
BiLSTM+keras+tensorflow實現中文分詞
一、Word2Vec
Word2Vec(Word Embeddings)——詞向量/詞嵌入
是一個可以將語言中字詞轉化為向量形式表達(Vector Representations)的模型。
主要分為CBOW(Continuous Bag of Words)和Skip-Gram兩種模式,其中CBOW是從原始語句(比如:中國的首都是____)推測目標字詞(比如:北京);而Skip-Gram則正好相反,它是從目標字詞推出原始語句,其中CBOW對小型資料比較合適,而Skip-Gram則在大型語料中表現的更好。
且使用Word2Vec訓練語料會得到一些非常有趣的結果,比如意思相近的詞在向量空間中的位置會接近。諸如
二、雙向RNN
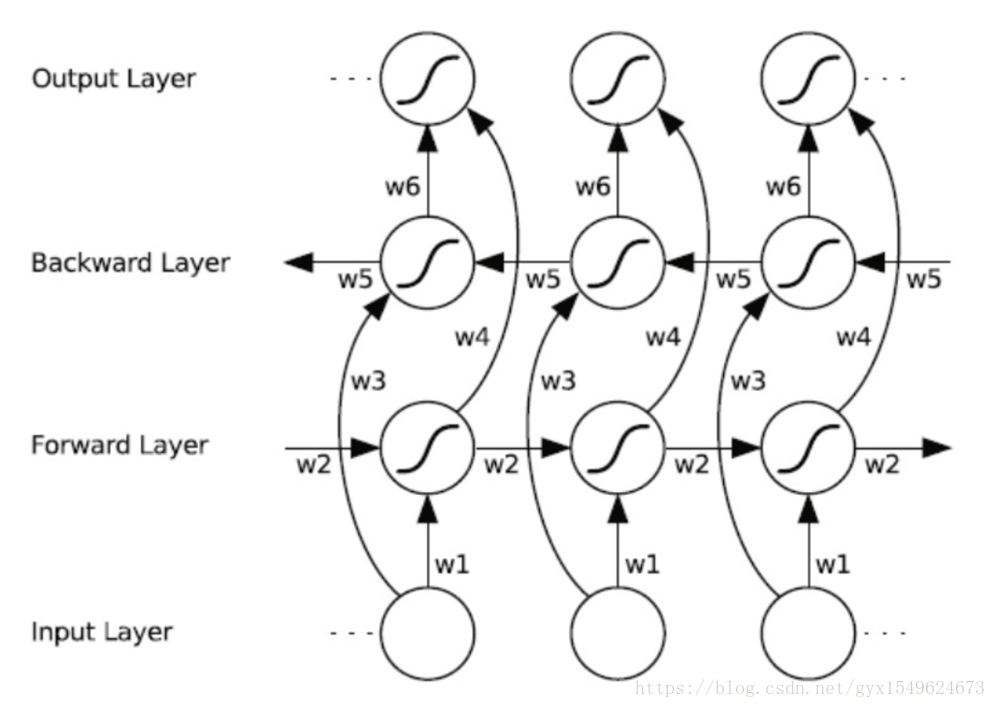
雙向迴圈神經網路(BRNN)的基本思想是提出每一個訓練序列向前和向後分別是兩個迴圈神經網路(RNN),而且這兩個都連線著一個輸出層。這個結構提供給輸出層輸入序列中每一個點的完整的過去和未來的上下文資訊。下圖展示的是一個沿著時間展開的雙向迴圈神經網路。六個獨特的權值在每一個時步被重複的利用,六個權值分別對應:輸入到向前和向後隱含層(w1, w3),隱含層到隱含層自己(w2, w5),向前和向後隱含層到輸出層(w4, w6)。值得注意的是:向前和向後隱含層之間沒有資訊流,這保證了展開圖是非迴圈的
三、雙向LSTM
