
Java:hashMap詳解
Java集合:HashMap詳解(JDK 1.8)
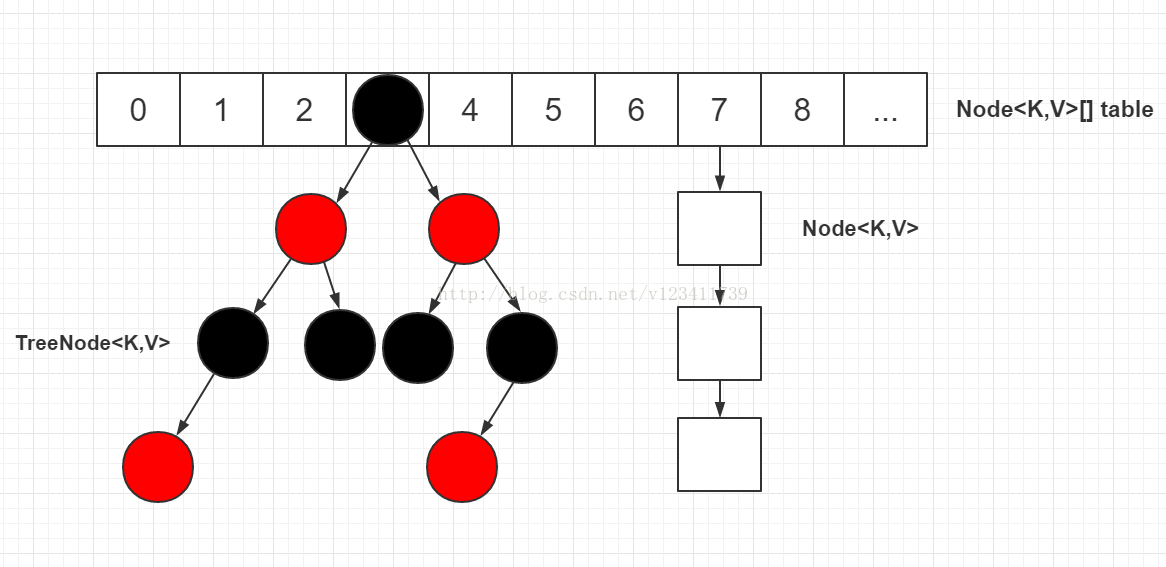
置頂 2018年01月07日 18:00:41 JoonWhee 閱讀數:8495JDK 1.8對HashMap進行了比較大的優化,底層實現由之前的“陣列+連結串列”改為“陣列+連結串列+紅黑樹”,本文就HashMap的幾個常用的重要方法和JDK 1.8之前的死迴圈問題展開學習討論。JDK 1.8的HashMap的資料結構如下圖所示,當連結串列節點較少時仍然是以連結串列存在,當連結串列節點較多時(大於8)會轉為紅黑樹。
幾個點:
先了解以下幾個點,有利於更好的理解HashMap的原始碼和閱讀本文。
- 頭節點指的是table表上索引位置的節點,也就是連結串列的頭節點。
- 根結點(root節點)指的是紅黑樹最上面的那個節點,也就是沒有父節點的節點。
- 紅黑樹的根結點不一定是索引位置的頭結點。
- 轉為紅黑樹節點後,連結串列的結構還存在,通過next屬性維持,紅黑樹節點在進行操作時都會維護連結串列的結構,並不是轉為紅黑樹節點,連結串列結構就不存在了。
- 在紅黑樹上,葉子節點也可能有next節點,因為紅黑樹的結構跟連結串列的結構是互不影響的,不會因為是葉子節點就說該節點已經沒有next節點。
- 原始碼中一些變數定義:如果定義了一個節點p,則pl為p的左節點,pr為p的右節點,pp為p的父節點,ph為p的hash值,pk為p的key值,kc為key的類等等。原始碼中很喜歡在if/for等語句中進行賦值並判斷,請注意。
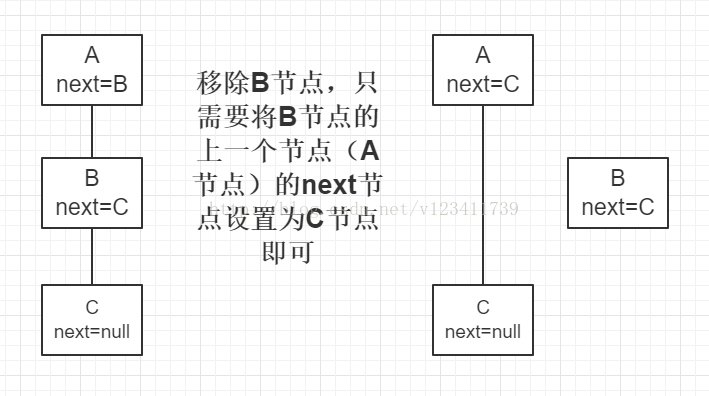
- 連結串列中移除一個節點只需如下圖操作,其他操作同理。
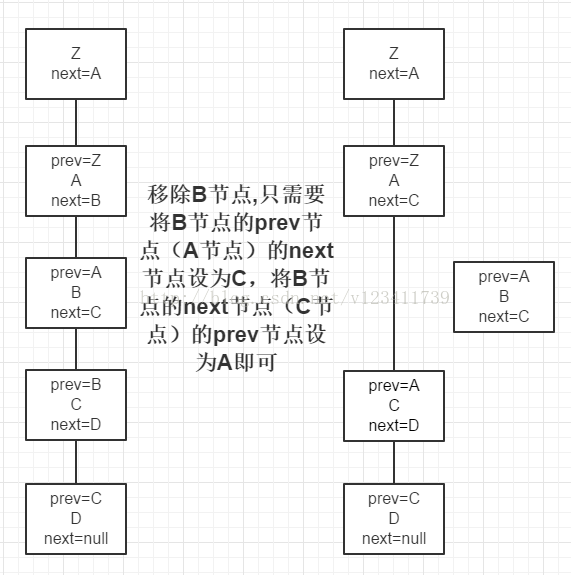
- 紅黑樹在維護連結串列結構時,移除一個節點只需如下圖操作(紅黑樹中增加了一個prev屬性),其他操作同理。注:此處只是紅黑樹維護連結串列結構的操作,紅黑樹還需要單獨進行紅黑樹的移除或者其他操作。
- 原始碼中進行紅黑樹的查詢時,會反覆用到以下兩條規則:1)如果目標節點的hash值小於p節點的hash值,則向p節點的左邊遍歷;否則向p節點的右邊遍歷。2)如果目標節點的key值小於p節點的key值,則向p節點的左邊遍歷;否則向p節點的右邊遍歷。這兩條規則是利用了紅黑樹的特性(左節點<根結點<右節點)。
- 原始碼中進行紅黑樹的查詢時,會用dir(direction)來表示向左還是向右查詢,dir儲存的值是目標節點的hash/key與p節點的hash/key的比較結果。
基本屬性
- /**
- * The default initial capacity - MUST be a power of two.
- */
- static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 預設容量16
- /**
- * The maximum capacity, used if a higher value is implicitly specified
- * by either of the constructors with arguments.
- * MUST be a power of two <= 1<<30.
- */
- static final int MAXIMUM_CAPACITY = 1 << 30; // 最大容量
- /**
- * The load factor used when none specified in constructor.
- */
- static final float DEFAULT_LOAD_FACTOR = 0.75f; // 預設負載因子0.75
- /**
- * The bin count threshold for using a tree rather than list for a
- * bin. Bins are converted to trees when adding an element to a
- * bin with at least this many nodes. The value must be greater
- * than 2 and should be at least 8 to mesh with assumptions in
- * tree removal about conversion back to plain bins upon
- * shrinkage.
- */
- static final int TREEIFY_THRESHOLD = 8; // 連結串列節點轉換紅黑樹節點的閾值, 9個節點轉
- /**
- * The bin count threshold for untreeifying a (split) bin during a
- * resize operation. Should be less than TREEIFY_THRESHOLD, and at
- * most 6 to mesh with shrinkage detection under removal.
- */
- static final int UNTREEIFY_THRESHOLD = 6; // 紅黑樹節點轉換連結串列節點的閾值, 6個節點轉
- /**
- * The smallest table capacity for which bins may be treeified.
- * (Otherwise the table is resized if too many nodes in a bin.)
- * Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
- * between resizing and treeification thresholds.
- */
- static final int MIN_TREEIFY_CAPACITY = 64; // 轉紅黑樹時, table的最小長度
- /**
- * Basic hash bin node, used for most entries. (See below for
- * TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
- */
- static class Node<K,V> implements Map.Entry<K,V> { // 基本hash節點, 繼承自Entry
- final int hash;
- final K key;
- V value;
- Node<K,V> next;
- Node(int hash, K key, V value, Node<K,V> next) {
- this.hash = hash;
- this.key = key;
- this.value = value;
- this.next = next;
- }
- public final K getKey() { return key; }
- public final V getValue() { return value; }
- public final String toString() { return key + "=" + value; }
- public final int hashCode() {
- return Objects.hashCode(key) ^ Objects.hashCode(value);
- }
- public final V setValue(V newValue) {
- V oldValue = value;
- value = newValue;
- return oldValue;
- }
- public final boolean equals(Object o) {
- if (o == this)
- return true;
- if (o instanceof Map.Entry) {
- Map.Entry<?,?> e = (Map.Entry<?,?>)o;
- if (Objects.equals(key, e.getKey()) &&
- Objects.equals(value, e.getValue()))
- return true;
- }
- return false;
- }
- }
- /**
- * Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
- * extends Node) so can be used as extension of either regular or
- * linked node.
- */
- static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {// 紅黑樹節點
- TreeNode<K,V> parent; // red-black tree links
- TreeNode<K,V> left;
- TreeNode<K,V> right;
- TreeNode<K,V> prev; // needed to unlink next upon deletion
- boolean red;
- TreeNode(int hash, K key, V val, Node<K,V> next) {
- super(hash, key, val, next);
- }
- // ...
- }
定位雜湊桶陣列索引位置
不管增加、刪除、查詢鍵值對,定位到雜湊桶陣列的位置都是很關鍵的第一步。前面說過HashMap的資料結構是“陣列+連結串列+紅黑樹”的結合,所以我們當然希望這個HashMap裡面的元素位置儘量分佈均勻些,儘量使得每個位置上的元素數量只有一個,那麼當我們用hash演算法求得這個位置的時候,馬上就可以知道對應位置的元素就是我們要的,不用遍歷連結串列/紅黑樹,大大優化了查詢的效率。HashMap定位陣列索引位置,直接決定了hash方法的離散效能。下面是定位雜湊桶陣列的原始碼:
- // 程式碼1
- static final int hash(Object key) { // 計算key的hash值
- int h;
- // 1.先拿到key的hashCode值; 2.將hashCode的高16位參與運算
- return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
- }
- // 程式碼2
- int n = tab.length;
- // 將(tab.length - 1) 與 hash值進行&運算
- int index = (n - 1) & hash;
整個過程本質上就是三步:
- 拿到key的hashCode值
- 將hashCode的高位參與運算,重新計算hash值
- 將計算出來的hash值與(table.length - 1)進行&運算
方法解讀:
對於任意給定的物件,只要它的hashCode()返回值相同,那麼計算得到的hash值總是相同的。我們首先想到的就是把hash值對table長度取模運算,這樣一來,元素的分佈相對來說是比較均勻的。
但是模運算消耗還是比較大的,我們知道計算機比較快的運算為位運算,因此JDK團隊對取模運算進行了優化,使用上面程式碼2的位與運算來代替模運算。這個方法非常巧妙,它通過 “(table.length -1) & h” 來得到該物件的索引位置,這個優化是基於以下公式:x mod 2^n = x & (2^n - 1)。我們知道HashMap底層陣列的長度總是2的n次方,並且取模運算為“h mod table.length”,對應上面的公式,可以得到該運算等同於“h & (table.length - 1)”。這是HashMap在速度上的優化,因為&比%具有更高的效率。
在JDK1.8的實現中,還優化了高位運算的演算法,將hashCode的高16位與hashCode進行異或運算,主要是為了在table的length較小的時候,讓高位也參與運算,並且不會有太大的開銷。
下圖是一個簡單的例子,table長度為16:

get方法
- public V get(Object key) {
- Node<K,V> e;
- return (e = getNode(hash(key), key)) == null ? null : e.value;
- }
- final Node<K,V> getNode(int hash, Object key) {
- Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
- // table不為空 && table長度大於0 && table索引位置(根據hash值計算出)不為空
- if ((tab = table) != null && (n = tab.length) > 0 &&
- (first = tab[(n - 1) & hash]) != null) {
- if (first.hash == hash && // always check first node
- ((k = first.key) == key || (key != null && key.equals(k))))
- return first; // first的key等於傳入的key則返回first物件
- if ((e = first.next) != null) { // 向下遍歷
- if (first instanceof TreeNode) // 判斷是否為TreeNode
- // 如果是紅黑樹節點,則呼叫紅黑樹的查詢目標節點方法getTreeNode
- return ((TreeNode<K,V>)first).getTreeNode(hash, key);
- // 走到這代表節點為連結串列節點
- do { // 向下遍歷連結串列, 直至找到節點的key和傳入的key相等時,返回該節點
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k))))
- return e;
- } while ((e = e.next) != null);
- }
- }
- return null; // 找不到符合的返回空
- }
- 先對table進行校驗,校驗是否為空,length是否大於0
- 使用table.length - 1和hash值進行位與運算,得出在table上的索引位置,將該索引位置的節點賦值給first節點,校驗該索引位置是否為空
- 檢查first節點的hash值和key是否和入參的一樣,如果一樣則first即為目標節點,直接返回first節點
- 如果first的next節點不為空則繼續遍歷
- 如果first節點為TreeNode,則呼叫getTreeNode方法(見下文程式碼塊1)查詢目標節點
- 如果first節點不為TreeNode,則呼叫普通的遍歷連結串列方法查詢目標節點
- 如果查詢不到目標節點則返回空
程式碼塊1:getTreeNode方法
- final TreeNode<K,V> getTreeNode(int h, Object k) {
- // 使用根結點呼叫find方法
- return ((parent != null) ? root() : this).find(h, k, null);
- }
- 找到呼叫此方法的節點的樹的根節點
- 使用該樹的根節點呼叫find方法(見下文程式碼塊2)
程式碼塊2:find方法
- /**
- * 從呼叫此方法的結點開始查詢, 通過hash值和key找到對應的節點
- * 此處是紅黑樹的遍歷, 紅黑樹是特殊的自平衡二叉查詢樹
- * 平衡二叉查詢樹的特點:左節點<根節點<右節點
- */
- final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
- TreeNode<K,V> p = this; // this為呼叫此方法的節點
- do {
- int ph, dir; K pk;
- TreeNode<K,V> pl = p.left, pr = p.right, q;
- if ((ph = p.hash) > h) // 傳入的hash值小於p節點的hash值, 則往p節點的左邊遍歷
- p = pl; // p賦值為p節點的左節點
- else if (ph < h) // 傳入的hash值大於p節點的hash值, 則往p節點的右邊遍歷
- p = pr; // p賦值為p節點的右節點
- // 傳入的hash值和key值等於p節點的hash值和key值,則p節點為目標節點,返回p節點
- else if ((pk = p.key) == k || (k != null && k.equals(pk)))
- return p;
- else if (pl == null) // p節點的左節點為空則將向右遍歷
- p = pr;
- else if (pr == null) // p節點的右節點為空則向左遍歷
- p = pl;
- else if ((kc != null ||
- // 如果傳入的key(k)所屬的類實現了Comparable介面,則將傳入的key跟p節點的key比較
- (kc = comparableClassFor(k)) != null) && // 此行不為空代表k實現了Comparable
- (dir = compareComparables(kc, k, pk)) != 0)//k<pk則dir<0, k>pk則dir>0
- p = (dir < 0) ? pl : pr; // k < pk則向左遍歷(p賦值為p的左節點), 否則向右遍歷
- // 程式碼走到此處, 代表key所屬類沒有實現Comparable, 直接指定向p的右邊遍歷
- else if ((q = pr.find(h, k, kc)) != null)
- return q;
- else// 程式碼走到此處代表上一個向右遍歷(pr.find(h, k, kc))為空, 因此直接向左遍歷
- p = pl;
- } while (p != null);
- return null;
- }
- 將p節點賦值為呼叫此方法的節點
- 如果傳入的hash值小於p節點的hash值,則往p節點的左邊遍歷
- 如果傳入的hash值大於p節點的hash值,則往p節點的右邊遍歷
- 如果傳入的hash值等於p節點的hash值,並且傳入的key值跟p節點的key值相等, 則該p節點即為目標節點,返回p節點
- 如果p的左節點為空則向右遍歷,反之如果p的右節點為空則向左遍歷
- 如果傳入的key(即程式碼中的引數變數k)所屬的類實現了Comparable介面(kc不為空,comparableClassFor方法見下文程式碼塊3),則將傳入的key跟p節點的key進行比較(kc實現了Comparable介面,因此通過kc的比較方法進行比較),並將比較結果賦值給dir,如果dir<0則代表k<pk,則向p節點的左邊遍歷(pl);否則,向p節點的右邊遍歷(pr)。
- 程式碼走到此處,代表key所屬類沒有實現Comparable,因此直接指定向p的右邊遍歷,如果能找到目標節點則返回
- 程式碼走到此處代表與第7點向右遍歷沒有找到目標節點,因此直接向左邊遍歷
- 以上都找不到目標節點則返回空
程式碼塊3:comparableClassFor方法
- /**
- * Returns x's Class if it is of the form "class C implements
- * Comparable<C>", else null.
- */
- static Class<?> comparableClassFor(Object x) {
- if (x instanceof Comparable) {
- Class<?> c; Type[] ts, as; Type t; ParameterizedType p;
- if ((c = x.getClass()) == String.class) // bypass checks
- return c;
- if ((ts = c.getGenericInterfaces()) != null) {
- for (int i = 0; i < ts.length; ++i) {
- if (((t = ts[i]) instanceof ParameterizedType) &&
- ((p = (ParameterizedType)t).getRawType() ==
- Comparable.class) &&
- (as = p.getActualTypeArguments()) != null &&
- as.length == 1 && as[0] == c) // type arg is c
- return c;
- }
- }
- }
- return null;
- }
如果x實現了Comparable介面,則返回 x的Class。
put方法
- public V put(K key, V value) {
- return putVal(hash(key), key, value, false, true);
- }
- final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
- boolean evict) {
- Node<K,V>[] tab; Node<K,V> p; int n, i;
- // table是否為空或者length等於0, 如果是則呼叫resize方法進行初始化
- if ((tab = table) == null || (n = tab.length) == 0)
- n = (tab = resize()).length;
- // 通過hash值計算索引位置, 如果table表該索引位置節點為空則新增一個
- if ((p = tab[i = (n - 1) & hash]) == null)// 將索引位置的頭節點賦值給p
- tab[i] = newNode(hash, key, value, null);
- else { // table表該索引位置不為空
- Node<K,V> e; K k;
- if (p.hash == hash && // 判斷p節點的hash值和key值是否跟傳入的hash值和key值相等
- ((k = p.key) == key || (key != null && key.equals(k))))
- e = p; // 如果相等, 則p節點即為要查詢的目標節點,賦值給e
- // 判斷p節點是否為TreeNode, 如果是則呼叫紅黑樹的putTreeVal方法查詢目標節點
- else if (p instanceof TreeNode)
- e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
- else { // 走到這代表p節點為普通連結串列節點
- for (int binCount = 0; ; ++binCount) { // 遍歷此連結串列, binCount用於統計節點數
- if ((e = p.next) == null) { // p.next為空代表不存在目標節點則新增一個節點插入連結串列尾部
- p.next = newNode(hash, key, value, null);
- // 計算節點是否超過8個, 減一是因為迴圈是從p節點的下一個節點開始的
- if (binCount >= TREEIFY_THRESHOLD - 1)
- treeifyBin(tab, hash);// 如果超過8個,呼叫treeifyBin方法將該連結串列轉換為紅黑樹
- break;
- }
- if (e.hash == hash && // e節點的hash值和key值都與傳入的相等, 則e即為目標節點,跳出迴圈
- ((k = e.key) == key || (key != null && key.equals(k))))
- break;
- p = e; // 將p指向下一個節點
- }
- }
- // e不為空則代表根據傳入的hash值和key值查詢到了節點,將該節點的value覆蓋,返回oldValue
- if (e != null) {
- V oldValue = e.value;
- if (!onlyIfAbsent || oldValue == null)
- e.value = value;
- afterNodeAccess(e); // 用於LinkedHashMap
- return oldValue;
- }
- }
- ++modCount;
- if (++size > threshold) // 插入節點後超過閾值則進行擴容
- resize();
- afterNodeInsertion(evict); // 用於LinkedHashMap
- return null;
- }
- 校驗table是否為空或者length等於0,如果是則呼叫resize方法(見下文resize方法)進行初始化
- 通過hash值計算索引位置,將該索引位置的頭節點賦值給p節點,如果該索引位置節點為空則使用傳入的引數新增一個節點並放在該索引位置
- 判斷p節點的key和hash值是否跟傳入的相等,如果相等, 則p節點即為要查詢的目標節點,將p節點賦值給e節點
- 如果p節點不是目標節點,則判斷p節點是否為TreeNode,如果是則呼叫紅黑樹的putTreeVal方法(見下文程式碼塊4)查詢目標節點
- 走到這代表p節點為普通連結串列節點,則呼叫普通的連結串列方法進行查詢,並定義變數binCount來統計該連結串列的節點數
- 如果p的next節點為空時,則代表找不到目標節點,則新增一個節點並插入連結串列尾部,並校驗節點數是否超過8個,如果超過則呼叫treeifyBin方法(見下文程式碼塊6)將連結串列節點轉為紅黑樹節點
- 如果遍歷的e節點存在hash值和key值都與傳入的相同,則e節點即為目標節點,跳出迴圈
- 如果e節點不為空,則代表目標節點存在,使用傳入的value覆蓋該節點的value,並返回oldValue
- 如果插入節點後節點數超過閾值,則呼叫resize方法(見下文resize方法)進行擴容
程式碼塊4:putTreeVal方法
- /**
- * Tree version of putVal.
- * 紅黑樹插入會同時維護原來的連結串列屬性, 即原來的next屬性
- */
- final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
- int h, K k, V v) {
- Class<?> kc = null;
- boolean searched = false;
- // 查詢根節點, 索引位置的頭節點並不一定為紅黑樹的根結點
- TreeNode<K,V> root = (parent != null) ? root() : this;
- for (TreeNode<K,V> p = root;;) { // 將根節點賦值給p, 開始遍歷
- int dir, ph; K pk;
- if ((ph = p.hash) > h) // 如果傳入的hash值小於p節點的hash值
- dir = -1; // 則將dir賦值為-1, 代表向p的左邊查詢樹
- else if (ph < h) // 如果傳入的hash值大於p節點的hash值,
- dir = 1; // 則將dir賦值為1, 代表向p的右邊查詢樹
- // 如果傳入的hash值和key值等於p節點的hash值和key值, 則p節點即為目標節點, 返回p節點
- else if ((pk = p.key) == k || (k != null && k.equals(pk)))
- return p;
- // 如果k所屬的類沒有實現Comparable介面 或者 k和p節點的key相等
- else if ((kc == null &&
- (kc = comparableClassFor(k)) == null) ||
- (dir = compareComparables(kc, k, pk)) == 0) {
- if (!searched) { // 第一次符合條件, 該方法只有第一次才執行
- TreeNode<K,V> q, ch;
- searched = true;
- // 從p節點的左節點和右節點分別呼叫find方法進行查詢, 如果查詢到目標節點則返回
- if (((ch = p.left) != null &&
- (q = ch.find(h, k, kc)) != null) ||
- ((ch = p.right) != null &&
- (q = ch.find(h, k, kc)) != null))
- return q;
- }
- // 否則使用定義的一套規則來比較k和p節點的key的大小, 用來決定向左還是向右查詢
- dir = tieBreakOrder(k, pk); // dir<0則代表k<pk,則向p左邊查詢;反之亦然
- }
- TreeNode<K,V> xp = p; // xp賦值為x的父節點,中間變數,用於下面給x的父節點賦值
- // dir<=0則向p左邊查詢,否則向p右邊查詢,如果為null,則代表該位置即為x的目標位置
- if ((p = (dir <= 0) ? p.left : p.right) == null) {
- // 走進來代表已經找到x的位置,只需將x放到該位置即可
- Node<K,V> xpn = xp.next; // xp的next節點
- // 建立新的節點, 其中x的next節點為xpn, 即將x節點插入xp與xpn之間
- TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
- if (dir <= 0) // 如果時dir <= 0, 則代表x節點為xp的左節點
- xp.left = x;
- else // 如果時dir> 0, 則代表x節點為xp的右節點
- xp.right = x;
- xp.next = x; // 將xp的next節點設定為x
- x.parent = x.prev = xp; // 將x的parent和prev節點設定為xp
- // 如果xpn不為空,則將xpn的prev節點設定為x節點,與上文的x節點的next節點對應
- if (xpn != null)
- ((TreeNode<K,V>)xpn).prev = x;
- moveRootToFront(tab, balanceInsertion(root, x)); // 進行紅黑樹的插入平衡調整
- return null;
- }
- }
- }
- 查詢當前紅黑樹的根結點,將根結點賦值給p節點,開始進行查詢
- 如果傳入的hash值小於p節點的hash值,將dir賦值為-1,代表向p的左邊查詢樹
- 如果傳入的hash值大於p節點的hash值, 將dir賦值為1,代表向p的右邊查詢樹
- 如果傳入的hash值等於p節點的hash值,並且傳入的key值跟p節點的key值相等, 則該p節點即為目標節點,返回p節點
- 如果k所屬的類沒有實現Comparable介面,或者k和p節點的key使用compareTo方法比較相等:第一次會從p節點的左節點和右節點分別呼叫find方法(見上文程式碼塊2)進行查詢,如果查詢到目標節點則返回;如果不是第一次或者呼叫find方法沒有找到目標節點,則呼叫tieBreakOrder方法(見下文程式碼塊5)比較k和p節點的key值的大小,以決定向樹的左節點還是右節點查詢。
- 如果dir <= 0則向左節點查詢(p賦值為p.left,並進行下一次迴圈),否則向右節點查詢,如果已經無法繼續查詢(p賦值後為null),則代表該位置即為x的目標位置,另外變數xp用來記錄查詢的最後一個節點,即下文新增的x節點的父節點。
- 以傳入的hash、key、value引數和xp節點的next節點為引數,構建x節點(注意:xp節點在此處可能是葉子節點、沒有左節點的節點、沒有右節點的節點三種情況,即使它是葉子節點,它也可能有next節點,紅黑樹的結構跟連結串列的結構是互不影響的,不會因為某個節點是葉子節點就說它沒有next節點,紅黑樹在進行操作時會同時維護紅黑樹結構和連結串列結構,next屬性就是用來維護連結串列結構的),根據dir的值決定x決定放在xp節點的左節點還是右節點,將xp的next節點設為x,將x的parent和prev節點設為xp,如果原xp的next節點(xpn)不為空, 則將該節點的prev節點設定為x節點, 與上面的將x節點的next節點設定為xpn對應。
- 進行紅黑樹的插入平衡調整,見文末的解釋2。
程式碼塊5:tieBreakOrder方法
相關推薦
Java:hashMap詳解
原 Java集合:HashMap詳解(JDK 1.8) 置頂 2018年01月07日 18:00:41 JoonWhee
java中HashMap詳解
上面方法的程式碼很簡單,但其中包含了一個非常優雅的設計:系統總是將新新增的 Entry 物件放入 table 陣列的 bucketIndex 索引處——如果 bucketIndex 索引處已經有了一個 Entry 物件,那新新增的 Entry 物件指向原有的 Entry 物件(產生一個 Entry 鏈),如果
6. Spring:Java註解技術詳解
6. Spring:Java註解技術詳解 自定義註解示例:https://blog.csdn.net/wangpengzhi19891223/article/details/78131137/ Java註解技術基本概念 Annotation是Java5開始引入的新特徵。中文
java基礎學習總結(二十五):logback詳解
為什麼使用logback logback大約有以下的一些優點: 核心重寫、測試充分、初始化記憶體載入更小,這一切讓logback效能和log4j相比有諸多倍的提升 logback非常自然地直接實現了slf4j,這個嚴格來說算不上優點,只是這樣,再理解slf4j的前提下會很容易理解
Java 併發程式設計: ThreadPoolExecutor 詳解
1. 使用執行緒池能解決兩方面的問題 a) 減少執行緒呼叫開銷,提升效能; b) 通過限制執行緒數量達到限制程式資源佔用的目的; 2. 執行緒建立的規則 &nbs
java程式設計思想讀書筆記三(HashMap詳解)
Map Map介面規定了一系列的操作,作為一個總規範它所定義的方法也是最基礎,最通用的。 AbstractMap AbstractMap是HashMap、TreeMap,、ConcurrentHashMap 等類的父類。當我們巨集觀去理解Map時會發現,其實Map就是一
