
影象分割綜述【深度學習方法】
CNN影象語義分割基本上是這個套路:
- 下采樣+上取樣:Convlution + Deconvlution/Resize
- 多尺度特徵融合:特徵逐點相加/特徵channel維度拼接
- 獲得畫素級別的segement map:對每一個畫素點進行判斷類別
即使是更復雜的DeepLab v3+依然也是這個基本套路。
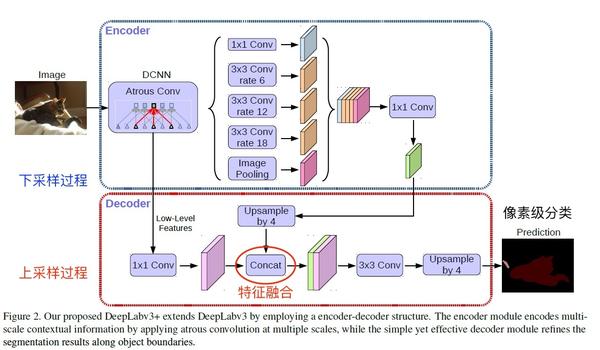 圖13 DeepLab v3+
圖13 DeepLab v3+
Image Segmentation(影象分割)網路結構比較
| 網路 | 父輩 | 生辰 | 增加的結構 | 丟棄的結構 | 優勢 | 劣勢 |
|---|---|---|---|---|---|---|
| VGG16 | FCN的靈感來源 | |||||
| FCN | VGG16 | 2014 | 一個Deconv層(從無到有) | 所有fc層 | 簡單 | 粗糙 |
| DeconvNet | FCN | 2015 | Unpooling層(從無到有)、多個Deconv層(層數增加)、fc層(從無到有) | |||
| SegNet | DeconvNet | 2016 | 每個max_pooling的max索引 | 所有fc層 | ||
| DeepLab | FCN | |||||
| PSPNet | ||||||
| Mask-RCNN | 2017 | 真正做到畫素級 |
Image Segmentation(影象分割)族譜
FCN
-
DeepLab
-
DeconvNet
- SegNet
-
PSPNet
-
Mask-RCNN
按分割目的劃分
-
普通分割
將不同分屬不同物體的畫素區域分開。 如前景與後景分割開,狗的區域與貓的區域與背景分割開。
-
語義分割
在普通分割的基礎上,分類出每一塊區域的語義(即這塊區域是什麼物體)。 如把畫面中的所有物體都指出它們各自的類別。
-
例項分割
在語義分割的基礎上,給每個物體編號。 如這個是該畫面中的狗A,那個是畫面中的狗B。
論文推薦:
影象的語義分割(Semantic Segmentation)是計算機視覺中非常重要的任務。它的目標是為影象中的每個畫素分類。如果能夠快速準去地做影象分割,很多問題將會迎刃而解。因此,它的應用領域就包括但不限於:自動駕駛、影象美化、三維重建等等。

語義分割是一個非常困難的問題,尤其是在深度學習之前。深度學習使得影象分割的準確率提高了很多,下面我們就總結一下近年來最具有代表性的方法和論文。
Fully Convolutional Networks (FCN)
我們介紹的第一篇論文是Fully Convolutional Networks for Semantic Segmentation,簡稱FCN。這篇論文是第一篇成功使用深度學習做影象語義分割的論文。論文的主要貢獻有兩點:
- 提出了全卷積網路。將全連線網路替換成了卷積網路,使得網路可以接受任意大小的圖片,並輸出和原圖一樣大小的分割圖。只有這樣,才能為每個畫素做分類。
- 使用了反捲積層(Deconvolution)。分類神經網路的特徵圖一般只有原圖的幾分之一大小。想要映射回原圖大小必須對特徵圖進行上取樣,這就是反捲積層的作用。雖然名字叫反捲積層,但其實它並不是卷積的逆操作,更合適的名字叫做轉置卷積(Transposed Convolution),作用是從小的特徵圖卷出大的特徵圖。
這是神經網路做語義分割的開山之作,需徹底理解。
DeepLab
