
Stanford CS231n Notes
一、文章來由
二、cs231n 課程
第二講:資料驅動的影象分類方式:K最近鄰與線性分類器
(1)經典影象識別演算法不可擴充套件,data-driven的方式更科學
早期沒有使用的原因是早期沒有這麼多data,訓練的模型是一個類
(2)nearest neighbor classifier
記住所有training images和他們的label,找一個最相近的label
這種方法簡單,但是應用時效率低
CNN相對於這個方法反過來,不論訓練資料多少,分類時間都是固定的
KNN是nearest neighbor classifier的一種,找到最近K個images,have them vote on the label
5個最近點,分界線變得平滑
超引數:
1)最好的距離選取標準
2)k如何選
(3)5折理論
將所有data5折,其中一折用於超引數的設定
迴圈驗證,選取不同的折來設定超參
(4)線性分類器
類似於filter或者模板
f = Wx+b
將x展平,相乘於W,再加上b
所有的分數都是所有畫素點值的加權和
W和b要訓練出來
(5)為了定量選擇的模型或者權值,定義了loss函式
為了讓loss函式最小化
第三講: 線性分類器損失函式與最優化
(1)計算loss,採用multiclass SVM loss
相當於單個相減,然後加安全係數1(可以是任意正數),hinge loss

full training loss就是在其上除以總數

程式碼實現

但這個裡面有一個bug
如果double每個值,其實結果沒有影響,但是會使資料間的差值越來越大
(2)正則化,給每個數字的權值儘量平均
分散權值

(3)softmax classifier

(4)不同的loss函式的比較
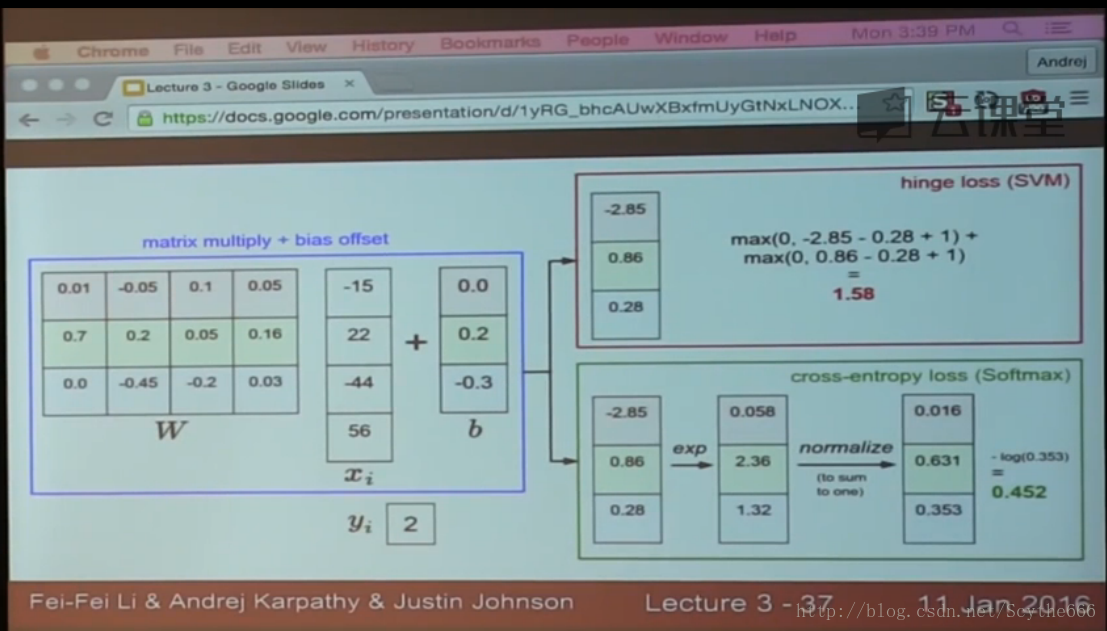
最大化log概率比直接最大化概率好
最大不同:
SVM比softmax穩定,就算slightly提高值也不會變化(前提條件是誤分類評分小於正確評分減一),softmax不然,將所有樣本點納入考量

(5)梯度下降法
計算複雜,且如果引數很多的時候,每個都要計算不太可能
用微積分求解
要檢查,寫起來簡單
並不是全部資料,而是抽樣
SGD是一種常用的更新W的方法
(6)經典方法是用 特徵+線性分類器 的方法
比如顏色直方圖+hog邊緣特徵,這樣線性分類器就有辦法處理,通常是將一幅圖人為拆分成多個特徵的組合
=== 某種程度上的統計特徵
傳統方法 vs 深度學習

第四講:反向傳播與神經網路初步
1、求偏導
反向傳播
在正向計算的時候,每個引數就能夠把其對最後的結果偏導公式計算出來
導數的意義是,因變數的增量與自變數增量的比值

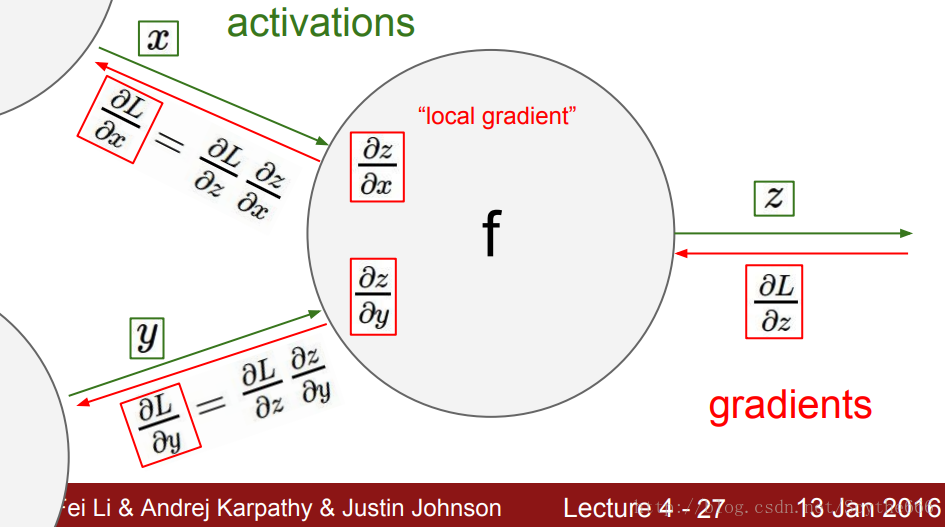

正向和反向傳播的時間差不多相同。
2、反向傳播門的性質
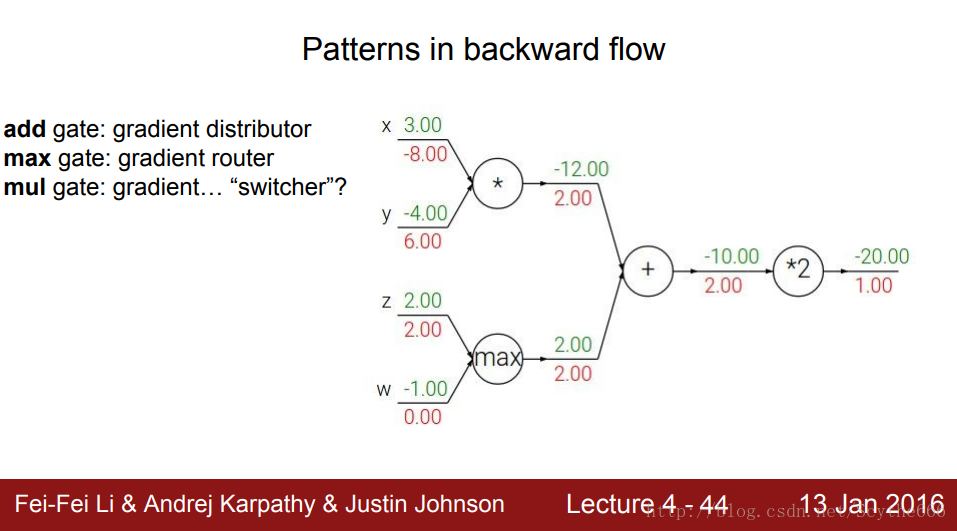
加法門:梯度分配器,將梯度分配到前面的門
max門:梯度路由,將最大梯度放入路由,反向傳播的時候只分配給最大的那個(因為不是最大的,對結果產生不了影響)
乘法門:梯度開關
沒有迴路
3、正向傳播與反向傳播
1、總結前饋和反饋
對於每次更新,都要進行一次完整的前饋與反饋:
前饋計算loss,反饋計算梯度,update在負權值上權值微調
雅可比矩陣是一階偏導組成的矩陣
特殊情況下,不必計算雅可比行列式所有值
每一層之間都是通過矩陣連線
2、神經網路
隱含層可以有多個數,自己定義
隱含層引入多樣化
換算成公式太複雜,反向傳播簡化計算
每個單個的neuron都可以看作一個線性分類器
各種啟用函式

relu會讓神經網路快很多,預設啟用函式首選
算神經網路的層數是算有權值的層數
正則化係數越低,擬合程度越高,也越容易過擬合
幾條線就大概是幾條邊界,所以對於circle data來說,3條就好
三條邊的組合,第二層只是把這些組合拼在一起
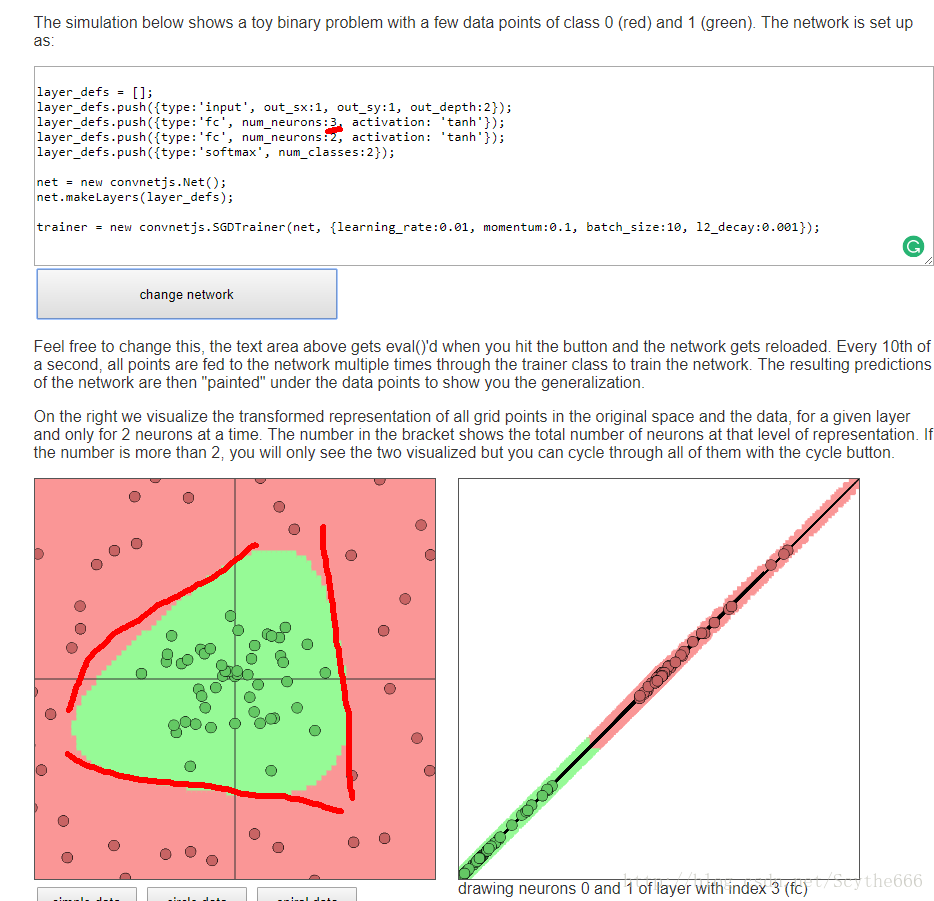
網路中的neuron越多越好,但是要選擇合適的正則化項,而不是減少neuron,但可能有沒時間訓練等因素,所以選用更小的network
如果網路很小,有一種網路優化演算法L-BFGS,mini-batch好用,通常用不上
對於更深還是更寬也沒有一個確定的答案,對於圖片來說,層數更重要
對於其他問題,是data相關的
不同層用不同的啟用函式
通常不會這樣做,通常是選一個啟用函式,整個網路都用,不同層中換不同啟用函式一般並沒有什麼好處
第五講:神經網路訓練細節
講述步驟

激勵函式
(1)sigmoid function

梯度消失問題
問題很多,飽和的神經元要麼非常接近0,要不非常接近1
—>反向的時候,梯度趨於0
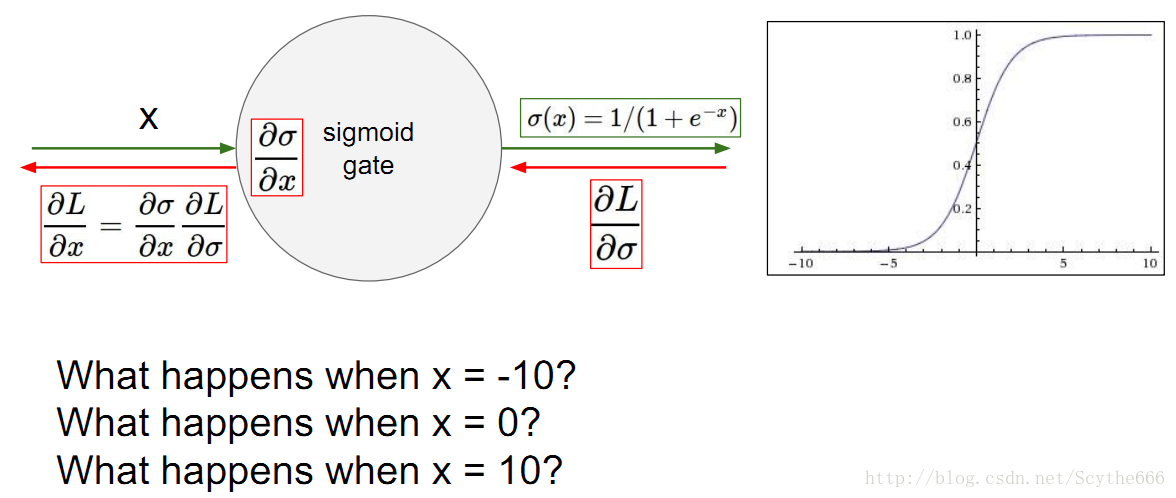
問題1:local梯度很小
只在sigmoid的啟用區域才會有用
問題2:
不關於原點中心對稱,輸出值都在0,1之間
w的梯度要麼全正要麼全負,收斂速度很慢
問題3:
exp()耗時
但在rnn中用到,因為特殊原因
(2)tanh(x)

(3)ReLU

網路收斂速度快,之前的6倍
問題:不中心對稱
如果ReLU從未被啟用,那反向的時候就會梯度消失,不啟用就不能進行反向傳播(不更新權值,可以說什麼都不做)
如果激活了,因為區域性梯度是1,所以都是將梯度傳遞給前面的
如果在x為0的時候,梯度未定義,隨便選一個對結果也不會有很大影響
dead relu問題:
永遠不啟用,也不更新
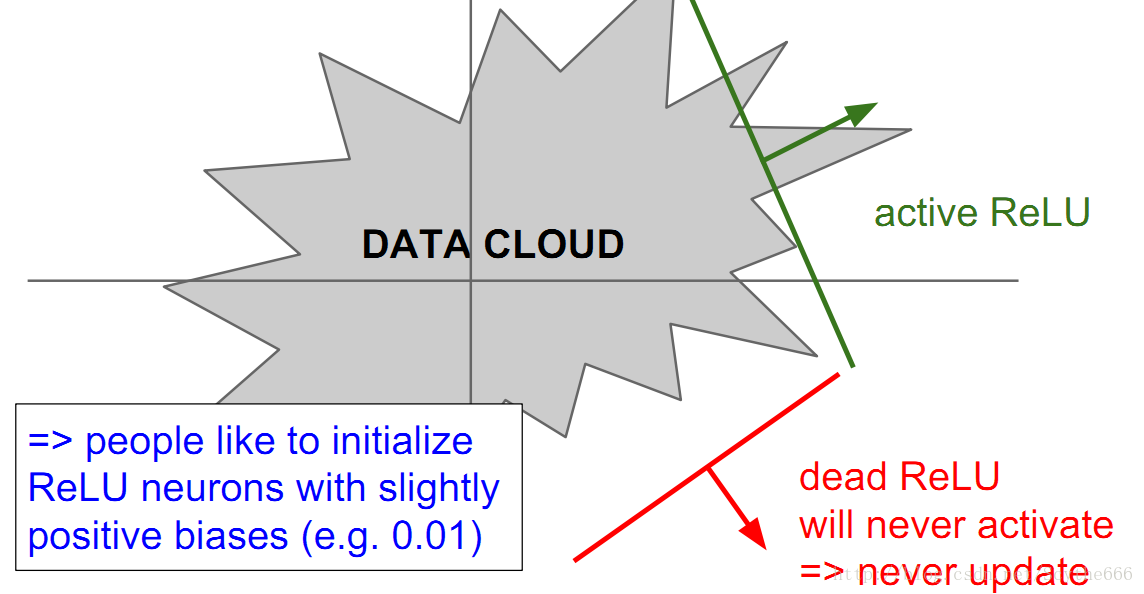
學習率過高也會出現這個問題
解決方法:可以給一個小的bias,重新啟用已死的神經元,但是講者認為這個方法沒什麼用
(3)Leaky ReLU

