
常用七種排序的python實現
阿新 • • 發佈:2018-12-10
閱讀目錄
1 演算法複雜度
演算法複雜度分為時間複雜度和空間複雜度。其中, 時間複雜度是指執行演算法所需要的計算工作量;而空間複雜度是指執行這個演算法所需要的記憶體空間。
演算法的複雜性體現在執行該演算法時的計算機所需資源的多少上,計算機資源最重要的是時間和空間資源,因此複雜度分為時間和空間複雜度。用大O表示。
常見的時間複雜度(按效率排序)
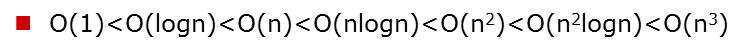
2 氣泡排序
冒泡法:第一趟:相鄰的兩數相比,大的往下沉。最後一個元素是最大的。
第二趟:相鄰的兩數相比,大的往下沉。最後一個元素不用比。
1 def bubble_sort(array): 2 for i in range(len(array)-1): 3 for j in range(len(array) - i -1): 4 if array[j] > array[j+1]: 5 array[j], array[j+1] = array[j+1], array[j]
時間複雜度:O(n^2)
穩定性:穩定
改進:如果一趟比較沒有發生位置變換,則認為排序完成

1 def bubble_sort(array): 2 for i in range(len(array)-1): 3 current_status = False 4 for j in range(len(array) - i -1): 5 if array[j] > array[j+1]: 6 array[j], array[j+1] = array[j+1], array[j] 7 current_status = True 8 if not current_status: 9 break
3 直接選擇排序
選擇排序法:每一次從待排序的資料元素中選出最小(或最大)的一個元素,存放到序列的起始位置,直到全部排完。
1 def select_sort(array): 2 for i in range(len(array)-1): 3 min = i 4 for j in range(i+1, len(array)): 5 if array[j] < array[min]: 6 min = j 7 array[i], array[min] = array[min], array[i]
時間複雜度:O(n^2)
穩定性:不穩定
4 直接插入排序
列表被分為有序區和無序區兩個部分。最初有序區只有一個元素。
每次從無序區選擇一個元素,插入到有序區的位置,直到無序區變空。
其實就相當於摸牌:
1 def insert_sort(array):
2 # 迴圈的是第二個到最後(待摸的牌)
3 for i in range(1, len(array)):
4 # 待插入的數(摸上來的牌)
5 min = array[i]
6 # 已排好序的最右邊一個元素(手裡的牌的最右邊)
7 j = i - 1
8 # 一隻和排好的牌比較,排好的牌的牌的索引必須大於等於0
9 # 比較過程中,如果手裡的比摸上來的大,
10 while j >= 0 and array[j] > min:
11 # 那麼手裡的牌往右邊移動一位,就是把j付給j+1
12 array[j+1] = array[j]
13 # 換完以後在和下一張比較
14 j -= 1
15 # 找到了手裡的牌比摸上來的牌小或等於的時候,就把摸上來的放到它右邊
16 array[j+1] = min
時間複雜度:O(n^2)
穩定性:穩定
5 快速排序
取一個元素p(通常是第一個元素,但是這是比較糟糕的選擇),使元素p歸位(把p右邊比p小的元素都放在它左邊,在把空缺位置的左邊比p大的元素放在p右邊);
列表被p分成兩部分,左邊都比p小,右邊都比p大;
遞迴完成排序。
1 def quick_sort(array, left, right):
2 if left < right:
3 mid = partition(array, left, right)
4 quick_sort(array, left, mid-1)
5 quick_sort(array, mid+1, right)
6
7 def partition(array, left, right):
8 tmp = array[left]
9 while left < right:
10 while left < right and array[right] >= tmp:
11 right -= 1
12 array[left] = array[right]
13 while left < right and array[left] <= tmp:
14 left += 1
15 array[right] = array[left]
16 array[left] = tmp
17 return left
時間複雜度:O(nlogn),一般情況是O(nlogn),最壞情況(逆序):O(n^2)
穩定性:不穩定
特點:就是快
6 堆排序
步驟:
建立堆
得到堆頂元素,為最大元素
去掉堆頂,將堆最後一個元素放到堆頂,此時可通過一次調整重新使堆有序。
堆頂元素為第二大元素。
重複步驟3,直到堆變空。
1 def sift(array, left, right):
2 """調整"""
3 i = left # 當前調整的小堆的父節點
4 j = 2*i + 1 # i的左孩子
5 tmp = array[i] # 當前調整的堆的根節點
6 while j <= right: # 如果孩子還在堆的邊界內
7 if j < right and array[j] < array[j+1]: # 如果i有右孩子,且右孩子比左孩子大
8 j = j + 1 # 大孩子就是右孩子
9 if tmp < array[j]: # 比較根節點和大孩子,如果根節點比大孩子小
10 array[i] = array[j] # 大孩子上位
11 i = j # 新調整的小堆的父節點
12 j = 2*i + 1 # 新調整的小堆中I的左孩子
13 else: # 否則就是父節點比大孩子大,則終止迴圈
14 break
15 array[i] = tmp # 最後i的位置由於是之前大孩子上位了,是空的,而這個位置是根節點的正確位置。
16
17
18 def heap(array):
19 n = len(array)
20 # 建堆,從最後一個有孩子的父親開始,直到根節點
21 for i in range(n//2 - 1, -1, -1):
22 # 每次調整i到結尾
23 sift(array, i, n-1)
24 # 挨個出數
25 for i in range(n-1, -1, -1):
26 # 把根節點和調整的堆的最後一個元素交換
27 array[0], array[i] = array[i], array[0]
28 # 再調整,從0到i-1
29 sift(array, 0, i-1)
時間複雜度:O(nlogn),
穩定性:不穩定
特點:通常都比快排慢
7 為什麼堆排比快排慢?
