
《Statistical Analysis with Missing Data》習題1.6
題目


解答
由於題目要求需要重複三次類似的操作,故首先載入所需要的包,構造生成資料的函式以及繪圖的函式:
library(tidyr) # 繪圖所需 library(ggplot2) # 繪圖所需 # 生成資料 GenerateData <- function(a = 0, b = 0, seed = 2018) { set.seed(seed) z1 <- rnorm(100) z2 <- rnorm(100) z3 <- rnorm(100) y1 <- 1 + z1 y2 <- 5 + 2 * z1 + z2 u <- a * (y1 - 1) + b * (y2 - 5) + z3 m2 <- 1 * (u < 0) y2_na <- y2 y2_na[u < 0] <- NA # y2_na[as.logical(m2)] <- NA dat_comp <- data.frame(y1 = y1, y2 = y2) dat_incomp <- data.frame(y1 = y1, y2 = y2_na) dat_incomp <- na.omit(dat_incomp) return(list(dat_comp = dat_comp, dat_incomp = dat_incomp)) } # 展現缺失出具與未缺失資料的分佈情況 PlotTwoDistribution <- function(dat) { p1 <- dat_comp %>% gather(y1, y2, key = "var", value = "value") %>% ggplot(aes(x = value)) + geom_histogram(aes(fill = factor(var), y = ..density..), alpha = 0.3, colour = 'black') + stat_density(geom = 'line', position = 'identity', size = 1.5, aes(colour = factor(var))) + facet_wrap(~ var, ncol = 2) + labs(y = '直方圖與密度曲線', x = '值', title = '完整無缺失資料', fill = '變數') + theme(plot.title = element_text(hjust = 0.5)) + guides(color = FALSE) p2 <- dat_incomp %>% gather(y1, y2, key = "var", value = "value") %>% ggplot(aes(x = value)) + geom_histogram(aes(fill = factor(var), y = ..density..), alpha = 0.3, colour = 'black') + stat_density(geom = 'line', position = 'identity', size = 1.5, aes(colour = factor(var))) + facet_wrap(~ var, ncol = 2) + labs(y = '直方圖與密度曲線', x = '值', title = '有缺失資料', fill = '變數') + theme(plot.title = element_text(hjust = 0.5)) + guides(color = FALSE) return(list(p_comp = p1, p_incomp = p2)) }
下面考慮三種情況:
1. a = 0, b = 0
a) 生成資料並繪圖展示
# 生成資料並檢視資料樣式
dat <- GenerateData(a = 0, b = 0)
dat_comp <- dat$dat_comp
dat_incomp <- dat$dat_incomp
head(dat_comp)
head(dat_incomp)
# 繪圖展示
p <- PlotTwoDistribution(dat)
p$p_comp
p$p_incomp
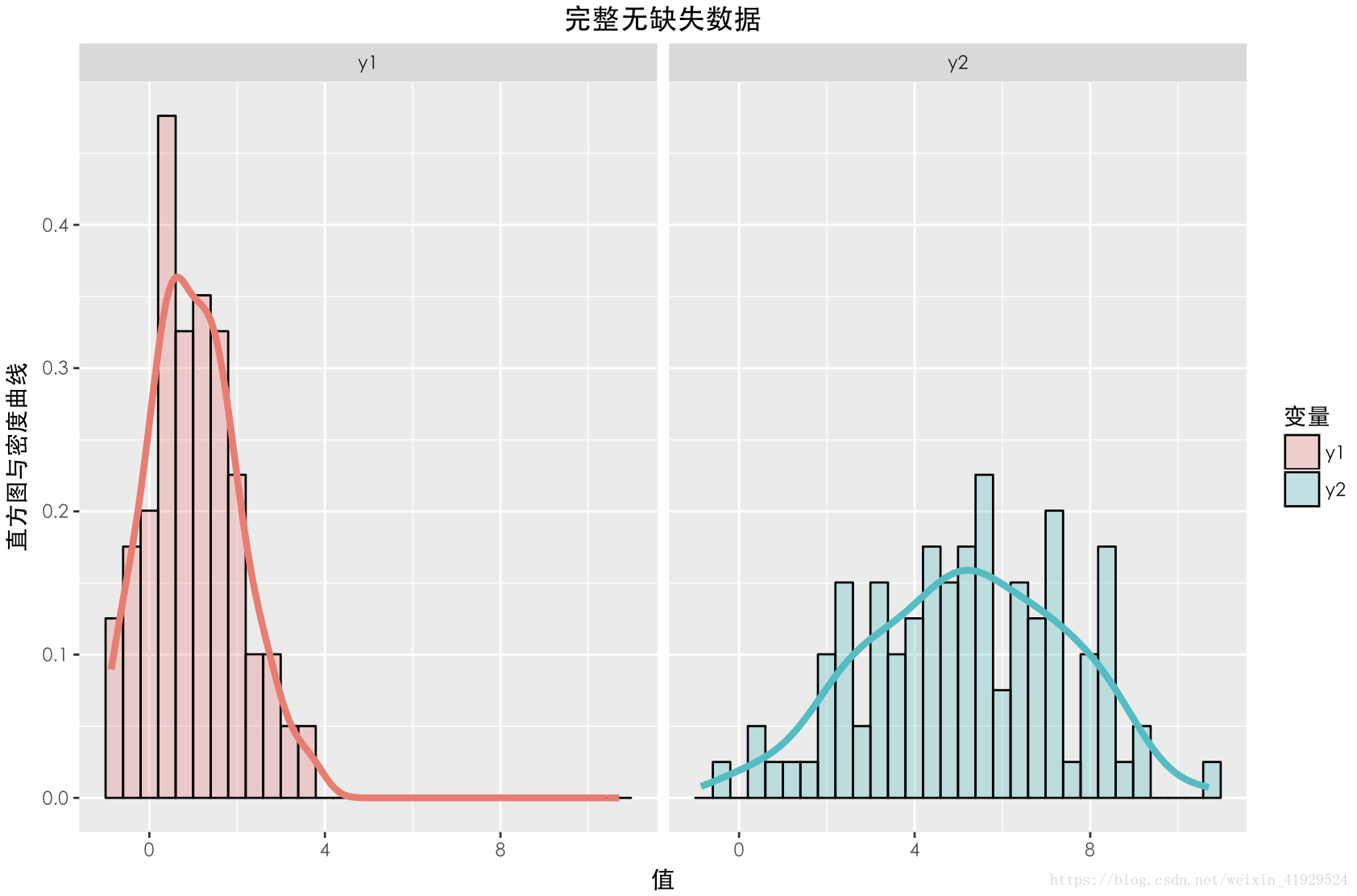
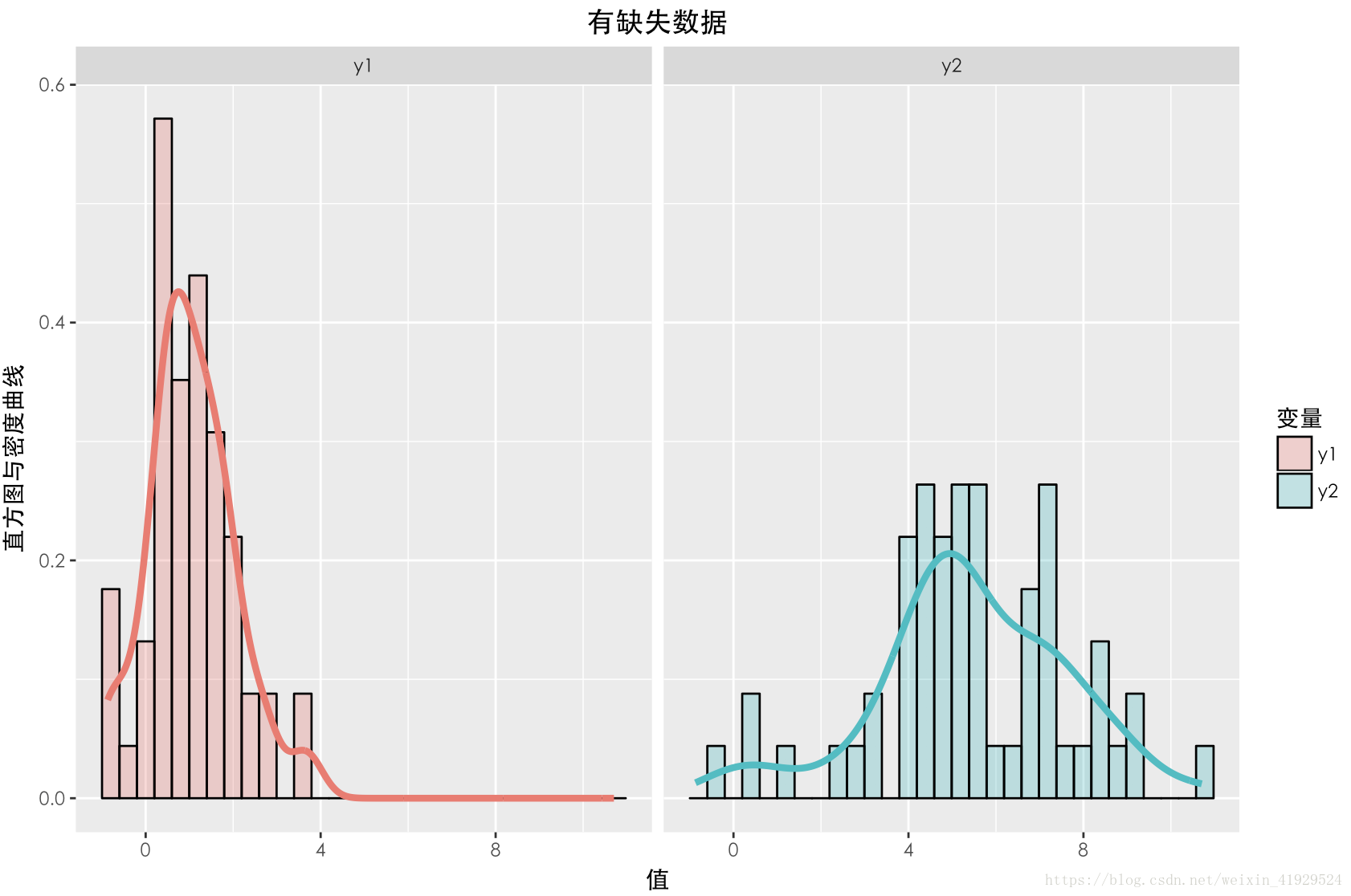
缺失資料與未缺失資料的分佈如上圖所示。可以發現,對於完整資料與缺失資料之間的的分佈與的分佈與期望相差不大。並且在採用這種構造時,從構造的公式可以看出,中樣本的缺失情況與兩者都無關(因為與均獨立),所以這種缺失機制是:MCAR。
b) 進行t檢驗
題設條件中說的是的均值,所以考慮完整資料與缺失資料(這裡的缺失指的是若有缺失,也會進行相應地缺失處理)
