
機器學習系列文章(監督學習):迴歸
在機器學習領域,最神奇的模型當屬迴歸模型,迴歸模型也是非專業人員一談機器學習就能無意涉及到的內容。在這裡,筆者先談談當前資訊學科被無良媒體誇大報道賺取點選率關注度的商業行為。不知何時起,國民自負的以為手裡拿著手機,包裡揹著筆記本就以為掌握了資訊時代發展的最前沿資訊。這種不理性的行為,除了為你賺取一點跟你一樣自負人的談資外,一無所獲。另一方面,當一項新的網際網路技術取得了突破性成果後,無良媒體瘋狂炒作概念,引誘使用者群體關注。所以希望我們每個專業和非專業人士都能時刻保持理性,正確看待技術革新。避免再次出現,‘區塊鏈養豬’,‘區塊鏈種菜’ 等笑料。
迴歸模型通過多項式插值的方式學習一個能夠擬合採樣資料的多項式數值函式。通過這個一般的多項式函式,預測未來資料在這個多項式函式中的走勢。進而,達到預測的目的。
--迴歸模型理論解釋
在機器學習中,函式是未知的,不過我們有從其中抽取的訓練集。




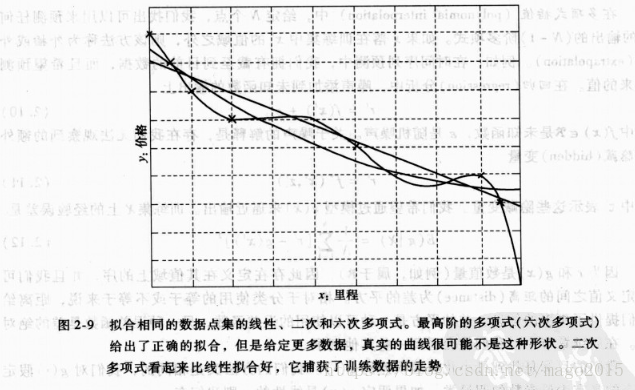
參考:機器學習導論
相關推薦
機器學習系列文章(監督學習):迴歸
在機器學習領域,最神奇的模型當屬迴歸模型,迴歸模型也是非專業人員一談機器學習就能無意涉及到的內容。在這裡,筆者先談談當前資訊學科被無良媒體誇大報道賺取點選率關注度的商業行為。不知何時起,國民自負的以為手裡拿著手機,包裡揹著筆記本就以為掌握了資訊時代發展的最前沿資訊。這種不理性
【轉載】《零基礎入門深度學習》系列文章(教程+程式碼)
轉自:https://blog.csdn.net/TS1130/article/details/53244576 無論即將到來的是大資料時代還是人工智慧時代,亦或是傳統行業使用人工智慧在雲上處理大資料的時代,作為一個有理想有追求的程式設計師,不懂深度學習(Deep Learning)這個超熱的技
[轉]《零基礎入門深度學習》系列文章(教程+程式碼)
無論即將到來的是大資料時代還是人工智慧時代,亦或是傳統行業使用人工智慧在雲上處理大資料的時代,作為一個有理想有追求的程式設計師,不懂深度學習(Deep Learning)這個超熱的技術,會不會感覺馬上就out了?現在救命稻草來了,《零基礎入門深度學習》系列文章旨
【機器學習系列文章】第1部分:為什麼機器學習很重要 ?
