分析
資料 表示 image 隨機 訓練樣本 -s mage 例如 lin 從大量數據中抽取出一些樣本,例如,從大量彈珠中隨機抽取出一些樣本,總的樣本中橘色彈珠的比例為,抽取出的樣本中橘色彈珠的比例為,這兩個比例的值相差很大的幾率很小,數學公式表示為: 用抽取到的樣本作為訓練
機器學習筆記(六)邏輯回歸
邏輯回歸 alt 表示 結果 不變 改變 最小值 nbsp 可能性 一、邏輯回歸問題 二分類的問題為是否的問題,由算出的分數值,經過sign函數輸出的是(+1,-1),想要輸出的結果為一個幾率值,則需要改變函數模型 ,其中,, 則邏輯回歸的函數為 二、邏輯回歸錯誤評價 線性
Ng第十一課:機器學習系統的設計(Machine Learning System Design)
未能 計算公式 pos 構建 我們 行動 mic 哪些 指標 11.1 首先要做什麽 11.2 誤差分析 11.3 類偏斜的誤差度量 11.4 查全率和查準率之間的權衡 11.5 機器學習的數據 11.1 首先要做什麽 在接下來的視頻將談到機器
機器學習筆記(八)非線性變換
nbsp 線性 logs 等於 線性模型 images http 自己 空間 一、非線性問題 對於線性不可分的數據資料,用線性模型分類,Ein會很大,相應的Ein=Eout的情況下,Eout也會很大,導致模型表現不好,此時應用非線性模型進行分類,例如: 分類器模型是一個圓
juedaiyuer MNIST機器學習
examples website reading 計算機 python MNIST是一個入門級的計算機視覺數據集,它包含各種手寫數字圖片:1. MNIST數據集MNIST,是不是聽起來特高端大氣,不知道這個是什麽東西?== 手寫數字分類問題所要用到的(經典)MNIST數據集 ==M
機器學習最佳入門學習資料匯總
行程 view 概率 應該 mic 時有 挖掘 書包 發現 譯者:teyla 原文作者:Jasonb 發布:2014-06-05 13:54:15 挑錯 這篇文章的確很難寫,因為我希望它真正地對初學者有幫助。面前放著一張空白的紙,我坐下來問自己一個難題:面對一個對機器學習
機器學習筆記(Washington University)- Classification Specialization-week 3
read was lowest already start choose class sort pty 1. Quality metric Quality metric for the desicion tree is the classification error er
Ng第十七課:大規模機器學習(Large Scale Machine Learning)
在線 src 化簡 ima 機器學習 learning 大型數據集 machine cnblogs 17.1 大型數據集的學習 17.2 隨機梯度下降法 17.3 微型批量梯度下降 17.4 隨機梯度下降收斂 17.5 在線學習 17.6 映射化簡和數據並行
機器學習的防止過擬合方法
alt int 變化 http 處理 提高 pro 無法 structure 過擬合 ??我們都知道,在進行數據挖掘或者機器學習模型建立的時候,因為在統計學習中,假設數據滿足獨立同分布(i.i.d,independently and identically distribu
Spark機器學習
tin ordering 自身 優點 根據 最好 man ray ron 這篇文章參考《Spark快速大數據分析》,歸納spark技術核心的rdd及MLlib以及其中幾個重要庫的使用。 初始化操作 spark shell: bin/pyspark 每個spark應用都由一