也不一定是0.01,可以是任意值,這個α可以被學習,反饋學到
計算圖中的每個神經元都有α,可以通過學習學到
還是relu最常用
(4)ELU
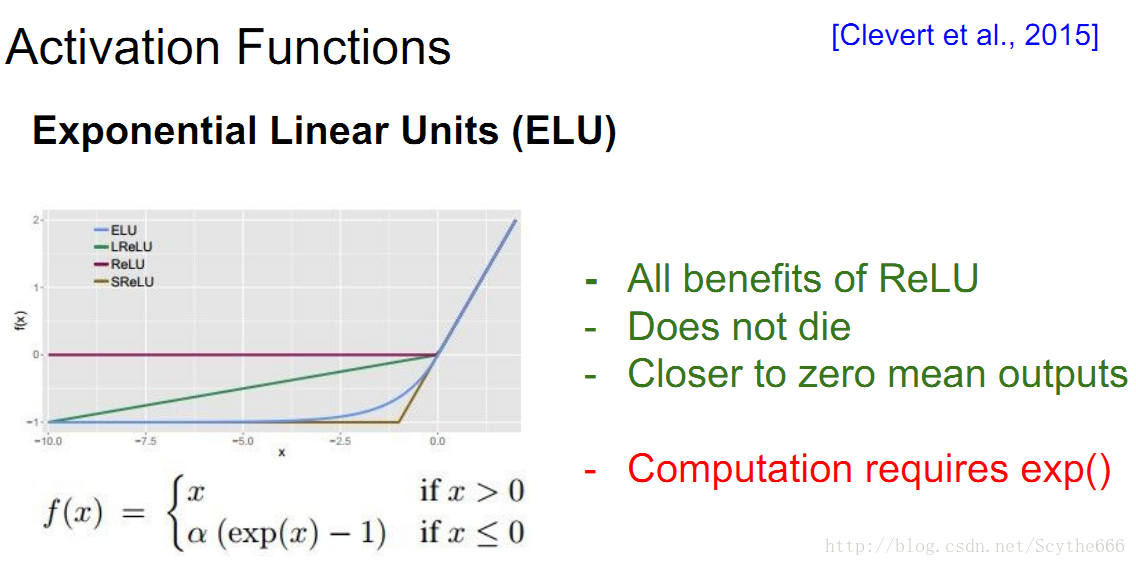
(5)maxout

資料處理
PPT中介紹了很多資料處理方法,但在影象處理中歸一化不常用,但0中心化應用很多,均值中心化

每個畫素減去均值image或者減去per channel 均值,後者更常用
權重初始化
過去人們常用全0初始化,但是效果不好,因為所有神經元的計算完全相同,反向的時候梯度也相同。最好採用隨機小值。
如果初始化不好,很可能飽和,反向不了
策略也已經有了,2010年提出的Glorot提出的Xavier初始化
但是這個用於tanh,不用於relu
但新發論文引入因數2
但這就是一個data-driven的活,不同批資料效果不同
還有方法是通過一個公式,能夠將資料高斯分佈化

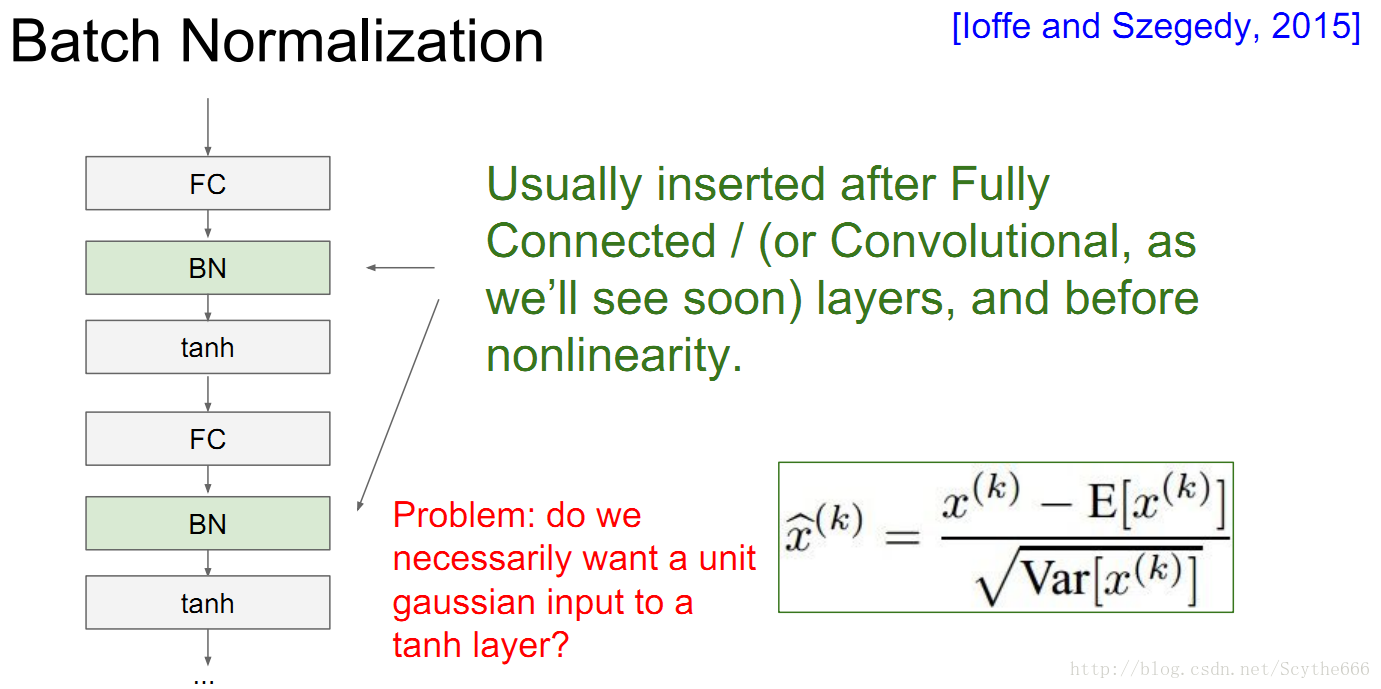
BN有很多優點,如下:

代替了一部分正則化的工作
Note: at test time BatchNorm layer
functions differently:
The mean/std are not computed
based on the batch. Instead, a single
fixed empirical mean of activations
during training is used.
(e.g. can be estimated during training
with running averages)
會稍稍延長一點時間
Babysitting the Learning Process
正確性檢查,非常重要
為了確保神經網路工作正常:
step1:初始化2層神經網路,weights和bias用最簡單的初始值
step2:two_layer_net那句是train這個網路,最重要的是關注要返回的loss和梯度,講者取消了正則化,以確保損失值正確
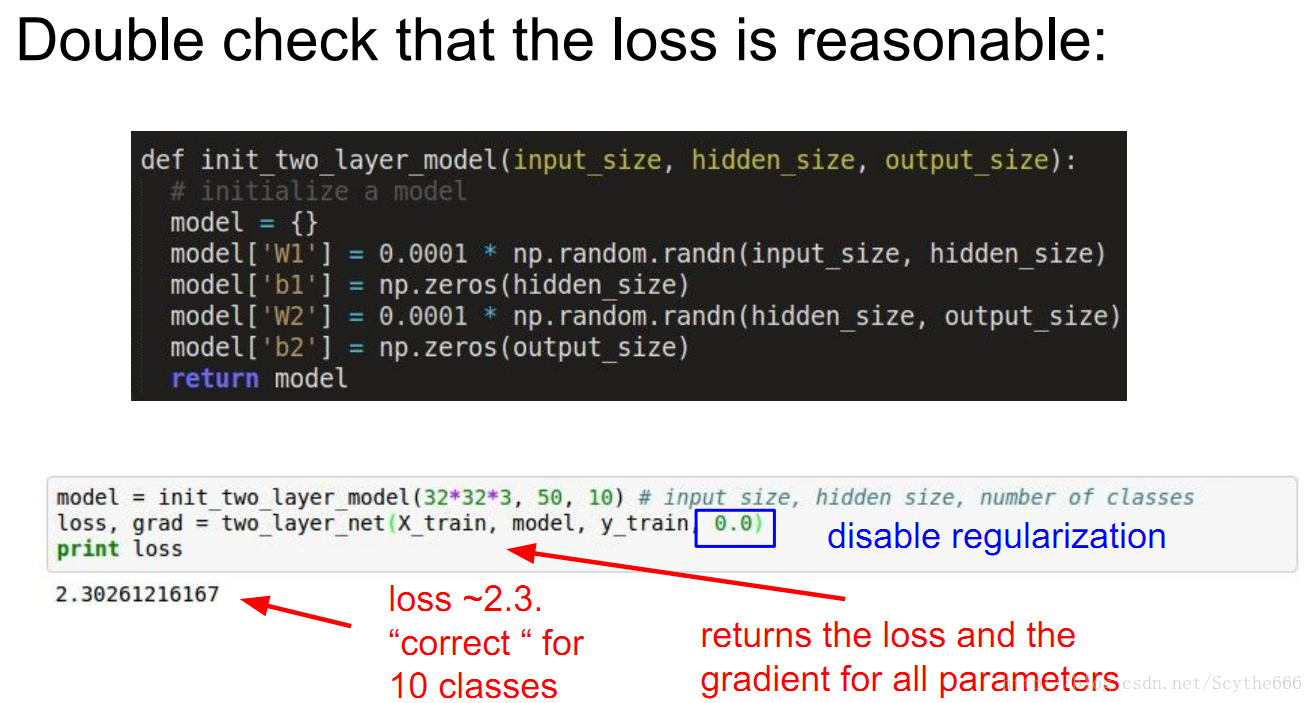
step3:估算,softmax是-log(1/10)
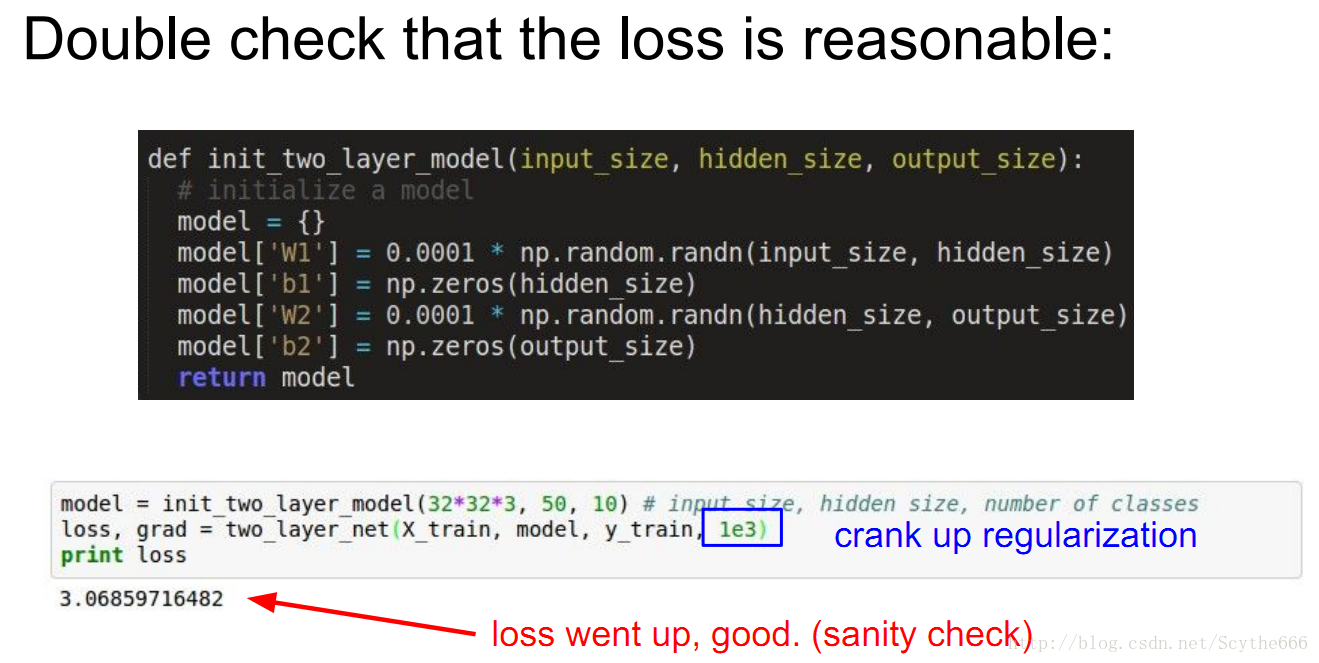
step4:對於小資料,能夠達到過飽和說明具有合理性(反向傳播+update+學習率OK,演算法沒有大問題),然後才考慮增大訓練集。所以不應該擴大訓練集直到完全通過測試。
step5:擴大訓練集,在找到好的learning rate,從小的learning rate開始
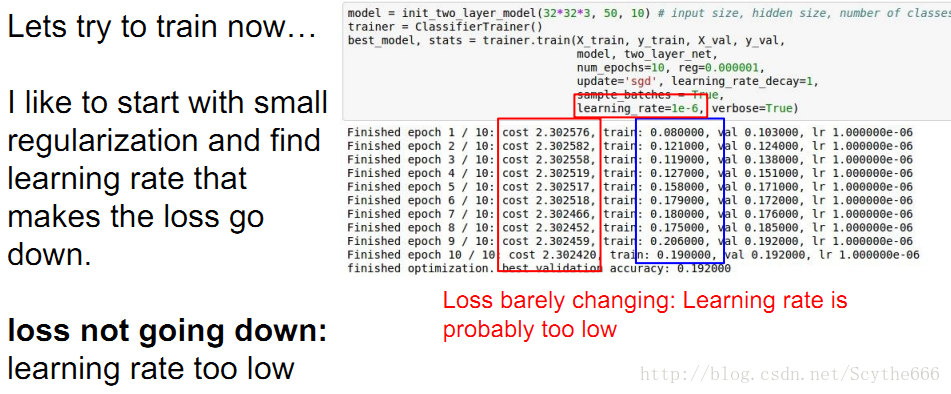
learning rate太小的情況,這種假設是要建立在完成了正確性檢查之後,因為檢查無誤才能大膽判斷
但如果rate太大,cost就爆炸了
cost: NaN almost
always means high
learning rate…
超引數優化
粗糙—>精細的過程
超引數優化要隨機取樣超引數,網格取比隨機取差
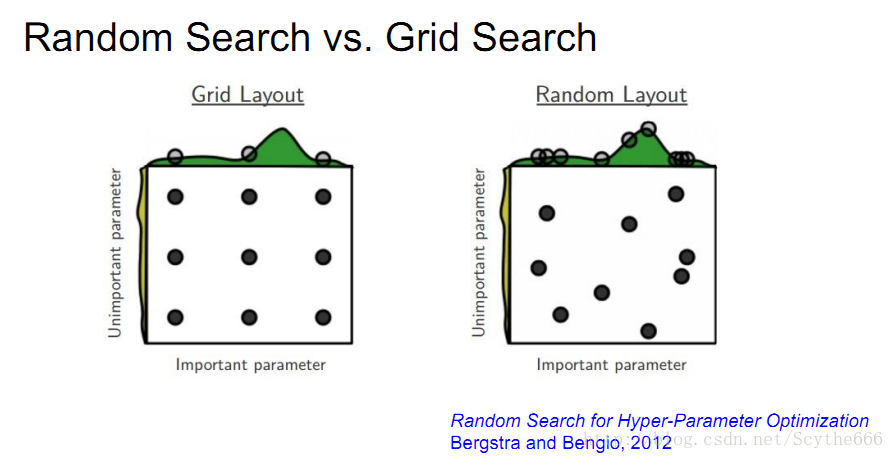
一些可優化的超參

學會解讀不同的圖形
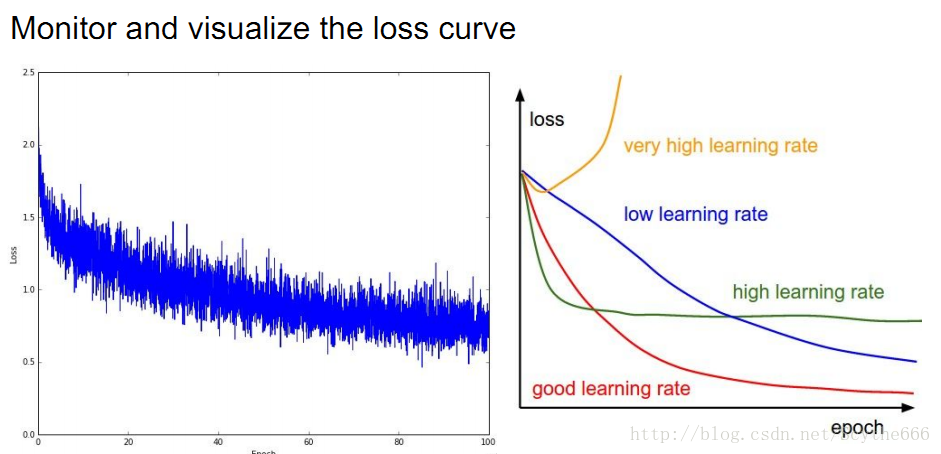
也要關注一些其他的引數,比如準確率
總結:

下節課繼續:

第六講:神經網路訓練細節 part2
如何訓練神經網路
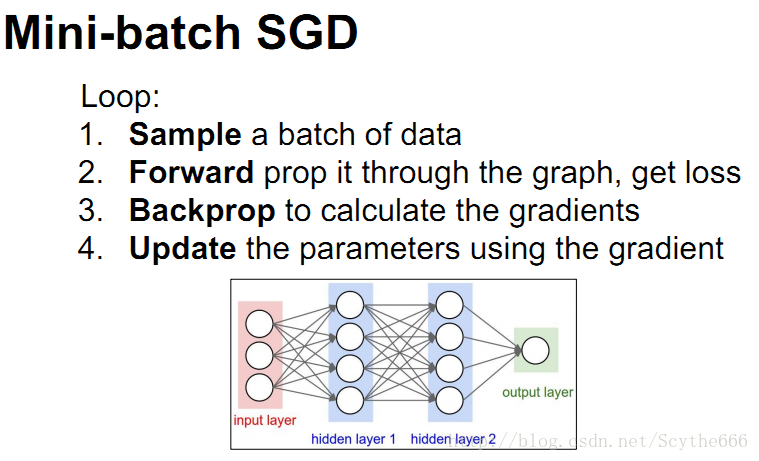
為什麼要用啟用函式?
答:如果不用,不論多少層,如上圖,也只是一個三層的三明治,還是相當於一個線性分類器,使用線性分類器記憶data
如果初始權重太小,在網路中activate,權值更新就會趨於0;如果太大,就會梯度爆炸
—>那麼將會以超飽和的網路或者全0結束
–>選擇一個合理的初始化範圍很重要
batch normalization減輕初始化權重設定的麻煩

dx是梯度
原來只是用簡單的梯度與learning rate相乘,現在要更復雜一點
對於gsd,在豎直方向上比較快,在水平方向上比較慢,所以會震盪,有一種方法就是用momentum方法

mu在0與1之間,通常取0.5~0.9
v通常初始化為0
不同引數更新方法
(1)nesterov momentum

original的方法是建立了一個actual向量,但是現在要做的是想一步超前,計算下一步的梯度,會有一點點的不同
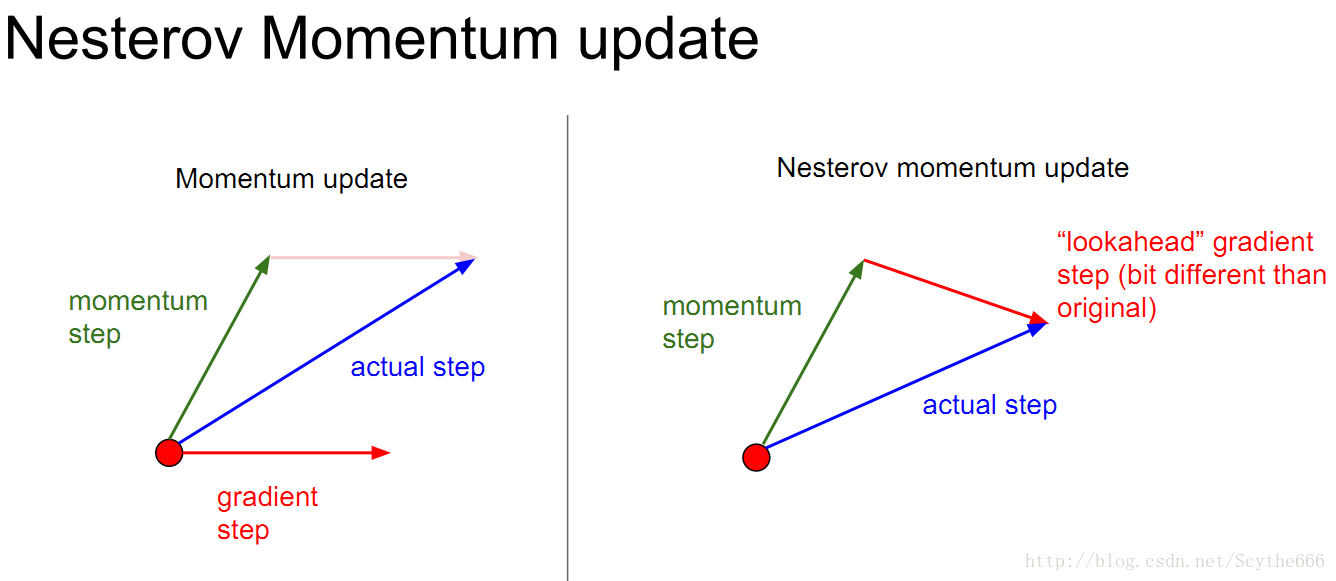
動量法的出現也不是因為有區域性最小值,當網路規模越來越大的時候,區域性最小值的問題不用特別關心
(2)AdaGrad update自適應梯度法

凸優化理論的成熟拿過來的
用一個cache(梯度的平方和構成,聯合向量,每個維度記錄相應梯度的平方和,有時叫做 second momentum),per parameter adaptive learning rate,儲存引數空間的每一維都有不同的learning rate,比如上面那張圖,垂直方向的learning rate會遞減,水平方向的會增大
反對有個問題:learning步長會減少,最終停止
(3)RMSProp update
Hinton做了一個小的改動,將上面的那個問題解決了,不會更新停止,而是不斷帶來更新
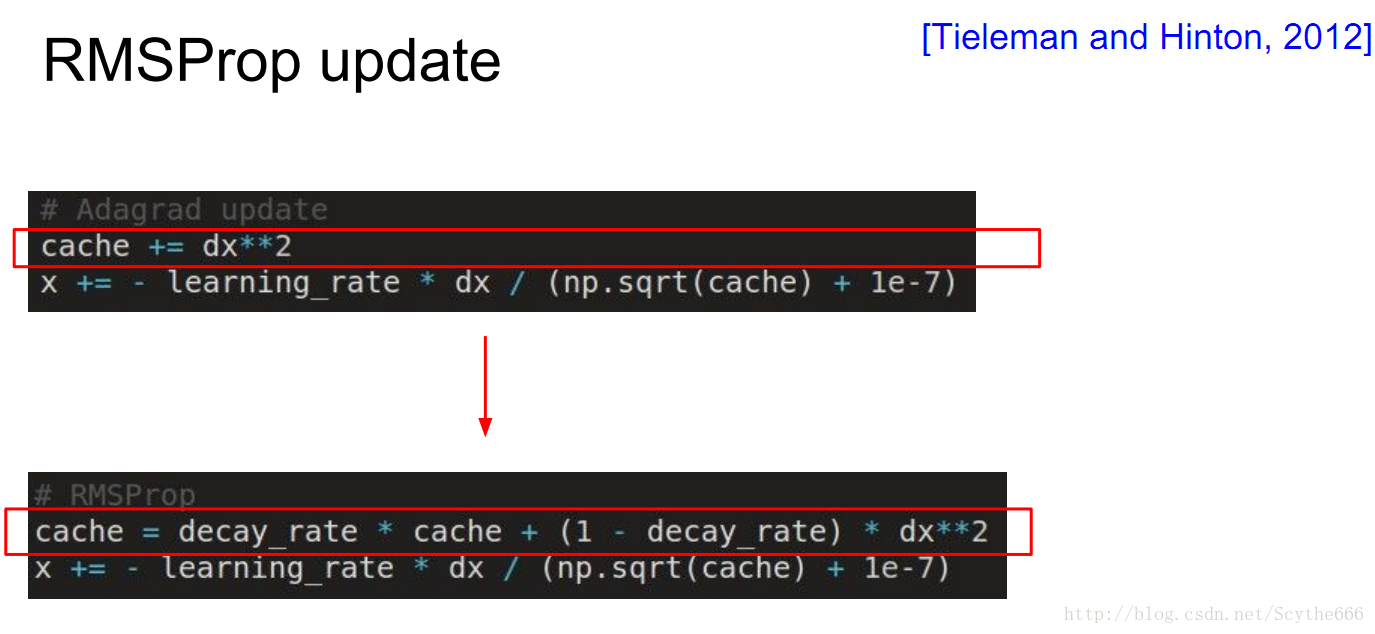

梯度大的地方減慢速度才是最好的
(4)Adam update
ada和momentum的結合
動量用於穩定梯度方向

beta1和2是超引數
beta1通常是0.9,beta2通常是0.995
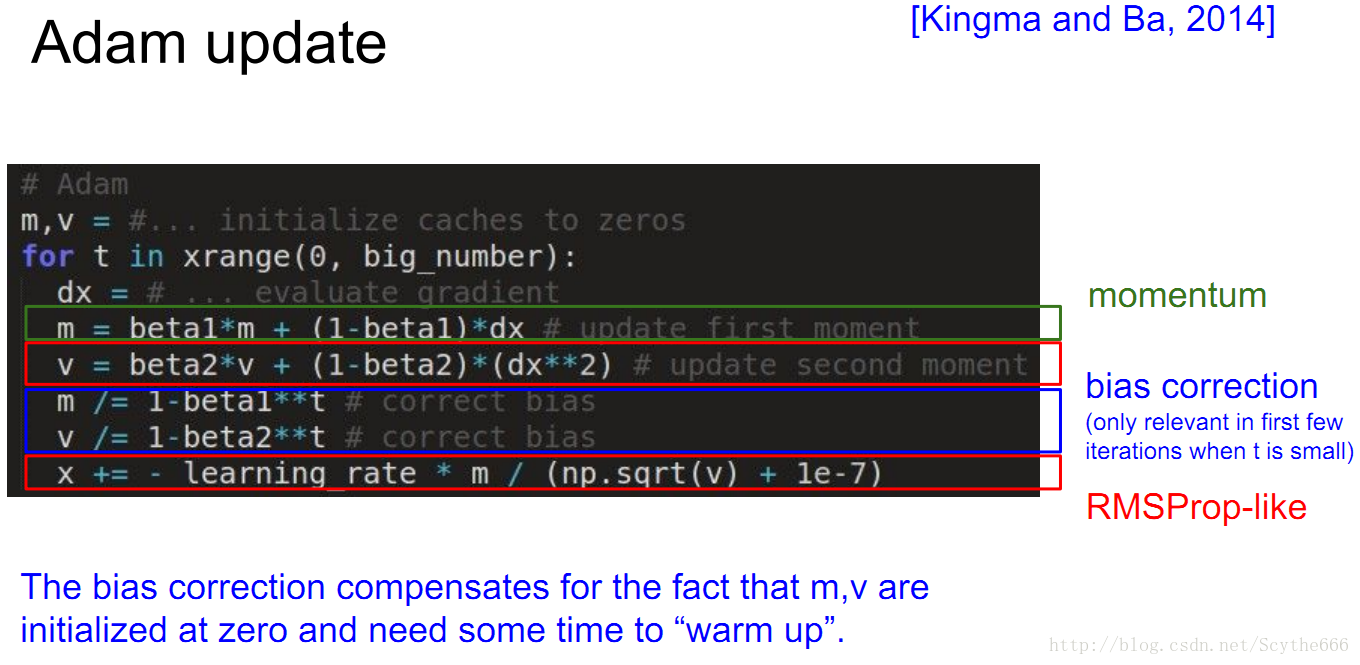
Adam很好用,通常講者使用Adam
learning rate 怎麼設定更好

其實這裡很難說,開始的時候最好使用大一點的learning rate,但是到後期可以使用小一點的rate,因為系統能量太大不容易settle down
另一些凸優化方法,但是不細講

Hessian Matrix,又譯作海森矩陣、海瑟矩陣、海塞矩陣等,是一個多元函式的二階偏導數構成的方陣,描述了函式的局部曲率。黑塞矩陣最早於19世紀由德國數學家Ludwig Otto Hesse提出,並以其名字命名。黑塞矩陣常用於牛頓法解決優化問題。


- Adam is a good default choice in most cases
- If you can afford to do full batch updates then try out
L-BFGS (and don’t forget to disable all sources of noise)
In practice
實際的大資料集不會採用 L-BFGS
adam 不會讓你學習率變為0,因為他說leaky gradient;如果用adagrad就不一樣了,learning rate可能降到0。
Evaluation: Model Ensembles
- Train multiple independent models
- At test time average their results
Enjoy 2% extra performance

這裡x_test是對於現在引數x的一個指數衰減,使用資料集和測試集,結果總比x要好,像引數進行加權的集合(不好解釋,想象碗狀函式優化問題,在最低點周圍不停跳動,最後做一個對這些值的,能夠更接近最低點)
Regularization (dropout)
涉及small samples,在前向的時候,要隨機將一些神經元置0
不僅在前向的時候,反向的時候也要用

都要乘以U1和U2,隨機失活過濾器
防止過擬合,如果只用一半網路,表達能力就變弱了,偏差-方差均衡
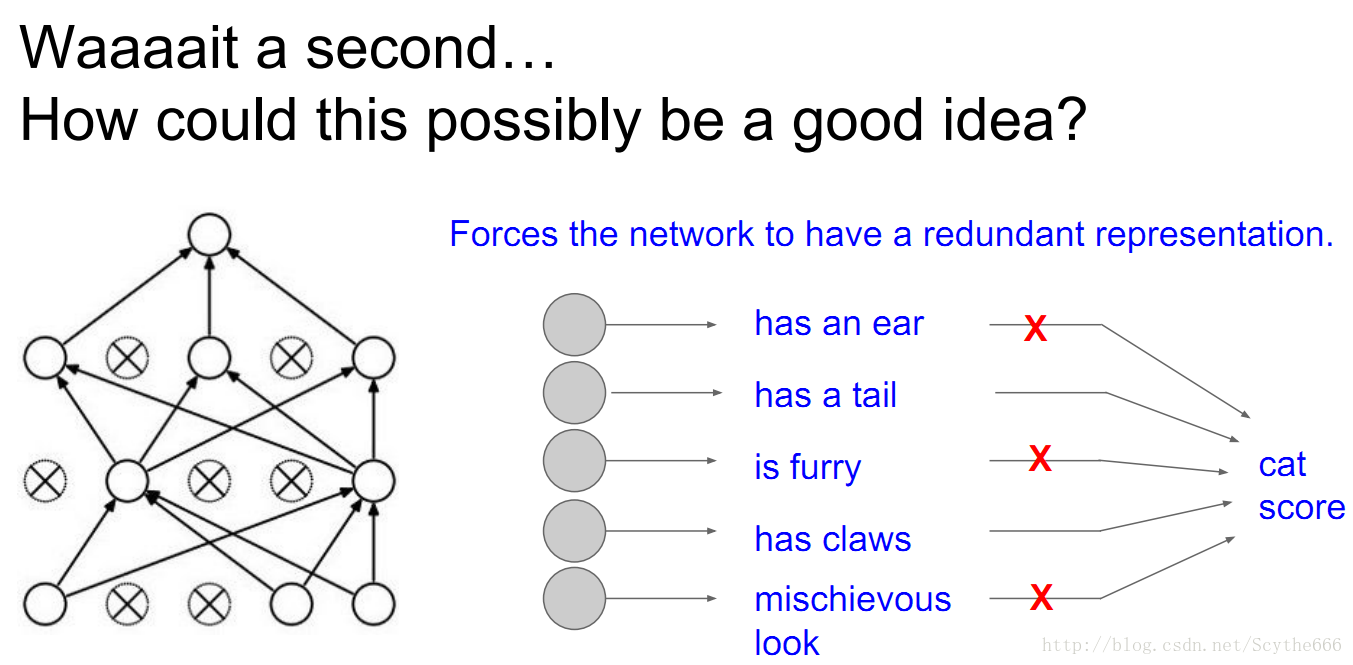
一旦dropout,沒有失活的神經元引數或者說神經元梯度才會被更新,因為一旦神經元被關閉,把輸出值固定為0,就不會有梯度經過他,他對應的上一層神經元的權值也不會更新,相當於是sub-sampling
因為他的值在計算損失函式中沒有用到,所以他的權值也就不更新了
在多次迴圈中我們會用相同的資料點訓練不同的共有引數的模型—>這就是隨機失活
每次前向的時候,我們sample,就會得到一個子網路
每一次迴圈中,我們先得到一個mini-batch,然後在神經網路中取樣,得到那些沒有失活的神經元,形成子網,然後前向+後向,然後得到梯度,一直重複這個過程
是否可以在不同層失活不同的比例,可以的,如果想更強的正則化,就失活多一點,比如一層有很多神經元,就可以多失活一點
也可以對每一個神經元進行一定概率的失活,叫做drop connect