DeepLab有v1 v2 v3,第一篇名字叫做DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs。這一系列論文引入了以下幾點比較重要的方法:
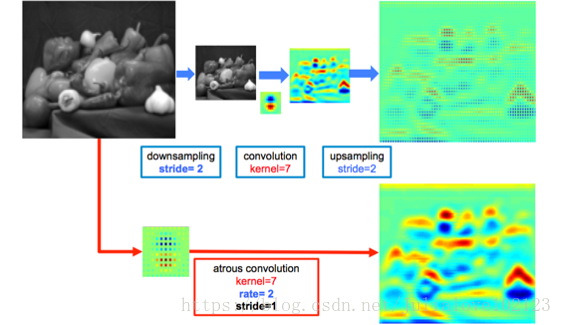
第一個是帶洞卷積,英文名叫做Dilated Convolution,或者Atrous Convolution。帶洞卷積實際上就是普通的卷積核中間插入了幾個洞,如下圖。
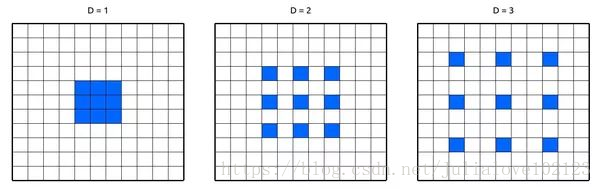
它的運算量跟普通卷積保持一樣,好處是它的“視野更大了”,比如普通3x3卷積的結果的視野是3x3,插入一個洞之後的視野是5x5。視野變大的作用是,在特徵圖縮小到同樣倍數的情況下可以掌握更多影象的全域性資訊,這在語義分割中很重要。

Pyramid Scene Parsing Network
Pyramid Scene Parsing Network的核心貢獻是Global Pyramid Pooling,翻譯成中文叫做全域性金字塔池化。它將特徵圖縮放到幾個不同的尺寸,使得特徵具有更好地全域性和多尺度資訊,這一點在準確率提升上上非常有用。
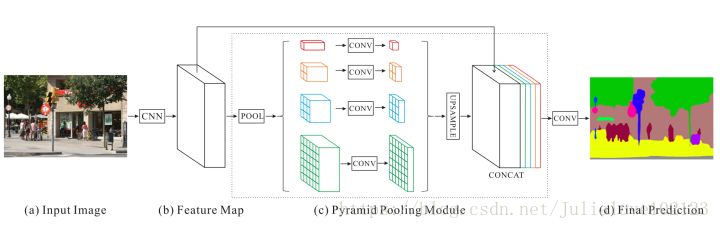
其實不光是語義分割,金字塔多尺度特徵對於各類視覺問題都是挺有用的。
Mask R-CNN
Mask R-CNN是大神何凱明的力作,將Object Detection與Semantic Segmentation合在了一起做。它的貢獻主要是以下幾點。
第一,神經網路有了多個分支輸出。Mask R-CNN使用類似Faster R-CNN的框架,Faster R-CNN的輸出是物體的bounding box和類別,而Mask R-CNN則多了一個分支,用來預測物體的語義分割圖。也就是說神經網路同時學習兩項任務,可以互相促進。
第二,在語義分割中使用Binary Mask。原來的語義分割預測類別需要使用0 1 2 3 4等數字代表各個類別。在Mask R-CNN中,檢測分支會預測類別。這時候分割只需要用0 1預測這個物體的形狀面具就行了。
第三,Mask R-CNN提出了RoiAlign用來替換Faster R-CNN中的RoiPooling。RoiPooling的思想是將輸入影象中任意一塊區域對應到神經網路特徵圖中的對應區域。RoiPooling使用了化整的近似來尋找對應區域,導致對應關係與實際情況有偏移。這個偏移在分類任務中可以容忍,但對於精細度更高的分割則影響較大。
為了解決這個問題,RoiAlign不再使用化整操作,而是使用線性插值來尋找更精準的對應區域。效果就是可以得到更好地對應。實驗也證明了效果不錯。下面展示了與之前方法的對比,下面的圖是Mask R-CNN,可以看出精細了很多。

U-Net
U-Net是原作者參加ISBI Challenge提出的一種分割網路,能夠適應很小的訓練集(大約30張圖)。U-Net與FCN都是很小的分割網路,既沒有使用空洞卷積,也沒有後接CRF,結構簡單。
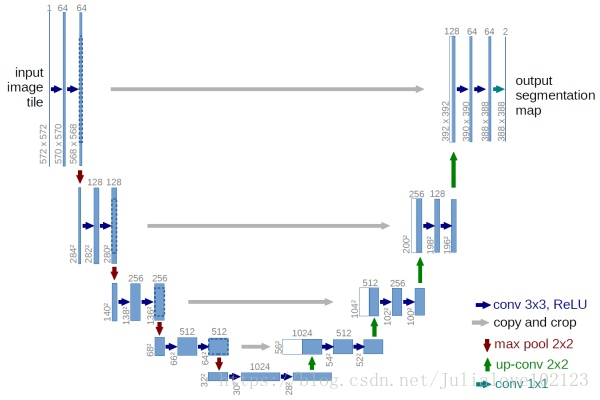
圖9 U-Net網路結構圖
整個U-Net網路結構如圖9,類似於一個大大的U字母:首先進行Conv+Pooling下采樣;然後Deconv反捲積進行上取樣,crop之前的低層feature map,進行融合;然後再次上取樣。重複這個過程,直到獲得輸出388x388x2的feature map,最後經過softmax獲得output segment map。總體來說與FCN思路非常類似。
為何要提起U-Net?是因為U-Net採用了與FCN完全不同的特徵融合方式:拼接!
