
SQL Server三種表連線原理
在SQL Server資料庫中,查詢優化器在處理表連線時,通常會使用一下三種連線方式:
-
-
- 巢狀迴圈連線(Nested Loop Join)
- 合併連線 (Merge Join)
- Hash連線 (Hash Join)
-
充分理解這三種表連線工作原理,可以使我們在優化SQL Server連線方面的程式碼有據可依,為開展優化工作提供一定的思路。接下來我們來認識下這三種連線。
1. 巢狀迴圈連線(Nested Loop Join)
該連線方式通常在小資料量並且語句比較簡單的場景中使用,也是比較常見的連線方式,比如以下示例:
1: use AdventureWorks2008
2: go
3: SELECT H.*
4: FROM Sales.SalesOrderHeader H
5: JOIN Sales.Sale
1: use AdventureWorks2008
sOrderDetail D
6: ON H.SalesOrderID=D.SalesOrderID
7: WHERE H.SalesOrderID = 43659
AdventureWorks2008資料庫是SQL Server的一個sample,你可以在微軟官方網站上自由下載。http://msftdbprodsamples.codeplex.com/releases/view/37109
我們在資料庫中執行這段程式碼:

通過執行計劃我們可以看到,資料庫的優化器使用了巢狀連線(Neasted Loops),上面第一行中的Sales.SalesOrderHeader表因為只有一行資料所以做為外部表使用,SalesOrderDetail有12行資料做為內部表使用。
巢狀迴圈的工作原理如圖所示:
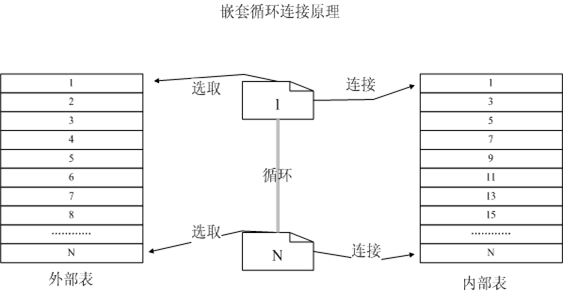
圖1 巢狀迴圈工作原理圖
其原理就是根據條件從表中過濾出一個外部連結表,迴圈的從外部表中讀取一行資料,去內部表中進行匹配,偽碼如下:
For (i=0;i< Number of outerTable Row;i++)
{
OuterTable[i] connect InnerTable[1,2.....N] To Create New Row
WHERE OuterTable[i].data.value = OuterTable[1,2.....N].data.Value
}
瞭解巢狀的工作原理後,我們不難發現,這種連線的方式具有一定的侷限性的:
1. 因為演算法是迴圈進行的,所以比較適合資料量較小的表進行連線,尤其是外部表的資料。
2. 兩張表最好是排序的。表中的條件列和連線列最好有索引,尤其是內部表必須有索引,這樣工作效率會成倍增加。
當外部表較小,而內部表較大並且連線欄位上有索引的情況下,迴圈巢狀非常高效。並且巢狀迴圈是三種方式中唯一支援不等式連線的方式。
2. 合併連線 (Merge Join)
在SQL Server資料庫中,如果查詢優化器,發現要連線的兩張物件表,在連線列上都已經排序幷包含索引,那麼優化器將會極大可能選擇“合併”連線策略。條件是:兩個表都是排序的,並且表連線條件中至少有一個等號連線,查詢分析器會去選擇合併連線。
程式碼示例:
1: USE AdventureWorks2008
2:
3: GO
4:
5: SELECT P.*
6:
7: FROM Production.ProductModel P
8:
9: JOIN Production.ProductModelProductDescriptionCulture PPMD
10:
11: ON P.ProductModelID = PPMD.ProductModelID
