
各種優化器Optimizer的總結與比較
1.梯度下降法(Gradient Descent)
梯度下降法是最基本的一類優化器,目前主要分為三種梯度下降法:
標準梯度下降法(GD, Gradient Descent)
隨機梯度下降法(SGD, Stochastic Gradient Descent)
批量梯度下降法(BGD, Batch Gradient Descent)
class tf.train.GradientDescentOptimizer 使用梯度下降演算法的Optimizer
標準梯度下降法(GD)
假設要學習訓練的模型引數為W,代價函式為J(W),則代價函式關於模型引數的偏導數即相關梯度為
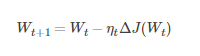
其中,Wt表示tt時刻的模型引數
從表示式來看,模型引數的更新調整,與代價函式關於模型引數的梯度有關,即沿著梯度的方向不斷減小模型引數,從而最小化代價函式
基本策略可以理解為”在有限視距內尋找最快路徑下山“,因此每走一步,參考當前位置最陡的方向(即梯度)進而邁出下一步
評價:標準梯度下降法主要有兩個缺點:
訓練速度慢:
每走一步都要要計算調整下一步的方向,下山的速度變慢
在應用於大型資料集中,每輸入一個樣本都要更新一次引數,且每次迭代都要遍歷所有的樣本
會使得訓練過程及其緩慢,需要花費很長時間才能得到收斂解
容易陷入區域性最優解:
由於是在有限視距內尋找下山的反向
當陷入平坦的窪地,會誤以為到達了山地的最低點,從而不會繼續往下走
所謂的區域性最優解就是鞍點。落入鞍點,梯度為0,使得模型引數不在繼續更新
批量梯度下降法(BGD)
假設批量訓練樣本總數為nn,每次輸入和輸出的樣本分別為X(i),Y(i),模型引數為W,代價函式為J(W)
每輸入一個樣本ii代價函式關於W的梯度為ΔJi(Wt,X(i),Y(i)),學習率為ηt,則使用批量梯度下降法更新引數表示式為
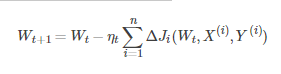
其中,WtWt表示tt時刻的模型引數
從表示式來看,模型引數的調整更新與全部輸入樣本的代價函式的和(即批量/全域性誤差)有關。
即每次權值調整發生在批量樣本輸入之後,而不是每輸入一個樣本就更新一次模型引數。這樣就會大大加快訓練速度。
基本策略可以理解為,在下山之前掌握了附近的地勢情況,選擇總體平均梯度最小的方向下山
評價:
批量梯度下降法比標準梯度下降法訓練時間短,且每次下降的方向都很正確
隨機梯度下降法(SGD)
對比批量梯度下降法,假設從一批訓練樣本n中隨機選取一個樣本is。
模型引數為W,代價函式為J(W),梯度為ΔJ(W),學習率為ηt,則使用隨機梯度下降法更新引數表示式為
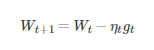
其中,gt=ΔJis(Wt;X(is);X(is)), is∈{1,2,...,n}表示隨機選擇的一個梯度方向,Wt表示t時刻的模型引數
E(gt)=ΔJ(Wt)E(gt)=ΔJ(Wt),這裡雖然引入了隨機性和噪聲,但期望仍然等於正確的梯度下降
基本策略可以理解為隨機梯度下降像是一個盲人下山,不用每走一步計算一次梯度,但是他總能下到山底,只不過過程會顯得扭扭曲曲
評價:
優點:
雖然SGD需要走很多步的樣子,但是對梯度的要求很低(計算梯度快)。而對於引入噪聲,大量的理論和實踐工作證明,只要噪聲不是特別大,SGD都能很好地收斂。
應用大型資料集時,訓練速度很快。比如每次從百萬資料樣本中,取幾百個資料點,算一個SGD梯度,更新一下模型引數。
相比於標準梯度下降法的遍歷全部樣本,每輸入一個樣本更新一次引數,要快得多。
缺點:
SGD在隨機選擇梯度的同時會引入噪聲,使得權值更新的方向不一定正確。
此外,SGD也沒能單獨克服區域性最優解的問題。
2.動量優化法
動量優化方法是在梯度下降法的基礎上進行的改變,具有加速梯度下降的作用。一般有標準動量優化方法Momentum、NAG(Nesterov accelerated gradient)動量優化方法
NAG在Tensorflow中與Momentum合併在同一函式tf.train.MomentumOptimizer中,可以通過引數配置啟用
Momentum
使用動量(Momentum)的隨機梯度下降法(SGD),主要思想是引入一個積攢歷史梯度資訊動量來加速SGD
從訓練集中取一個大小為nn的小批量{X(1),X(2),...,X(n)}樣本,對應的真實值分別為Y(i),則Momentum優化表示式為:
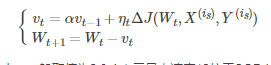
其中,vt表示t時刻積攢的加速度。α表示動力的大小,一般取值為0.9(表示最大速度10倍於SGD)。ΔJ(Wt,X(is),Y(is))含義見SGD演算法。Wt表示t時刻模型引數
動量主要解決SGD的兩個問題:一是隨機梯度的方法(引入的噪聲);二是Hessian矩陣病態問題(可以理解為SGD在收斂過程中和正確梯度相比來回擺動比較大的問題)。
理解策略為:由於當前權值的改變會受到上一次權值改變的影響,類似於小球向下滾動的時候帶上了慣性。這樣可以加快小球向下滾動的速度
NAG
牛頓加速梯度(NAG, Nesterov accelerated gradient)演算法,是Momentum動量演算法的變種。更新模型引數表示式如下
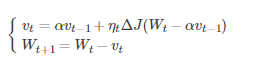
其中,vt表示t時刻積攢的加速度;α表示動力的大小;ηt表示學習率,Wt表示t時刻的模型引數,ΔJ(Wt−αvt−1)表示代價函式關於Wt的梯度
Nesterov動量梯度的計算在模型引數施加當前速度之後,因此可以理解為往標準動量中添加了一個校正因子
理解策略:在Momentun中小球會盲目地跟從下坡的梯度,容易發生錯誤。所以需要一個更聰明的小球,能提前知道它要去哪裡,還要知道走到坡底的時候速度慢下來而不是又衝上另一個坡。
計算Wt−αvt−1可以表示小球下一個位置大概在哪裡。從而可以提前知道下一個位置的梯度,然後使用到當前位置來更新引數
在凸批量梯度的情況下,Nesterov動量將額外誤差收斂率從O(1/k)(k步後)改進到O(1/k2)。然而,在隨機梯度情況下,Nesterov動量對收斂率的作用卻不是很大
3.自適應學習率優化演算法
自適應學習率優化演算法主要有:AdaGrad演算法,RMSProp演算法,Adam演算法以及AdaDelta演算法
AdaGrad演算法
思想:
AdaGrad演算法,獨立地適應所有模型引數的學習率,縮放每個引數反比於其所有梯度歷史平均值總和的平方根
具有代價函式最大梯度的引數相應地有個快速下降的學習率,而具有小梯度的引數在學習率上有相對較小的下降。
演算法描述:
AdaGrad演算法優化策略一般可以表示為:
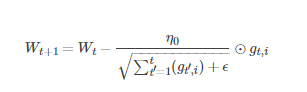
假定一個多分類問題,i表示第i個分類,t表示第t迭代同時也表示分類i累計出現的次數。η0表示初始的學習率取值一般為0.01,ϵ是一個取值很小的數(一般為1e-8)為了避免分母為0。
Wt表示t時刻即第t迭代模型的引數,gt,i=ΔJ(Wt,i)表示t時刻,指定分類ii,代價函式J(⋅)關於W的梯度。
從表示式可以看出,對出現比較多的類別資料,Adagrad給予越來越小的學習率,而對於比較少的類別資料,會給予較大的學習率。因此Adagrad適用於資料稀疏或者分佈不平衡的資料集。
Adagrad 的主要優勢在於不需要人為的調節學習率,它可以自動調節;缺點在於,隨著迭代次數增多,學習率會越來越小,最終會趨近於0
RMSProp演算法
思想:
RMSProp演算法修改了AdaGrad的梯度積累為指數加權的移動平均,使得其在非凸設定下效果更好。
演算法描述:
RMSProp演算法的一般策略可以表示為:
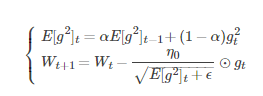
其中,Wt表示tt時刻即第t迭代模型的引數,gt=ΔJ(Wt)表示t次迭代代價函式關於W的梯度大小,E[g2]t表示前t次的梯度平方的均值。
α表示動力(通常設定為0.9),η0表示全域性初始學習率。ϵ是一個取值很小的數(一般為1e-8)為了避免分母為0
RMSProp借鑑了Adagrad的思想,觀察表示式,分母為√E[g2]t+ϵ。由於取了個加權平均,避免了學習率越來越低的的問題,而且能自適應地調節學習率。
RMSProp演算法在經驗上已經被證明是一種有效且實用的深度神經網路優化演算法。目前它是深度學習從業者經常採用的優化方法之一
AdaDelta演算法
思想:AdaGrad演算法和RMSProp演算法都需要指定全域性學習率,AdaDelta演算法結合兩種演算法每次引數的更新步長即
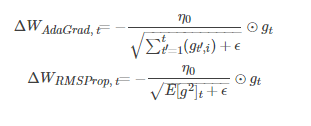
演算法描述:
AdaDelta演算法策略可以表示為:
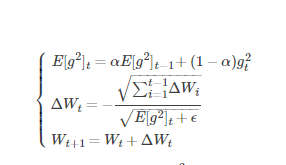
其中Wt為第t次迭代的模型引數,gt=ΔJ(Wt)為代價函式關於W的梯度。E[g2]t表示前t次的梯度平方的均值。∑t−1i=1ΔWi表示前t−1t−1次模型引數每次的更新步長累加求根。
從表示式可以看出,AdaDelta不需要設定一個預設的全域性學習率。
評價:
在模型訓練的初期和中期,AdaDelta表現很好,加速效果不錯,訓練速度快。
在模型訓練的後期,模型會反覆地在區域性最小值附近抖動。
Adam演算法
https://blog.csdn.net/shenxiaoming77/article/details/77169756
https://blog.csdn.net/weixin_40170902/article/details/80092628