
推薦系統中的常用評估指標
最近研究推薦系統,是時候整理一下五花八門的評測指標了。
1.recall,pre前文中有介紹。
2.f1-score:

3.AUC,ROC前文有介紹
4.HR:

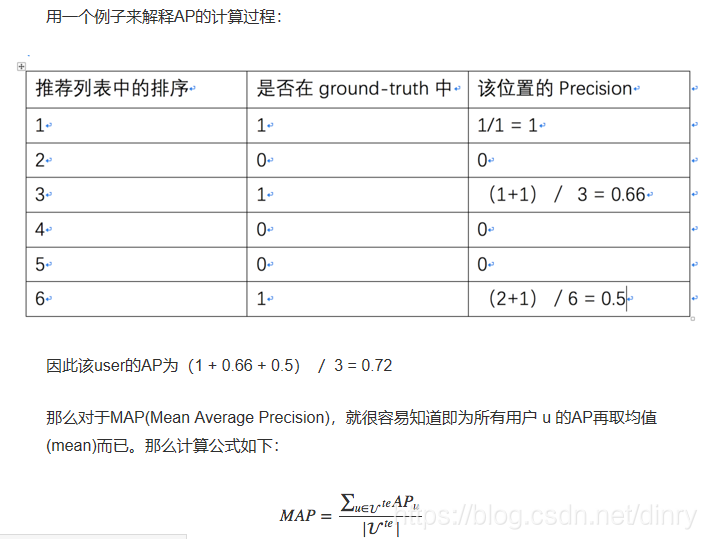
5.map:

6.NDCG:
7.MPR:
8.ILS:
本文實踐了部分上面提到的評價指標,git地址為:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-Evaluation-metrics
相關推薦
機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介
模型 可擴展性 決策樹 balance rman bsp 理解 多個 缺失值 數據挖掘、機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介。 引言: 在機器學習、數據挖掘、推薦系統完成建模之後,需要對模型的
轉:【總結】推薦系統中常用算法 以及優點缺點對比
必須 根據 是把 簡單的 con upload 推薦算法 成功 這一 轉:http://www.sohu.com/a/108145158_464065 在推薦系統簡介中,我們給出了推薦系統的一般框架。很明顯,推薦方法是整個推薦系統中最核心、最關鍵的部分,很大程度上
轉:【總結】推薦系統中常用演算法 以及優點缺點對比
轉:http://www.sohu.com/a/108145158_464065 在推薦系統簡介中,我們給出了推薦系統的一般框架。很明顯,推薦方法是整個推薦系統中最核心、最關鍵的部分,很大程度上決定了推薦系統性能的優劣。目前,主要的推薦方法包括:基於內容推薦、協同過濾
推薦系統_推薦系統的常用評測指標
為了評估推薦演算法的好壞需要各方面的評估指標。 對使用者u推薦N個物品(記為R(u)),令使用者u在測試集上喜歡的物品集合為T(u) 準確率 準確率就是最終的推薦列表中有多少是推薦對了的。描述最終的推薦列表中有多少比例是發生過的使用者-物品評分記錄
推薦系統中的常用評估指標
最近研究推薦系統,是時候整理一下五花八門的評測指標了。 1.recall,pre前文中有介紹。 2.f1-score: 3.AUC,ROC前文有介紹 4.HR: 5.map: 6.NDCG: 7.MPR: 8.ILS: 本文實踐了部分上面提
推薦系統遇上深度學習(十六)--詳解推薦系統中的常用評測指標
最近閱讀論文的過程中,發現推薦系統中的評價指標真的是五花八門,今天我們就來系統的總結一下,這些指標有的適用於二分類問題,有的適用於對推薦列表topk的評價。1、精確率、召回率、F1值我們首先來看一下混淆矩陣,對於二分類問題,真實的樣本標籤有兩類,我們學習器預測的類別有兩類,那麼根據二者的類別組合可以劃分為四組
推薦系統學習之評測指標
又能 根據 ima 商品 .net 一般來說 解釋 image 推薦系統 轉自 http://blog.csdn.net/sinat_33741547/article/details/52704986 最近開始學習推薦系統,特記錄一下學習過程並做個分享。推薦系統是什麽不用多
CentOS系統中常用查看日誌命令
守護 cut 交換分區 spool 情況 狀態 日誌 redhat oot Linux IDE RedHat 防火墻活動 .cat tail -f日 誌 文 件 說 明 /var/log/message 系統啟動後的信息和錯誤日誌,是Red Hat Linux中最常用
SVD(singular value decomposition)應用——推薦系統中
val end lin inf 抽取 比例 過程 說明 from 參考自:http://www.igvita.com/2007/01/15/svd-recommendation-system-in-ruby/ 看到SVD用於推薦評分矩陣的分解,主要是可以根據所需因子
推薦系統中的稀疏矩陣處理
style k-means 協同過濾算法 基礎 尋找 中產 過濾 推薦系統 數據 數據稀疏問題嚴重制約著協同過滿推薦系統的發展。對於大型商務網站來說,由於產品和用戶數量都很龐大,用戶評分產品一般不超過產品總數的1%,兩個用戶共同評分的產品更是少之又少,解決數據稀菊問題是
機器學習-推薦系統中基於深度學習的混合協同過濾模型
近些年,深度學習在語音識別、影象處理、自然語言處理等領域都取得了很大的突破與成就。相對來說,深度學習在推薦系統領域的研究與應用還處於早期階段。 攜程在深度學習與推薦系統結合的領域也進行了相關的研究與應用,並在國際人工智慧頂級會議AAAI 2017上發表了相應的研究成果《A Hy
推薦系統中協同過濾演算法實現分析(重要兩個圖!!)
“協”,指許多人協力合作。 “協同”,就是指協調兩個或者兩個以上的不同資源或者個體,協同一致地完成某一目標的過程。 “協同過濾”,簡單來說,就是利用興趣相投或擁有共同經驗的群體的喜好來給使用者推薦感興趣的資訊,記錄下來個人對於資訊相當程度的迴應(如評分),以達到過濾的目的,進而幫助別人篩
機器學習:奇異值分解SVD簡介及其在推薦系統中的簡單應用
轉載自:https://www.cnblogs.com/lzllovesyl/p/5243370.html 本文先從幾何意義上對奇異值分解SVD進行簡單介紹,然後分析了特徵值分解與奇異值分解的區別與聯絡,最後用python實現將SVD應用於推薦系統。 1.SVD詳解 SVD(singul
達觀資料於敬:深度學習來一波,受限玻爾茲曼機原理及在推薦系統中的應用
深度學習相關技術近年來在工程界可謂是風生水起,在自然語言處理、影象和視訊識別等領域得到極其廣泛的應用,並且在效果上更是碾壓傳統的機器學習。一方面相對傳統的機器學習,深度學習使用更多的資料可以進行更好的擴充套件,並且具有非常優異的自動提取抽象特徵的能力。 另外得益於GPU、SSD儲存、大
機器學習常用評估指標的前世今生
在機器學習中,效能指標(Metrics)是衡量一個模型好壞的關鍵,通過衡量模型輸出y_predict和y_true之間的某種“距離”得出的。 效能指標往往使我們做模型時的最終目標,如準確率,召回率,敏感度等等,但是效能指標常常因為不可微分,無法作為優化的loss函式,因此採用如cross-entrop
奇異值分解SVD簡介及其在推薦系統中的簡單應用
本文先從幾何意義上對奇異值分解SVD進行簡單介紹,然後分析了特徵值分解與奇異值分解的區別與聯絡,最後用python實現將SVD應用於推薦系統。 1.SVD詳解 SVD(singular value decomposition),翻譯成中文就是奇異值分解。SVD的用處有
AutoML在推薦系統中的應用
大家好,歡迎參加GitChat舉辦的線上分享活動。我是第四正規化研究員嘉磊,今天我和同事遠飛及負責推薦業務研究同事曉澄,一起給大家分享AutoML在推薦系統中的應用。 先介紹一下我們公司——第四正規化,第四正規化是國際領先的人工智慧技術與服務提供商,致力於降低人工智慧應用的門檻,基於機器
SVD在推薦系統中的應用詳解以及演算法推導
前面文章SVD原理及推導已經把SVD的過程講的很清楚了,本文介紹如何將SVD應用於推薦系統中的評分預測問題。其實也就是復現Koren在NetFlix大賽中的使用到的SVD演算法以及其擴展出的RSVD、SVD++。 記得剛接觸SVD是在大二,那會兒跟師兄在做專案的時候就
理順主題模型LDA及在推薦系統中的應用
1 關於主題模型 使用LDA做推薦已經有一段時間了,LDA的推導過程反覆看過很多遍,今天有點理順的感覺,就先寫一版。 隱含狄利克雷分佈簡稱LDA(latent dirichlet allocation),是主題模型(topic model)的一種,由Ble
推薦系統中的矩陣分解總結
最近學習矩陣分解,但是學了好多種類,都亂了,看了這篇文章,系統性的總結了矩陣分解,感覺很棒,故分享如下: 前言 推薦系統中最為主流與經典的技術之一是協同過濾技術(Collaborative Filtering),它是基於這樣的假設:使用者如果在過去對某些專案產生過