根據執行計劃我們可以看到,這次的連線操作使用的合併連線:
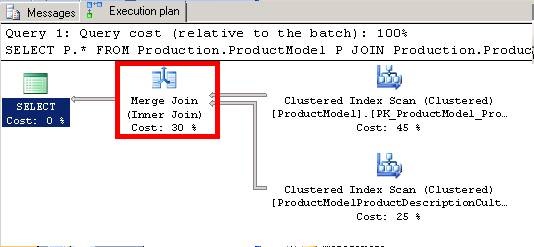
這兩張表中,資料量分別為128和762行資料,連線列是表中的主鍵並且資料是有序的,因此資料庫的查詢優化器自動選擇了合併連線。合併連線的工作原理如下圖所示:
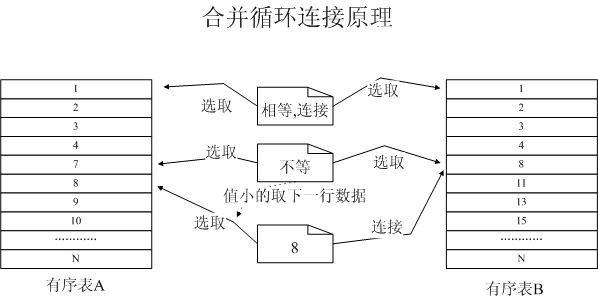
圖2 合併連線的工作原理
資料庫優化器在決定使用合併連線後,並行的在兩個表(術語叫輸入集合)中各取第一行資料,進行匹配,匹配則返回匹配行並進行連線。如果不匹配,那麼小的那一個表(輸入集合),則順序取下一行資料繼續嘗試匹配。
通過其工作原理我們可以發現,合併連線可以看成是一個類似於併發工作機制。操作分別在兩個表(輸入集合)依次獲取資料並進行比較,這就要求兩張表是有序的,有序的排列會極大的提高工作的效率。
有關表排序的問題,如果連線語句中使用Sort關鍵字來排序資料表,那麼SQL Server的優化器會比較傾向於Hash Join。在合併連線中,並不排斥order by, group by, distinct等關鍵字,在使用這些語句時,查詢優化器也有極大的可能選擇合併連線。
當我們使用一些查詢限定條件,比如不等式(>,<,>=等)限定條件範圍,那麼合併連線的效率會有更好。
合併連線的限定條件:
1. 兩張表的連線列需要排序
2. 連線列必須有索引
3. 雜湊連線(Hash Join)
當我們嘗試將兩張資料量較大,沒有排序和索引的兩張表進行連線時,SQL Server的查詢優化器會嘗試使用Hash Join。
程式碼示例:
1: SELECT *
2:
3: FROM Production.Product P
4:
5: Join Production.ProductSubcategory SPC
6:
7: on P.ProductSubcategoryID = SPC.ProductSubcategoryID
根據執行計劃我們可以看到,這次的連線操作使用的雜湊連線:

該連線在處理大量無序的資料時,效率較高,但是對處理器和記憶體資源的消耗較大。實現過程如下:
Hash Join連線的執行操作分為兩個階段,建立和探測。
建立是指對輸入表進行的一系列的操作。首先優化器會將輸入表中的每一行資料掃描到系統記憶體中,然後根據內建的雜湊演算法計算出相應雜湊值,相同雜湊值的資料會被分到一個Hash池中。這些雜湊值和資料地址儲存在一個Hash表中,提供給探測使用。通常優化器會選擇資料較少的表作為建立輸入表。
建立完成後,開始探查工作。另一個連線表(我們叫探查輸入)同樣會被逐行的掃描、計算,得出一個Hash值。連線操作會使用探查輸入的Hash值和建立輸入的Hash值列表進行掃描和匹配工作,最終建立連線。
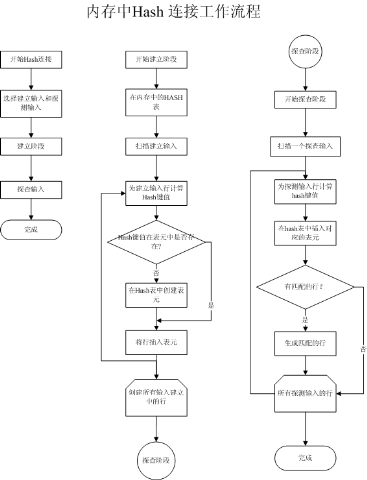
上圖是Hash連線的工作流程,接下來我們可以來了解下雜湊演算法的實現的機制,以下的內容是個人對演算法的理解,若有偏頗請指正。
Hash的實際含義是“雜湊”的意思,它主要的功能就是將一組資料,通過演算法,變換成固定長度的輸出,這個輸出我們就稱之為雜湊值(Hash值),通常在安全領域,如密碼學中使用較多。
在SQL Server裡面雜湊雜湊函式是黑盒的,沒有具體的演算法可以參考。實際上很多開發人員在解決海量資料查詢的時候,都會採用Hash方式,並且開發適合需求的雜湊演算法。常用的一些演算法包括一些取餘、MD2、MD4、MD5 和 SHA-1等等。
因為演算法,不同的資料可能會生成相同的雜湊值。它將大量的資料按照規則分散到不同資料堆或者連結串列中,建立內部的對映關係。我們可以認為他是將陣列和連結串列結合在一起,想要達到一種定址容易、插入刪除方便的資料結構,而Hash表就是一種資料內容和資料存放地址之間的對映關係。
