
Stanford CS231n 2017春季課程
斯坦福大學的 CS231n(全稱:面向視覺識別的卷積神經網路)一直是計算機視覺和深度學習領域的經典課程,每年開課都吸引很多學生。今年是該課程第3次開課,學生達到730人(第1次150人,第2次350人)。今年的CS231n Spring的instructors 是李飛飛、Justin Johnson和Serena Yeung,並邀請 Ian Goodfellow 等人講解GAN等重要主題。最近斯坦福大學公開了該課程的全部視訊(配備英文)、slides等全部課程資料,新智元帶來介紹。
全部課程視訊(英文字幕):http://t.cn/R9Dfnxn
所有課程資料、PPT等:http://cs231n.stanford.edu/syllabus.html
課程描述
計算機視覺在我們的社會中已經無處不在,例如應用於搜尋、影象理解、apps、地圖、醫療、無人機、自動駕駛汽車,等等。大部分應用的核心是視覺識別任務,例如影象分類、定位和檢測。神經網路(又稱“深度學習”)方法最新的進展大大提高了這些最先進的視覺識別系統的效能。本課程將帶大家深入瞭解深度學習的架構,重點是學習這些任務,尤其是影象分類任務的端到端模型。
在為期10周的課程中,同學們將要學習實現、訓練和除錯自己的神經網路,並深入瞭解計算機視覺的最前沿的研究。期末作業將涉及訓練一個數百萬引數的卷積神經網路,並將其應用於最大的影象分類資料集(ImageNet)。我們將重點介紹如何建立影象識別問題,學習演算法(例如反向傳播演算法),訓練和微調網路的實用工程技巧,引導學生進行實際操作和最終的課程專案。本課程的背景知識和材料的大部分來自 ImageNet 挑戰賽。
先修要求
-
熟練使用Python,C / C ++高階熟悉所有的類分配都將使用Python(並使用numpy)(我們為那些不熟悉Python的人提供了一個教程),但是一些深入學習的庫 我們可以看看後面的類是用C ++編寫的。 如果你有很多的程式設計經驗,但使用不同的語言(例如C / C ++ / Matlab / Java),你可能會很好。
-
大學微積分,線性代數(例如MATH 19或41,MATH 51)您應該很樂意使用衍生詞和理解矩陣向量運算和符號。
-
基本概率和統計學(例如CS 109或其他統計學課程)您應該知道概率的基礎知識,高斯分佈,平均值,標準偏差等。
-
CS229(機器學習)的等效知識我們將制定成本函式,採用導數和梯度下降執行優化。
課程 Notes:
課程Notes: http://cs231n.github.io/
模組0:準備內容
Python / Numpy 教程
IPython Notebook 教程
Google Cloud 教程
Google Cloud with GPU教程
AWS 教程
模組1:神經網路
-
影象分類:資料驅動的方法,k最近鄰法,train/val/test splits
L1 / L2距離,超引數搜尋,交叉驗證
-
線性分類:支援向量機,Softmax
引數化方法,bias技巧,hinge loss,交叉熵損失,L2正則化,web demo
-
優化:隨機梯度下降
本地搜尋,學習率,分析/數值梯度
-
反向傳播,直覺
鏈規則解釋,real-valued circuits,gradient flow中的模式
-
神經網路第1部分:建立架構
生物神經元模型,啟用函式,神經網路架構
-
神經網路第2部分:設定資料和損失
預處理,權重初始化,批量歸一化,正則化(L2 /dropout),損失函式
-
神經網路第3部分:學習和評估
梯度檢查,完整性檢查,動量(+ nesterov),二階方法,Adagrad / RMSprop,超引數優化,模型集合
-
把它放在一起:一個神經網路案例研究
極小2D玩具資料示例
模組2:卷積神經網路
-
卷積神經網路:架構,卷積/池化層
層,空間排列,層模式,層大小模式,AlexNet / ZFNet / VGGNet案例研究,計算考慮
-
理解和視覺化卷積神經網路
tSNE嵌入,deconvnets,資料梯度,fooling ConvNets,human comparisons
-
遷移學習和微調卷積神經網路
內容簡介
Lecture 1:面向視覺識別的卷積神經網路課程簡介