t.test(dat_comp$y1, dat_incomp$y1)
這裡進行t檢驗(其實不是非常嚴謹,因為不一定滿足正態假設),比較缺失與否的均值,這裡p-value = 0.8334。在顯著性水平為0.05的前提下,並不能斷言有缺失與無缺失兩個之間的均值有差異,也就是說其實MCAR, MAR, NMAR三種情況都有可能,並不能斷言哪種不可能發生。
2. a = 2, b = 0
a) 生成資料並繪圖展示
# 生成資料並檢視資料樣式
dat <- GenerateData(a = 2, b = 0)
dat_comp <- dat$dat_comp
dat_incomp <- dat$dat_incomp
head(dat_comp)
head(dat_incomp)
# 繪圖展示
p <- PlotTwoDistribution(dat)
p$p_comp
p$p_incomp
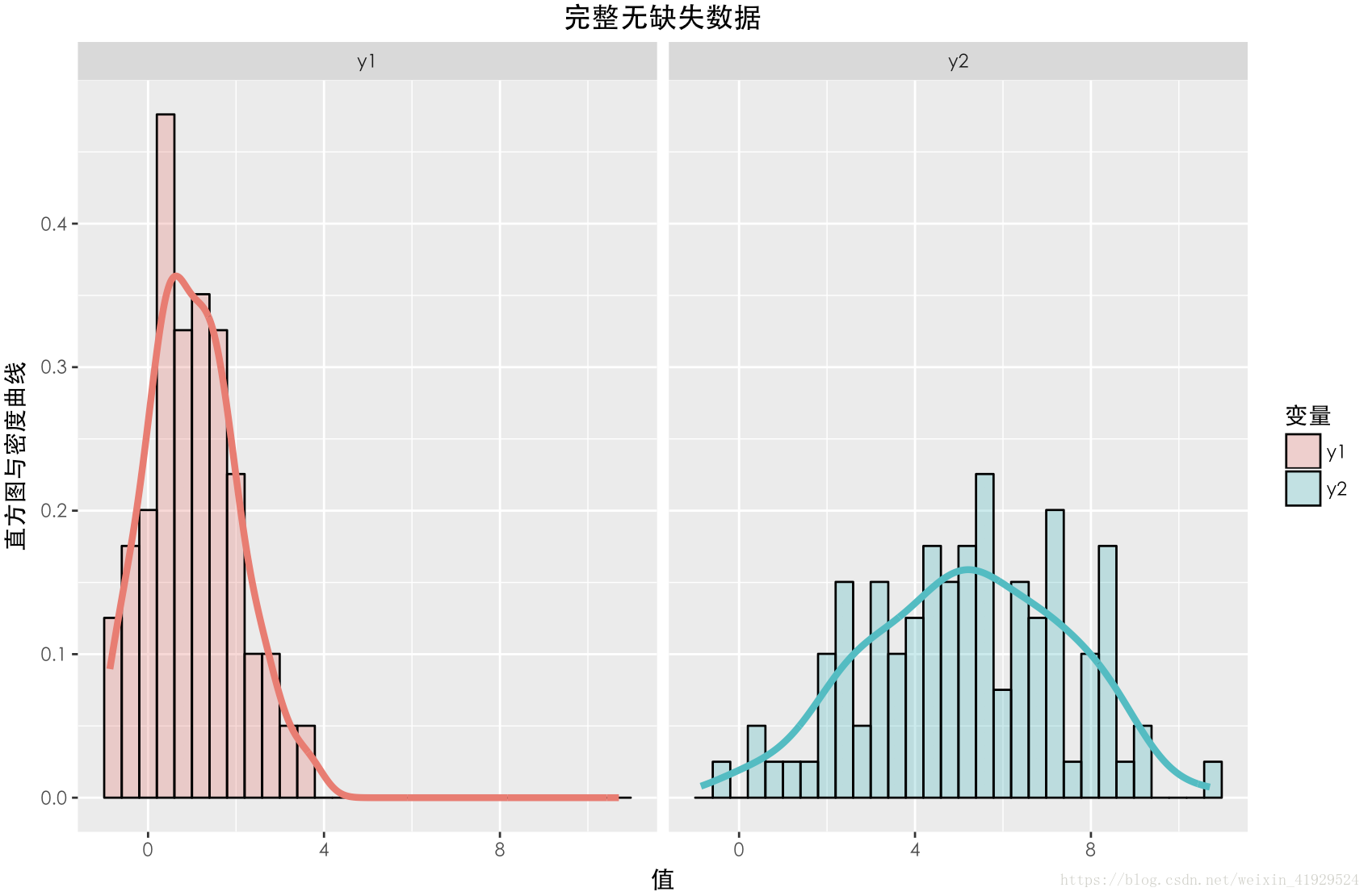
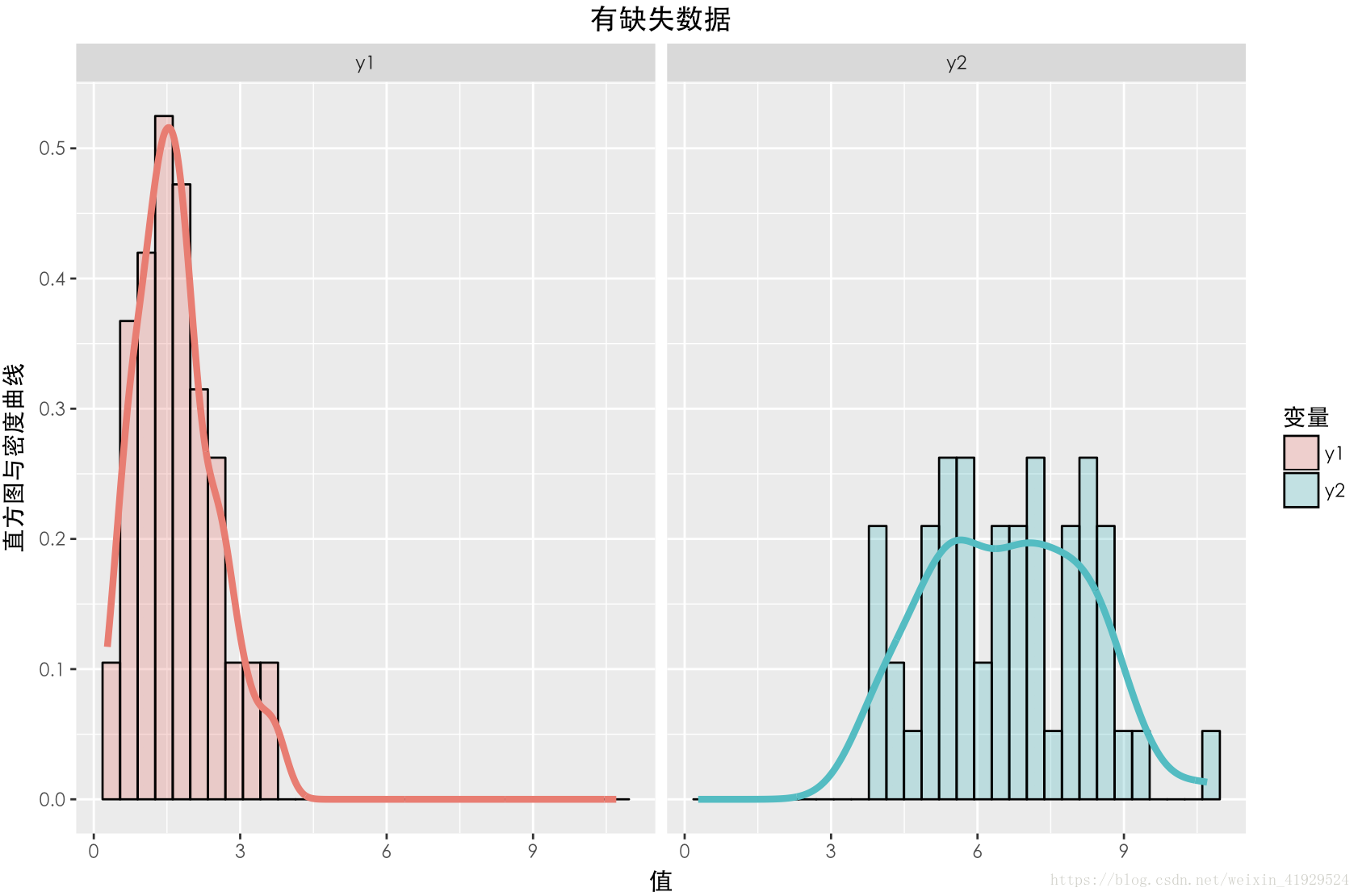
