
機器學習實戰教程(十二):線性迴歸提高篇之樂高玩具套件二手價預測
一、前言
本篇文章講解線性迴歸的縮減方法,嶺迴歸以及逐步線性迴歸,同時熟悉sklearn的嶺迴歸使用方法,對樂高玩具套件的二手價格做出預測。
二、嶺迴歸
如果資料的特徵比樣本點還多應該怎麼辦?很顯然,此時我們不能再使用上文的方法進行計算了,因為矩陣X不是滿秩矩陣,非滿秩矩陣在求逆時會出現問題。為了解決這個問題,統計學家引入嶺迴歸(ridge regression)的概念。
1、什麼是嶺迴歸?
嶺迴歸即我們所說的L2正則線性迴歸,在一般的線性迴歸最小化均方誤差的基礎上增加了一個引數w的L2範數的罰項,從而最小化罰項殘差平方和:
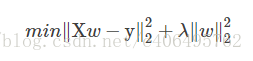
簡單說來,嶺迴歸就是在普通線性迴歸的基礎上引入單位矩陣。迴歸係數的計算公式變形如下:

2、編寫程式碼
為了使用嶺迴歸和縮減技術,首先需要對特徵做標準化處理。因為,我們需要使每個維度特徵具有相同的重要性。本文使用的標準化處理比較簡單,就是將所有特徵都減去各自的均值併除以方差。
程式碼很簡單,只需要稍做修改,其中,λ為模型的引數。我們先繪製一個迴歸係數與log(λ)的曲線圖,看下它們的規律,編寫程式碼如下:
# -*-coding:utf-8 -*- from matplotlib.font_manager import FontProperties import matplotlib.pyplot as plt import numpy as np def loadDataSet(fileName): """ 函式說明:載入資料 Parameters: fileName - 檔名 Returns: xArr - x資料集 yArr - y資料集 Website: http://www.cuijiahua.com/ Modify: 2017-11-20 """ numFeat = len(open(fileName).readline().split('\t')) - 1 xArr = []; yArr = [] fr = open(fileName) for line in fr.readlines(): lineArr =[] curLine = line.strip().split('\t') for i in range(numFeat): lineArr.append(float(curLine[i])) xArr.append(lineArr) yArr.append(float(curLine[-1])) return xArr, yArr def ridgeRegres(xMat, yMat, lam = 0.2): """ 函式說明:嶺迴歸 Parameters: xMat - x資料集 yMat - y資料集 lam - 縮減係數 Returns: ws - 迴歸係數 Website: http://www.cuijiahua.com/ Modify: 2017-11-20 """ xTx = xMat.T * xMat denom = xTx + np.eye(np.shape(xMat)[1]) * lam if np.linalg.det(denom) == 0.0: print("矩陣為奇異矩陣,不能轉置") return ws = denom.I * (xMat.T * yMat) return ws def ridgeTest(xArr, yArr): """ 函式說明:嶺迴歸測試 Parameters: xMat - x資料集 yMat - y資料集 Returns: wMat - 迴歸係數矩陣 Website: http://www.cuijiahua.com/ Modify: 2017-11-20 """ xMat = np.mat(xArr); yMat = np.mat(yArr).T #資料標準化 yMean = np.mean(yMat, axis = 0) #行與行操作,求均值 yMat = yMat - yMean #資料減去均值 xMeans = np.mean(xMat, axis = 0) #行與行操作,求均值 xVar = np.var(xMat, axis = 0) #行與行操作,求方差 xMat = (xMat - xMeans) / xVar #資料減去均值除以方差實現標準化 numTestPts = 30 #30個不同的lambda測試 wMat = np.zeros((numTestPts, np.shape(xMat)[1])) #初始迴歸係數矩陣 for i in range(numTestPts): #改變lambda計算迴歸係數 ws = ridgeRegres(xMat, yMat, np.exp(i - 10)) #lambda以e的指數變化,最初是一個非常小的數, wMat[i, :] = ws.T #計算迴歸係數矩陣 return wMat def plotwMat(): """ 函式說明:繪製嶺迴歸係數矩陣 Website: http://www.cuijiahua.com/ Modify: 2017-11-20 """ font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14) abX, abY = loadDataSet('abalone.txt') redgeWeights = ridgeTest(abX, abY) fig = plt.figure() ax = fig.add_subplot(111) ax.plot(redgeWeights) ax_title_text = ax.set_title(u'log(lambada)與迴歸係數的關係', FontProperties = font) ax_xlabel_text = ax.set_xlabel(u'log(lambada)', FontProperties = font) ax_ylabel_text = ax.set_ylabel(u'迴歸係數', FontProperties = font) plt.setp(ax_title_text, size = 20, weight = 'bold', color = 'red') plt.setp(ax_xlabel_text, size = 10, weight = 'bold', color = 'black') plt.setp(ax_ylabel_text, size = 10, weight = 'bold', color = 'black') plt.show() if __name__ == '__main__': plotwMat()
執行結果如下:

圖繪製了迴歸係數與log(λ)的關係。在最左邊,即λ最小時,可以得到所有係數的原始值(與線性迴歸一致);而在右邊,係數全部縮減成0;在中間部分的某個位置,將會得到最好的預測結果。想要得到最佳的λ引數,可以使用交叉驗證的方式獲得,文章的後面會繼續講解。
三、前向逐步線性迴歸
前向逐步線性迴歸演算法屬於一種貪心演算法,即每一步都儘可能減少誤差。我們計算迴歸係數,不再是通過公式計算,而是通過每次微調各個迴歸係數,然後計算預測誤差。那個使誤差最小的一組迴歸係數,就是我們需要的最佳迴歸係數。
前向逐步線性迴歸實現也很簡單。當然,還是先進行資料標準化,編寫程式碼如下:
# -*-coding:utf-8 -*- from matplotlib.font_manager import FontProperties import matplotlib.pyplot as plt import numpy as np def loadDataSet(fileName): """ 函式說明:載入資料 Parameters: fileName - 檔名 Returns: xArr - x資料集 yArr - y資料集 Website: http://www.cuijiahua.com/ Modify: 2017-11-20 """ numFeat = len(open(fileName).readline().split('\t')) - 1 xArr = []; yArr = [] fr = open(fileName) for line in fr.readlines(): lineArr =[] curLine = line.strip().split('\t') for i in range(numFeat): lineArr.append(float(curLine[i])) xArr.append(lineArr) yArr.append(float(curLine[-1])) return xArr, yArr def regularize(xMat, yMat): """ 函式說明:資料標準化 Parameters: xMat - x資料集 yMat - y資料集 Returns: inxMat - 標準化後的x資料集 inyMat - 標準化後的y資料集 Website: http://www.cuijiahua.com/ Modify: 2017-11-23 """ inxMat = xMat.copy() #資料拷貝 inyMat = yMat.copy() yMean = np.mean(yMat, 0) #行與行操作,求均值 inyMat = yMat - yMean #資料減去均值 inMeans = np.mean(inxMat, 0) #行與行操作,求均值 inVar = np.var(inxMat, 0) #行與行操作,求方差 inxMat = (inxMat - inMeans) / inVar #資料減去均值除以方差實現標準化 return inxMat, inyMat def rssError(yArr,yHatArr): """ 函式說明:計算平方誤差 Parameters: yArr - 預測值 yHatArr - 真實值 Returns: Website: http://www.cuijiahua.com/ Modify: 2017-11-23 """ return ((yArr-yHatArr)**2).sum() def stageWise(xArr, yArr, eps = 0.01, numIt = 100): """ 函式說明:前向逐步線性迴歸 Parameters: xArr - x輸入資料 yArr - y預測資料 eps - 每次迭代需要調整的步長 numIt - 迭代次數 Returns: returnMat - numIt次迭代的迴歸係數矩陣 Website: http://www.cuijiahua.com/ Modify: 2017-12-03 """ xMat = np.mat(xArr); yMat = np.mat(yArr).T #資料集 xMat, yMat = regularize(xMat, yMat) #資料標準化 m, n = np.shape(xMat) returnMat = np.zeros((numIt, n)) #初始化numIt次迭代的迴歸係數矩陣 ws = np.zeros((n, 1)) #初始化迴歸係數矩陣 wsTest = ws.copy() wsMax = ws.copy() for i in range(numIt): #迭代numIt次 # print(ws.T) #列印當前迴歸係數矩陣 lowestError = float('inf'); #正無窮 for j in range(n): #遍歷每個特徵的迴歸係數 for sign in [-1, 1]: wsTest = ws.copy() wsTest[j] += eps * sign #微調回歸係數 yTest = xMat * wsTest #計算預測值 rssE = rssError(yMat.A, yTest.A) #計算平方誤差 if rssE < lowestError: #如果誤差更小,則更新當前的最佳迴歸係數 lowestError = rssE wsMax = wsTest ws = wsMax.copy() returnMat[i,:] = ws.T #記錄numIt次迭代的迴歸係數矩陣 return returnMat def plotstageWiseMat(): """ 函式說明:繪製嶺迴歸係數矩陣 Website: http://www.cuijiahua.com/ Modify: 2017-11-20 """ font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14) xArr, yArr = loadDataSet('abalone.txt') returnMat = stageWise(xArr, yArr, 0.005, 1000) fig = plt.figure() ax = fig.add_subplot(111) ax.plot(returnMat) ax_title_text = ax.set_title(u'前向逐步迴歸:迭代次數與迴歸係數的關係', FontProperties = font) ax_xlabel_text = ax.set_xlabel(u'迭代次數', FontProperties = font) ax_ylabel_text = ax.set_ylabel(u'迴歸係數', FontProperties = font) plt.setp(ax_title_text, size = 15, weight = 'bold', color = 'red') plt.setp(ax_xlabel_text, size = 10, weight = 'bold', color = 'black') plt.setp(ax_ylabel_text, size = 10, weight = 'bold', color = 'black') plt.show() if __name__ == '__main__': plotstageWiseMat()
執行結果如下:
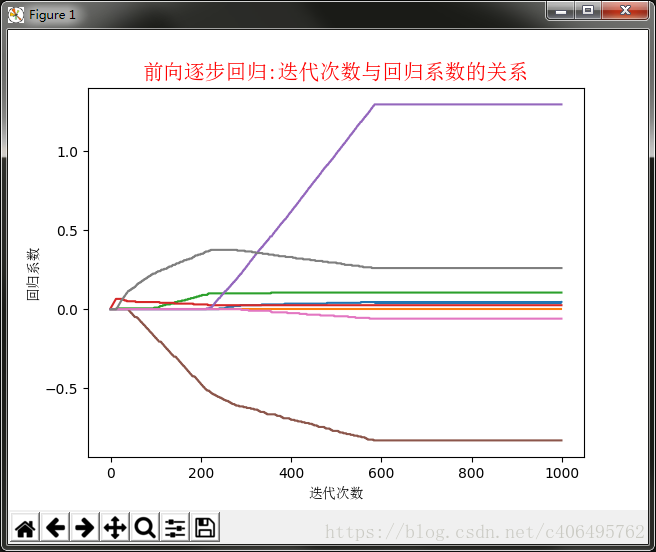
還是,我們列印了迭代次數與迴歸係數的關係曲線。可以看到,有些係數從始至終都是約為0的,這說明它們不對目標造成任何影響,也就是說這些特徵很可能是不需要的。逐步線性迴歸演算法的優點在於它可以幫助人們理解有的模型並做出改進。當構建了一個模型後,可以執行該演算法找出重要的特徵,這樣就有可能及時停止對那些不重要特徵的收集。
總結一下:
縮減方法(逐步線性迴歸或嶺迴歸),就是將一些係數縮減成很小的值或者直接縮減為0。這樣做,就增大了模型的偏差(減少了一些特徵的權重),通過把一些特徵的迴歸係數縮減到0,同時也就減少了模型的複雜度。消除了多餘的特徵之後,模型更容易理解,同時也降低了預測誤差。但是當縮減過於嚴厲的時候,就會出現過擬合的現象,即用訓練集預測結果很好,用測試集預測就糟糕很多。
四、預測樂高玩具套件的價格
樂高(LEGO)公司生產拼裝類玩具,由很多大小不同的塑料插塊組成。它的樣子如下圖所示:

一般來說,這些插塊都是成套出售,它們可以拼裝成很多不同的東西,如船、城堡、一些著名建築等。樂高公司每個套裝包含的部件數目從10件到5000件不等。
一種樂高套件基本上在幾年後就會停產,但樂高的收藏者之間仍會在停產後彼此交易。本次例項,就是使用迴歸方法對收藏者之間的交易價格進行預測。
1、獲取資料
書中使用的方法是通過Google提供的API進行獲取資料,但是現在這個API已經關閉,我們無法通過api獲取資料了。不過幸運的是,我在網上找到了書上用到的那些html檔案。
原始資料下載地址:資料下載
我們通過解析html檔案,來獲取我們需要的資訊,如果學過我的《Python3網路爬蟲》,那麼我想這部分的內容會非常簡單,解析程式碼如下:
# -*-coding:utf-8 -*-
from bs4 import BeautifulSoup