雜湊函式的選擇會決定影響Hash表元數量大小和每個鍵值包含的資料多少,這個是數學上的問題這裡不進行進一步討論。
說到這裡,可能大家還是不太理解,我們這裡舉例來說明:
比如說有兩張表:
表A{A,F,C,D,B,E……}
表B{F,B,E,D,A,F…….}
並且表A的資料量小於表B,這兩張表進行Hash連線的過程如下:
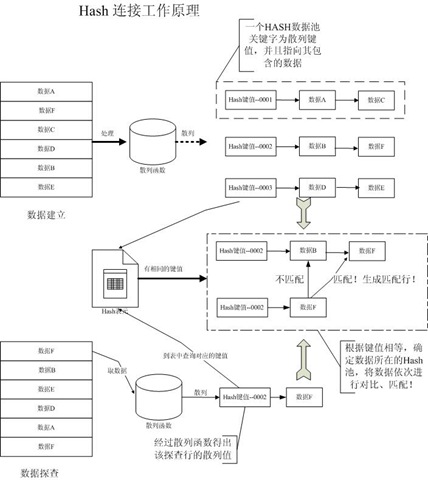
1. 首先資料庫會將表A中的所有資料,掃描存入記憶體中。
2. 記憶體中的表A的資料,經過雜湊函式依次得到對應的雜湊值(Hash值)。
3. 表A中相同雜湊值(鍵值)的資料,會統一的放入到一個Hash池中。個人認為Hash池中的資料,就是陣列和連結串列的集合。Hash的鍵值可以看到是一個數組的下標,而池中的資料以連結串列的形式連線在陣列中。
Hash【鍵值】-->資料1-->資料2..............
如圖中的一組資料,資料A和資料C具有相同的Hash值,值為001,那麼他們都被分配到以001命名的Hash池中。
4. 將Hash值和對應的資料,依次存入到一個Hash表中,建立結束。
5. 探測階段,資料庫依次讀取掃描表B中的每一行資料,並通過雜湊函式計算出一個Hash值。
6. 根據Hash值,去Hash表中和表A的鍵值進行匹配,找到對應的Hash池。
7. 接下來將表B的資料去和對應的Hash池中的每條資料,去對比和匹配。如果匹配成功則進行資料連線。
通過對原理的瞭解,我們可以看到這種連線方式,需要大量的計算操作,對CPU帶來一定的壓力。通常Hash 連線操作在記憶體中進行,如果記憶體不足,資料庫會將資料寫入到硬碟中,影響效能。
4.小結
三種連線方式的特點:
| 型別 |
連線列上索引 |
表的大小 |
排序 |
連線子句 |
| 巢狀 |
內部表:必須 外部表:有最好 |
小 |
可選 |
所有型別 |
| 合併 |
內部表:必須 聚簇索引或者覆蓋索引 外部表:必須 聚簇索引或者覆蓋索引 |
大 |
需要 |
Equi-join |
| HASH |
內部表:不需要 外部表:可選,最好有 小的外部表,大得內部表 |
任意 |
不需要 |
Equi-join |
三種方式對資源的壓力:
| 巢狀迴圈連線 |
合併連線 |
雜湊連線 |
|
| CPU |
低 |
低(如果沒有顯式排序) |
高 |
| 記憶體 |
低 |
低(如果沒有顯式排序) |
高 |
| IO |
可能高可能低 |
低 |
可能高可能低 |
以上是個人對三種連線的個人理解,不當之處請指正。
題外話:
其實我們可以把這三種連線比喻成相親。
巢狀連線就是熟人介紹,親戚朋友根據你的條件,搜尋下週圍的資源,然後安排你和幾個姑娘見面,看看能不能匹配上。如果你的條件很明確(外部表索引),並且朋友對姑娘比較熟悉,對方的要求也很明確(內部表索引),那麼成功率就會比較高。
合併連線就是社群或者網站組織的小型相親聯誼會,比如電影《戀愛33天中》那種8分鐘面對面的形式。男女雙方面對面進行交談(匹配判斷),每幾分鐘就換一個人再次交談,由於大家條件和目的性明確(都有索引),所以整個流程效率會比較高。
Hash連線則就像是萬人相親大會,比如上海的中山公園(條件好的已婚人士慎入)。單身青年的父母,入園後由於各種原因隨機的分成各個小群組(經過雜湊函式分成Hash池)。然後參與者根據自己的判斷(確認Hash鍵值),找到合適小組後(Hash鍵值相等),依次交談交換條件和資訊(嘗試匹配),看看裡面有沒有合適人選,有就進一步瞭解(匹配成功,連線)。