
Hbase物理儲存
物理模型
- 每個column family儲存在HDFS上的一個單獨檔案中,空值不會被儲存。
- Key 和 Version number在每個column family中均有一份;
- HBase為每個值維護了多級索引,即:<key, columnfamily, columnname, timestamp>;
- 表在行的方向上分割為多個Region;
- Region是Hbase中分散式儲存和負載均衡的最小單元,不同Region分佈到不同RegionServer上。
- Region按大小分割的,隨著資料增多,Region不斷增大,當增大到一個閥值的時候,Region就會分成兩個新的Region;
- Region雖然是分散式儲存的最小單元,但並不是儲存的最小單元。每個Region包含著多個Store物件。每個Store包含一個MemStore或若干StoreFile,StoreFile包含一個或多個HFile。MemStore存放在記憶體中,StoreFile儲存在HDFS上。

Region的數量設計
這裡需要提一下,每個regionsServer的region數量不要太多,以免造成RS不響應或其它問題。Region的數量由memstore記憶體使用情況來決定的,
每個region都有至少一個memstore,這個儲存的值可分配,一般來說都是128M-256M範圍,每個memstore佔堆記憶體的預設值為40%
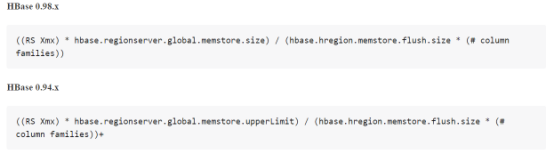
以下是region的計算公式。
MemStore
將修改資訊快取在記憶體當中
資訊格式為Cell/KeyValue
當flush觸發時,MemStore會生成快照儲存起來,新的MemStore會繼續接收修改資訊,指導flush完成之後快照會被刪除
當一個MemStore flush發生時,屬於同一個region的memStore會一起flush
MemStore Flush刷入觸發機制
MemStore的大小達到單個MemStore閥值
hbase.hregion.memstore.flush.size
RegionServer中所有MemStore的使用率超過RS中MemStore上限值,該Server上所有MemStore會執行flush直到完成或者小於RS中MemStore安全值
hbase.regionserver.global.memstore.upperLimit
或者
hbase.regionserver.global.memstore.size
RegionServer中WAL超過WAL閥值
hbase.regionserver.max.logs
ROOT表和META表
HBase的所有Region元資料被儲存在.META.表中,隨著Region的增多,.META.表中的資料也會增大,並分裂成多個新的Region。為了定位.META.表中各個Region的位置,把.META.表中所有Region的元資料儲存在-ROOT-表中,最後由Zookeeper記錄-ROOT-表的位置資訊。所有客戶端訪問使用者資料前,需要首先訪問Zookeeper獲得-ROOT-的位置,然後訪問-ROOT-表獲得.META.表的位置,最後根據.META.表中的資訊確定使用者資料存放的位置,如下圖所示。
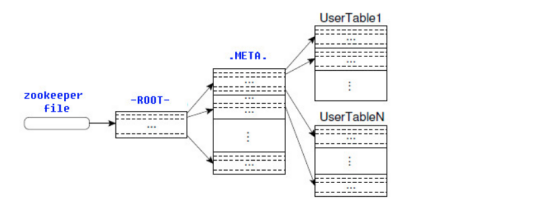
-ROOT-表永遠不會被分割,它只有一個Region,這樣可以保證最多隻需要三次跳轉就可以定位任意一個Region。為了加快訪問速度,.META.表的所有Region全部儲存在記憶體中。客戶端會將查詢過的位置資訊快取起來,且快取不會主動失效。如果客戶端根據快取資訊還訪問不到資料,則詢問相關.META.表的Region伺服器,試圖獲取資料的位置,如果還是失敗,則詢問-ROOT-表相關的.META.表在哪裡。最後,如果前面的資訊全部失效,則通過ZooKeeper重新定位Region的資訊。所以如果客戶端上的快取全部是失效,則需要進行6次網路來回,才能定位到正確的Region。
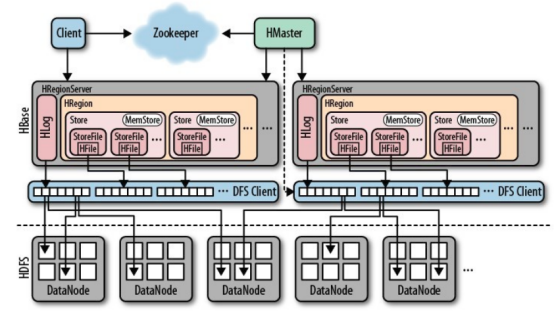
一個完整分散式的HBase的組成示意圖如下
Hbase高可用
Write-Ahead-Log(WAL)保障資料高可用
由於HBase的資料是先寫入記憶體,資料累計達到記憶體閥值時才往磁碟中flush資料,所以,如果在資料還沒有flush進硬碟時,regionserver down掉了,記憶體中的資料將丟失。要想解決這個場景的問題就需要用到WAL(Write-Ahead-Log),tableDesc.setDurability(Durability. SYNC_WAL ) 就是設定寫WAL日誌的級別,該方式安全性較高,但無疑會一定程度影響效能,請根據具體場景選擇使用;
我們理解下HLog的作用。HBase中的HLog機制是WAL的一種實現,而WAL(一般翻譯為預寫日誌)是事務機制中常見的一致性的實現方式。每個RegionServer中都會有一個HLog的例項,RegionServer會將更新操作(如 Put,Delete)先記錄到 WAL(也就是HLog)中,然後將其寫入到Store的MemStore,最終MemStore會將資料寫入到持久化的HFile中(MemStore 到達配置的記憶體閥值)。這樣就保證了HBase的寫的可靠性。如果沒有 WAL,當RegionServer宕掉的時候,MemStore 還沒有寫入到HFile,或者StoreFile還沒有儲存,資料就會丟失。或許有的讀者會擔心HFile本身會不會丟失,這是由 HDFS 來保證的。在HDFS中的資料預設會有3份。因此這裡並不考慮 HFile 本身的可靠性。
HFile由很多個數據塊(Block)組成,並且有一個固定的結尾塊。其中的資料塊是由一個Header和多個Key-Value的鍵值對組成。在結尾的資料塊中包含了資料相關的索引資訊,系統也是通過結尾的索引資訊找到HFile中的資料。
元件高可用
- Master容錯:Zookeeper重新選擇一個新的Master。如果無Master過程中,資料讀取仍照常進行,但是,region切分、負載均衡等無法進行;
- RegionServer容錯:定時向Zookeeper彙報心跳,如果一旦時間內未出現心跳,Master將該RegionServer上的Region重新分配到其他RegionServer上,失效伺服器上“預寫”日誌由主伺服器進行分割並派送給新的RegionServer;
- Zookeeper容錯:Zookeeper是一個可靠地服務,一般配置3或5個Zookeeper例項。