def scrapePage(retX, retY, inFile, yr, numPce, origPrc):
"""
函式說明:從頁面讀取資料,生成retX和retY列表
Parameters:
retX - 資料X
retY - 資料Y
inFile - HTML檔案
yr - 年份
numPce - 樂高部件數目
origPrc - 原價
Returns:
無
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
# 開啟並讀取HTML檔案
with open(inFile, encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html)
i = 1
# 根據HTML頁面結構進行解析
currentRow = soup.find_all('table', r = "%d" % i)
while(len(currentRow) != 0):
currentRow = soup.find_all('table', r = "%d" % i)
title = currentRow[0].find_all('a')[1].text
lwrTitle = title.lower()
# 查詢是否有全新標籤
if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1):
newFlag = 1.0
else:
newFlag = 0.0
# 查詢是否已經標誌出售,我們只收集已出售的資料
soldUnicde = currentRow[0].find_all('td')[3].find_all('span')
if len(soldUnicde) == 0:
print("商品 #%d 沒有出售" % i)
else:
# 解析頁面獲取當前價格
soldPrice = currentRow[0].find_all('td')[4]
priceStr = soldPrice.text
priceStr = priceStr.replace('$','')
priceStr = priceStr.replace(',','')
if len(soldPrice) > 1:
priceStr = priceStr.replace('Free shipping', '')
sellingPrice = float(priceStr)
# 去掉不完整的套裝價格
if sellingPrice > origPrc * 0.5:
print("%d\t%d\t%d\t%f\t%f" % (yr, numPce, newFlag, origPrc, sellingPrice))
retX.append([yr, numPce, newFlag, origPrc])
retY.append(sellingPrice)
i += 1
currentRow = soup.find_all('table', r = "%d" % i)
def setDataCollect(retX, retY):
"""
函式說明:依次讀取六種樂高套裝的資料,並生成資料矩陣
Parameters:
無
Returns:
無
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
scrapePage(retX, retY, './lego/lego8288.html', 2006, 800, 49.99) #2006年的樂高8288,部件數目800,原價49.99
scrapePage(retX, retY, './lego/lego10030.html', 2002, 3096, 269.99) #2002年的樂高10030,部件數目3096,原價269.99
scrapePage(retX, retY, './lego/lego10179.html', 2007, 5195, 499.99) #2007年的樂高10179,部件數目5195,原價499.99
scrapePage(retX, retY, './lego/lego10181.html', 2007, 3428, 199.99) #2007年的樂高10181,部件數目3428,原價199.99
scrapePage(retX, retY, './lego/lego10189.html', 2008, 5922, 299.99) #2008年的樂高10189,部件數目5922,原價299.99
scrapePage(retX, retY, './lego/lego10196.html', 2009, 3263, 249.99) #2009年的樂高10196,部件數目3263,原價249.99
if __name__ == '__main__':
lgX = []
lgY = []
setDataCollect(lgX, lgY)執行結果如下:
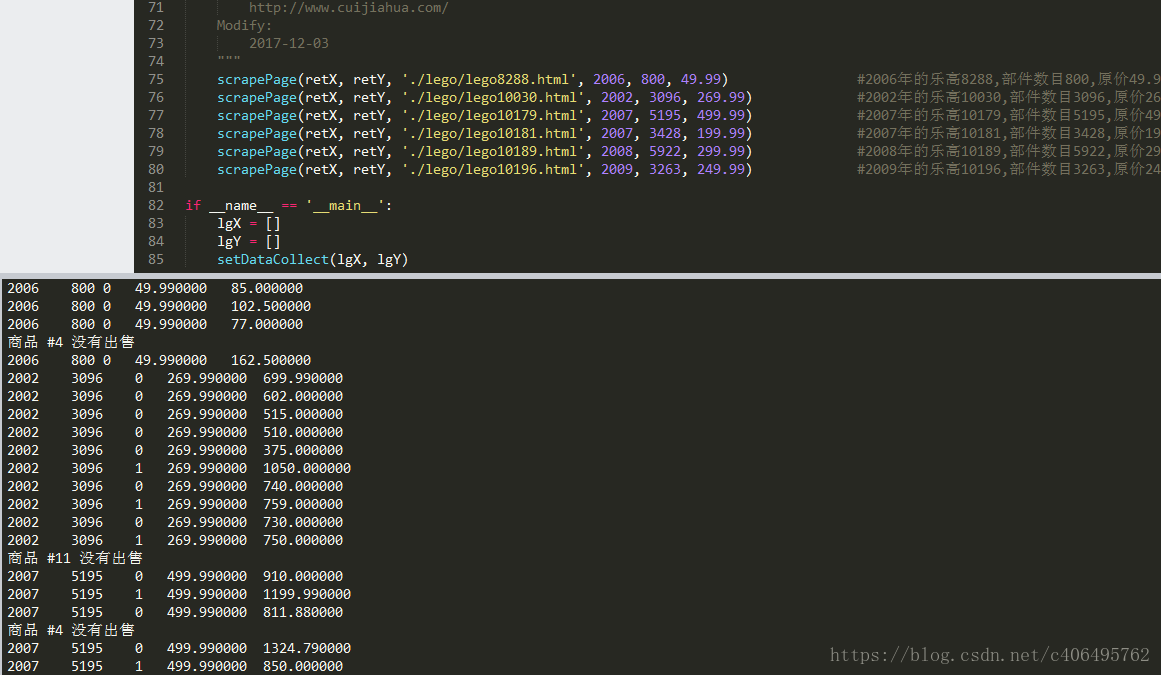
我們對沒有的商品做了處理。這些特徵分別為:出品年份、部件數目、是否為全新、原價、售價(二手交易)。
html解析頁面不會使用?那就學習一下爬蟲知識吧~!如果對此不感興趣,也可以跳過獲取資料和解析資料,這個過程,當作已知資料,繼續進行下一步。
2、建立模型
我們已經處理好了資料集,接下來就是訓練模型。首先我們需要新增全為0的特徵X0列。因為線性迴歸的第一列特徵要求都是1.0。然後使用最簡單的普通線性迴歸i,編寫程式碼如下:
# -*-coding:utf-8 -*-
import numpy as np
from bs4 import BeautifulSoup
def scrapePage(retX, retY, inFile, yr, numPce, origPrc):
"""
函式說明:從頁面讀取資料,生成retX和retY列表
Parameters:
retX - 資料X
retY - 資料Y
inFile - HTML檔案
yr - 年份
numPce - 樂高部件數目
origPrc - 原價
Returns:
無
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
# 開啟並讀取HTML檔案
with open(inFile, encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html)
i = 1
# 根據HTML頁面結構進行解析
currentRow = soup.find_all('table', r = "%d" % i)
while(len(currentRow) != 0):
currentRow = soup.find_all('table', r = "%d" % i)
title = currentRow[0].find_all('a')[1].text
lwrTitle = title.lower()
# 查詢是否有全新標籤
if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1):
newFlag = 1.0
else:
newFlag = 0.0
# 查詢是否已經標誌出售,我們只收集已出售的資料
soldUnicde = currentRow[0].find_all('td')[3].find_all('span')
if len(soldUnicde) == 0:
print("商品 #%d 沒有出售" % i)
else:
# 解析頁面獲取當前價格
soldPrice = currentRow[0].find_all('td')[4]
priceStr = soldPrice.text
priceStr = priceStr.replace('$','')
priceStr = priceStr.replace(',','')
if len(soldPrice) > 1:
priceStr = priceStr.replace('Free shipping', '')
sellingPrice = float(priceStr)
# 去掉不完整的套裝價格
if sellingPrice > origPrc * 0.5:
print("%d\t%d\t%d\t%f\t%f" % (yr, numPce, newFlag, origPrc, sellingPrice))
retX.append([yr, numPce, newFlag, origPrc])
retY.append(sellingPrice)
i += 1
currentRow = soup.find_all('table', r = "%d" % i)
#
def setDataCollect(retX, retY):
"""
函式說明:依次讀取六種樂高套裝的資料,並生成資料矩陣
Parameters:
無
Returns:
無
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
scrapePage(retX, retY, './lego/lego8288.html', 2006, 800, 49.99) #2006年的樂高8288,部件數目800,原價49.99
scrapePage(retX, retY, './lego/lego10030.html', 2002, 3096, 269.99) #2002年的樂高10030,部件數目3096,原價269.99
scrapePage(retX, retY, './lego/lego10179.html', 2007, 5195, 499.99) #2007年的樂高10179,部件數目5195,原價499.99
scrapePage(retX, retY, './lego/lego10181.html', 2007, 3428, 199.99) #2007年的樂高10181,部件數目3428,原價199.99
scrapePage(retX, retY, './lego/lego10189.html', 2008, 5922, 299.99) #2008年的樂高10189,部件數目5922,原價299.99
scrapePage(retX, retY, './lego/lego10196.html', 2009, 3263, 249.99) #2009年的樂高10196,部件數目3263,原價249.99
def regularize(xMat, yMat):
"""
函式說明:資料標準化
Parameters:
xMat - x資料集
yMat - y資料集
Returns:
inxMat - 標準化後的x資料集
inyMat - 標準化後的y資料集
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
inxMat = xMat.copy() #資料拷貝
inyMat = yMat.copy()
yMean = np.mean(yMat, 0) #行與行操作,求均值
inyMat = yMat - yMean #資料減去均值
inMeans = np.mean(inxMat, 0) #行與行操作,求均值
inVar = np.var(inxMat, 0) #行與行操作,求方差
# print(inxMat)
print(inMeans)
# print(inVar)
inxMat = (inxMat - inMeans) / inVar #資料減去均值除以方差實現標準化
return inxMat, inyMat
def rssError(yArr,yHatArr):
"""
函式說明:計算平方誤差
Parameters:
yArr - 預測值
yHatArr - 真實值
Returns:
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
return ((yArr-yHatArr)**2).sum()
def standRegres(xArr,yArr):
"""
函式說明:計算迴歸係數w
Parameters:
xArr - x資料集
yArr - y資料集
Returns:
ws - 迴歸係數
Website:
http://www.cuijiahua.com/
Modify:
2017-11-12
"""
xMat = np.mat(xArr); yMat = np.mat(yArr).T
xTx = xMat.T * xMat #根據文中推導的公示計算迴歸係數
if np.linalg.det(xTx) == 0.0:
print("矩陣為奇異矩陣,不能轉置")
return
ws = xTx.I * (xMat.T*yMat)
return ws
def useStandRegres():
"""
函式說明:使用簡單的線性迴歸
Parameters:
無
Returns:
無
Website:
http://www.cuijiahua.com/
Modify:
2017-11-12
"""
lgX = []
lgY = []
setDataCollect(lgX, lgY)
data_num, features_num = np.shape(lgX)
lgX1 = np.mat(np.ones((data_num, features_num + 1)))
lgX1[:, 1:5] = np.mat(lgX)
ws = standRegres(lgX1, lgY)
print('%f%+f*年份%+f*部件數量%+f*是否為全新%+f*原價' % (ws[0],ws[1],ws[2],ws[3],ws[4]))
if __name__ == '__main__':
useStandRegres()執行結果如下圖所示:

可以看到,模型採用的公式如上圖所示。雖然這個模型對於資料擬合得很好,但是看上不沒有什麼道理。套件裡的部件數量越多,售價反而降低了,這是不合理的。
我們使用嶺迴歸,通過交叉驗證,找到使誤差最小的λ對應的迴歸係數。編寫程式碼如下:
# -*-coding:utf-8 -*-
import numpy as np
from bs4 import BeautifulSoup
import random
def scrapePage(retX, retY, inFile, yr, numPce, origPrc):
"""
函式說明:從頁面讀取資料,生成retX和retY列表
Parameters:
retX - 資料X
retY - 資料Y
inFile - HTML檔案
yr - 年份
numPce - 樂高部件數目
origPrc - 原價
Returns:
無
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
# 開啟並讀取HTML檔案
with open(inFile, encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html)
i = 1
# 根據HTML頁面結構進行解析
currentRow = soup.find_all('table', r = "%d" % i)
while(len(currentRow) != 0):
currentRow = soup.find_all('table', r = "%d" % i)
title = currentRow[0].find_all('a')[1].text
lwrTitle = title.lower()
# 查詢是否有全新標籤
if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1):
newFlag = 1.0
else:
newFlag = 0.0
# 查詢是否已經標誌出售,我們只收集已出售的資料
soldUnicde = currentRow[0].find_all('td')[3].find_all('span')
if len(soldUnicde) == 0:
print("商品 #%d 沒有出售" % i)
else:
# 解析頁面獲取當前價格
soldPrice = currentRow[0].find_all('td')[4]
priceStr = soldPrice.text
priceStr = priceStr.replace('$','')
priceStr = priceStr.replace(',','')
if len(soldPrice) > 1:
priceStr = priceStr.replace('Free shipping', '')
sellingPrice = float(priceStr)
# 去掉不完整的套裝價格
if sellingPrice > origPrc * 0.5:
print("%d\t%d\t%d\t%f\t%f" % (yr, numPce, newFlag, origPrc, sellingPrice))
retX.append([yr, numPce, newFlag, origPrc])
retY.append(sellingPrice)
i += 1
currentRow = soup.find_all('table', r = "%d" % i)
def ridgeRegres(xMat, yMat, lam = 0.2):
"""
函式說明:嶺迴歸
Parameters:
xMat - x資料集
yMat - y資料集
lam - 縮減係數
Returns:
ws - 迴歸係數
Website:
http://www.cuijiahua.com/
Modify:
2017-11-20
"""
xTx = xMat.T * xMat
denom = xTx + np.eye(np.shape(xMat)[1]) * lam
if np.linalg.det(denom) == 0.0:
print("矩陣為奇異矩陣,不能轉置")
return
ws = denom.I * (xMat.T * yMat)
return ws
def setDataCollect(retX, retY):
"""
函式說明:依次讀取六種樂高套裝的資料,並生成資料矩陣
Parameters:
無
Returns:
無
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
scrapePage(retX, retY, './lego/lego8288.html', 2006, 800, 49.99) #2006年的樂高8288,部件數目800,原價49.99
scrapePage(retX, retY, './lego/lego10030.html', 2002, 3096, 269.99) #2002年的樂高10030,部件數目3096,原價269.99
scrapePage(retX, retY, './lego/lego10179.html', 2007, 5195, 499.99) #2007年的樂高10179,部件數目5195,原價499.99
scrapePage(retX, retY, './lego/lego10181.html', 2007, 3428, 199.99) #2007年的樂高10181,部件數目3428,原價199.99
scrapePage(retX, retY, './lego/lego10189.html', 2008, 5922, 299.99) #2008年的樂高10189,部件數目5922,原價299.99
scrapePage(retX, retY, './lego/lego10196.html', 2009, 3263, 249.99) #2009年的樂高10196,部件數目3263,原價249.99
def regularize(xMat, yMat):
"""
函式說明:資料標準化
Parameters:
xMat - x資料集
yMat - y資料集
Returns:
inxMat - 標準化後的x資料集
inyMat - 標準化後的y資料集
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
inxMat = xMat.copy() #資料拷貝
inyMat = yMat.copy()
yMean = np.mean(yMat, 0) #行與行操作,求均值
inyMat = yMat - yMean #資料減去均值
inMeans = np.mean(inxMat, 0) #行與行操作,求均值
inVar = np.var(inxMat, 0) #行與行操作,求方差
# print(inxMat)
print(inMeans)
# print(inVar)
inxMat = (inxMat - inMeans) / inVar #資料減去均值除以方差實現標準化
return inxMat, inyMat
def rssError(yArr,yHatArr):
"""
函式說明:計算平方誤差
Parameters:
yArr - 預測值
yHatArr - 真實值
Returns:
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
return ((yArr-yHatArr)**2).sum()
def standRegres(xArr,yArr):
"""
函式說明:計算迴歸係數w
Parameters:
xArr - x資料集
yArr - y資料集
Returns:
ws - 迴歸係數
Website:
http://www.cuijiahua.com/
Modify:
2017-11-12
"""
xMat = np.mat(xArr); yMat = np.mat(yArr).T
xTx = xMat.T * xMat #根據文中推導的公示計算迴歸係數
if np.linalg.det(xTx) == 0.0:
print("矩陣為奇異矩陣,不能轉置")
return
ws = xTx.I * (xMat.T*yMat)
return ws
def crossValidation(xArr, yArr, numVal = 10):
"""
函式說明:交叉驗證嶺迴歸
Parameters:
xArr - x資料集
yArr - y資料集
numVal - 交叉驗證次數
Returns:
wMat - 迴歸係數矩陣
Website:
http://www.cuijiahua.com/
Modify:
2017-11-20
"""
m = len(yArr) #統計樣本個數
indexList = list(range(m)) #生成索引值列表
errorMat = np.zeros((numVal,30)) #create error mat 30columns numVal rows
for i in range(numVal): #交叉驗證numVal次
trainX = []; trainY = [] #訓練集
testX = []; testY = [] #測試集
random.shuffle(indexList) #打亂次序
for j in range(m): #劃分資料集:90%訓練集,10%測試集
if j < m * 0.9:
trainX.append(xArr[indexList[j]])
trainY.append(yArr[indexList[j]])
else:
testX.append(xArr[indexList[j]])
testY.append(yArr[indexList[j]])
wMat = ridgeTest(trainX, trainY) #獲得30個不同lambda下的嶺迴歸係數
for k in range(30): #遍歷所有的嶺迴歸係數
matTestX = np.mat(testX); matTrainX = np.mat(trainX) #測試集
meanTrain = np.mean(matTrainX,0) #測試集均值
varTrain = np.var(matTrainX,0) #測試集方差
matTestX = (matTestX - meanTrain) / varTrain #測試集標準化
yEst = matTestX * np.mat(wMat[k,:]).T + np.mean(trainY) #根據ws預測y值
errorMat[i, k] = rssError(yEst.T.A, np.array(testY)) #統計誤差
meanErrors = np.mean(errorMat,0) #計算每次交叉驗證的平均誤差
minMean = float(min(meanErrors)) #找到最小誤差
bestWeights = wMat[np.nonzero(meanErrors == minMean)] #找到最佳迴歸係數
xMat = np.mat(xArr); yMat = np.mat(yArr).T
meanX = np.mean(xMat,0); varX = np.var(xMat,0)
unReg = bestWeights / varX #資料經過標準化,因此需要還原
print('%f%+f*年份%+f*部件數量%+f*是否為全新%+f*原價' % ((-1 * np.sum(np.multiply(meanX,unReg)) + np.mean(yMat)), unReg[0,0], unReg[0,1], unReg[0,2], unReg[0,3]))
def ridgeTest(xArr, yArr):
"""
函式說明:嶺迴歸測試
Parameters:
xMat - x資料集
yMat - y資料集
Returns:
wMat - 迴歸係數矩陣
Website:
http://www.cuijiahua.com/
Modify:
2017-11-20
"""
xMat = np.mat(xArr); yMat = np.mat(yArr).T
#資料標準化
yMean = np.mean(yMat, axis = 0) #行與行操作,求均值
yMat = yMat - yMean #資料減去均值
xMeans = np.mean(xMat, axis = 0) #行與行操作,求均值
xVar = np.var(xMat, axis = 0) #行與行操作,求方差
xMat = (xMat - xMeans) / xVar #資料減去均值除以方差實現標準化
numTestPts = 30 #30個不同的lambda測試
wMat = np.zeros((numTestPts, np.shape(xMat)[1])) #初始迴歸係數矩陣
for i in range(numTestPts): #改變lambda計算迴歸係數
ws = ridgeRegres(xMat, yMat, np.exp(i - 10)) #lambda以e的指數變化,最初是一個非常小的數,
wMat[i, :] = ws.T #計算迴歸係數矩陣
return wMat
if __name__ == '__main__':
lgX = []
lgY = []
setDataCollect(lgX, lgY)
crossValidation(lgX, lgY)執行結果如下圖所示:
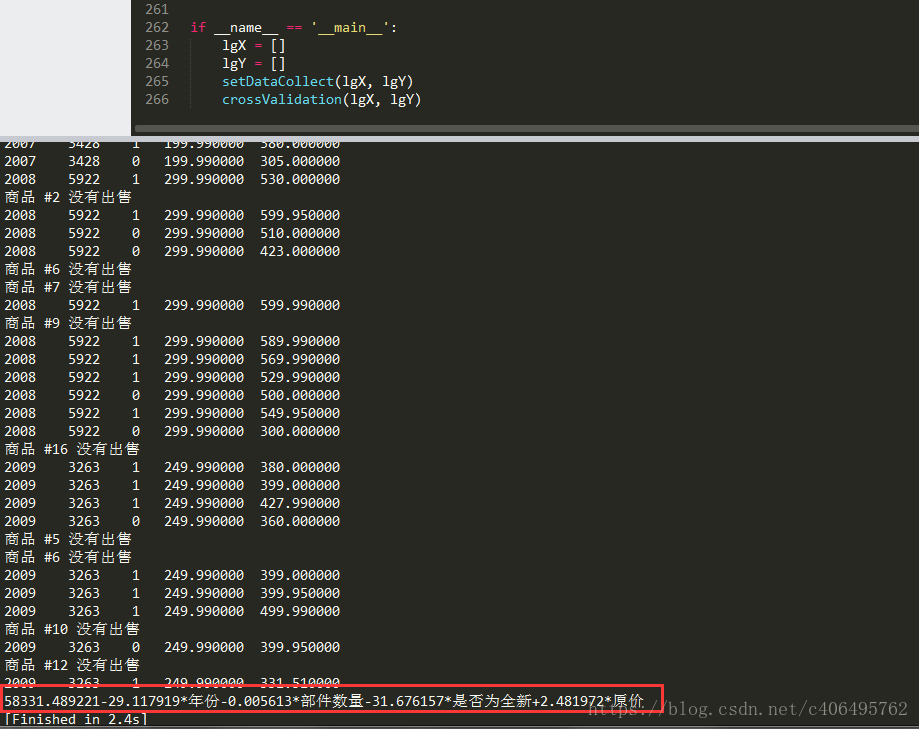
這裡隨機選取樣本,因為其隨機性,所以每次執行的結果可能略有不同。不過整體如上圖所示,可以看出,它與常規的最小二乘法,即普通的線性迴歸沒有太大差異。我們本期望找到一個更易於理解的模型,顯然沒有達到預期效果。
現在,我們看一下在縮減過程中迴歸係數是如何變化的。編寫程式碼如下:
# -*-coding:utf-8 -*-
import numpy as np
from bs4 import BeautifulSoup
import random
def scrapePage(retX, retY, inFile, yr, numPce, origPrc):
"""
函式說明:從頁面讀取資料,生成retX和retY列表
Parameters:
retX - 資料X
retY - 資料Y
inFile - HTML檔案
yr - 年份
numPce - 樂高部件數目
origPrc - 原價
Returns:
無
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
# 開啟並讀取HTML檔案
with open(inFile, encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html)
i = 1
# 根據HTML頁面結構進行解析
currentRow = soup.find_all('table', r = "%d" % i)
while(len(currentRow) != 0):
currentRow = soup.find_all('table', r = "%d" % i)
title = currentRow[0].find_all('a')[1].text
lwrTitle = title.lower()
# 查詢是否有全新標籤
if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1):
newFlag = 1.0
else:
newFlag = 0.0
# 查詢是否已經標誌出售,我們只收集已出售的資料
soldUnicde = currentRow[0].find_all('td')[3].find_all('span')
if len(soldUnicde) == 0:
print("商品 #%d 沒有出售" % i)
else:
# 解析頁面獲取當前價格
soldPrice = currentRow[0].find_all('td')[4]
priceStr = soldPrice.text
priceStr = priceStr.replace('$','')
priceStr = priceStr.replace(',','')
if len(soldPrice) > 1:
priceStr = priceStr.replace('Free shipping', '')
sellingPrice = float(priceStr)
# 去掉不完整的套裝價格
if sellingPrice > origPrc * 0.5:
print("%d\t%d\t%d\t%f\t%f" % (yr, numPce, newFlag, origPrc, sellingPrice))
retX.append([yr, numPce, newFlag, origPrc])
retY.append(sellingPrice)
i += 1
currentRow = soup.find_all('table', r = "%d" % i)
def ridgeRegres(xMat, yMat, lam = 0.2):
"""
函式說明:嶺迴歸
Parameters:
xMat - x資料集
yMat - y資料集
lam - 縮減係數
Returns:
ws - 迴歸係數
Website:
http://www.cuijiahua.com/
Modify:
2017-11-20
"""
xTx = xMat.T * xMat
denom = xTx + np.eye(np.shape(xMat)[1]) * lam
if np.linalg.det(denom) == 0.0:
print("矩陣為奇異矩陣,不能轉置")
return
ws = denom.I * (xMat.T * yMat)
return ws
def setDataCollect(retX, retY):
"""
函式說明:依次讀取六種樂高套裝的資料,並生成資料矩陣
Parameters:
無
Returns:
無
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
scrapePage(retX, retY, './lego/lego8288.html', 2006, 800, 49.99) #2006年的樂高8288,部件數目800,原價49.99
scrapePage(retX, retY, './lego/lego10030.html', 2002, 3096, 269.99) #2002年的樂高10030,部件數目3096,原價269.99
scrapePage(retX, retY, './lego/lego10179.html', 2007, 5195, 499.99) #2007年的樂高10179,部件數目5195,原價499.99
scrapePage(retX, retY, './lego/lego10181.html', 2007, 3428, 199.99) #2007年的樂高10181,部件數目3428,原價199.99
scrapePage(retX, retY, './lego/lego10189.html', 2008, 5922, 299.99) #2008年的樂高10189,部件數目5922,原價299.99
scrapePage(retX, retY, './lego/lego10196.html', 2009, 3263, 249.99) #2009年的樂高10196,部件數目3263,原價249.99
def regularize(xMat, yMat):
"""
函式說明:資料標準化
Parameters:
xMat - x資料集
yMat - y資料集
Returns:
inxMat - 標準化後的x資料集
inyMat - 標準化後的y資料集
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
inxMat = xMat.copy() #資料拷貝
inyMat = yMat.copy()
yMean = np.mean(yMat, 0) #行與行操作,求均值
inyMat = yMat - yMean #資料減去均值
inMeans = np.mean(inxMat, 0) #行與行操作,求均值
inVar = np.var(inxMat, 0) #行與行操作,求方差
# print(inxMat)
print(inMeans)
# print(inVar)
inxMat = (inxMat - inMeans) / inVar #資料減去均值除以方差實現標準化
return inxMat, inyMat
def rssError(yArr,yHatArr):
"""
函式說明:計算平方誤差
Parameters:
yArr - 預測值
yHatArr - 真實值
Returns:
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
return ((yArr-yHatArr)**2).sum()
def standRegres(xArr,yArr):
"""
函式說明:計算迴歸係數w
Parameters:
xArr - x資料集
yArr - y資料集
Returns:
ws - 迴歸係數
Website:
http://www.cuijiahua.com/
Modify:
2017-11-12
"""
xMat = np.mat(xArr); yMat = np.mat(yArr).T
xTx = xMat.T * xMat #根據文中推導的公示計算迴歸係數
if np.linalg.det(xTx) == 0.0:
print("矩陣為奇異矩陣,不能轉置")
return
ws = xTx.I * (xMat.T*yMat)
return ws
def ridgeTest(xArr, yArr):
"""
函式說明:嶺迴歸測試
Parameters:
xMat - x資料集
yMat - y資料集
Returns:
wMat - 迴歸係數矩陣
Website:
http://www.cuijiahua.com/
Modify:
2017-11-20
"""
xMat = np.mat(xArr); yMat = np.mat(yArr).T
#資料標準化
yMean = np.mean(yMat, axis = 0) #行與行操作,求均值
yMat = yMat - yMean #資料減去均值
xMeans = np.mean(xMat, axis = 0) #行與行操作,求均值
xVar = np.var(xMat, axis = 0) #行與行操作,求方差
xMat = (xMat - xMeans) / xVar #資料減去均值除以方差實現標準化
numTestPts = 30 #30個不同的lambda測試
wMat = np.zeros((numTestPts, np.shape(xMat)[1])) #初始迴歸係數矩陣
for i in range(numTestPts): #改變lambda計算迴歸係數
ws = ridgeRegres(xMat, yMat, np.exp(i - 10)) #lambda以e的指數變化,最初是一個非常小的數,
wMat[i, :] = ws.T #計算迴歸係數矩陣
return wMat
if __name__ == '__main__':
lgX = []
lgY = []
setDataCollect(lgX, lgY)
print(ridgeTest(lgX, lgY))執行結果如下圖所示:

看執行結果的第一行,可以看到最大的是第4項,第二大的是第2項。
因此,如果只選擇一個特徵來做預測的話,我們應該選擇第4個特徵,也就是原始加個。如果可以選擇2個特徵的話,應該選擇第4個和第2個特徵。
這種分析方法使得我們可以挖掘大量資料的內在規律。在僅有4個特徵時,該方法的效果也許並不明顯;但如果有100個以上的特徵,該方法就會變得十分有效:它可以指出哪個特徵是關鍵的,而哪些特徵是不重要的。
五、使用Sklearn的linear_model
老規矩,最後讓我們用sklearn實現下嶺迴歸吧。
官方英文文件地址:點選檢視
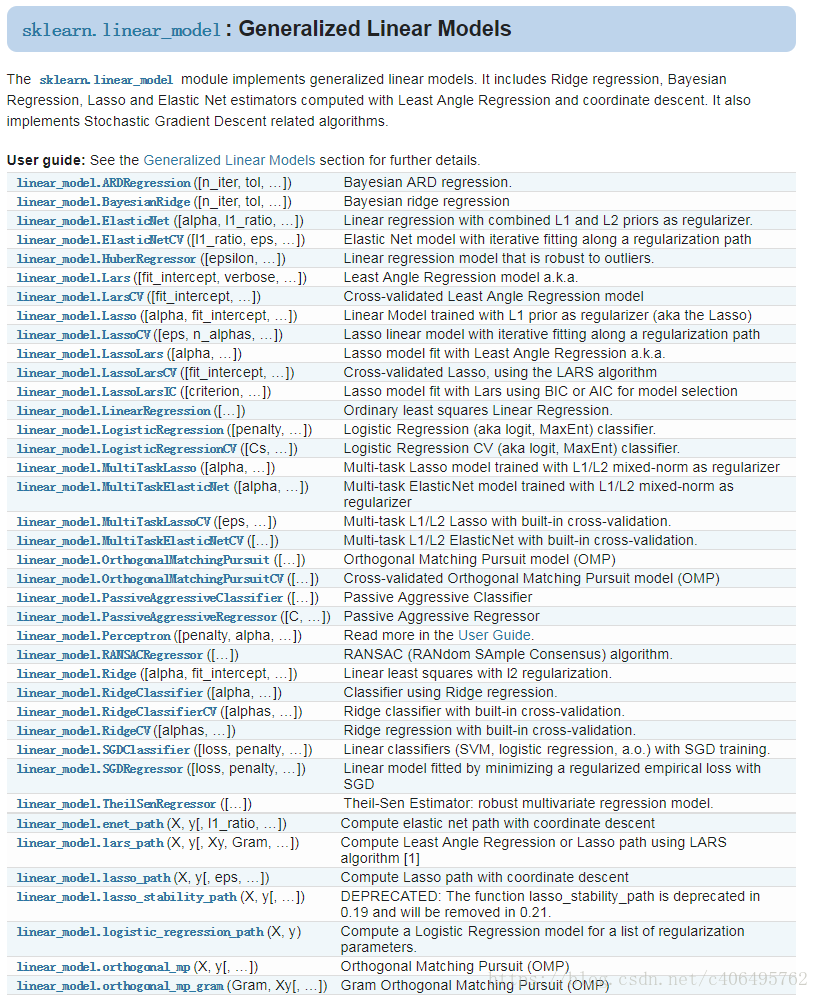
sklearn.linear_model提供了很多線性模型,包括嶺迴歸、貝葉斯迴歸、Lasso等。本文主要講解嶺迴歸Ridge。
1、Ridge
讓我們先看下Ridge這個函式,一共有8個引數:

引數說明如下:
- alpha:正則化係數,float型別,預設為1.0。正則化改善了問題的條件並減少了估計的方差。較大的值指定較強的正則化。
- fit_intercept:是否需要截距,bool型別,預設為True。也就是是否求解b。
- normalize:是否先進行歸一化,bool型別,預設為False。如果為真,則迴歸X將在迴歸之前被歸一化。 當fit_intercept設定為False時,將忽略此引數。 當迴歸量歸一化時,注意到這使得超引數學習更加魯棒,並且幾乎不依賴於樣本的數量。 相同的屬性對標準化資料無效。然而,如果你想標準化,請在呼叫normalize = False訓練估計器之前,使用preprocessing.StandardScaler處理資料。
- copy_X:是否複製X陣列,bool型別,預設為True,如果為True,將複製X陣列; 否則,它覆蓋原陣列X。
- max_iter:最大的迭代次數,int型別,預設為None,最大的迭代次數,對於sparse_cg和lsqr而言,預設次數取決於scipy.sparse.linalg,對於sag而言,則預設為1000次。
- tol:精度,float型別,預設為0.001。就是解的精度。
- solver:求解方法,str型別,預設為auto。可選引數為:auto、svd、cholesky、lsqr、sparse_cg、sag。