CCF URL對映 java 100分詳解 :巧妙地動態構造正則表示式
主要想法:將<int>替換成([0-9]+),將<str>替換成([^/]+),將<path>替換成(.+), 例如,/articles/<int>/<int>/<str>/ 替換之後就會變成/art
Java學習:Java集合框架詳解
早在Java 2中之前,Java就提供了特設類。比如:Dictionary, Vector, Stack, 和Properties這些類用來儲存和操作物件組。 雖然這些類都非常有用,但是它們缺少一個核心的,統一的主題。由於這個原因,使用Vector類的方式和使用Properties類的方式有著很
“全棧2019”Java第二十八章:陣列詳解(上篇)
難度 初級 學習時間 10分鐘 適合人群 零基礎 開發語言 Java 開發環境 JDK v11 IntelliJ IDEA v2018.3 文章原文連結 “全棧2019”Java第二十八章:陣列詳解(上篇) 下一章 “全棧2019”Java第二十九章:陣列詳解(中篇)
“全棧2019”Java第三十章:陣列詳解(下篇)
難度 初級 學習時間 10分鐘 適合人群 零基礎 開發語言 Java 開發環境 JDK v11 IntelliJ IDEA v2018.3 文章原文連結 “全棧2019”Java第三十章:陣列詳解(下篇) 下一章 “全棧
“全棧2019”Java第二十九章:陣列詳解(中篇)
難度 初級 學習時間 10分鐘 適合人群 零基礎 開發語言 Java 開發環境 JDK v11 IntelliJ IDEA v2018.3 文章原文連結 “全棧2019”Java第二十九章:陣列詳解(中篇) 下一章 “全
JVM內幕:Java虛擬機器詳解
這篇文章解釋了Java 虛擬機器(JVM)的內部架構。下圖顯示了遵守 Java SE 7 規範的典型的 JVM 核心內部元件。 上圖顯示的元件分兩個章節解釋。第一章討論針對每個執行緒建立的元件,第二章節討論了執行緒無關元件。 執行緒 JVM 系統執行緒
【搞定Java併發程式設計】第9篇:CAS詳解
上一篇:volatile關鍵字詳解:https://blog.csdn.net/pcwl1206/article/details/84881395 目 錄: 一、CAS基本概念 1.1、CAS的定義 1.2、CAS的3個運算元 二、Java如何實現原子操作
【搞定Java併發程式設計】第7篇:Java記憶體模型詳解
上一篇:ThreadLocal詳解:https://blog.csdn.net/pcwl1206/article/details/84859661 其實在Java虛擬機器的學習中,我們或多或少都已經接觸過了有關Java記憶體模型的相關概念(點選檢視),只不過在Java虛擬機器中講的不夠詳細,因此
【搞定Java併發程式設計】第6篇:ThreadLocal詳解
上一篇:synchronized關鍵字:https://blog.csdn.net/pcwl1206/article/details/84849400 目 錄: 1、ThreadLocal是什麼? 2、ThreadLocal使用示例 3、ThreadLocal原始碼分析
Java 資料結構5:Hash詳解
雜湊表 雜湊表也稱散列表(Hash),Hash表是基於健值對(key - value)直接進行訪問的資料結構。但是他的底層是基於陣列的,通過特定的雜湊函式把key對映到陣列的某個下標來加快查詢速度,對於雜湊表來說,查詢元素的複雜度是O(1) 我們來看一下Hash
深入淺出:Java集合類詳解
集合類說明及區別 Collection ├List │├LinkedList │├ArrayList │└Vector │ └Stack └Set Map ├Hashtable ├HashMap └WeakHashMap Collection介面 Collec
Java集合(四)HashMap詳解
HashMap簡介 java.lang.Object ↳ java.util.AbstractMap<K, V> ↳ java.util.HashMap<K, V> public class HashMap<K,V> ex
Java資料結構詳解(十二)- HashMap
HashMap 基於雜湊表的 Map 介面的實現。此實現提供所有可選的對映操作,並允許使用 null 值和 null 鍵。(除了非同步和允許使用 null 之外,HashMap 類與 Hashtable 大致相同。)此類不保證對映的順序,特別是它不保證該順序恆
Java HashMap實現原理2——HashMap詳解
博主的前兩篇文章Java HashMap實現原理0——從hashCode,equals說起,Java HashMap實現原理1——散列表已經講述了HashMap設計的知識點,包括:hashCode(),equals(),散列表結構,雜湊函式、衝突解決等,在散列表