Lecture 1介紹了計算機視覺這一領域,討論了其歷史和關鍵性挑戰。我們強調,計算機視覺涵蓋各種各樣的不同任務,儘管近期深度學習方法取得了一些成功,但我們仍然遠遠未能實現人類水平的視覺智慧的目標。
關鍵詞:計算機視覺,寒武紀爆炸,暗箱,Hubel 和 Wiesel,積木塊世界,規範化切割,人臉檢測,SIFT,空間金字塔匹配,定向梯度直方圖,PASCAL視覺物件挑戰賽,ImageNet挑戰賽
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture1.pdf
————————————————————————————————————————————————————————
Lecture 2:影象分類

Lecture 2 使影象分類問題正式化。我們討論了影象分類問題本身的難點,並介紹了資料驅動(data-driven)方法。我們討論了兩個簡單的資料驅動影象分類演算法:K-最近鄰法(K-Nearest Neighbors)和線性分類(Linear Classifiers)方法,並介紹了超引數和交叉驗證的概念。
關鍵詞:影象分類,K最近鄰,距離度量,超引數,交叉驗證,線性分類器
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture2.pdf
————————————————————————————————————————————————————————
Lecture 3:損失函式和最優化

Lecture 3 繼續討論線性分類器。我們介紹了損失函式的概念,並討論影象分類的兩個常用的損失函式:多類SVM損失(multiclass SVM loss)和多項邏輯迴歸損失(multinomial logistic regression loss)。我們還介紹了正規化(regularization ),作為對付過擬合的機制,以及將權重衰減(weight decay )作為一個具體的例子。 我們還介紹了優化(optimization)的概念和隨機梯度下降(stochastic gradient descent )演算法。我們還簡要討論了計算機視覺特徵表示(feature representation)的使用。
關鍵詞:影象分類,線性分類器,SVM損失,正則化,多項邏輯迴歸,優化,隨機梯度下降
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture3.pdf
————————————————————————————————————————————————————————
Lecture 4:神經網路介紹

在 Lecture 4 中,我們從線性分類器進展到全連線神經網路(fully-connected neural network)。本節介紹了計算梯度的反向傳播演算法(backpropagation algorithm),並簡要討論了人工神經網路與生物神經網路之間的關係。
關鍵詞:神經網路,計算圖,反向傳播,啟用函式,生物神經元
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture4.pdf
————————————————————————————————————————————————————————
Lecture 5:卷積神經網路

在 Lecture 5 中,我們從完全連線的神經網路轉向卷積神經網路。我們將討論卷積網路發展中的一些關鍵的歷史里程碑,包括感知器,新認知機(neocognitron),LeNet 和 AlexNet。我們將介紹卷積(convolution),池化(pooling)和完全連線(fully-connected)層,這些構成了現代卷積網路的基礎。
關鍵詞:卷積神經網路,感知器,neocognitron,LeNet,AlexNet,卷積,池化,完全連線層
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture5.pdf
————————————————————————————————————————————————————————
Lecture 6:訓練神經網路1

在Lecture 6中,我們討論了現代神經網路的訓練中的許多實際問題。我們討論了不同的啟用函式,資料預處理、權重初始化以及批量歸一化的重要性; 我們還介紹了監控學習過程和選擇超引數的一些策略。
關鍵詞:啟用函式,資料預處理,權重初始化,批量歸一化,超引數搜尋
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture6.pdf
————————————————————————————————————————————————————————
Lecture 7:訓練神經網路2

Lecture 7繼續討論訓練神經網路中的實際問題。我們討論了在訓練期間優化神經網路的不同更新規則和正則化大型神經網路的策略(包括dropout)。我們還討論轉移學習(transfer learnin)和 fine-tuning。
關鍵詞:優化,動量,Nesterov動量,AdaGrad,RMSProp,Adam,二階優化,L-BFGS,集合,正則化,dropout,資料擴張,遷移學習,fine-tuning
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture7.pdf
————————————————————————————————————————————————————————
Lecture 8:深度學習軟體