- auto根據資料型別自動選擇求解器。
- svd使用X的奇異值分解來計算Ridge係數。對於奇異矩陣比cholesky更穩定。
- cholesky使用標準的scipy.linalg.solve函式來獲得閉合形式的解。
- sparse_cg使用在scipy.sparse.linalg.cg中找到的共軛梯度求解器。作為迭代演算法,這個求解器比大規模資料(設定tol和max_iter的可能性)的cholesky更合適。
- lsqr使用專用的正則化最小二乘常數scipy.sparse.linalg.lsqr。它是最快的,但可能在舊的scipy版本不可用。它是使用迭代過程。
- sag使用隨機平均梯度下降。它也使用迭代過程,並且當n_samples和n_feature都很大時,通常比其他求解器更快。注意,sag快速收斂僅在具有近似相同尺度的特徵上被保證。您可以使用sklearn.preprocessing的縮放器預處理資料。
- random_state:sag的偽隨機種子。
以上就是所有的初始化引數,當然,初始化後還可以通過set_params方法重新進行設定。
知道了這些,接下來就可以編寫程式碼了:
# -*-coding:utf-8 -*-
import numpy as np
from bs4 import BeautifulSoup
import random
def scrapePage(retX, retY, inFile, yr, numPce, origPrc):
"""
函式說明:從頁面讀取資料,生成retX和retY列表
Parameters:
retX - 資料X
retY - 資料Y
inFile - HTML檔案
yr - 年份
numPce - 樂高部件數目
origPrc - 原價
Returns:
無
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
# 開啟並讀取HTML檔案
with open(inFile, encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html)
i = 1
# 根據HTML頁面結構進行解析
currentRow = soup.find_all('table', r = "%d" % i)
while(len(currentRow) != 0):
currentRow = soup.find_all('table', r = "%d" % i)
title = currentRow[0].find_all('a')[1].text
lwrTitle = title.lower()
# 查詢是否有全新標籤
if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1):
newFlag = 1.0
else:
newFlag = 0.0
# 查詢是否已經標誌出售,我們只收集已出售的資料
soldUnicde = currentRow[0].find_all('td')[3].find_all('span')
if len(soldUnicde) == 0:
print("商品 #%d 沒有出售" % i)
else:
# 解析頁面獲取當前價格
soldPrice = currentRow[0].find_all('td')[4]
priceStr = soldPrice.text
priceStr = priceStr.replace('$','')
priceStr = priceStr.replace(',','')
if len(soldPrice) > 1:
priceStr = priceStr.replace('Free shipping', '')
sellingPrice = float(priceStr)
# 去掉不完整的套裝價格
if sellingPrice > origPrc * 0.5:
print("%d\t%d\t%d\t%f\t%f" % (yr, numPce, newFlag, origPrc, sellingPrice))
retX.append([yr, numPce, newFlag, origPrc])
retY.append(sellingPrice)
i += 1
currentRow = soup.find_all('table', r = "%d" % i)
def setDataCollect(retX, retY):
"""
函式說明:依次讀取六種樂高套裝的資料,並生成資料矩陣
Parameters:
無
Returns:
無
Website:
http://www.cuijiahua.com/
Modify:
2017-12-03
"""
scrapePage(retX, retY, './lego/lego8288.html', 2006, 800, 49.99) #2006年的樂高8288,部件數目800,原價49.99
scrapePage(retX, retY, './lego/lego10030.html', 2002, 3096, 269.99) #2002年的樂高10030,部件數目3096,原價269.99
scrapePage(retX, retY, './lego/lego10179.html', 2007, 5195, 499.99) #2007年的樂高10179,部件數目5195,原價499.99
scrapePage(retX, retY, './lego/lego10181.html', 2007, 3428, 199.99) #2007年的樂高10181,部件數目3428,原價199.99
scrapePage(retX, retY, './lego/lego10189.html', 2008, 5922, 299.99) #2008年的樂高10189,部件數目5922,原價299.99
scrapePage(retX, retY, './lego/lego10196.html', 2009, 3263, 249.99) #2009年的樂高10196,部件數目3263,原價249.99
def usesklearn():
"""
函式說明:使用sklearn
Parameters:
無
Returns:
無
Website:
http://www.cuijiahua.com/
Modify:
2017-12-08
"""
from sklearn import linear_model
reg = linear_model.Ridge(alpha = .5)
lgX = []
lgY = []
setDataCollect(lgX, lgY)
reg.fit(lgX, lgY)
print('%f%+f*年份%+f*部件數量%+f*是否為全新%+f*原價' % (reg.intercept_, reg.coef_[0], reg.coef_[1], reg.coef_[2], reg.coef_[3]))
if __name__ == '__main__':
usesklearn()執行結果如下圖所示:
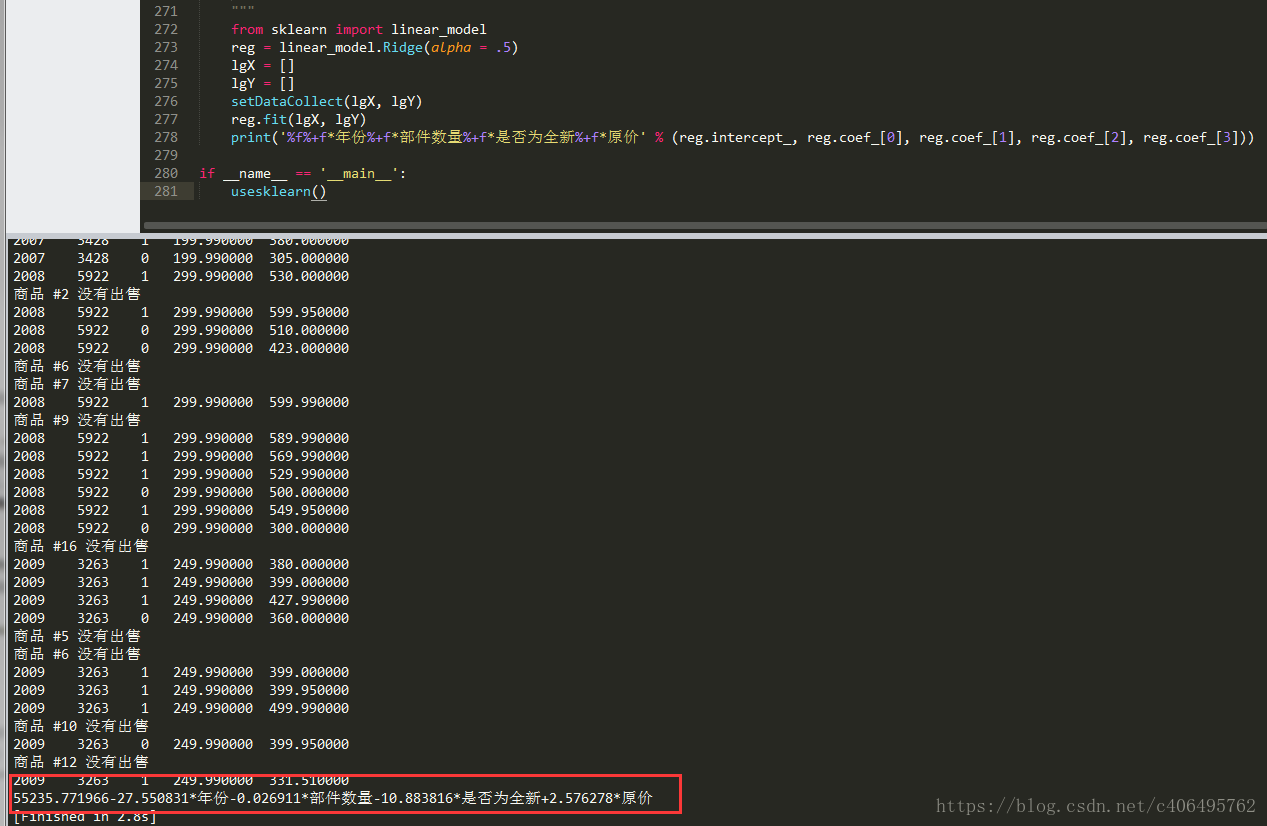
我們不搞太複雜,正則化項係數設為0.5,其餘引數使用預設即可。可以看到,獲得的結果與上小結的結果類似。
六、總結
- 與分類一樣,迴歸也是預測目標值的過程。迴歸與分類的不同點在於,前者預測連續型別變數,而後者預測離散型別變數。
- 嶺迴歸是縮減法的一種,相當於對迴歸係數的大小施加了限制。另一種很好的縮減法是lasso。lasso難以求解,但可以使用計算簡便的逐步線性迴歸方法求的近似解。
- 縮減法還可以看做是對一個模型增加偏差的同時減少方法。
- 下篇文章講解樹迴歸。
PS: 如果覺得本篇本章對您有所幫助,歡迎關注、評論、贊!
本文出現的所有程式碼和資料集,均可在我的github上下載,歡迎Follow、Star:點選檢視
參考文獻:
- 《機器學習實戰》的第五章內容。