目錄 路線圖 關於作者 簡單,簡單的解釋,附有數學,程式碼和現實世界的例子。 這個系列是一本完整的電子書!在這裡下載。免費下載,貢獻讚賞(paypal.me/ml4h) 路線圖 第1部分:為什麼機器學習很重要。人工智慧和機器學習的大
【機器學習系列文章】第6部分:最好的機器學習資源
目錄 基金會 程式設計 線性代數 概率與統計 微積分 機器學習 培訓 教科書 深度學習 培訓 專案 閱讀 強化學習 培訓 專案 閱讀 人工智慧 簡訊 別人的建議 製作人工智慧,機器學習和深度學習課程的資源彙編。 關於制定課
【機器學習系列文章】第5部分:強化學習
目錄 你做到了! 結束思考 探索和開發。馬爾可夫決策過程。Q-learning,政策學習和深度強化學習。 “我只吃了一些巧克力來完成最後一節。” 在有監督的學習中,訓練資料帶有來自某些神聖的“主管”的答案。如果只有這樣的生活! 在強化學
機器學習實戰教程(十二):線性迴歸提高篇之樂高玩具套件二手價預測
一、前言 本篇文章講解線性迴歸的縮減方法,嶺迴歸以及逐步線性迴歸,同時熟悉sklearn的嶺迴歸使用方法,對樂高玩具套件的二手價格做出預測。 二、嶺迴歸 如果資料的特徵比樣本點還多應該怎麼辦?很顯然,此時我們不能再使用上文的方法進行計算了,因為矩陣X不是滿秩矩陣,非
深度學習系列之(dlib+opencv)程式碼收藏
1. dlib::array2d 與 cv::Mat 互轉 dlib::array2d is an image already, you can use it for any dlib's image functions //load image: dl
ReactJS學習系列課程(React學習總結)
進來學習React, 下面來總結一下,主要有以下幾點: ReactJs是基於元件化的開發,所以最終你的頁面應該是由若干個小元件組成的大元件。 可以通過屬性,將值傳遞到元件內部,同理也可以通過屬性
Win10深度學習環境配置(上篇):python3 + curl + pip + Jupyter notebook
好記性不如爛筆頭,純粹為自己的學習生活記錄點什麼! 本次記錄win10下安裝python3+curl+pip+jupyter,以及修改右鍵快捷開啟cmd 對於大多數的學習者,還是習慣選擇在ubuntu系統上學習深度學習,主要還是因為絕大多數演算法實現都是ubunt
TiDB 原始碼閱讀系列文章(二十)Table Partition
作者:肖亮亮 Table Partition 什麼是 Table Partition Table Partition 是指根據一定規則,將資料庫中的一張表分解成多個更小的容易管理的部分。從邏輯上看只有一張表,但是底層卻是由多個物理分割槽組成。相信對有關係型資料庫使用背景的使用者來
TiDB 原始碼閱讀系列文章(十九)tikv-client(下)
上篇文章 中,我們介紹了資料讀寫過程中 tikv-client 需要解決的幾個具體問題,本文將繼續介紹 tikv-client 裡的兩個主要的模組——負責處理分散式計算的 copIterator 和執行二階段提交的 twoPhaseCommitter。 copIterator cop
Linux 學習之路(十一):壓縮歸檔以及RAID
壓縮、解壓縮命令 壓縮格式:gz,bz2,xz,zip,Z 壓縮演算法不同,壓縮比(壓縮後的大小-壓縮前的大小/壓縮前的大小)可能也會不同。 compress:FILENAME.Z uncompress 只能壓縮檔案,預設會刪除原檔案保留壓縮後文件: gzip
Linux 學習之路(十一):RAID和LVM
傳輸速度 Mb/8=MB 硬碟的介面: IDE(ATA):133Mbps 並行匯流排 SATA:300Mbps,600Mbps,6Gbps 序列匯流排 USB:USB3.0:480Mbps 序列匯流排 SCSI:Small Computer System Int
hadoop學習之HIVE(3.2):hadoop2.7.2下配置hiveserver2啟動遠端連線
./hive只是啟動本地客戶端,往往用來測試,我們可以啟動hive server2伺服器用於遠端連線,方便開發。 前提是配置好hadoop和hive 1,開啟hive server服務:bin/hiveserver2 可檢視服務是否開啟:netstat -nplt |
hadoop學習之HDFS(2.5):windows下eclipse遠端連線linux下的hadoop叢集並測試wordcount例子
windows下eclipse遠端連線linux下的hadoop叢集不像在linux下直接配置eclipse一樣方便,會出現各種各樣的問題,處處是坑,連線hadoop和執行例子時都會出現問題,而網上的
hadoop學習之HDFS(2.4):hadoop資料型別與java資料型別的對比與轉換
前言: hadoop由各個節點構成一個叢集,分散式儲存就要考慮到資料在節點之間來回傳遞的問題。為了解決這一問題,hadoop採用了java中的序列化和反序列化概念。序列化(serialization)是指將結構化的物件轉化為位元組流,以便在網路上傳輸或者寫入到硬碟進行
TiKV 原始碼解析系列文章(十一)Storage
作者:張金鵬 背景知識 TiKV 是一個強一致的支援事務的分散式 KV 儲存。TiKV 通過 raft 來保證多副本之間的強一致,
objc系列譯文(6.3):Mach-O 可執行檔案
當我們在Xcode中構建一個程式的時候,其中有一部分就是把原始檔(.m和.h)檔案轉變成可執行檔案。這個可執行檔案包含了將會在CPU(iOS裝置上的arm處理器或者你mac上的Intel處理器)執行的位元組碼。 我們將會過一遍編譯器這個過程的做了些什麼,同時也看一下
objc系列譯文(6.4):深入理解 CocoaPods
Cocoapods是 OS X 和 iOS 下的一個第三方庫管理工具。你能使用CocoaPods新增被稱作“Pods”的依賴庫,並輕鬆管理它們的版本,而不用考慮當前的時間和開發環境。 Cocoapods意義體現在兩個方面。首先,引入第三方庫無可避免地要進行各種各樣的