
深度學習優化器Optimizer總結-tensorflow-1原理篇
單純以演算法為論,深度學習從業者的演算法能力可能並不需要太大,因為很多時候,只需要構建合理的框架,直接使用框架是不需要太理解其中的演算法的。但是我們還是需要知道其中的很多原理,以便增加自身的知識強度,而優化器可能正是深度學習的演算法核心
官方文件所給的優化器很多,而且後續也在不停地添加當中,因此,我這裡只列舉基礎和常用的幾個:
優化器分類:
-
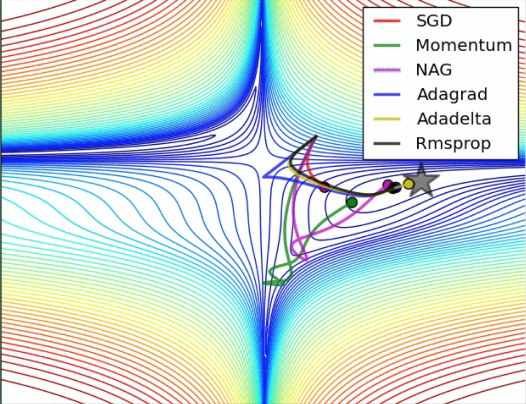
Stochastic Gradient Descent (SGD):隨機梯度,分批,隨機放入一批,而不是全部放入,加快訓練速度,卻不會大大影響效果
-
Optimizer 主類:
- GradientDescentOptimizer :實現梯度下降演算法的優化器。(結合理論可以看到,這個建構函式需要的一個學習率就行了)
- MomentumOptimizer
Momentum單詞即動量、動力,這裡的意思可以理解為慣性,想象一下,如果你現在從山上玩下衝,你的目的是到達最低點,但是如果這個山坡並不是直線梯度下降,而是區域性左拐右拐梯度下降,這樣將導致下降步驟是個折線形,大大降低訓練速度,這也是基本梯度下降演算法的缺點,因此這裡引入了動量因子。
所以你下山有之前的動量,即便你想拐彎都拐不了很大
比如:原來的梯度計算是:variable -= learning_rate * gradient;
現在變為:variable -= learning_rate * (momentum * accumulation + gradient)
這裡的momentum * accumulation是之前的動量積累,所以就導致即便區域性有折線,也會由於之前的動量影響太大,而儘量保持直線下降
原始碼公式:
accumulation = momentum * accumulation + gradient
variable -= learning_rate * accumulation
或者直接是:W += b1 * m -Learning rate * dx - AdagradOptimizer
公式變化如下:
W += -Learning rate * dx
變為:
v += dx^2
W += -Learining rate * dx /sqrt(v)
ada-即單詞Adaptive,中文:自適應
同增加慣性因子的原理類似,此方法也是為了減輕區域性偏折,但是作用在學習率上。即為了防止偏折過大,我們會首先計算偏折幅度-即梯度值,並將其作為學習率分母引數。意思就是,如果梯度很大,學習率就很低,這樣防止偏折過大;梯度很小,學習率就大。 - AdagradDAOptimizer 略
-
RMSPropOptimizer
AdaGrad阻力因子考慮了當前的梯度,並沒有考慮之前的梯度係數,這樣會導致不管是迭代100次的或者是迭代10000次的,阻力都是一樣的,沒有區別。如果是執行到接近最優化處,其實阻力應該更大一些,因為此時只需要微調就行,所以這裡增加了一個全域性梯度累計,這樣,梯度阻力會隨著迭代的次數不斷增大。
可能做到的改進:AdaGrad阻力因子沒有考慮一個特殊情況,即如果下山最大梯度確實有個很大的90度折線,而且這個折線正是全域性梯度方向,但是由於這個阻力因子的存在,可能每次梯度都很大,每次都阻礙,反而降低了下降速度,所以,這裡可以添加了一個佔比係數,即不僅僅考慮當前的梯度值,而且還要考慮之前的梯度值,這樣,當梯度值一直很大時,說明可能是對的道路,阻力相應就減小。
公式:
V = b2* V +(1-b2) * dx^2
W += -Learining rate * dx /sqrt(v) -
AdamOptimizer
Adam聯合了momentum 的慣性原則 , 加上 adagrad 的對錯誤方向的阻力
公式:
M += b1 * m -Learning rate * dx (momentum)
V = b2* V +(1-b2) * dx^2 (AdaGrad)
W += -Learining rate * M /sqrt(V)