這裡需要補足training的0.5那部分系數,需要在test時啟用函式也乘上這個係數,以減小輸出值


也有一種方法是在training中將啟用函式輸出變大

inverted dropout實際中應用很多
這裡的0.5不是絕對的,是期望
CNN
進入正題了,目前有一些很有名的網路,比如:
AlexNet,VGG-Net,LeNet,GoogleNet,ConvNet
AlexNet是2012年提出,但是跟1998年提出的LeNet差不多,差別就是一個用sigmoid一個用relu,而且更大更深,用gpu計算。
ConvNet對影象分類在行
第七講:卷積神經網路詳解
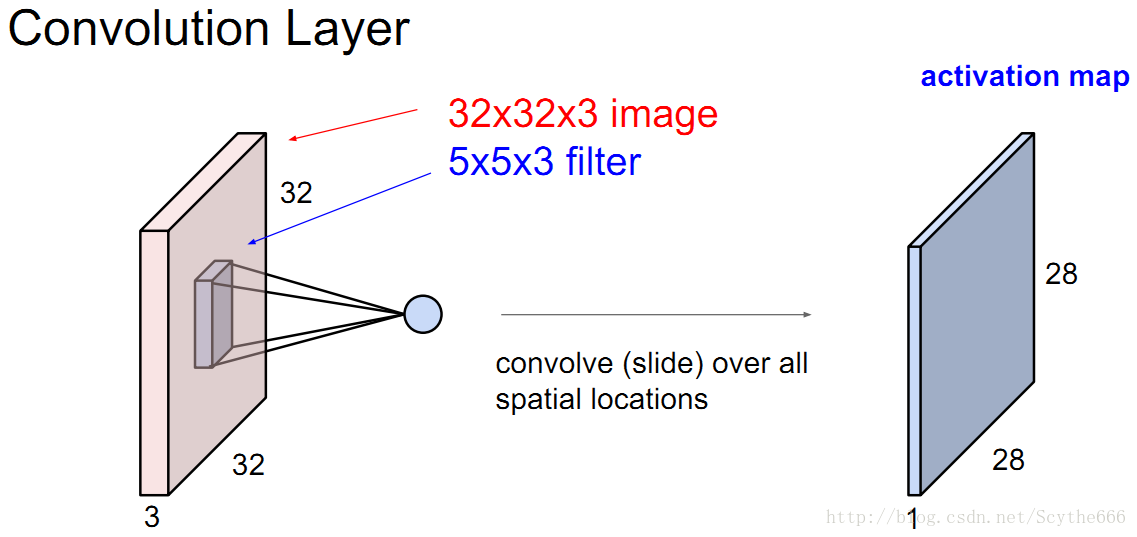
用一個5*5*3的卷積和做運算
—>得到一個28*28*3的卷積激勵map
—>用不同卷積filter做運算,可以得到一個多層的卷積組,比如6個,就得到28*28*6的卷積組
—>這些會被feed到下一個卷積層
當然這個過程中要經過激勵函式
通常filter都很小,一般3*3或者5*5等等
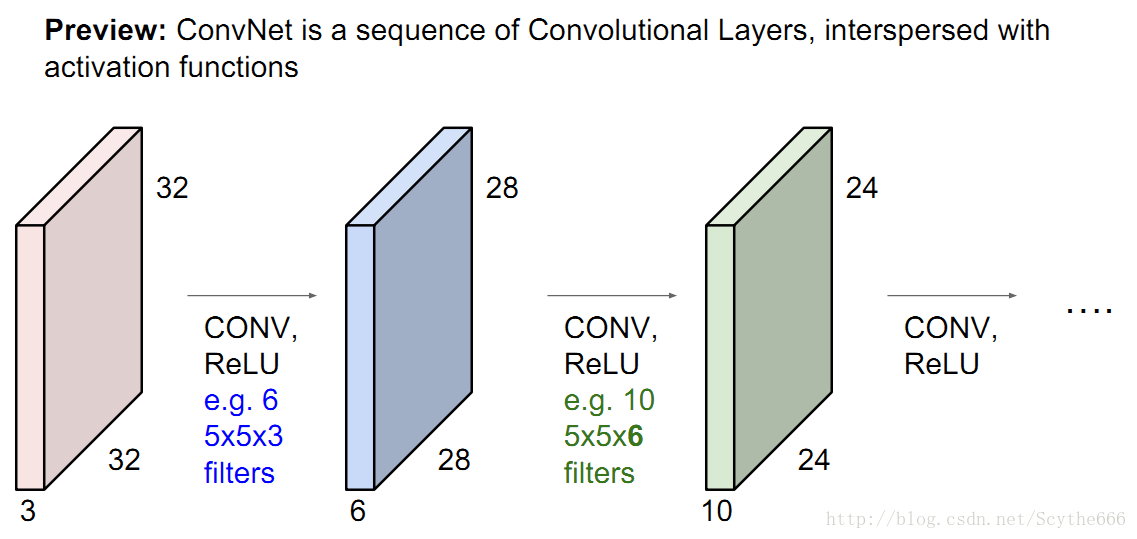
上圖中,第二層卷積層的大小變成5*5*6,有10個,所以得到一個24*24*10的卷積組
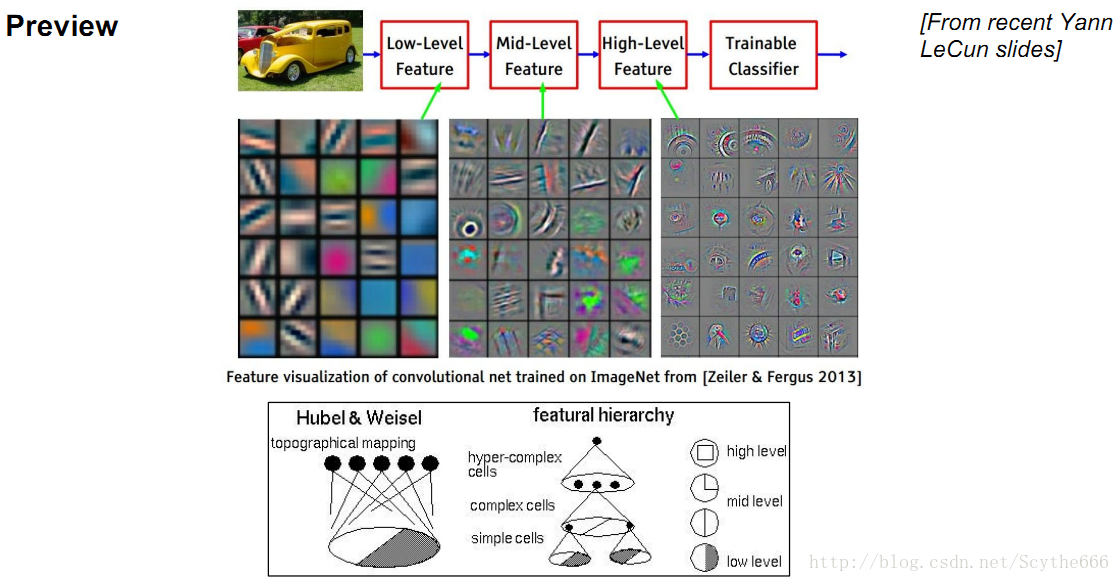
在每一層這會得到不同的特徵。
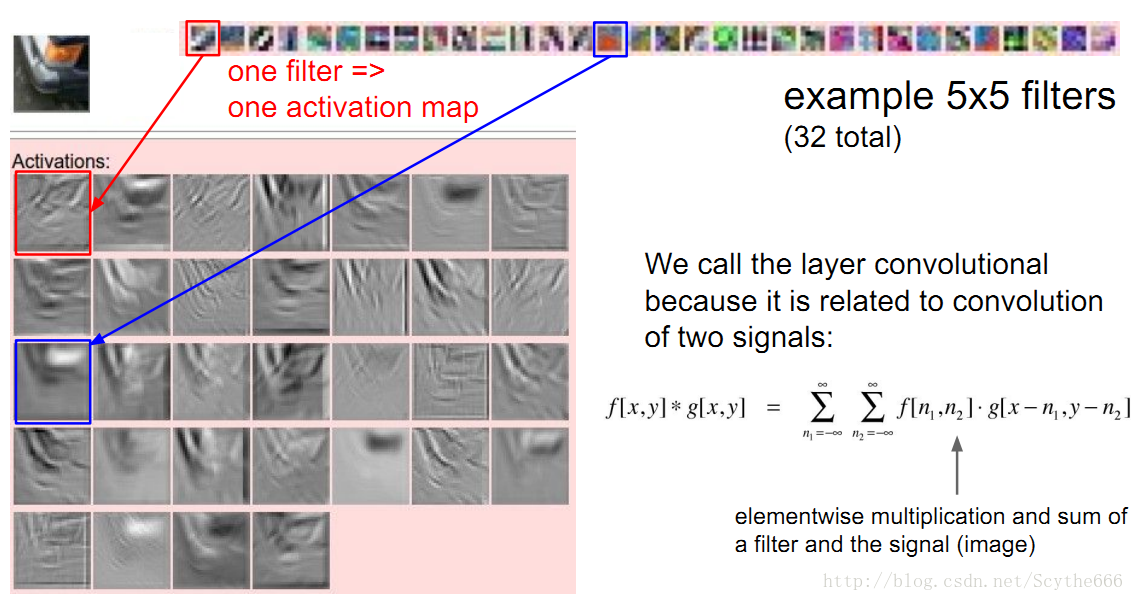
就是不同層的組合

步長不能是任意的,3的時候不允許

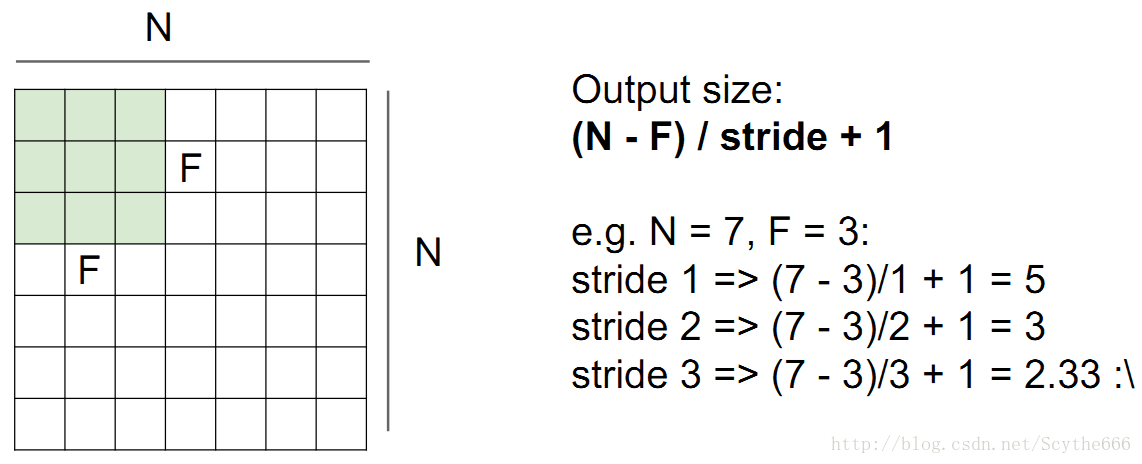
有時候會對影象做填補
作用就是,如果7*7的影象,用3*3的來filter,尺寸不會縮小

因為可能有很多層,如果縮小的太快,是不好的性質

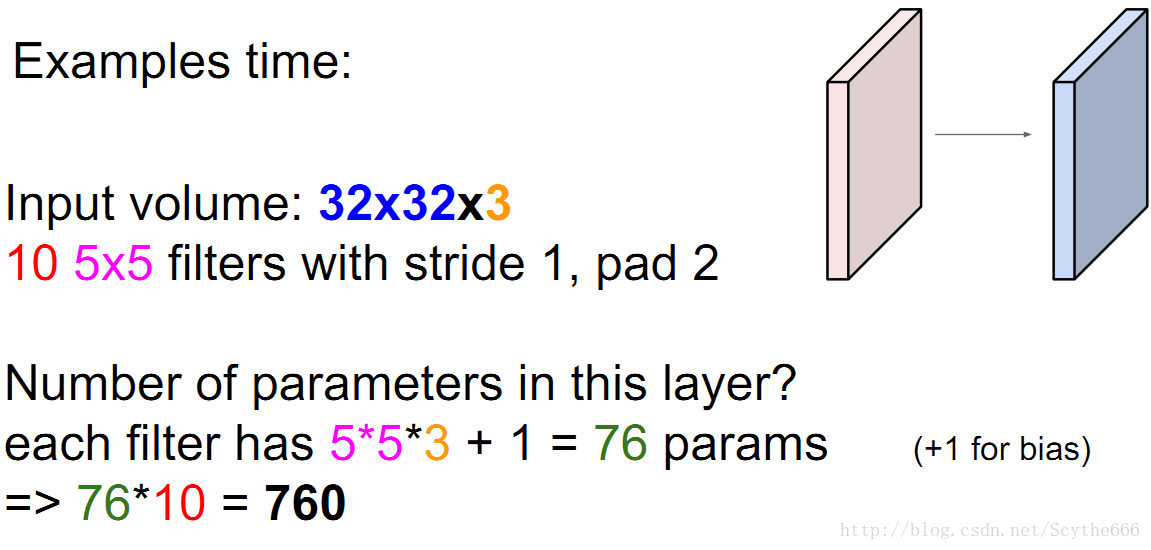
引數還要加上bias
總結一下:

K總要是2的指數,為了方便計算,有些程式對於2指數有特殊優化
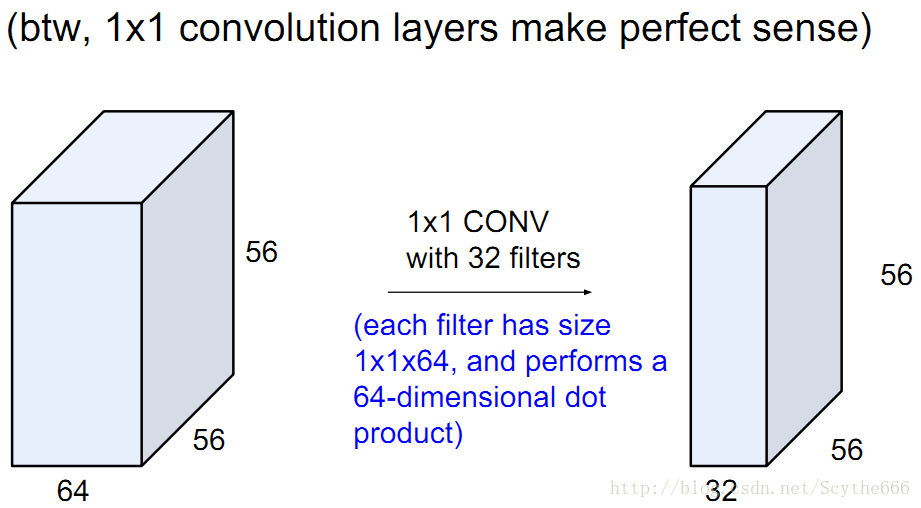
1*1的filter也是OK的,因為不僅是一個的,而是整個深度都參與卷積
filter總是偶數,奇數尺寸的濾波器有更好的表達,2*2也不是不行,但沒3*3好
為什麼填充的時候,只填充0,因為這樣filter只會考慮輸入的資料,點乘的時候,0不會對輸出有貢獻。即便是填充附近的資料。
每一層一般也不會用不同size的filter。
只有第一個卷積層能接觸到原始資料,後面的都是接觸前一個的資料
filter === kernel
在主流深度學習框架中也有體現:
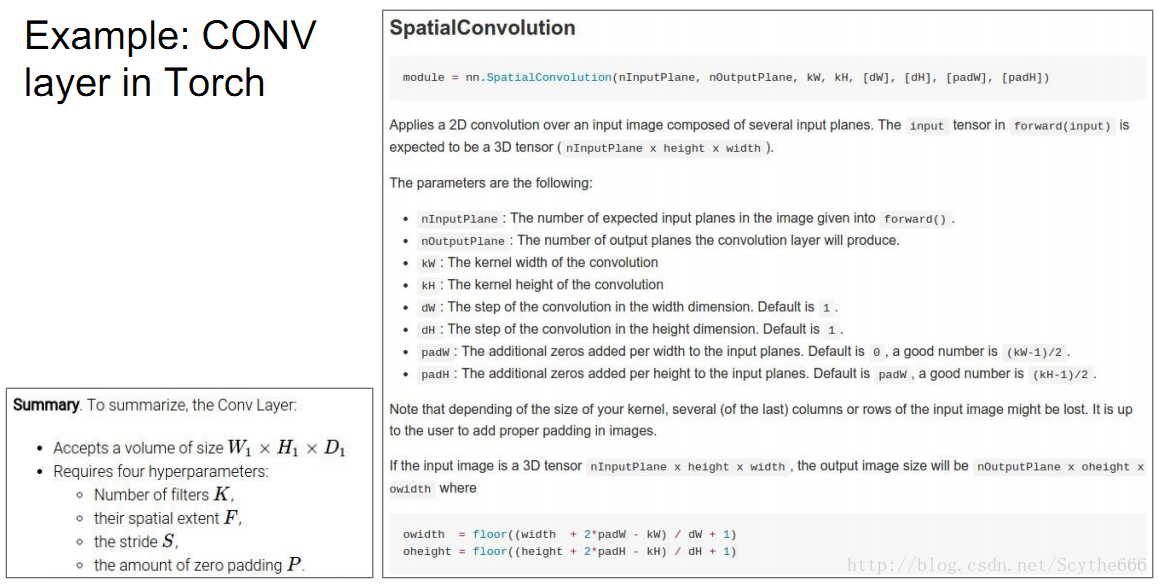

站在神經元的角度來看這個問題:
每個神經元只管自己的一小塊區域(對應於一個kernel),一塊板上的所有neuron在一個啟用對映中都share一個weight

一塊版上的neuron有兩個重要特性:
共享引數+局域連線
對於多個kernel可以理解為:
所有神經元全部以一個局域模式,共享引數,並關注著同一個資料體

如上圖的5個neuron都看著同一塊資料
共享引數+局域連線的作用:
從視覺上控制模型的能力,神經元平面上希望計算相似的東西,例如小的邊緣,這樣的功能是有意義的,也是一種控制過擬合的方式
pooling就是一種下采樣
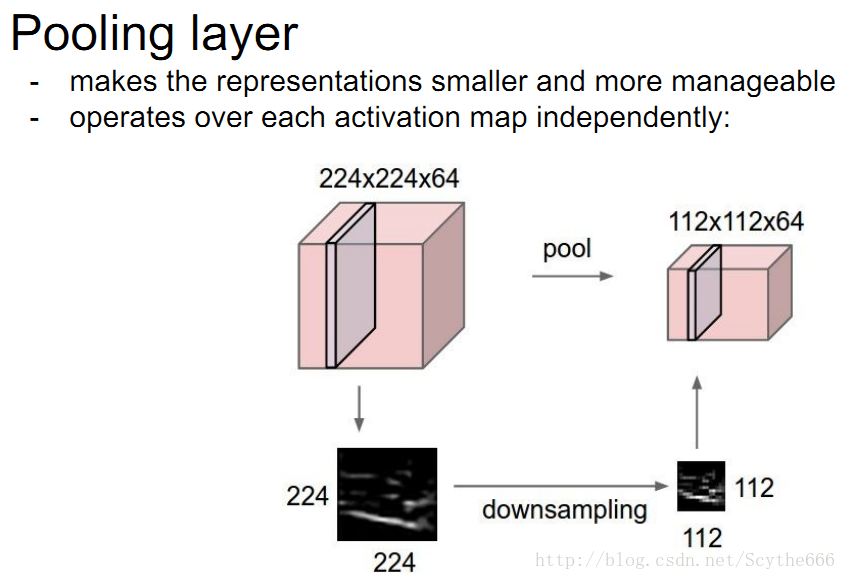
max pooling就是用幾個裡面的最大值代替,來進行下采樣
當然也是有average pooling
這就是兩種最常見的pooling技術
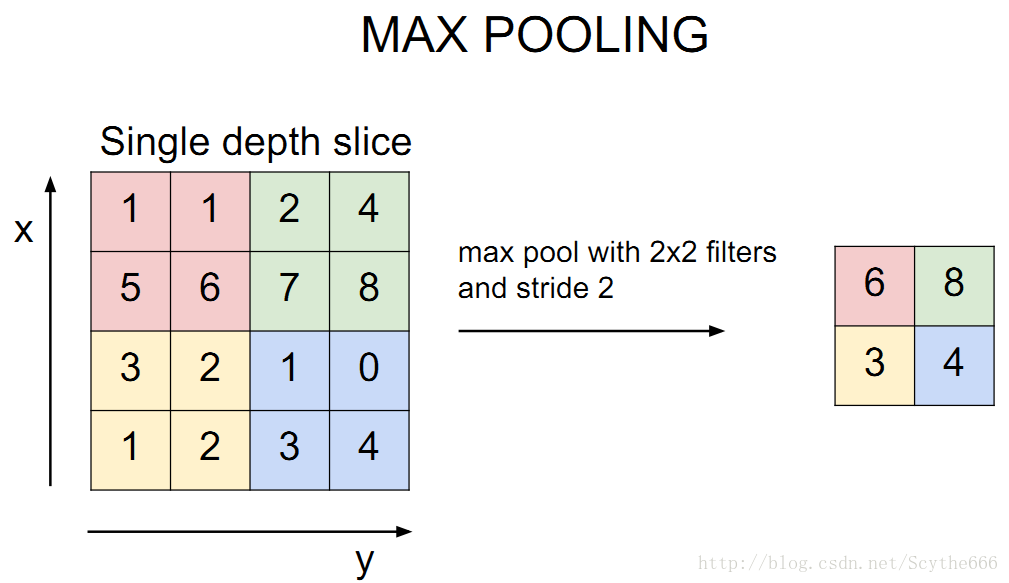
與Conv layer類似的是,pooling layer也有自己的定義,如下圖

這裡只有兩個引數,另外有輸入輸出的定義
fc層就是一個neuron來計算分類得分
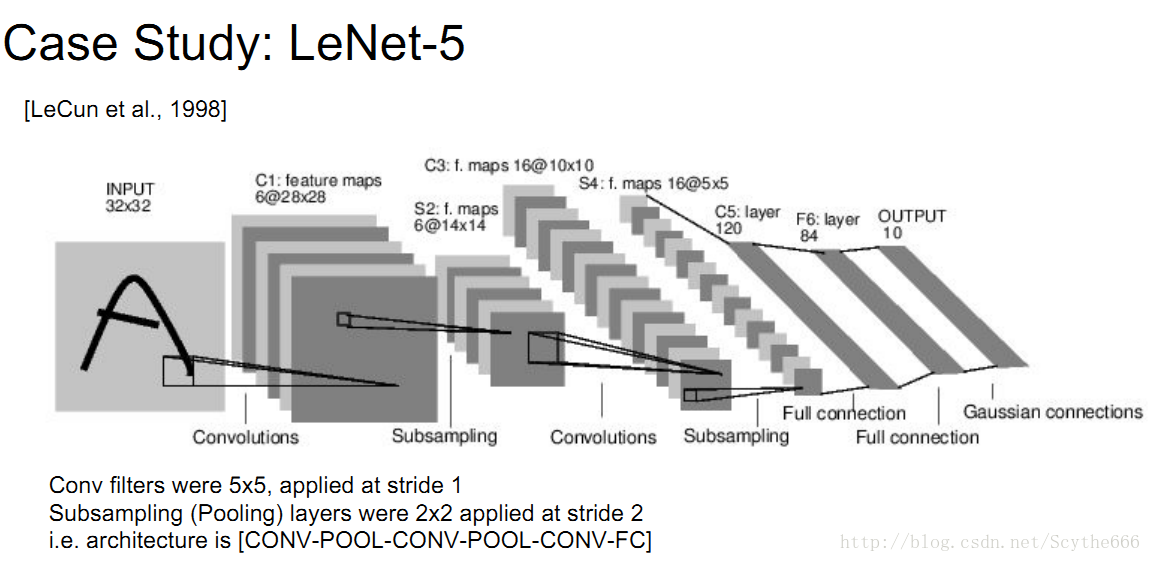
98年提出的LeNet
AlexNet,圖顯示不全,而且有兩條路的原因是因為當時gpu發展沒有那麼好,就分了兩個
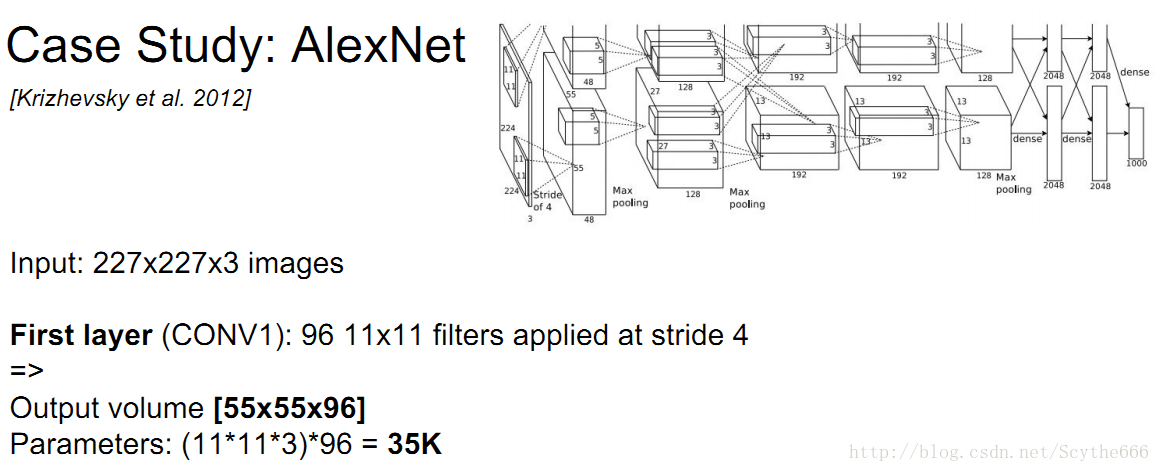
第一層應該是227,而不是224,Alex原作者說的有問題
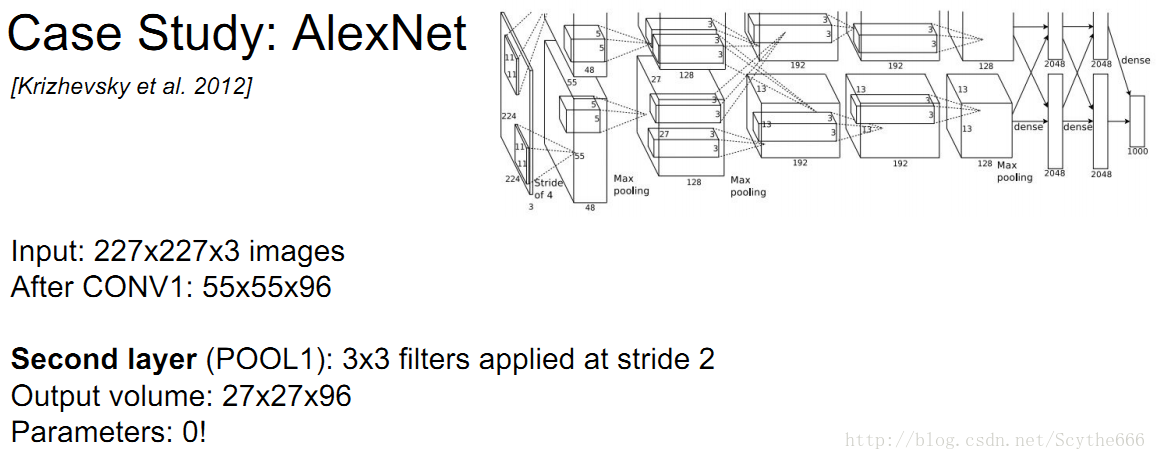
pooling layer沒有引數,只有卷積層有引數
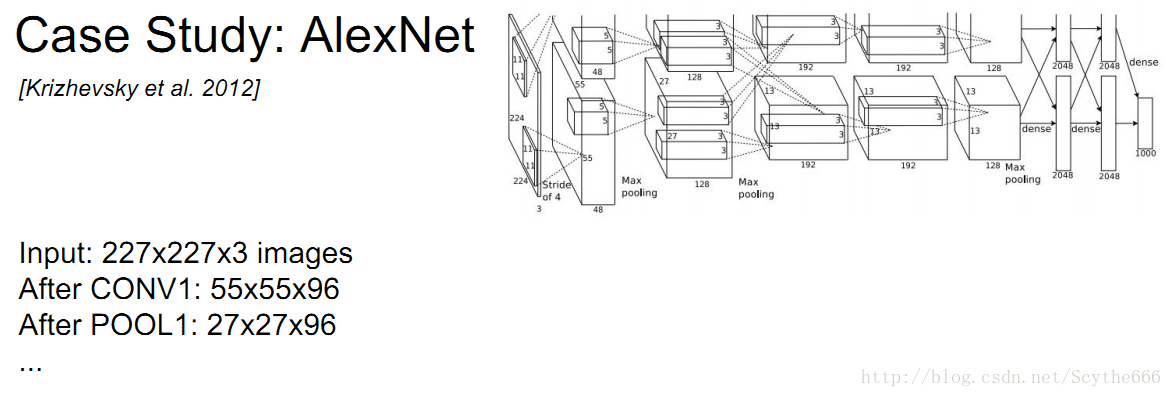
AlexNet完整的架構

依次為卷積-池化-norm,norm層是一個進行規範化的層,2012年前經常使用,現在不用了,因為對結果沒有幫助
也會對整個BP
BP的時候特別注意:
因為引數共享,當用filter做卷積的時候,所有neuron共享引數,所有濾波器梯度都彙總到一個weight blob
第一次使用relu
用了data 增強,拿到影象後不是直接用,而是先預處理
用了dropout 0.5,只在最後幾層用了
在監控準確率達到平臺期,學習率就除以10,基本減少一兩次,神經網路就收斂了
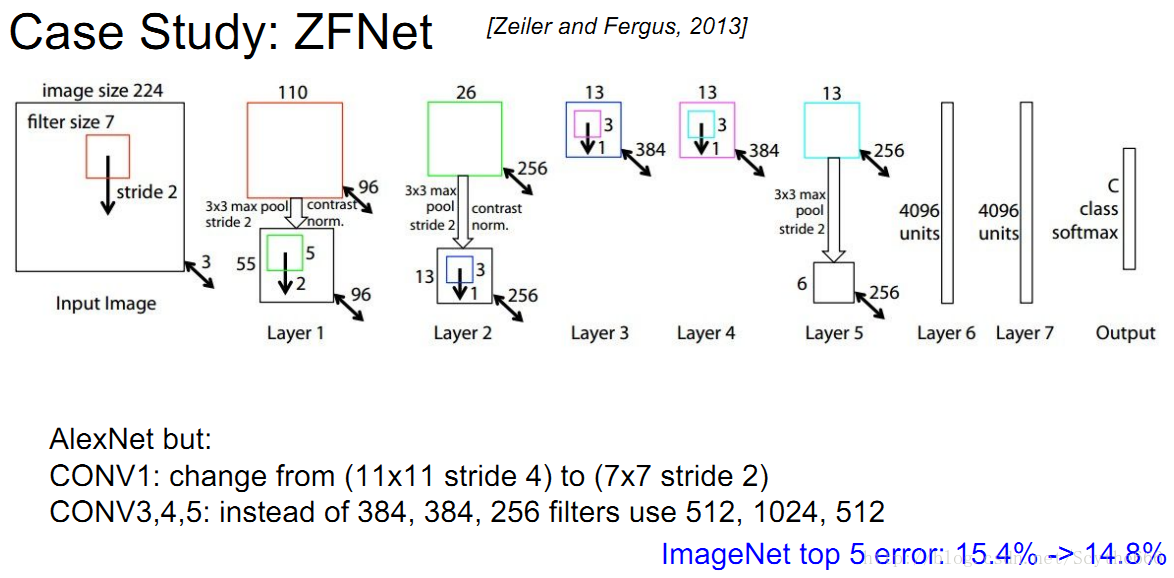
2013年冠軍是ZFNet,也是在Alexnet上改進的
fc7已經成為一個名詞:代表統計分數之前的最後一層
當然在每一個卷積層後有一個relu層
在fc層後也應該有一個relu層
2014年VGG提出,將top5 error率一下子刷到7%
全部的架構只使用 3*3 conv layer
2*2 max pooling layer
重複堆疊到16層,效果不錯
架構如下圖

我們注意到,過濾器在增加(更深),每個feature map在變小
224*224 —> 7*7
但是這一層深度不再是3通道,而是512個啟用通道(通過512個過濾器得到)
最後是每張圖片向前需要93m的記憶體,我們需要儲存這個值,因為要做BP,回來需要update,所以要double這個值,組後是最小200m左右
記憶體消耗主要在前期,見下圖,同時引數最多的時候在fc的時候

現在代替全連結層有—>average pooling技術
不直接全連結,而是改變他,成512個數,是通過average pooling對每個(feature map)取平均值得到512個數,效果幾乎一樣好,可以避免使用大量引數
GoogleNet使用這個方法
VGG有個很簡單的線性結構,GoogleNet就複雜化了
其最大創新點是加入了inception module
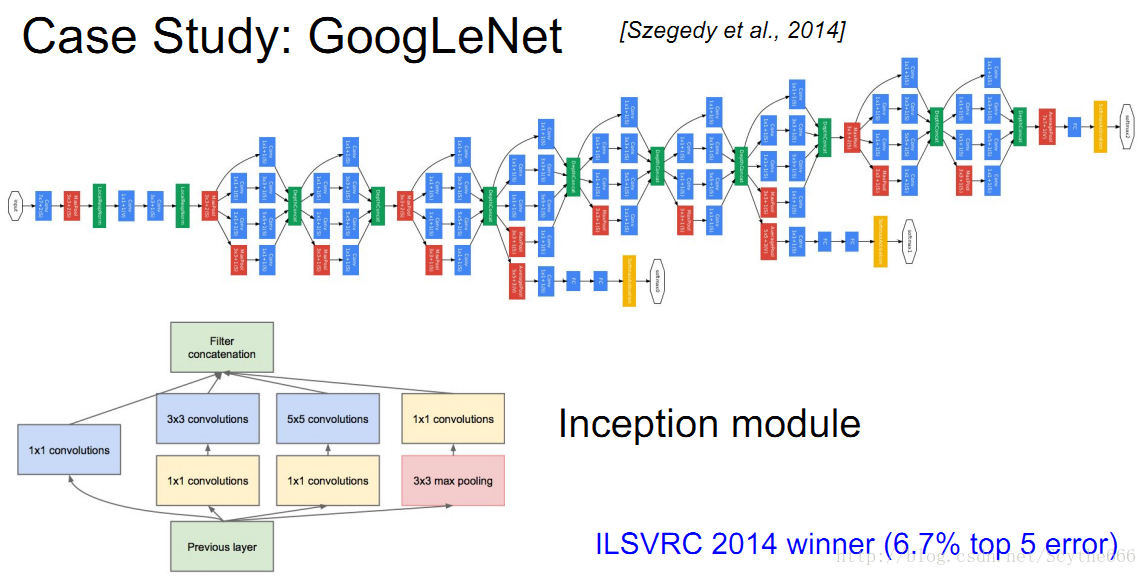
GoogleNet用inception layer取代了卷積層
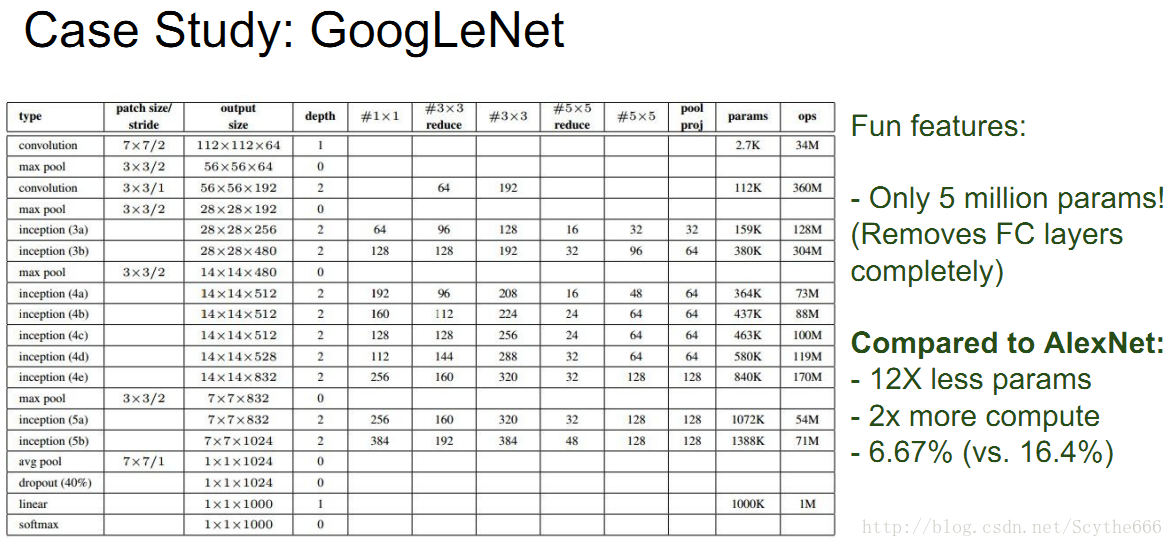
將7*7*1024降到1*1*1024
但是還是更多的人使用VGG,因為更好更統一的結構,人類的錯誤率差不多是5%,如果訓練人可以降低到2%~3%
2015年的冠軍是3.6%,來自於MSRA的residual network。
當然層數是越多越好
不過不是簡單的堆疊
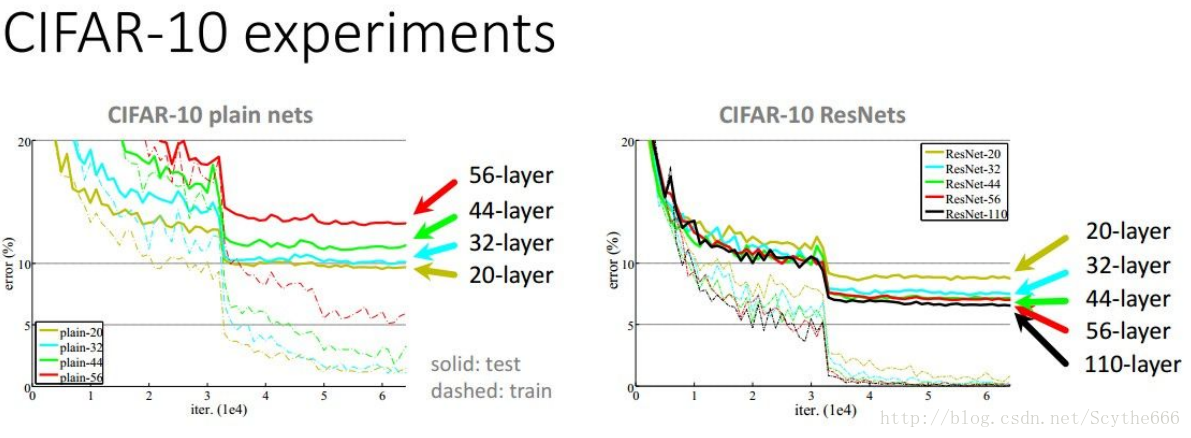
上圖說明了,如果要增加層數,不要用naive方法,要用resnet方法
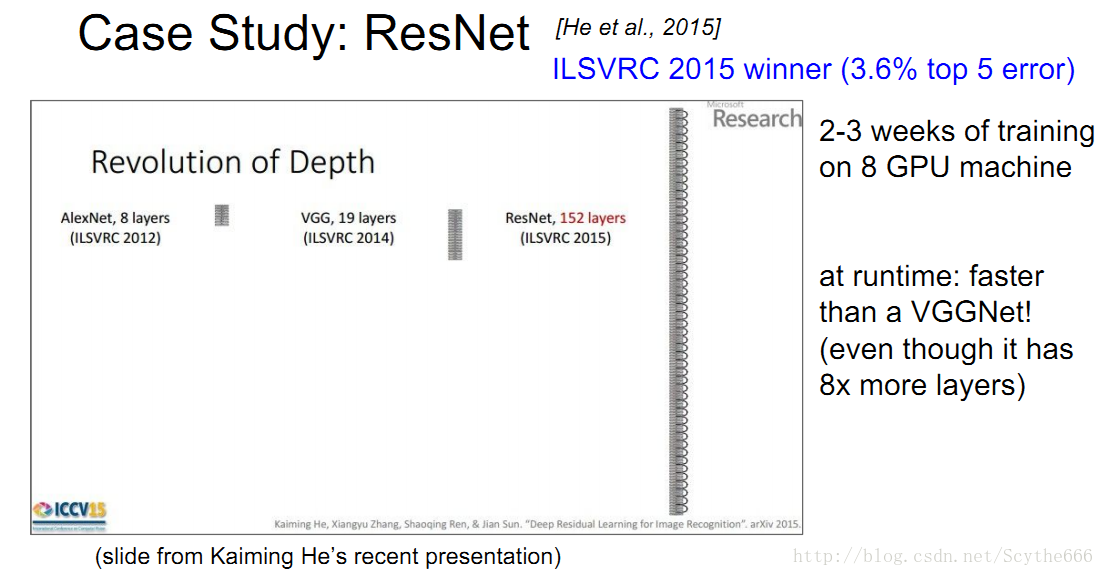
微軟亞研院的resNet有152層,訓練時間比較久,但是跑起來比VGGNet快
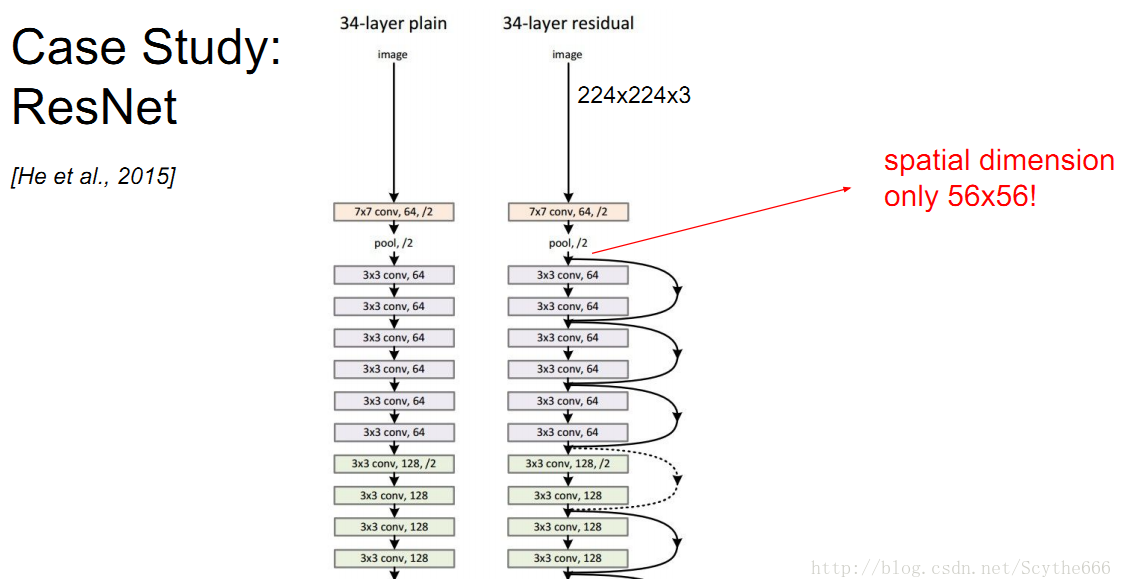
resnet,採用跳躍的連線,會通過一個大的因子壓縮到一層 56*56的空間,剩下的150多層,都只作用在56*56的數組裡,將很多資訊打包到如此小的空間
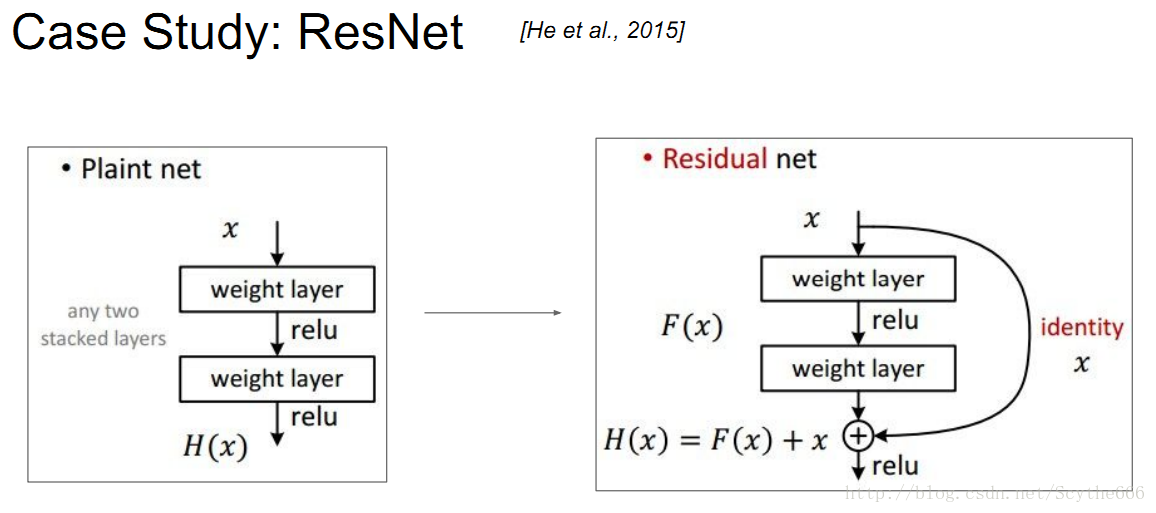
resnet的工作原理如上圖,需要加上輸入的殘差
原因就是,加法在BP的時候,梯度是直接分發給孩子,這樣跳躍的網路就可以幫助跳過很多中間層,因此可以訓練一個與原影象很像的影象,中間的層可以學習如何加入訊號使得更有效
如何訓練一個殘差網路:

Alexnet用了0.01的初始學習率,因為殘差網路有batch normalization,所以可以提高一點,沒有使用dropout
殘差網路也不用在加上的那個部分加權,最開始可以直接對結果產生影響
第八講:遷移學習之物體定位與檢測
localization可以看作迴歸問題。迴歸就是輸出一組數,而不是分類label了
選框可以用四個變數描述:左上角xy座標+長寬
類似分類問題:也有前向傳播+BP
loss可以選用標準的歐式距離loss
一個簡單的定位+分類recipe(固定種類)

pre-train就是先前有訓練的模型
簡單來說就是分別輸出框和分類結果
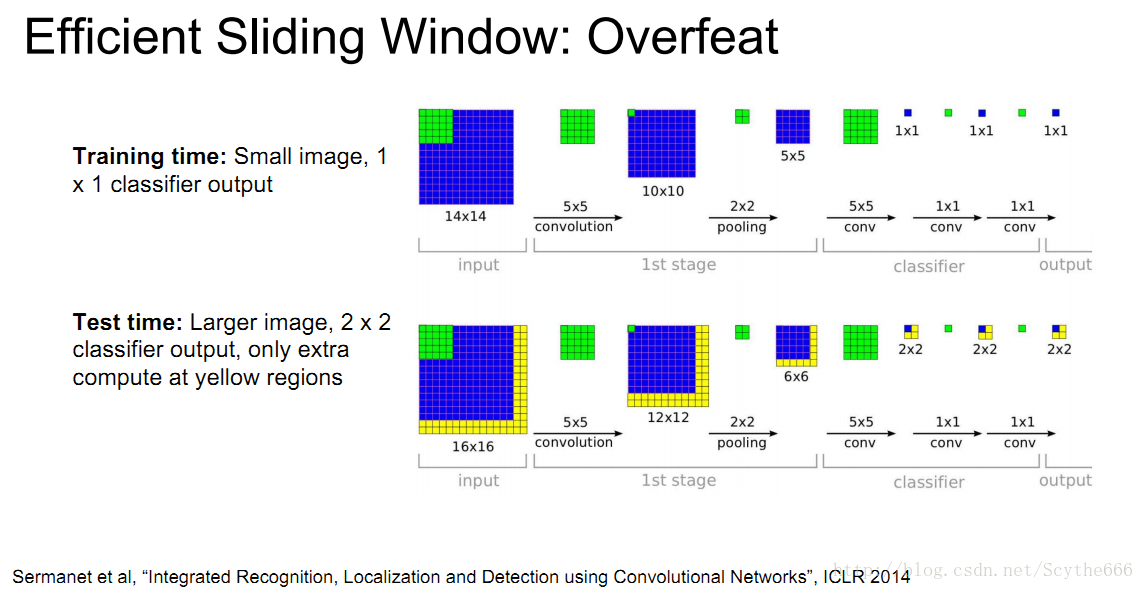
sliding window:overfeat
如果想識別圖中的物體,通常還有一種做法就是嘗試各種不同的框
重複上面的定位+分類操作,再將不同位置的結果進行聚合
將全連線層視為一個conv層
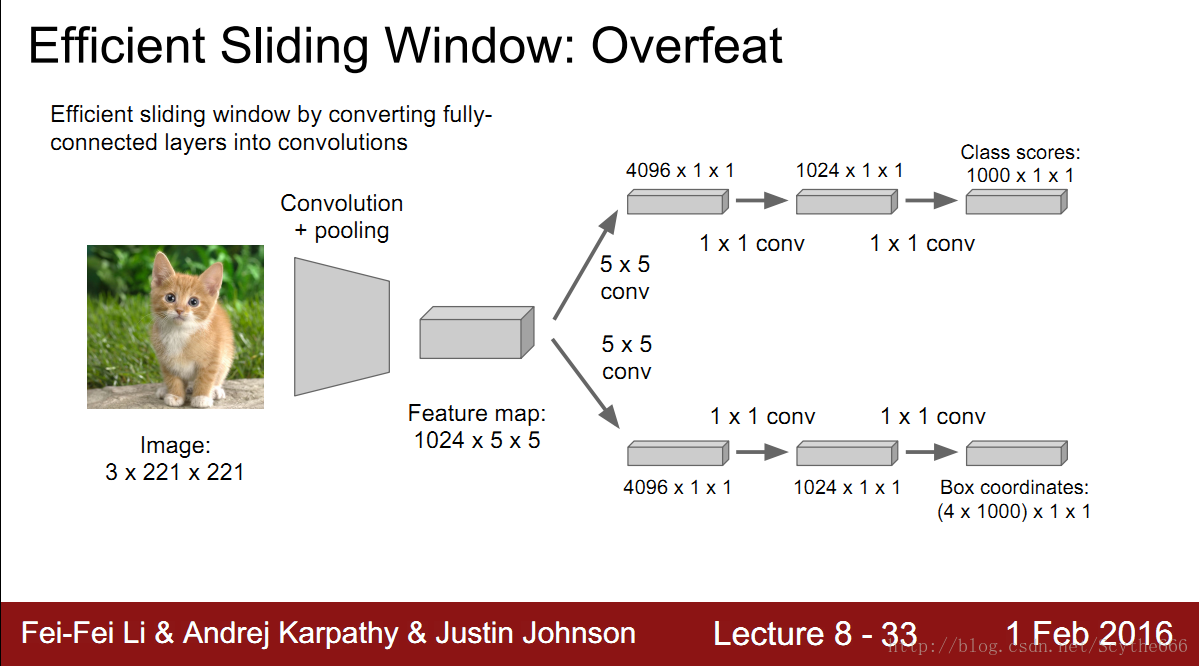
如上圖的5*5*1024 —> 被個4096個5*5的核conv
這樣就統一了計算,大大減少計算量
微軟2015年沒有靠的不只是更深層的特徵,而是發明了RPN—Region Proposal Network
L2 loss 有極端值的問題,L1沒有,所以可以用L1
有時有人會同時訓練迴歸與分類;有時分開
object detection
輸出的數量不定,也可以用不同的區域不停的試,試不同大小的視窗
加入兩個新東西:
(1)可以加入一個背景類,代表啥都沒有;
(2)多標籤分類,不用softmax loss,而是用獨立的迴歸loss,多個類可能在同一個點上
hog是用線性分類器,方向梯度直方圖,DPM類似CNN
當然不可能嘗試出所有的區域,所以用region proposal演算法

輸出可能含有物體的區域,不關心具體類別,只是告訴這個區域可能有物體,很快。在影象中找整塊的區域
最著名的Region proposal演算法有selective search — 將類似顏色+紋理進行融合成框,再用這些合成的框進行檢測
講者推薦edgebox
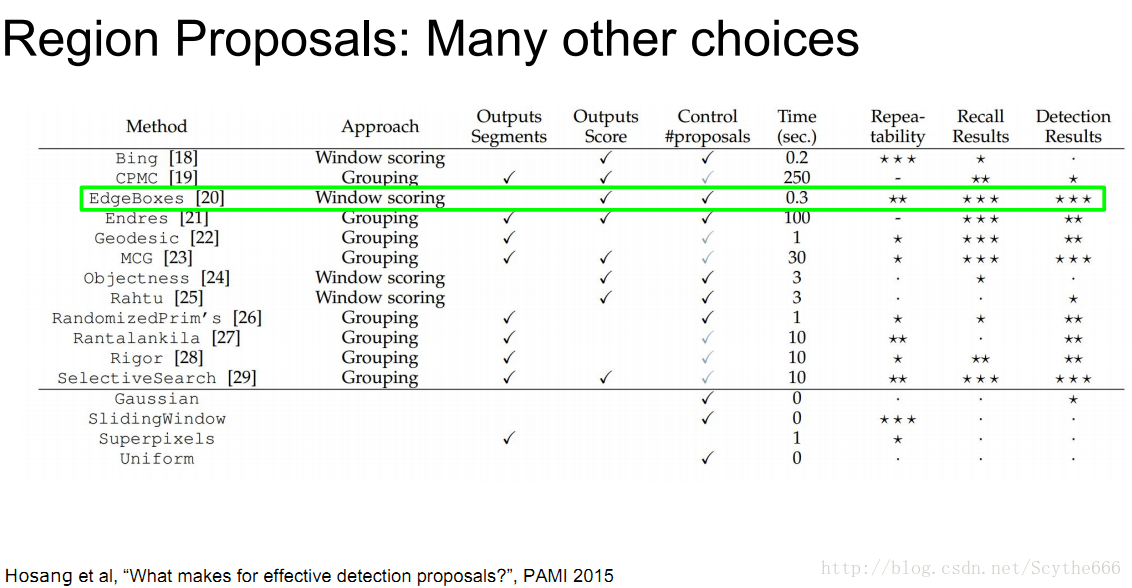
很快,1/3s一張圖
R-CNN Region based CNN
有了Region Proposal,有了CNN,就有了R-CNN
step1:執行selective search 到大噶2k個不同大小、不同位置的框
step2:每個框剪裁出來,調整到固定大小
step3:cnn分類 —> cnn網路分別連接回歸端+SVM分類端,迴歸端可以對目標框進行糾正
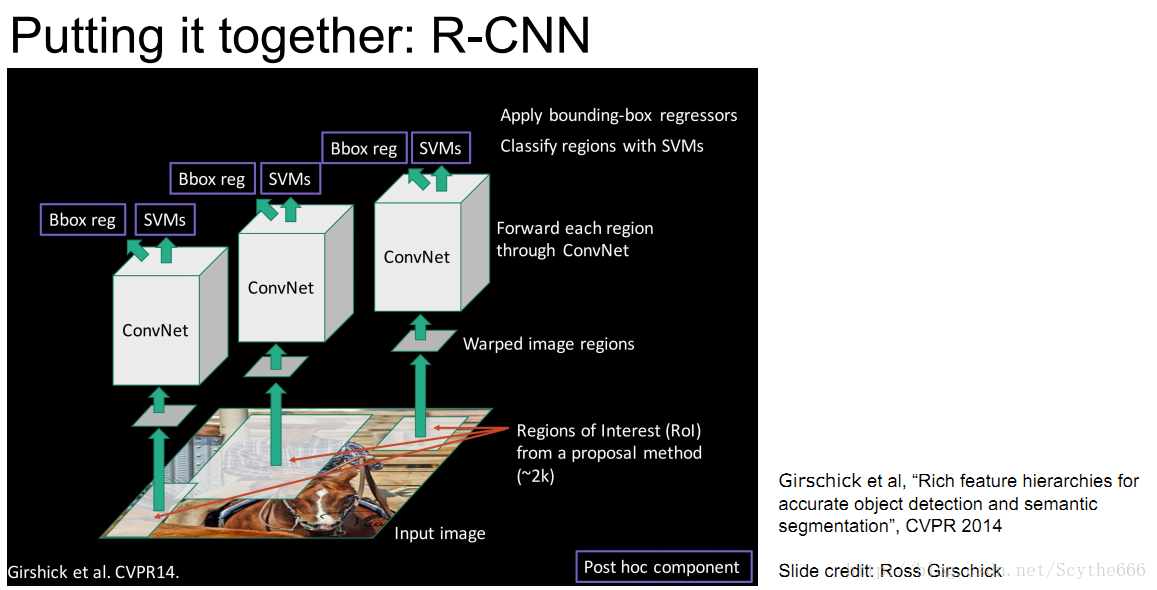
R-CNN Training 過程
step1:下載一個已有的對於imageNet資料集分類的模型比如Alexnet
step2:finetune用於檢測,因為原模型是用於1000類分類的,可以在後面加上幾層用於分類自己的資料
step3:提取特徵,存在磁碟上—對於每張圖片,執行selective search 演算法,送到CNN,把特徵存在磁碟
step4:訓練二分類SVM,回答是否包含特定物體
step5:box的迴歸,希望從特徵推回到box,有特徵+目標==訓練線性迴歸
測試標準

缺點:訓練有點麻煩,且費記憶體,慢,離線操作(不能update)
Fast R-CNN
swap提取出的區域再執行CNN,類似與overfeat滑動視窗
先高解析度影象輸入,卷積,得到高解析度卷積特徵
再用Region Proposal的方法, 即ROI分離區域特徵
投入全連線層
用分類端+迴歸端
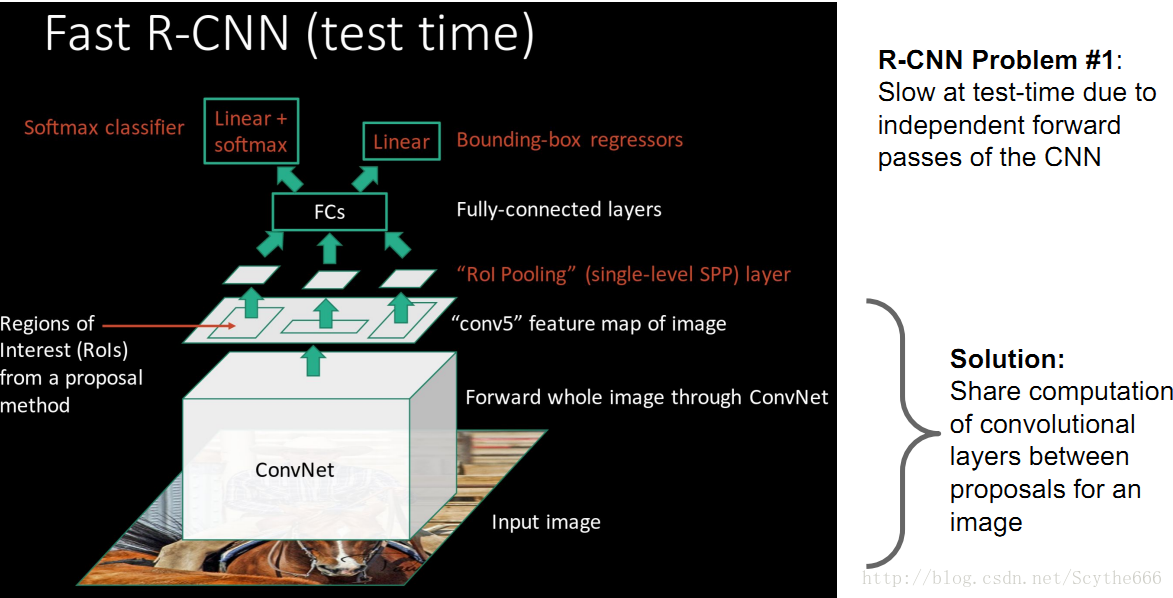
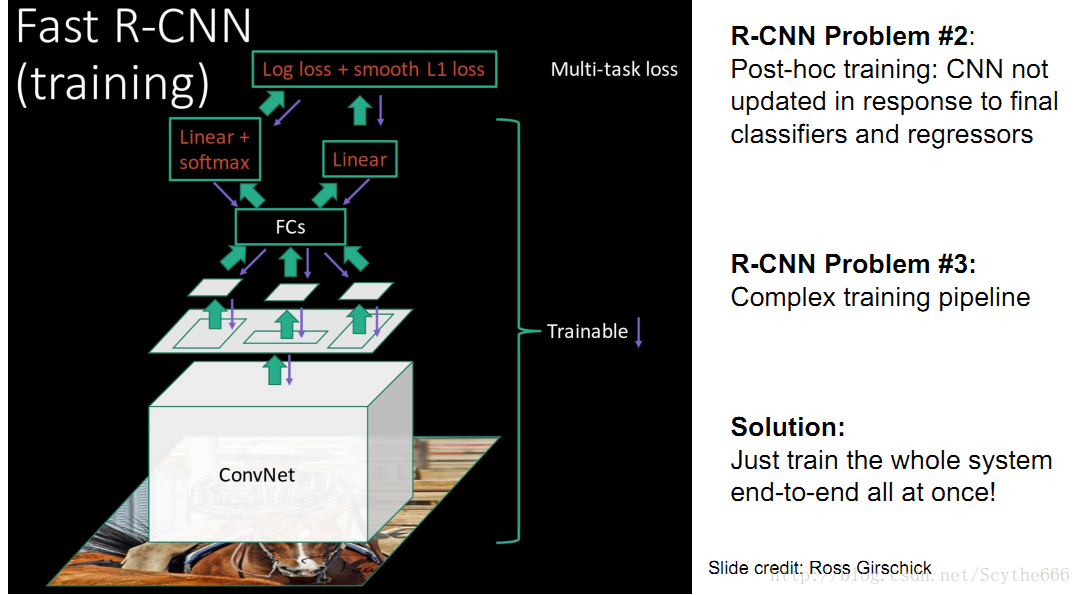
解決了R-CNN在test和train時候的問題
Region of Interest Pooling
給出目標框,投影到conv feature空間,將conv feature分成小塊
再做max pooling,這樣也是可以BP
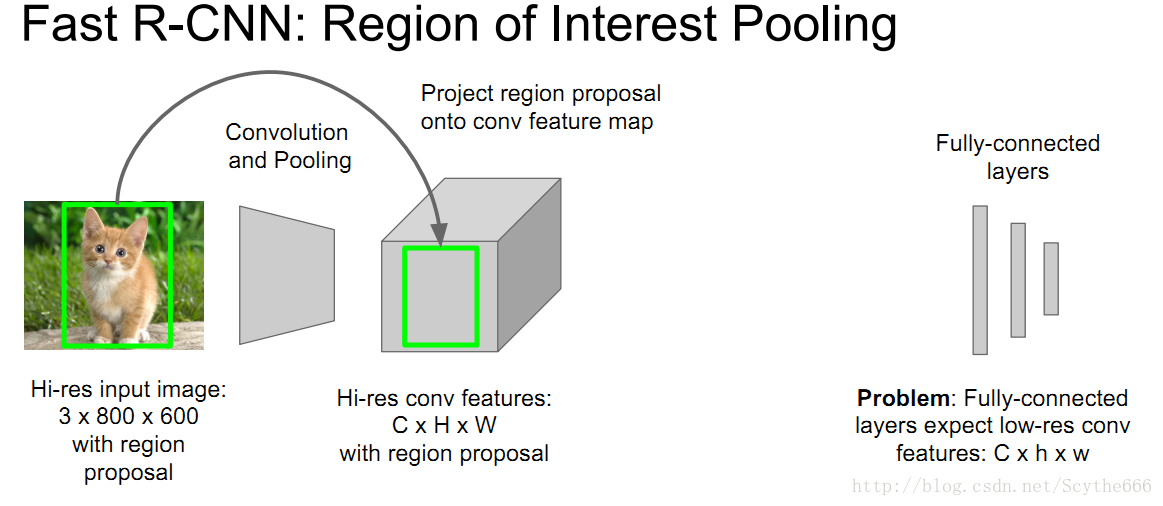
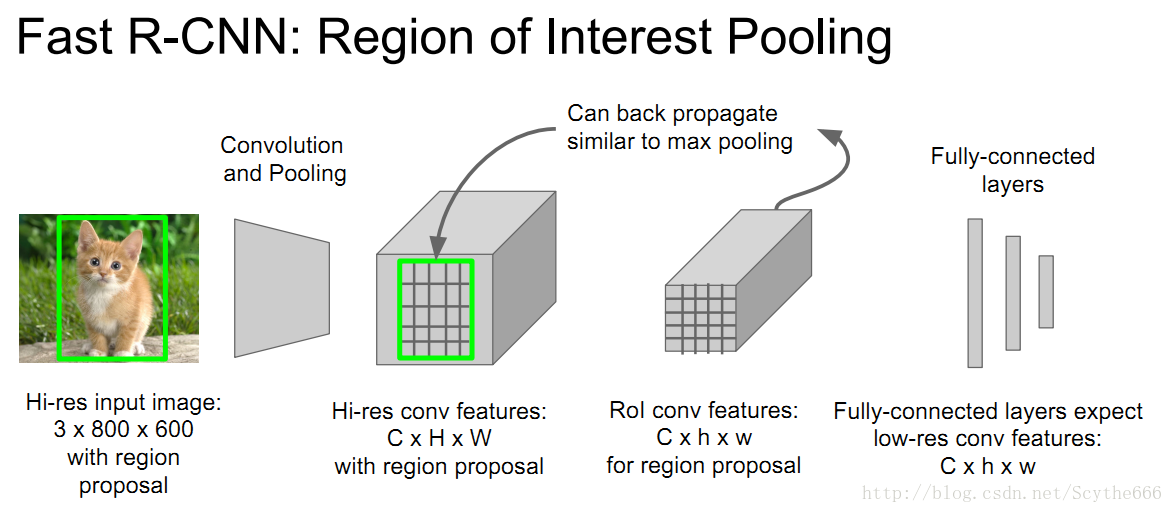
為什麼不用CNN做Region Proposal呢
Faster R-CNN
不用推薦區域的卷積,而是整張圖片卷積,使用RPN Region Proposal Network
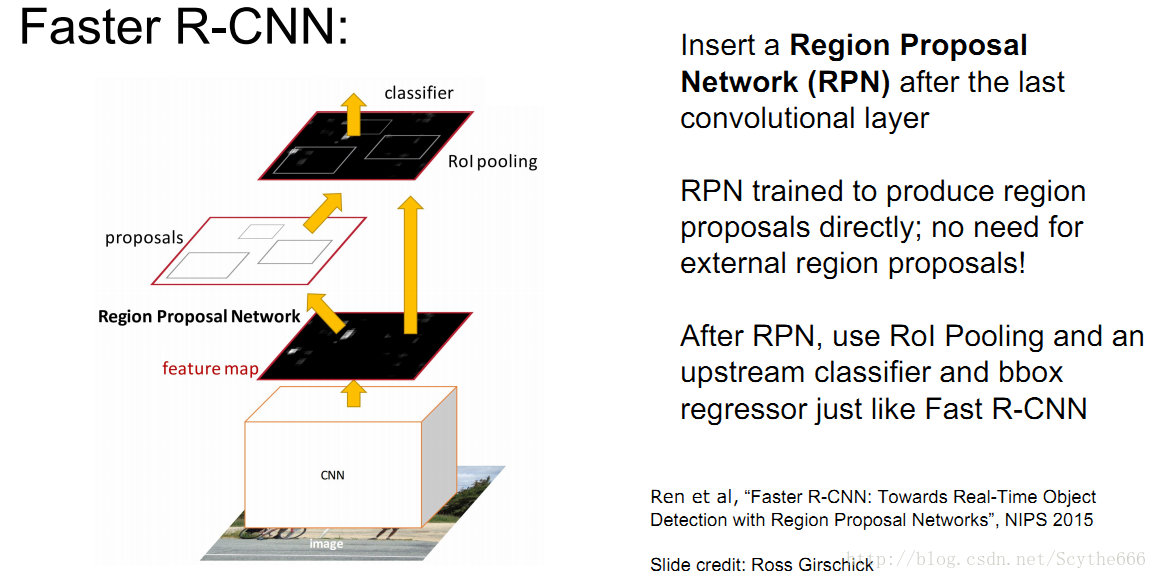