Lecture 8 討論瞭如何使用不同的軟體包進行深度學習,重點介紹 TensorFlow 和 PyTorch。我們還討論了CPU和GPU之間的一些區別。
關鍵詞:CPU vs GPU,TensorFlow,Keras,Theano,Torch,PyTorch,Caffe,Caffe2,動態計算圖與靜態計算圖
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture8.pdf
————————————————————————————————————————————————————————
Lecture 9:CNN架構

Lecture 9 討論了卷積神經網路的一些常見架構。我們討論了 ImageNet 挑戰賽中表現很好的一些架構,包括AlexNet,VGGNet,GoogLeNet 和 ResNet,以及其他一些有趣的模型。
關鍵詞:AlexNet,VGGNet,GoogLeNet,ResNet,Network in Network,Wide ResNet,ResNeXT,隨機深度,DenseNet,FractalNet,SqueezeNet
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture9.pdf
————————————————————————————————————————————————————————
Lecture 10:迴圈神經網路
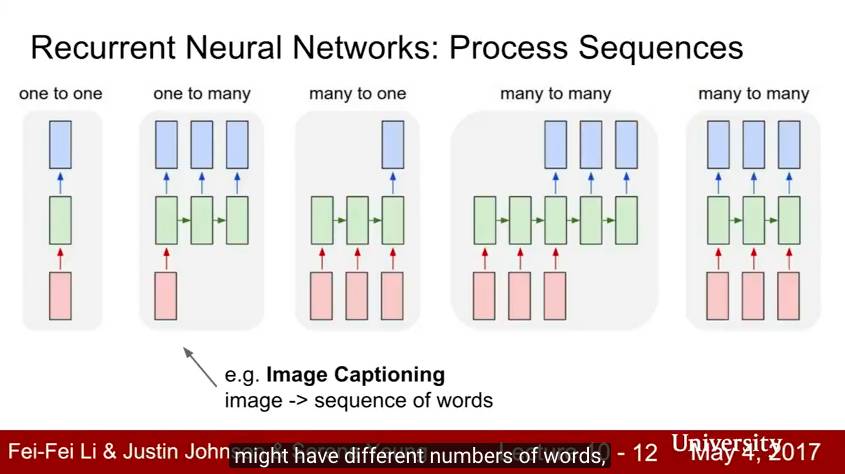
Lecture 10討論瞭如何使用迴圈神經網路為序列資料建模。我們展示瞭如何將迴圈神經網路用於語言建模和影象字幕,以及如何將 soft spatial attention 納入影象字幕模型中。我們討論了迴圈神經網路的不同架構,包括長短期記憶(LSTM)和門迴圈單元(GRU)。
關鍵詞:迴圈神經網路,RNN,語言建模,影象字幕, soft attention,LSTM,GRU
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture10.pdf
————————————————————————————————————————————————————————
Lecture 11:檢測和分割

在Lecture 11中,我們超越了影象分類,展示瞭如何將卷積網路應用於其他計算機視覺任務。我們展示了具有下采樣和上取樣層的完全卷積網路可以怎樣用於語義分割,以及多工損失如何用於定位和姿態估計。我們討論了一些物件檢測方法,包括基於區域的R-CNN系列方法和 single-shot 方法,例如SSD和YOLO。最後,我們展示瞭如何將來自語義分割和物件檢測的想法結合起來進行例項分割( instance segmentation)。
關鍵詞:語義分割,完全卷積網路,unpooling,轉置卷積(transpose convolution),localization,多工損失,姿態估計,物件檢測,sliding window,region proposals,R-CNN,Fast R-CNN,Faster R-CNN,YOLO,SSD,DenseCap ,例項分割,Mask R-CNN
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
————————————————————————————————————————————————————————
Lecture 12:視覺化和理解

Lecture 12討論了視覺化和理解卷積網路內部機制的方法。我們還討論瞭如何使用卷積網路來生成新的影象,包括DeepDream和藝術風格遷移。
關鍵詞:視覺化,t-SNE,saliency maps,class visualizations,fooling images, feature inversion,DeepDream,風格遷移
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture12.pdf
————————————————————————————————————————————————————————
Lecture 13:生成模型
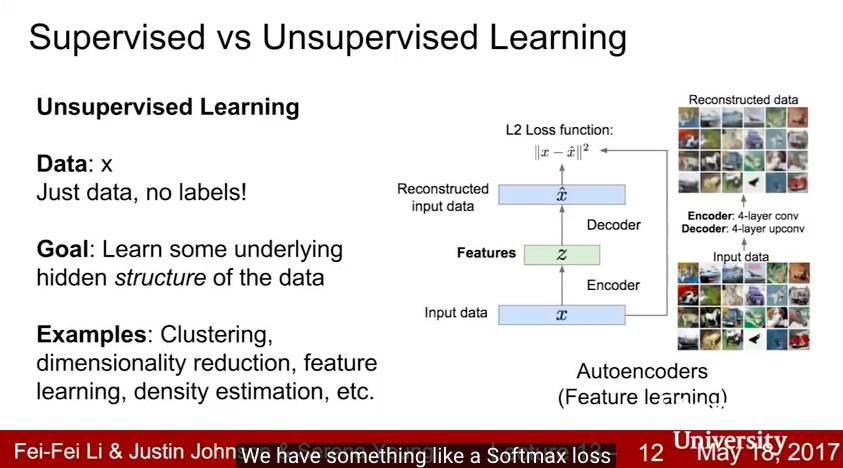
在Lecture 13中,我們超越了監督學習,並將生成模型作為一種無監督學習的形式進行討論。我們涵蓋了自迴歸的 PixelRNN 和 PixelCNN 模型,傳統和變分自編碼器(VAE)和生成對抗網路(GAN)。
關鍵詞:生成模型,PixelRNN,PixelCNN,自編碼器,變分自編碼器,VAE,生成對抗網路,GAN
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture13.pdf
————————————————————————————————————————————————————————
Lecture 14:深度強化學習

在Lecture 14中,我們從監督學習轉向強化學習(RL)。強化學習中,智慧體必須學會與環境互動,才能最大限度地得到獎勵。 我們使用馬爾科夫決策過程(MDPs),策略,價值函式和Q函式的語言來形式化強化學習。我們討論了強化學習的不同演算法,包括Q-Learning,策略梯度和Actor-Critic。我們展示了強化學習被用於玩 Atari 遊戲,AlphaGo在圍棋中超過人類專業棋手等。
關鍵詞:強化學習,RL,馬爾科夫決策過程,MDP,Q-Learning,政策梯度,REINFORCE,actor-critic, Atari 遊戲,AlphaGo
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture14.pdf
————————————————————————————————————————————————————————
Lecture 15:深度學習的高效方法和硬體

在Lecture 15中,客座講師 Song Han 討論了可用於加快深度學習工作負載訓練和推理的演算法和專用硬體。我們討論了剪枝,weight sharing,量化等技術,以及其他加速推理過程的技術,包括並行化,混合精度(mixed precision)等。我們討論了用於深度學習的專門硬體,例如GPU,FPGA 和 ASIC,包括NVIDIA最新Volta GPU中的Tensor Core,以及谷歌的TPU(Tensor Processing Units)。
關鍵詞:硬體,CPU,GPU,ASIC,FPGA,剪枝,權重共享,量化,二元網路,三元網路,Winograd變換,EIE,資料並行,模型並行,混合精度,FP16,FP32,model distillation,Dense-Sparse-Dense訓練,NVIDIA Volta,Tensor Core,Google TPU,Google Cloud TPU
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture15.pdf
————————————————————————————————————————————————————————
Lecture 16:對抗樣本和對抗訓練

Lecture 16由客座講師Ian Goodfellow主講,討論了深度學習中的對抗樣本(Adversarial Examples)。本講討論了為什麼深度網路和其他機器學習模型容易受到對抗樣本的影響,以及如何使用對抗樣本來攻擊機器學習系統。我們討論了針對對抗樣本的潛在防禦,以及即使在沒有明確的對手的情況下,如何用對抗樣本來改進機器學習系統,。
關鍵詞:對抗樣本,Fooling images,fast gradient sign method(FGSM),Clever Hans,對抗防禦,物理世界中的對抗樣本,對抗訓練,虛擬對抗訓練,基於模型的優化
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture16.pdf