統計學習方法筆記1
阿新 • • 發佈:2018-12-11
第一章統計學習方法概論
1.1統計學習
- 統計學習特點:計算機網路平臺,資料驅動,構建模型,預測分析
- 統計學習物件:data,具有一定統計規律的資料
- 統計學習目的:預測分析
- 統計學習方法:模型,策略,演算法; 統計學習方法的步驟:
- 統計學習方法的研究:理論與應用
- 統計學習方法重要性:資料探勘領域核心技術

1.2監督學習
1.2.1基本概念
- 輸入空間,輸出空間,特徵空間
例項的特徵向量表示:
特徵空間:表示例項的特徵向量的集合 訓練集的表示:
- 聯合概率分佈 輸入與輸出的隨機變數X和Y遵循聯合概率分佈P(X,Y),P(X,Y)表示分佈函式。
- 假設空間 輸入空間到輸出空間的模型集合,就是假設空間。 監督學習的模型分非概率模型(決策函式Y=F(X))和概率模型(條件概率表示)
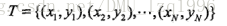
1.2.2問題形式化
監督學習問題:
1.3統計學習三要素(模型,策略,演算法)
1.3.1模型
模型:由輸入到輸出的一個函式,所有模型(函式)構成假設空間。
模型分類:由決策函式表示的模型稱為非概率模型;由條件概率表示的模型稱為概率模型。
非概率模型:

概率模型:

1.3.2策略(如何從假設空間選擇最優模型)
策略即衡量模型好壞的一個度量標準。
- 損失函式與風險函式
損失函式:利用模型進行預測的輸出值f(X)與真實值Y的度量函式,記為L(Y,f(X))。
統計學習中常用的損失函式:
風險函式(期望損失):平均意義下的損失,即損失函式的期望值。
模型選擇即策略就是選擇期望風險最小的模型。
- 經驗風險最小化與結構風險最小化
經驗風險:當具體到某一訓練集上時,風險函式就變為經驗風險,經驗風險是關於訓練樣本集的平均損失。根據大數定律可以知道,當樣本足夠大時,經驗風險就是風險函式。
經驗風險最小化策略:最優模型即經驗風險最小時的模型。
當樣本容量過小時存在問題:過擬合現象—結構風險最小化 結構風險最小化:在經驗風險上加上表示模型複雜度的正則化項(罰項) 結構風險定義為:
尾項表示模型複雜度,模型越複雜,結構風險越大,反之,模型越簡單,結構風險越小。即可以有效防止過擬合問題。
1.3.3演算法

1.4模型評估與模型選擇
1.4.1訓練誤差與測試誤差
訓練誤差:關於訓練資料集


1.4.2 過擬合與模型選擇
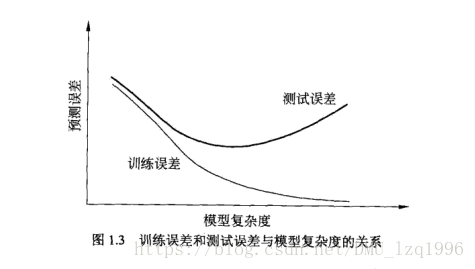
過擬合現象:對於訓練資料預測能力極高的高複雜度的模型 ,這類模型過於追求對於訓練資料的擬合程度,訓練誤差極低,但導致模型引數過多,複雜度太高,而且對於未知資料的預測能力低,測試誤差太大。
如何衡量模型複雜度與測試誤差及訓練誤差的關係?

1.5正則化與交叉驗證
1.5.1正則化
正則化:結構風險最小化策略的實現,為了選擇經驗風險與模型複雜度同時較小的模型。
正則化項:模型複雜度的單調遞增函式,模型複雜度越高,正則化值越大。
正則化項不同形式:(範數?)

1.5.2交叉驗證
資料集分為訓練集,驗證集,測試集,利用三個集合對模型進行來回驗證,即交叉驗證。 分類:簡單交叉驗證;S折交叉驗證;留一交叉驗證
1.6泛化能力
1.6.1 泛化誤差
泛化誤差即模型的期望風險。

1.6.2泛化誤差上界
泛化誤差上界性質:與樣本容量成反比,與假設空間容量成正比。
二分類的泛化誤差上界:

1.7生成模型與判別模型
生成模型:



1.8 三大監督學習問題
- 分類問題
分類問題中的模型稱為分類器,評價分類器效能的指標有以下:
- 標註問題
經典應用:詞性標註問題 常用統計學習方法:隱馬爾科夫模型,條件隨機場
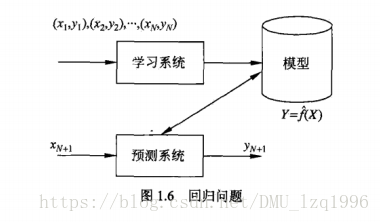
- 迴歸問題