做了和fast-RCNN相反的事情,用anchor框對特徵圖進行滑動,映射回原影象,特徵圖譜上的點和原影象有關聯,用這個就減少了計算量

原論文將RPN與Fast-RCNN訓練重合了,這樣就節省了很大的計算量
對於Faster的區域推薦只用通過一個3*3和一些1*1的卷積核,計算量很小,就基本不用花什麼時間了
速度對比:

授課時(2016.1)最好的組合還是 resNet101+faster RCNN
one-stage方法
YOLO:you only look once
將檢測問題直接當作迴歸來做
分離空間網格,他們7*7,對於網格中的每個元素,我們得到固定數目的bounding boxes,他們大部分實驗用B=2個
每個grid,預測2個B bounding boxes — 也就是4個數,還要預測一個score來表示可信度
現在還有SSD做實時的
問題:模型輸出數有限,速度快,但是不準,於是有fast YOLO
Object Detection 程式碼:
第九講:卷積神經網路的視覺化與進一步理解
conv層weights(過濾器)如下
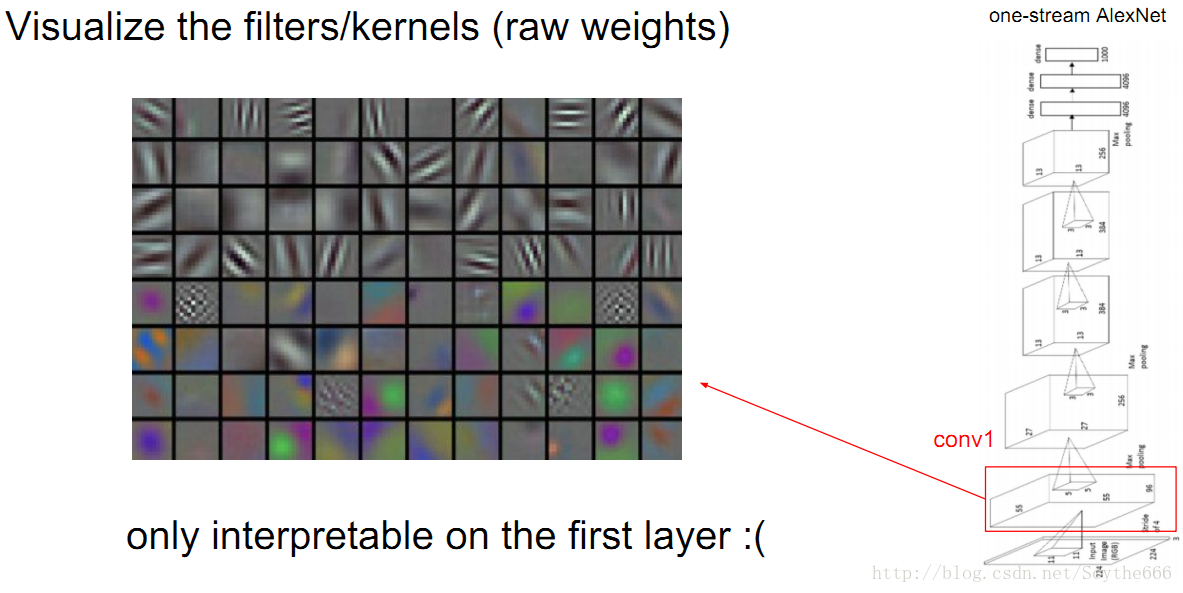
視覺化只能在第一層做,跟原圖有關
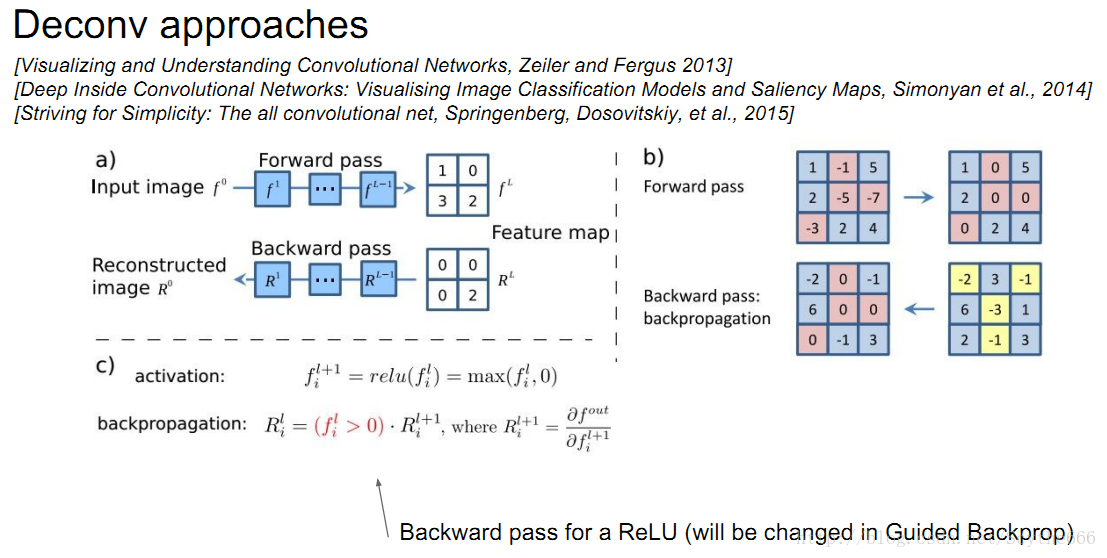
整個神經網路可微才能夠計算梯度
要想計算特定神經元的梯度,將這個神經元設定梯度為1.00,然後其餘的設定為0,做BP
用解析梯度法而不用數值梯度法的原因是,數值法更慢
對於一個任意的神經元,他的梯度並不是很容易看出是什麼,有個deconv的方法 guided BP
relu是阻斷為負數的BP
guided BP—只傳遞正數的梯度的部分,用relu;並且還阻斷梯度為負數的
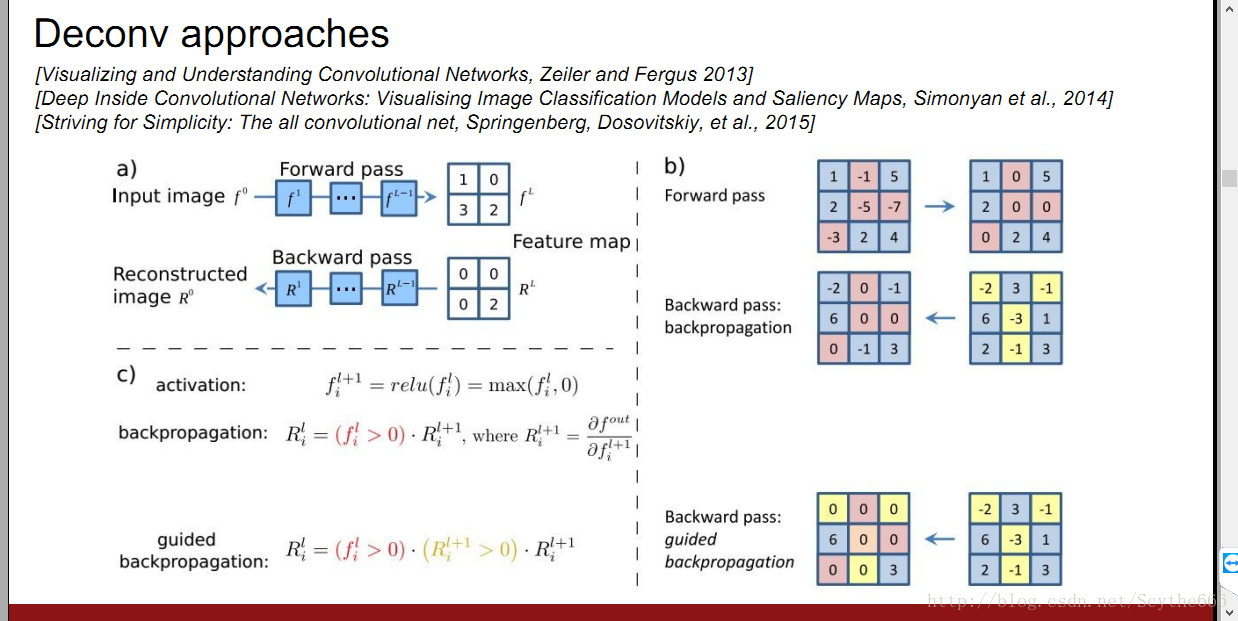
只通過有正影響的,不通過有負影響的
普通的看起來不明顯的原因,是因為每個畫素點到目標神經元的影響有正有負,在GBP的只通過正值,就能看到清晰的圖片
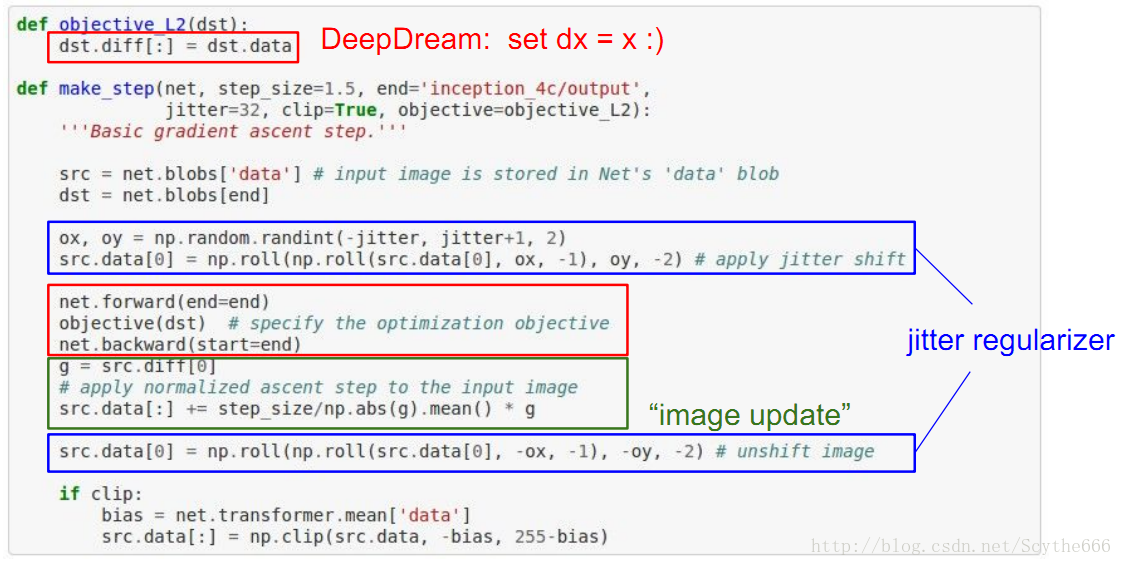
Optimization to Image
另外通過優化的方法,對某一類物體儘可能高的提高得分,最大程度的啟用網路中某些單元的影象

無論梯度正負,只取最大值效果,不考慮符號
暗色的地方說明:這塊地方出現的東西,神經網路不care對結果的影響,但是如果改變白色部分,就會影響結果
開始的時候,kernel很小,比如3*3,但是後面層的畫素對結果的影響就可以組合了,變大很多,所以在底層就是一些片段的組合,但是到高層了會成團,到高層之後一個neuron就可能是整張圖片的函數了
增強跟目標相似的東西,做BP增強原圖
因為資料中狗很多,所以整個網路比較關注狗的特徵
損失要和這裡的啟用匹配,比如啟用和放進甘道夫的啟用類似
如何去fool一個分類器
其實可以將一張圖“變成”另外一張圖,對於分類器來說。
在高層中將梯度設定成另一個類別,然後反向傳播,得到原影象的改變

只是把畫素向置信度高的方向移動一點點,對於分類器來說就成了另一張圖,這是因為前向傳播中的函式線性的特點,因為在網路的頂端加了一個線性分類器,對於高維空間,只需要對每個維度順著結果遞增的梯度方向做微小改變,這個分類器就會被fool。
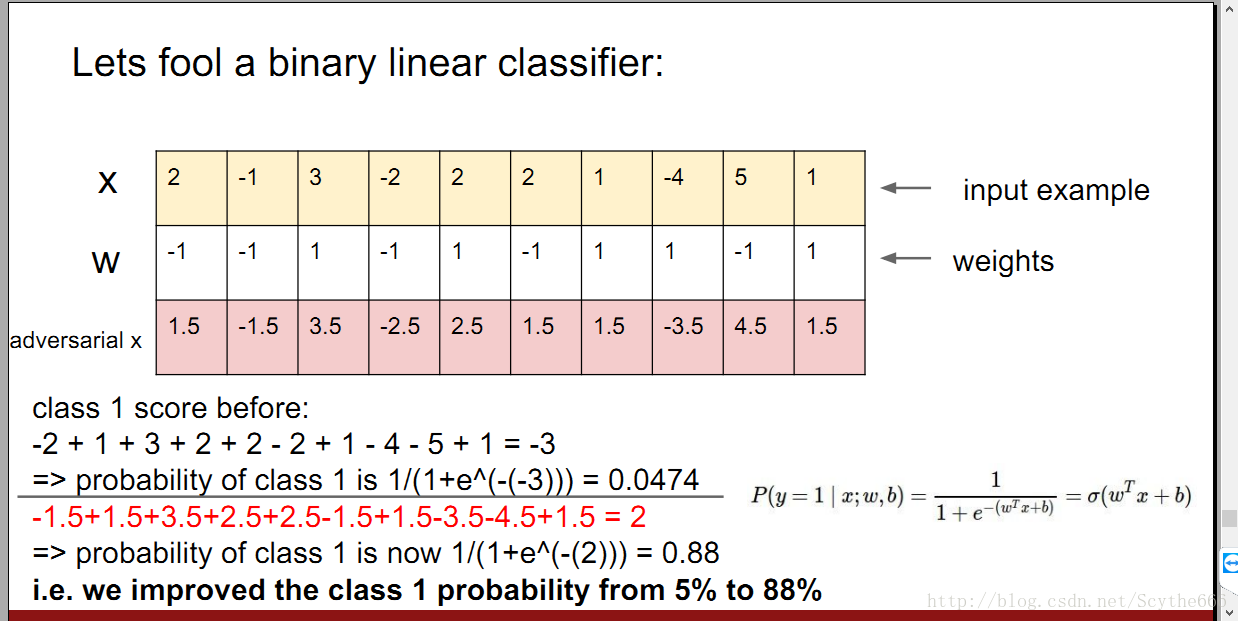

對抗樣本(adversarial example)—這是一種脆弱性,這和影象也沒關,任何data都可以做對抗樣本,目前沒有好的解決方法,是一個好的課題
如果人臉識別被做對抗樣本就可以變成任意一個人
第十講、RNN
RNN因為是不同做重複操作:
所以結果容易要麼爆炸,要麼消失
小技巧控制梯度爆炸:如果梯度大於5,就逐元素裁剪為5 — 梯度裁剪
- RNN有梯度彌散問題
- LSTM能很好的抑制梯度彌散,因為高速細胞只改變了加法運算,不會消失,每次都乘以相同的矩陣
第十一講、cnn實戰
data augmentation
- 翻轉是最常見的augment
random crops
test的時候,10-crops
上下左右中*2(水平翻轉),這十個位置得分取均值
顏色改變,如:對比度,但並不一定常見;還可以對每個畫素做PCA主成分分析,遍歷所有畫素後得到訓練集中的主要顏色有哪些,PCA給出顏色空間中3個主要顏色在哪個方向中變化最劇烈
防止過擬合,可以在forward的時候加一些隨機擾動,比如augment就是一種;還可以dropout+dropconnect;還有Batch Normalization(任一張圖片,因為在不同的batch中,會不同,相當於引入了隨機噪聲)
transfer learning
1、如果自己訓練資料真的很少,可以把pre-trained的網路,當作一個特徵提取器,只train最後一層
2、對於從scratch開始學的層:一般學習率較高,但也不能太高(比如原來網路的1/10);對於finetune的層:就需要更小的learning rate(比如原來的1/100)
3、一般情況下,用同類型的訓練資料好,但是前幾層的feature很general,幾乎所有的影象資料都需要,所以不用太擔心
4、finetune步驟:
step1. 把網路固定,只train後面幾層
step2. 當最後幾層快收斂之後,再對中間層微調

一般來說都不應該從scratch開始訓練,多用finetuning,除非有很大很大dataset
5、(1)三層3*3的layer疊起來,一個neuron可以看到多大
5*5
(2)三個加起來呢?
7*7
(3)引數數量比較

(4)浮點運算量比較
更深的網路,更少的計算就有更強的非線性

6、bottleneck技巧—ch