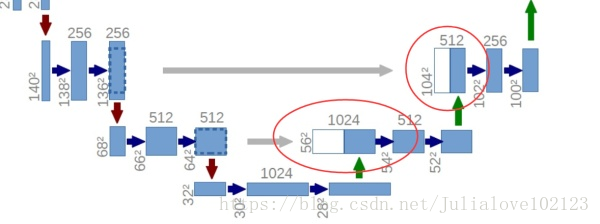
圖10 U-Net concat特徵融合方式
與FCN逐點相加不同,U-Net採用將特徵在channel維度拼接在一起,形成更“厚”的特徵。所以:
語義分割網路在特徵融合時也有2種辦法:
- FCN式的逐點相加,對應caffe的EltwiseLayer層,對應tensorflow的tf.add()
- U-Net式的channel維度拼接融合,對應caffe的ConcatLayer層,對應tensorflow的tf.concat()
綜述介紹
影象語義分割,簡單而言就是給定一張圖片,對圖片上的每一個畫素點分類
從影象上來看,就是我們需要將實際的場景圖分割成下面的分割圖:

不同顏色代表不同類別。經過閱讀“大量”論文和檢視PASCAL VOC Challenge performance evaluation server,發現影象語義分割從深度學習引入這個任務(FCN)到現在而言,一個通用的框架已經大概確定了。即:
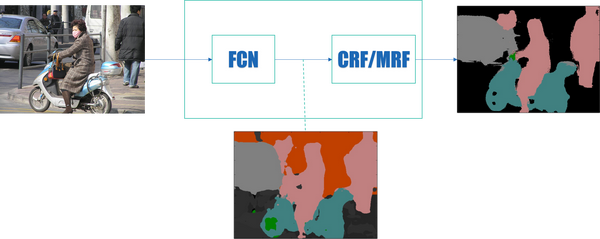
- FCN-全卷積網路
- CRF-條件隨機場
- MRF-馬爾科夫隨機場
前端使用FCN進行特徵粗提取,後端使用CRF/MRF優化前端的輸出,最後得到分割圖。
前端
為什麼需要FCN?
我們分類使用的網路通常會在最後連線幾層全連線層,它會將原來二維的矩陣(圖片)壓扁成一維的,從而丟失了空間資訊,最後訓練輸出一個標量,這就是我們的分類標籤。
而影象語義分割的輸出需要是個分割圖,且不論尺寸大小,但是至少是二維的。所以,我們需要丟棄全連線層,換上全卷積層,而這就是全卷積網路了。具體定義請參看論文:Fully Convolutional Networks for Semantic Segmentation
前端結構
FCN
作者的FCN主要使用了三種技術:
- 卷積化(Convolutional)
- 上取樣(Upsample)
- 跳躍結構(Skip Layer)
卷積化
卷積化即是將普通的分類網路,比如VGG16,ResNet50/101等網路丟棄全連線層,換上對應的卷積層即可。
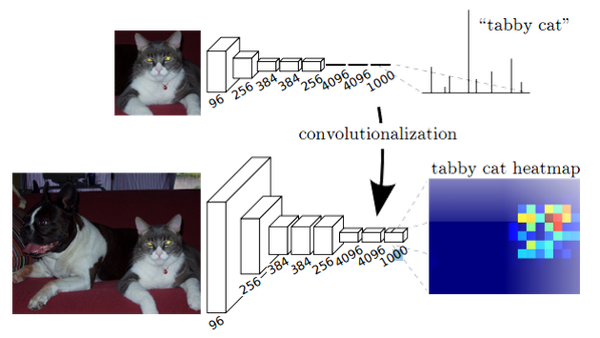
上取樣
此處的上取樣即是反捲積(Deconvolution)。當然關於這個名字不同框架不同,Caffe和Kera裡叫Deconvolution,而tensorflow裡叫conv_transpose。CS231n這門課中說,叫conv_transpose更為合適。
眾所諸知,普通的池化(為什麼這兒是普通的池化請看後文)會縮小圖片的尺寸,比如VGG16 五次池化後圖片被縮小了32倍。為了得到和原圖等大的分割圖,我們需要上取樣/反捲積。
反捲積和卷積類似,都是相乘相加的運算。只不過後者是多對一,前者是一對多。而反捲積的前向和後向傳播,只用顛倒卷積的前後向傳播即可。所以無論優化還是後向傳播演算法都是沒有問題。圖解如下:

但是,雖然文中說是可學習的反捲積,但是作者實際程式碼並沒有讓它學習,可能正是因為這個一對多的邏輯關係。程式碼如下:
layer {
name: "upscore"
type: "Deconvolution"
bottom: "score_fr"
top: "upscore"
param {
lr_mult: 0
}
convolution_param {
num_output: 21
bias_term: false
kernel_size: 64
stride: 32
}
}
可以看到lr_mult被設定為了0.
跳躍結構
(這個奇怪的名字是我翻譯的,好像一般叫忽略連線結構)這個結構的作用就在於優化結果,因為如果將全卷積之後的結果直接上取樣得到的結果是很粗糙的,所以作者將不同池化層的結果進行上取樣之後來優化輸出。具體結構如下:

而不同上取樣結構得到的結果對比如下:

當然,你也可以將pool1, pool2的輸出再上取樣輸出。不過,作者說了這樣得到的結果提升並不大。
這是第一種結構,也是深度學習應用於影象語義分割的開山之作,所以得了CVPR2015的最佳論文。但是,還是有一些處理比較粗糙的地方,具體和後面對比就知道了。
SegNet/DeconvNet
這樣的結構總結在這兒,只是我覺得結構上比較優雅,它得到的結果不一定比上一種好。
SegNet
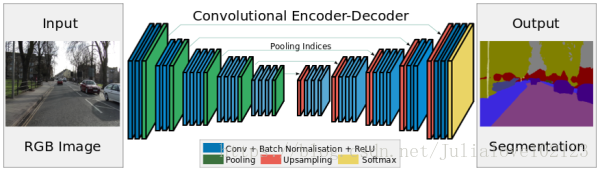
DeconvNet
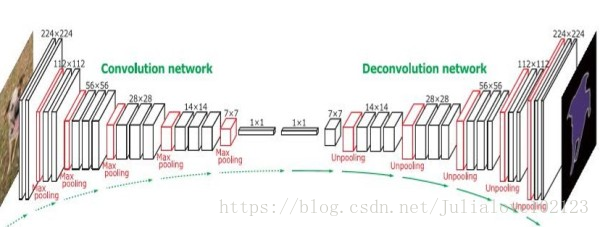
這樣的對稱結構有種自編碼器的感覺在裡面,先編碼再解碼。這樣的結構主要使用了反捲積和上池化。即:


反捲積如上。而上池化的實現主要在於池化時記住輸出值的位置,在上池化時再將這個值填回原來的位置,其他位置填0即OK。
DeepLab
接下來介紹一個很成熟優雅的結構,以至於現在的很多改進是基於這個網路結構的進行的。
首先這裡我們將指出一個第一個結構FCN的粗糙之處:為了保證之後輸出的尺寸不至於太小,FCN的作者在第一層直接對原圖加了100的padding,可想而知,這會引入噪聲。
而怎樣才能保證輸出的尺寸不會太小而又不會產生加100 padding這樣的做法呢?可能有人會說減少池化層不就行了,這樣理論上是可以的,但是這樣直接就改變了原先可用的結構了,而且最重要的一點是就不能用以前的結構引數進行fine-tune了。所以,Deeplab這裡使用了一個非常優雅的做法:將pooling的stride改為1,再加上 1 padding。這樣池化後的圖片尺寸並未減小,並且依然保留了池化整合特徵的特性。
但是,事情還沒完。因為池化層變了,後面的卷積的感受野也對應的改變了,這樣也不能進行fine-tune了。所以,Deeplab提出了一種新的卷積,帶孔的卷積:Atrous Convolution.即:
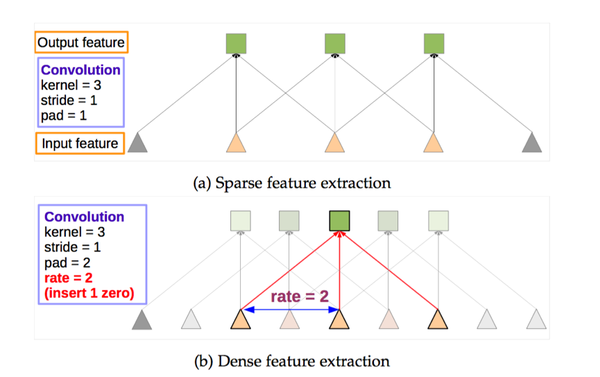
而具體的感受野變化如下:
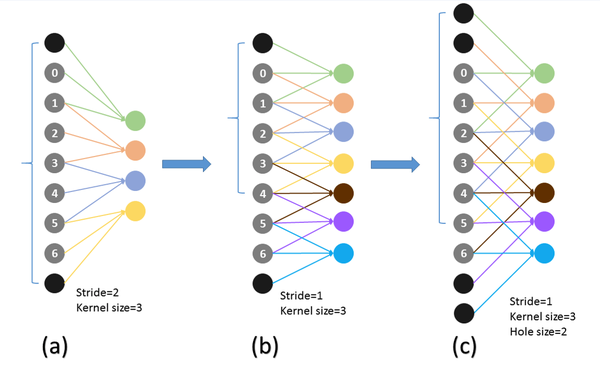 a為普通的池化的結果,b為“優雅”池化的結果。我們設想在a上進行卷積核尺寸為3的普通卷積,則對應的感受野大小為7.而在b上進行同樣的操作,對應的感受野變為了5.感受野減小了。但是如果使用hole為1的Atrous Convolution則感受野依然為7.
a為普通的池化的結果,b為“優雅”池化的結果。我們設想在a上進行卷積核尺寸為3的普通卷積,則對應的感受野大小為7.而在b上進行同樣的操作,對應的感受野變為了5.感受野減小了。但是如果使用hole為1的Atrous Convolution則感受野依然為7.
所以,Atrous Convolution能夠保證這樣的池化後的感受野不變,從而可以fine tune,同時也能保證輸出的結果更加精細。即:
總結
這裡介紹了三種結構:FCN, SegNet/DeconvNet,DeepLab。當然還有一些其他的結構方法,比如有用RNN來做的,還有更有實際意義的weakly-supervised方法等等。
後端
終於到後端了,後端這裡會講幾個場,涉及到一些數學的東西。我的理解也不是特別深刻,所以歡迎吐槽。
全連線條件隨機場(DenseCRF)
對於每個畫素具有類別標籤
還有對應的觀測值
,這樣每個畫素點作為節點,畫素與畫素間的關係作為邊,即構成了一個條件隨機場。而且我們通過觀測變數
來推測畫素
對應的類別標籤
。條件隨機場如下:
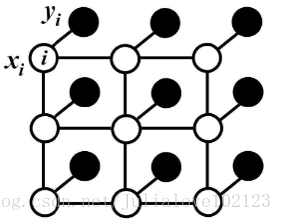
條件隨機場符合吉布斯分佈:(此處的即上面說的觀測值)
其中的是能量函式,為了簡便,以下省略全域性觀測
:
其中的一元勢函式即來自於前端FCN的輸出。而二元勢函式如下:
二元勢函式就是描述畫素點與畫素點之間的關係,鼓勵相似畫素分配相同的標籤,而相差較大的畫素分配不同標籤,而這個“距離”的定義與顏色值和實際相對距離有關。所以這樣CRF能夠使圖片儘量在邊界處分割。
而全連線條件隨機場的不同就在於,二元勢函式描述的是每一個畫素與其他所有畫素的關係,所以叫“全連線”。
關於這一堆公式大家隨意理解一下吧... ...而直接計算這些公式是比較麻煩的(我想也麻煩),所以一般會使用平均場近似方法進行計算。而平均場近似又是一堆公式,這裡我就不給出了(我想大家也不太願意看),願意瞭解的同學直接看論文吧。
CRFasRNN
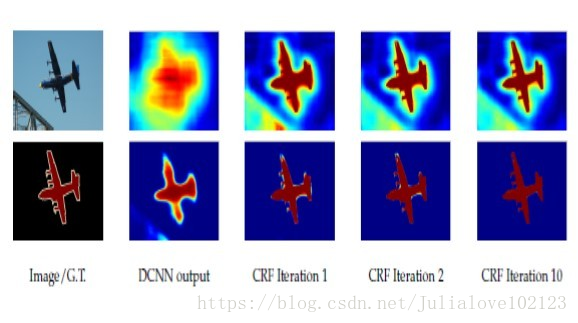
最開始使用DenseCRF是直接加在FCN的輸出後面,可想這樣是比較粗糙的。而且在深度學習中,我們都追求end-to-end的系統,所以CRFasRNN這篇文章將DenseCRF真正結合進了FCN中。
這篇文章也使用了平均場近似的方法,因為分解的每一步都是一些相乘相加的計算,和普通的加減(具體公式還是看論文吧),所以可以方便的把每一步描述成一層類似卷積的計算。這樣即可結合進神經網路中,並且前後向傳播也不存在問題。
當然,這裡作者還將它進行了迭代,不同次數的迭代得到的結果優化程度也不同(一般取10以內的迭代次數),所以文章才說是as RNN。優化結果如下:
馬爾科夫隨機場(MRF)
