
python爬蟲相關知識整理
1.徹底理解cookie,session,token
2.反爬蟲技巧
3.python(字元編碼)
檔案以什麼編碼儲存的,就以什麼編碼方式開啟。而檔案編碼儲存時候使用的編碼方式是右下角的編碼方式,而解碼的時候是使用文件開頭申明的編碼方式,兩種編碼不同的時候很容易出現亂碼的情況
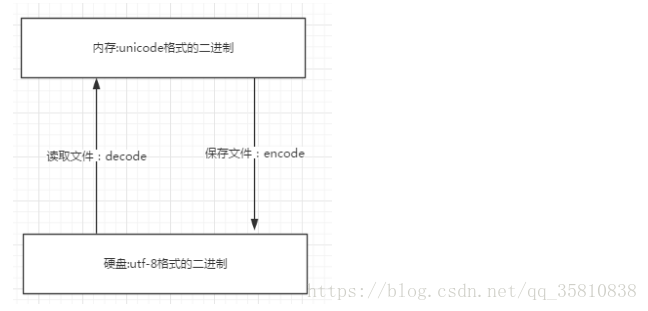
編碼:將字串轉為位元組碼 encode 適合計算機看
解碼:將位元組碼轉換為字串 decode 適合我們看
-----------------------------------------------------------------------------------------------------
字串存到檔案中(硬碟上),字元的unicode是不能直接儲存的,必須以一種編碼方式(utf8)轉為連續的位元組(bytes)
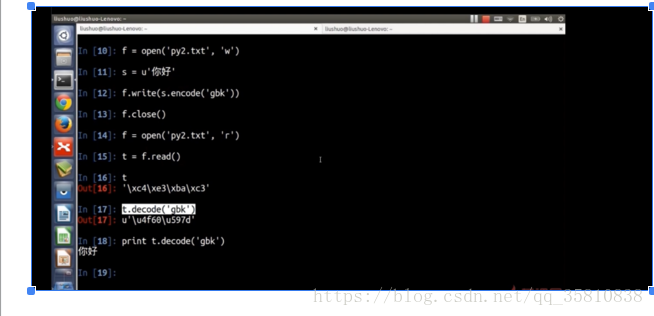
在python2中,字元有兩種型別(str (已經編碼後的位元組序列) unicode(編碼前的文字字元))
python2中文字檔案的讀寫
python3中的兩種字元型別(str(編碼過得unicode文字字元,雙引號,單引號) bytes(編碼前的位元組序列))
可以認為字串有兩種狀態,即文字狀態和位元組(二進位制)狀態。Python2 和 Python3 中的兩種字元型別都分別對應這兩種狀態,然後相互之間進行編解碼轉化。
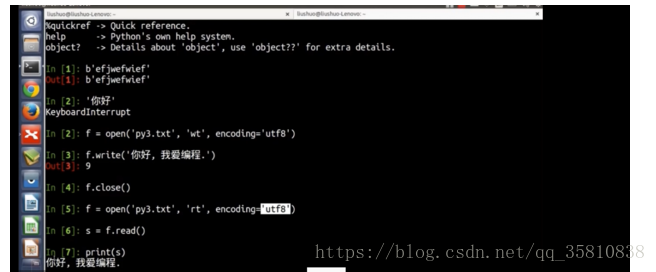
python2在檔案讀寫時用encode,decode解決。python3用encoding解決
檢視Python預設編碼方式
print(sys.getdefaultencoding()) #python3 print sys.getdefaultencoding() #python2
Python2 中,str 和 unicode 都有 encode 和 decode 方法。但是不建議對 str 使用 encode,對 unicode 使用 decode, 這是 Python2 設計上的缺陷。
Python3 則進行了優化,str 只有一個 encode 方法將字串轉化為一個位元組碼,而且 bytes 也只有一個 decode 方法將位元組碼轉化為一個文字字串。
Python2 的 str 和 unicode 都是 basestring 的子類,所以兩者可以直接進行拼接操作。而 Python3 中的 bytes 和 str 是兩個獨立的型別,兩者不能進行拼接。
Python2 中,普通的,用引號括起來的字元,就是 str;此時字串的編碼型別,對應著你的 Python 檔案本身儲存為何種編碼有關,最常見的 Windows 平臺中,預設用的是 GBK。Python3 中,被單引號或雙引號括起來的字串,就已經是 Unicode 型別的 str 了。
ython3預設是'utf-8'編碼,字串str為unicode,當儲存到檔案時需要轉換為bytes,讀取是要轉換為str(unicode)的形式,檔案的讀寫是,encoding這個引數會幫我們自動完成,這就是python3的優勢。