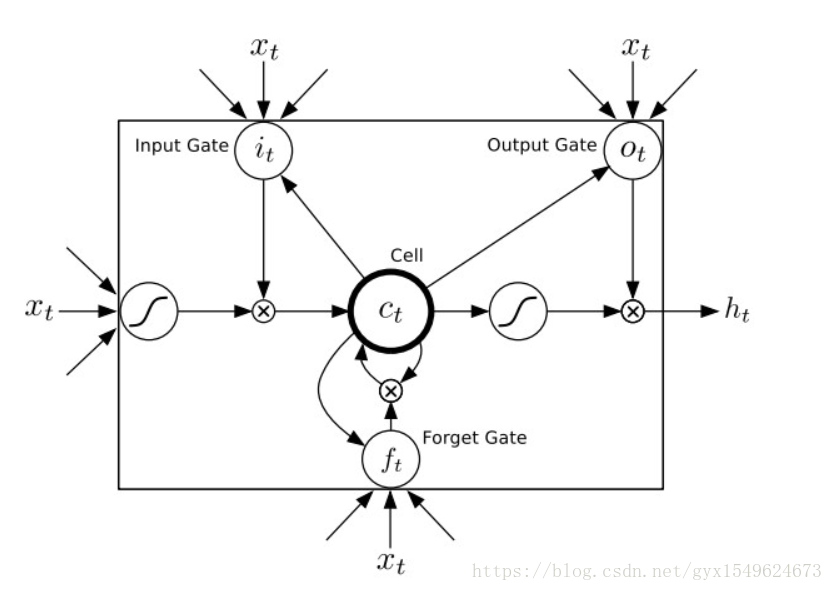
迴圈神經網路(RNN)在工作時一個重要的優點在於,其能夠在輸入和輸出序列之間的對映過程中利用上下文相關資訊。然而不幸的是,標準的迴圈神經網路(RNN)能夠存取的上下文資訊範圍很有限。這個問題就使得隱含層的輸入對於網路輸出的影響隨著網路環路的不斷遞迴而衰退。因此,為了解決這個問題,長短時記憶(LSTM)結構誕生了。與其說長短時記憶是一種迴圈神經網路,倒不如說是一個加強版的元件被放在了迴圈神經網路中。具體地說,就是把迴圈神經網路中隱含層的小圓圈換成長短時記憶的模組。這個模組的樣子如下圖所示:
將雙向RNN中的圓圈換成長短時記憶模組
四、分詞的實現
一、構造字典
將文字中出現的漢字加入到字典,每一個漢字對應唯一數字值
二、分詞向量
對已經分好詞的語料打上標籤,如下
一字詞:
我 s 4
二字詞:
中 B 1
國 E 3
三字詞:
共 B 1
產 M 2
黨 E 3
三、文字向量化
將文字根據標點符號進行切分成多條短文字splitpunc=[‘。’,’?’,’!’,’;’]根據第一步構造的字典將短文字轉化為向量,其中長度超過100的將超出部分切除,長度不足100的向量進行補0
四、進入BiLSTM進行訓練
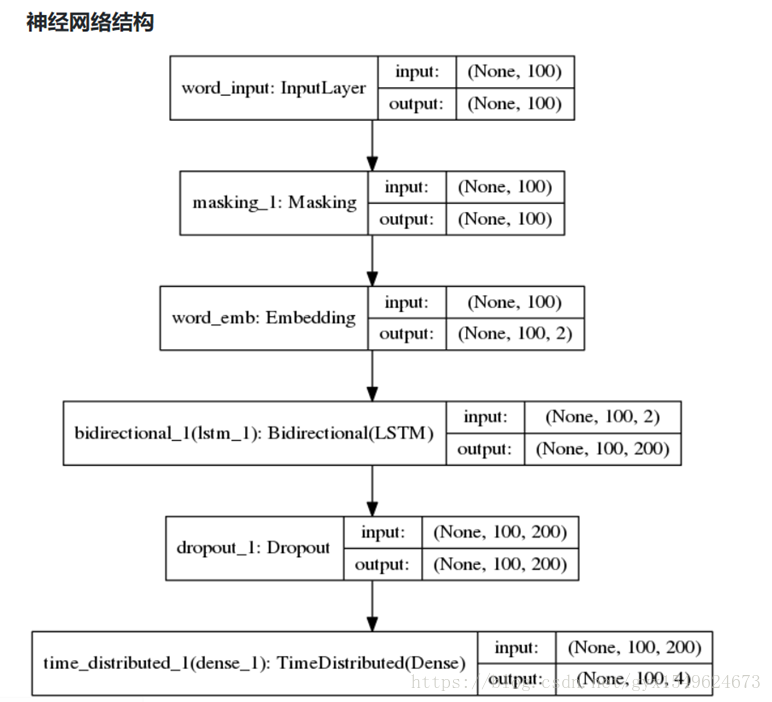
五、測試
結果:

實驗完整程式碼及語料:https://download.csdn.net/download/gyx1549624673/10721936