回顧一下堆排的過程:
1. 建立最大堆(堆頂的元素大於其兩個兒子,兩個兒子又分別大於它們各自下屬的兩個兒子... 以此類推)
2. 將堆頂的元素和最後一個元素對調(相當於將堆頂元素(最大值)拿走,然後將堆底的那個元素補上它的空缺),然後讓那最後一個元素從頂上往下滑到恰當的位置(重新使堆最大化)。
3. 重複第2步。
這裡的關鍵問題就在於第2步,堆底的元素肯定很小,將它拿到堆頂和原本屬於最大元素的兩個子節點比較,它比它們大的可能性是微乎其微的。實際上它肯定小於其中的一個兒子。而大於另一個兒子的可能性非常小。於是,這一次比較的結果就是概率不均等的,根據前面的分析,概率不均等的比較是不明智的,因為它並不能保證在糟糕情況下也能將問題的可能性削減到原本的1/2。可以想像一種極端情況,如果a肯定小於b,那麼比較a和b就會什麼資訊也得不到——原本剩下多少可能性還是剩下多少可能性。
在堆排裡面有大量這種近乎無效的比較,因為被拿到堆頂的那個元素幾乎肯定是很小的,而靠近堆頂的元素又幾乎肯定是很大的,將一個很小的數和一個很大的數比較,結果幾乎肯定是“小於”的,這就意味著問題的可能性只被排除掉了很小一部分。
這就是為什麼堆排比較慢(堆排雖然和快排一樣複雜度都是O(NlogN)但堆排複雜度的常係數更大)。
MacKay也提供了一個修改版的堆排:每次不是將堆底的元素拿到上面去,而是直接比較堆頂(最大)元素的兩個兒子,即選出次大的元素。由於這兩個兒子之間的大小關係是很不確定的,兩者都很大,說不好哪個更大哪個更小,所以這次比較的兩個結果就是概率均等的了8 歸併排序
思路:
一次歸併:將現有的列表分為左右兩段,將兩段裡的元素逐一比較,小的就放入新的列表中。比較結束後,新的列表就是排好序的。
然後遞迴。
1 # 一次歸併
2 def merge(array, low, mid, high):
3 """
4 兩段需要歸併的序列從左往右遍歷,逐一比較,小的就放到
5 tmp裡去,再取,再比,再放。
6 """
7 tmp = []
8 i = low
9 j = mid +1
10 while i <= mid and j <= high:
11 if array[i] <= array[j]:
12 tmp.append(array[i])
13 i += 1
14 else:
15 tmp.append(array[j])
16 j += 1
17 while i <= mid:
18 tmp.append(array[i])
19 i += 1
20 while j <= high:
21 tmp.append(array[j])
22 j += 1
23 array[low:high+1] = tmp
24
25 def merge_sort(array, low, high):
26 if low < high:
27 mid = (low + high) // 2
28 merge_sort(array, low, mid)
29 merge_sort(array, mid+1, high)
30 merge(array, low, mid, high)
時間複雜度:O(nlogn)
穩定性:穩定
快排、堆排和歸併的小結
三種排序演算法的時間複雜度都是O(nlogn)
一般情況下,就執行時間而言:
快速排序 < 歸併排序 < 堆排序
三種排序演算法的缺點:
快速排序:極端情況下排序效率低
歸併排序:需要額外的記憶體開銷
堆排序:在快的排序演算法中相對較慢9 希爾排序
希爾排序是一種分組插入排序演算法。
首先取一個整數d1=n/2,將元素分為d1個組,每組相鄰量元素之間距離為d1,在各組內進行直接插入排序;
取第二個整數d2=d1/2,重複上述分組排序過程,直到di=1,即所有元素在同一組內進行直接插入排序。希爾排序每趟並不使某些元素有序,而是使整體資料越來越接近有序;最後一趟排序使得所有資料有序。
1 def shell_sort(li):
2 """希爾排序"""
3 gap = len(li) // 2
4 while gap > 0:
5 for i in range(gap, len(li)):
6 tmp = li[i]
7 j = i - gap
8 while j >= 0 and tmp < li[j]:
9 li[j + gap] = li[j]
10 j -= gap
11 li[j + gap] = tmp
12 gap //= 2
時間複雜度:O((1+τ)n)
不是很快,位置尷尬
10 排序小結

作者:ZingpLiu 出處:http://www.cnblogs.com/zingp/ 本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線。