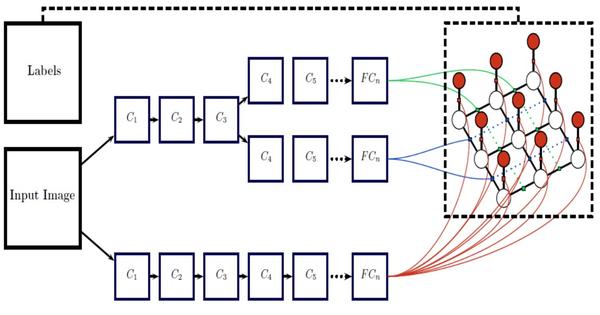
在Deep Parsing Network中使用的是MRF,它的公式具體的定義和CRF類似,只不過作者對二元勢函式進行了修改:
其中,作者加入的為label context,因為
只是定義了兩個畫素同時出現的頻率,而
可以對一些情況進行懲罰,比如,人可能在桌子旁邊,但是在桌子下面的可能性就更小一些。所以這個量可以學習不同情況出現的概率。而原來的距離
只定義了兩個畫素間的關係,作者在這兒加入了個triple penalty,即還引入了
附近的
,這樣描述三方關係便於得到更充足的區域性上下文。具體結構如下:

這個結構的優點在於:
- 將平均場構造成了CNN
- 聯合訓練並且可以one-pass inference,而不用迭代
高斯條件隨機場(G-CRF)
這個結構使用CNN分別來學習一元勢函式和二元勢函式。這樣的結構是我們更喜歡的:
而此中的能量函式又不同於之前:
而當是對稱正定時,求
的最小值等於求解:
而G-CRF的優點在於:
- 二次能量有明確全域性
- 解線性簡便很多
感悟
- FCN更像一種技巧。隨著基本網路(如VGG, ResNet)效能的提升而不斷進步。
- 深度學習+概率圖模型(PGM)是一種趨勢。其實DL說白了就是進行特徵提取,而PGM能夠從數學理論很好的解釋事物本質間的聯絡。
- 概率圖模型的網路化。因為PGM通常不太方便加入DL的模型中,將PGM網路化後能夠是PGM引數自學習,同時構成end-to-end的系統。
完結撒花
引用
影象分割 (Image Segmentation) 重大資源:
入門學習
進階論文
綜述
- A Review on Deep Learning Techniques Applied to Semantic Segmentation Alberto Garcia-Garcia, Sergio Orts-Escolano, Sergiu Oprea, Victor Villena-Martinez, Jose Garcia-Rodriguez 2017
- Computer Vision for Autonomous Vehicles: Problems, Datasets and State-of-the-Art
Tutorial
視訊教程
- CS231n: Convolutional Neural Networks for Visual Recognition Lecture 11 Detection and Segmentation
- Machine Learning for Semantic Segmentation - Basics of Modern Image Analysis
程式碼
Semantic segmentation
Instance aware segmentation
Satellite images segmentation
Video segmentation
Autonomous driving
Annotation Tools: