
大檔案拆分方案的java實踐(附原始碼)
目錄
正文
1. 引子
大檔案拆分問題涉及到io處理、併發程式設計、生產者/消費者模式的理解,是一個很好的綜合應用場景,為此,花點時間做一些實踐,對相關的知識做一次梳理和整合,總結一些共性的處理方案和思路,以供後續工作中借鑑。
本文將嘗試由淺入深的方式表述大檔案拆分的問題及不同解決方案,給出的方案不一定是最優解,也並非線上環境論證過的靠譜方式,目的只是在於通過該問題融會貫通io、多執行緒等基礎知識理論。生產環境請慎用。
本文不會逐行講解程式碼實現,而注重在方案設計及思路探討上,但會在文末附上原始碼demo git地址。
2. 問題
假設一個CSV檔案有8GB,裡面有1億條資料,每行資料最長不超過1KB,目前需要將這1億條資料拆分為10MB一個的子CSV檔案,寫入到同目錄下,要求每一個子CSV檔案的資料必須是完整行,所有子檔案不能大於10MB;
確保檔案拆分後文件內容不會丟失;
使用java語言程式設計實現。
3. 單執行緒讀-多執行緒寫的方案
設計思路
1、讀寫並行。原始檔大小為:8G,太大,不能一次性讀入記憶體,很大可能出現oom; 2、單執行緒讀原始檔,多執行緒寫檔案。原因:磁碟讀快於磁碟寫,且多執行緒讀取檔案的複雜度較大,捨棄; 3、使用字元流按行讀取和寫入,以滿足‘資料是完整行’的需求; 4、通過比較讀入原始檔位元組數和實際寫入位元組數是否相等來檢查檔案拆分寫入是否成功。 5、寫操作的多執行緒使用普通的ThreadPoolExcutor 或者 ForkJoinPool。
示意圖

類圖
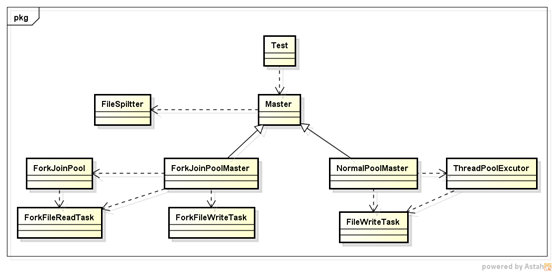
Master——負責協調讀寫任務,可以有普通執行緒池和ForkJoinPool的實現方式;
*Task —— 完成具體的讀寫任務,均為Thread實現類;
FileSpiltter —— 檔案分割器,完成檔案分割計算;
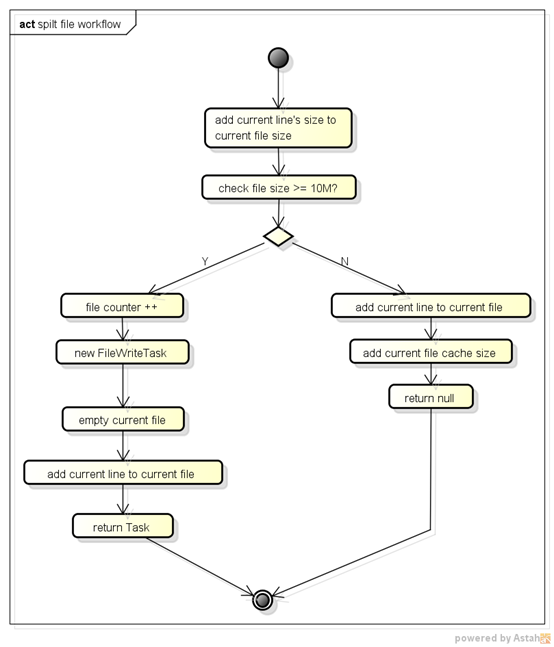
檔案拆分的核心流程圖
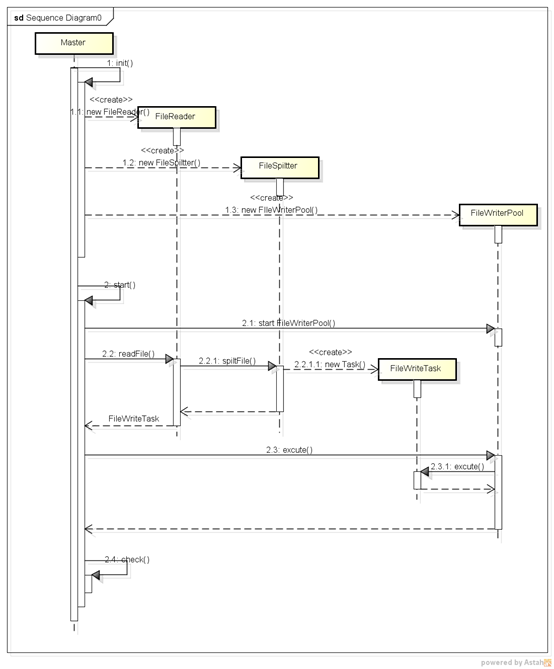
時序圖
優劣勢分析
優勢
1、單執行緒讀,程式時間和檔案拆分邏輯控制簡單;
2、確保檔案拆分過程中,檔案內容寫入的有序性;FileSpiltter在積聚滿一個子檔案內容後,一次性寫入磁碟。
3、鑑於2的有序寫入,子檔案大小分佈均勻。
劣勢
1、單執行緒讀,效率不高,且在使用高效率寫方式時,可能成為瓶頸;
2、記憶體增長不可控,易出現OMM。對於執行中的寫檔案任務不可控,記憶體使用不可控。詳細分析如下:
使用普通ThreadPool時,任務佇列實際上使用的是ThreadPool的queue,這裡選擇的有界的BlockingQueue,那麼當任務數超負載了,執行緒池的拒絕策略有:異常停止、丟棄任務、使用呼叫者執行緒執行,前兩種策略不能滿足功能上的需求,後一種策略解決不了記憶體不可控的問題。考慮嘗試執行緒池使用SychronizedQueue或者無界BlockingQueue,依然無法解決記憶體使用不可控的問題,因為讀檔案側不能得到子檔案寫入任務的反饋,沒法及時調整自己的進度。
使用ForkJoinPool時,同樣存在這個問題,讀檔案側無法感知到寫檔案側的進度,一股腦傻乎乎地寫。
ThreadPoolExcutor vs ForkJoinPool
本方案中使用了兩種執行緒池實現,理論上,ForkJoinPool線上程利用率上會好於普通執行緒池,因為,它會在記憶體協調各個執行緒池的任務,互幫互助,提高處理效率。那麼是否ForkJoinPool的效能會好過普通的ThreadPoolExutor呢?且看下面的測試資料:
|
序號 |
Pool |
Worker Threads |
-Xms |
-Xmx |
Jvm_cpu(%) |
Jvm_mem |
Duration(ms) |
Remark |
|
1 |
ThreadPoolExutor |
4write+1main |
2048m |
2048m |
10 |
500m |
94534 |
|
|
2 |
ForkJoinPool |
4worker |
2048m |
2048m |
10~50 |
500m |
91036 |
|
|
3 |
ForkJoinPool |
5worker |
2048m |
2048m |
10~50 |
500m |
89493 |
1、 ThreadPoolExcutor main執行緒負責讀取原始檔,可以看到block在BufferedReader.readLine()上,FileWrite執行緒block在BufferedWriter.flush()方法上。
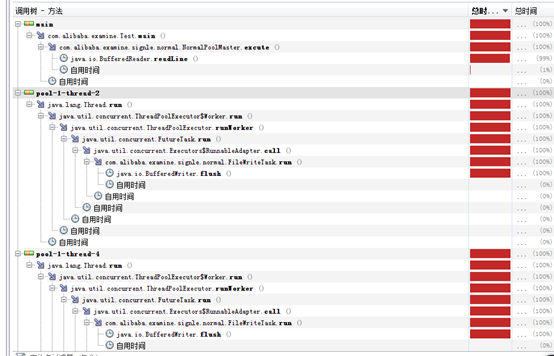
2、 ForkJoinPool,預設4個worker執行緒工作,發現jvm cpu使用率波動很大,10%~50%,且worker執行緒block在BufferedReader.readLine()或者BufferedWriter.flush()上。
仔細觀察發現,FileRead和FileWrite的task都是由ForkJoinPool的4個預設worker完成的,也就是說相對與實驗1,少了一個worker執行緒,實驗1的main作為FileRead的worker執行緒存在。
嘗試將ForkJoinPool的worker執行緒設定為5,以求和實驗1保持相同的worker執行緒數。
3、 ForkJoinPool,5個worker執行緒工作。
負責read的執行緒100%忙,其他4個負責write的worker則大部分時間在等待,所以可以看出瓶頸實際在FileRead上,所以即使增大了worker數量也解決不了問題。

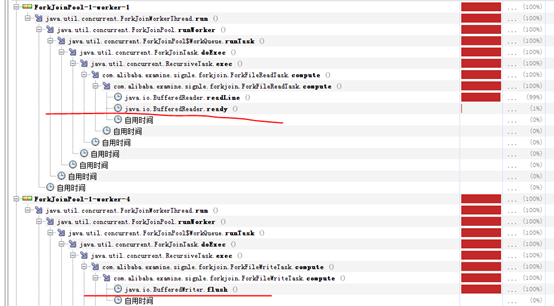
通過實驗發現,兩種方式在效能上並無多大差異。在字元流按行讀寫檔案的場景下,讀寫worker均block在檔案的讀/寫上,不論是使用普通的ThreadPoolExutor或者是ForkJoinPool執行緒池,效能上沒有大的區別。
但是ForkJoinPool執行緒池的分而治之的思想值得學習,在並行排序、平行計算的場景非常適用,比如如果這裡不是檔案拆分,而是讀取大檔案中的1億個數字,找出其中最大的top100,那麼這時候適用ForkJoinPool將會非常合適。
4. 生產者-消費者模式(多執行緒讀/寫)
鑑於上述方案的劣勢,我們提出使用生產者-消費者模式來實現,同時為了提高讀效率,使用多執行緒讀/寫。
設計思路
1、採用生產者-消費者模式,對讀寫任務可控,從而讀記憶體使用可控,防止出現omm;
2、使用多執行緒讀/寫,提高效率;
3、藉助記憶體檔案對映MappedByteBuffer,分段多執行緒讀取檔案;
示意圖

類圖

Master、*Task、FileSpiltter —— 和之前一樣的職責;只是不同的實現方式;
*Pool —— 讀/寫執行緒池,使用ThreadPoolExcutor實現,使用有界佇列、有界執行緒池;
TaskAllocater —— *Task任務初始化,填充*Pool;
Queue —— 生產者/消費者共享Blocking任務佇列,有界,大小可配置;
FileLine —— 包裝一行檔案內容,這裡的一行為csv檔案內容的一行,同時出現\r和\n位元組時任務換行;
時序圖
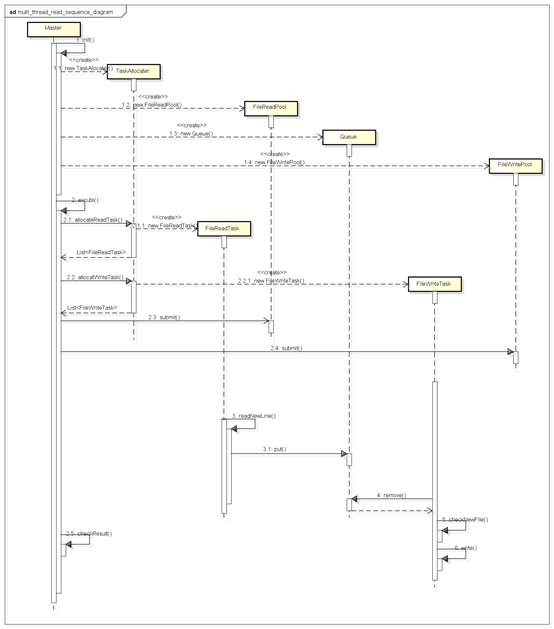
優劣勢
優勢
1、記憶體使用可控,避免OMM問題;
2、讀檔案效率提高,整個檔案拆分時延降低;
劣勢
1、檔案拆分邏輯和任務控制邏輯複雜,程式碼複雜度高;
2、檔案內容的有序性無法保證;FileWriteTask從queue裡獲取FileLine是隨機的,無法保證檔案內容寫入的有序性,這裡的有序性是指相對於原始檔的行位置;
3、檔案拆分後子檔案大小的均勻性無法保證;多執行緒之間互相不知道狀態,因此在最後會出現不確定的小檔案。
效能調優
生產者/消費者方式的實現,使得任務控制和檔案拆分邏輯複雜,最初版本效能比‘單執行緒讀-多執行緒寫’的方案還要查,後來通過調優得到了比較滿意的結果。
總結下來:需要針對幾個關鍵性引數進行調節,以求得到最佳效能,這幾個關鍵性的引數包括:FileReadTaskNum(生產者數量,原始檔讀取任務數量)、FileWriteTaskNum(消費者數量,子檔案寫入任務數量)、queueSize(任務佇列大小)。
下面簡單羅列下在測試機的調優過程:
測試環境
OS: windows 7 64bit
cpu: 4core, 主頻:2.4GHZ
mem:6G
jdk version:Java HotSpot(TM) 64-Bit ,1.8.0_101
調優過程
先直觀給出各個調優實驗的結果資料,主要關注幾個引數:jvm cpu使用率、jvm memory使用、實體記憶體使用(涉及到記憶體檔案對映,這部分記憶體不受jvm管控):
|
序號 |
-Xms |
-Xmx |
readTaskNum |
writeTaskNum |
queueSize |
Durition (ms) |
jvm_ CPU(%) |
jvm_ mem |
Physics _mem |
|
子檔案一次性寫+FileOutputStream |
|||||||||
|
1 |
512m |
512m |
4 |
4 |
1024 |
35752 |
80 |
400m |
4.2G |
|
2 |
512m |
512m |
4 |
4 |
4096 |
37878 |
80 |
400M |
4.2G |
|
3 |
512m |
512m |
8 |
4 |
4096 |
36507 |
80 |
350m |
4.2G |
|
4 |
512m |
512m |
8 |
8 |
4096 |
39566 |
80 |
350m |
4.3G |
|
5 |
512m |
512m |
8 |
12 |
4096 |
55879 |
80->60 |
400M |
4.3G |
|
子檔案按行寫+FileOutputStream |
|||||||||
|
6 |
512m |
512m |
8 |
12 |
4096 |
63245 |
60 |
100m |
4.9G |
|
7 |
512m |
512m |
8 |
12 |
10240 |
62421 |
60 |
100m |
4.7G |
|
9 |
512m |
512m |
8 |
4 |
10240 |
64342 |
60 |
100m |
4.9G |
|
子檔案按行寫+nio |
|||||||||
|
10 |
512m |
512m |
8 |
8 |
10240 |
123322 |
20 |
100m |
4.6G |
|
11 |
512m |
512m |
16 |
8 |
10240 |
17237 |
20 |
100m |
4.5G |
|
12 |
512m |
512m |
24 |
8 |
10240 |
6333 |
80 |
100m |
4.5G |
|
13 |
512m |
512m |
24 |
8 |
20480 |
6656 |
80 |
100m |
4.5G |
|
14 |
512m |
512m |
32 |
8 |
20480 |
7001 |
80 |
100m |
4.5G |
|
15 |
512m |
512m |
32 |
16 |
20490 |
7554 |
80 |
100m |
4.5G |
|
16 |
512m |
512m |
32 |
16 |
40960 |
8824 |
80 |
100m |
4.5G |
|
子檔案一次性寫入+nio |
|||||||||
|
17 |
512m |
512m |
24 |
8 |
10240 |
8158 |
80 |
100m |
4.6G |
表中第一列編號對應於下面描述中的編號,可以結合著看。
1、 read和write均block在queue的操作上
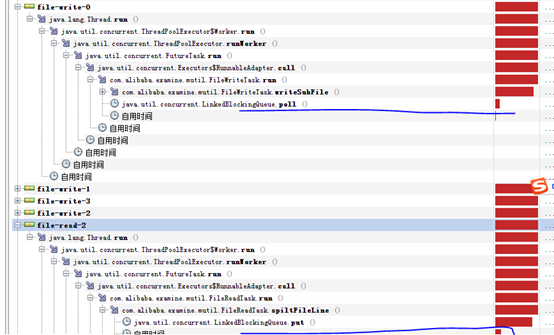
嘗試增大queueSize
2、 read不在block在queue的put上,轉而block在讀入位元組流的過濾上,但是由於read不夠快,故而write仍然block在queue的take上。
效能和負載上沒有大的變化

嘗試增大read的執行緒數
3、 read 執行緒增加一倍後,read速度快於write速度,導致read block在queue的put,writeblock在寫檔案上。
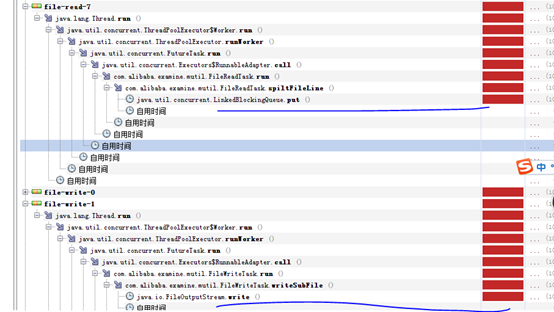
嘗試增大write一倍的話,很有可能write等待read的任務產生,再次讓write block在queue的tack上? 接下來驗證下。
4、 增大write執行緒數後,並未出現write等待read的情況,和3一樣,read 在等待write消費任務,block在了queue 的put上,這說明write檔案到磁碟成為了瓶頸。
在IO寫成為瓶頸的情況下,增大write的執行緒數,反而雪上加霜,使得時延增加。
為了驗證這個結論,我們繼續加大write的執行緒數,看看時延的變化情況。
5、 在IO寫成為瓶頸的情況下,增大write的執行緒數,反而雪上加霜,使得時延增加。多個write不斷地爭搶io資源,Cpu利用率降低。
Review程式碼發現,現在的write是在收集滿一個子檔案後才一次性向外面寫,多個執行緒可能同一時刻都要去申請io寫,這時候等待時間會很長,嘗試將一次性寫整個子檔案,更改為每次寫一行。
6、 將寫檔案動作分散化後,時延沒有什麼好轉,但是帶來了如下好處:
A、 效能表現穩定,多次試驗時延、cpu負載均表現平穩,沒有大起大落。之前等湊齊一個檔案再寫時,很容易產生io阻塞,多個執行緒阻塞在io上,導致效能表現不穩定。
B、 Jvm記憶體使用降低。讀一行寫一行,使得記憶體中快取的檔案內容降低。
也帶了一個不好的變化:實體記憶體使用增加。懷疑和時延增大,read使用MappedByteBuffer讀取檔案時,直接使用了實體記憶體作為快取,時延增大,導致快取駐留時間更長。
接下來嘗試調大queueSize,以便能緩解實體記憶體的佔用。
7、 調大queueSize未能解決問題,瓶頸仍然在write檔案上。根本問題不解決,處理效率上不來,導致read進實體記憶體的快取內容長期佔用,實體記憶體居高。
8、 反向思維,將write執行緒調低呢?也沒有好轉。
接下來還是著手從根本上解決write效能地下的問題。
通過實驗發現,對於10M左右的檔案,使用FileChannel的nio模式效率最高。詳細見:java中多種寫檔案方式的效率對比實驗
9、 使用FileChannel+MappedByteBuffer寫入檔案後,時延沒有提升,但是可以看到write的效率大大高於了read。
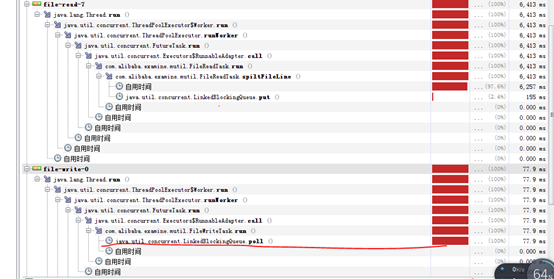
接下來,增加read的執行緒數。
10-16、 調整readtaskNum、writeTaskNum、queueSize發現在readtaskNum=24, writeTaskNum=8, queueSize=10240時時延最低,且cpu使用率已經接近100%,為最優點。
‘子檔案按行寫+NIO’存在一個功能性的問題:由於預先分配好了ByteBuffer的大小,當檔案內容不足時,會存在很多空NUL的位元組,使得檔案內容失真。

17、將逐行寫入更改為子檔案一次性寫入,可以解決上面的功能性問題,且時延並未增加太多。
調優結果
最後選擇了第17步得到的方案:子檔案一次性寫入+nio處理,readtaskNum=24, writeTaskNum=8, queueSize=10240。
5. 如何更完美?
針對‘生產者-消費者模式’的方案,存在如下兩個功能性相關的不足,我們如何設計能讓這個方案更加完美呢? 我們可以嘗試去想一下:
檔案內容寫入的有序性保證
這裡的有序性是指拆分後的行的前後行和原始檔中的一致,如果是跨子檔案,那麼子檔案編號小的在前,編號大的行在後。由於FileWriteTask從queue裡獲取FileLine是隨機的,無法保證檔案內容寫入的有序性,因此,這裡可以考慮對FileLine增加一個lineSeq的屬性,這個屬性由FileReadTask賦值,形如:taskSeq+lineSeqInSubFile,taskSeq為FileReadTask的任務編號,lineSeqInSubFile為特定子檔案內部唯一有序編號;FileWriteTask仍然隨機從queue中讀取FileLine,但是寫入時需要判定FileLine的lineSeq是否為當前需要寫入的seq,如果不是則捨棄。這樣的方案會急劇降低寫入效能,同時可能出現假死現象,queue中不包含任何writeTask需要的正確順序的FileLine,所有writeTask等待下一個正確順序的FileLine出現,queue中的任務無法繼續被消費,進而導致FileWriteTask也被block,整個任務處理假死。
在多執行緒讀寫模式下,我還未找到一個有效的方法來保證檔案內容寫入的有序性,如果要保證檔案內容寫入的有序性,只能使用單執行緒寫 或者 單執行緒讀,捨棄高效能。
拆分後子檔案大小的均勻性保證
當前實現中,FileWriteTask從queue中獲取FileLine,並完成寫入,由於FileLine是無序的,且各個fileWriteTask例項之間不能通訊,因此,可能出現還剩下最後幾個檔案的大小很小,使得檔案大小的均勻性收到破壞。例如,當總共有8個FileWriteTask在工作,在最後時刻,所有8個task都已經完成了上一個檔案的寫入,queue裡還剩下8條FileLine,這時候發現queue還有FileLine任務沒有處理,於是紛紛新建一個子檔案,開始寫入,最後的結果可能是:8個task分別寫入最後一個子檔案,但是每個子檔案中只有一條FileLine,大小和之前的問題件差別很大。
我們希望的是最後的8條FileLine都被寫入了同一個子檔案。
可以想到如下解決辦法:在所有子檔案寫入結束後,再做一次檔案合併,對檔案過小的子檔案合併至一個檔案,這個方法會損害一定的效能,但應當是可以實現功能的,應當還有其他方法,可以思考下。
6. 總結
1、使用‘生產者-消費者’模式可以很好地控制記憶體中存在的任務數,從而有效控制jvm記憶體大小,防止omm出現;
2、使用記憶體檔案對映完成讀/寫檔案,能夠獲得最高的效率;
3、ForkJoinPool適合於平行計算(如並行排序)場景,其分而治之的思想值得學習,但在大檔案拆分場景並無優勢;
4、‘生產者-消費者’模式的效能調優中涉及到:生產者任務數量、消費者任務數量、任務佇列大小的協同調整;
7. TODO
1、拆分後文件寫入的有序性保證問題
2、拆分後子檔案大小的均勻性保證問題
3、記憶體對映檔案佔據記憶體的回收問題
8. Demo
github地址:https://github.com/daoqidelv/filespilt-demo
9. 備註
文中資料對應的測試場景為:將一個1G大小的csv檔案按照10M為單位進行拆分。
測試環境為:OS: windows 7 64bit、cpu: 4core, 主頻:2.4GHZ、mem:6G、jdk version:Java HotSpot(TM) 64-Bit ,1.8.0_101