缺失資料與未缺失資料的分佈如上圖所示。可以發現,兩個資料的期望以及分佈(無論還是),整體都有一定差異。在採用這種構造時,從構造的公式可以看出,中樣本的缺失情況與有關,所以這種缺失機制是:MAR。
b) 進行t檢驗
t.test(dat_comp$y1, dat_incomp$y1)
這裡進行t檢驗(其實不是非常嚴謹,因為不一定滿足正態假設),比較缺失與否的均值,這裡p-value = ,p-value非常小,說明不是MCAR,但有可能是NMAR, MAR這兩種情況。NMAR自不必提,有可能為MAR是因為,雖然是缺失,但其如果為MAR是有可能與有關的,這樣就會出現對進行t檢驗為顯著的情況。
3. a = 0, b = 2
a) 生成資料並繪圖展示
# 生成資料並檢視資料樣式
dat <- GenerateData(a = 0, b = 2)
dat_comp <- dat$dat_comp
dat_incomp <- dat$dat_incomp
head(dat_comp)
head(dat_incomp)
# 繪圖展示
p <- PlotTwoDistribution(dat)
p$p_comp
p$p_incomp
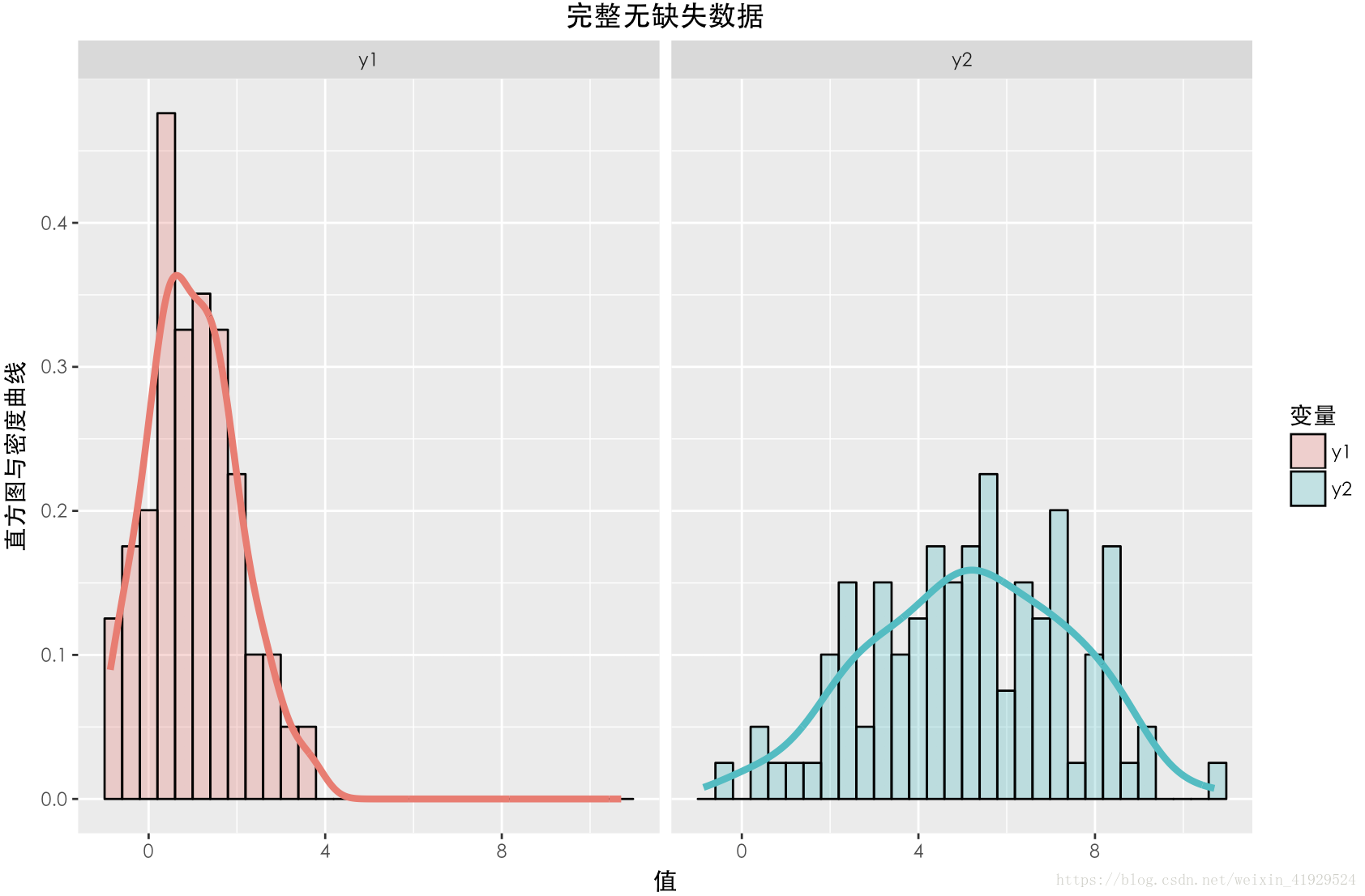
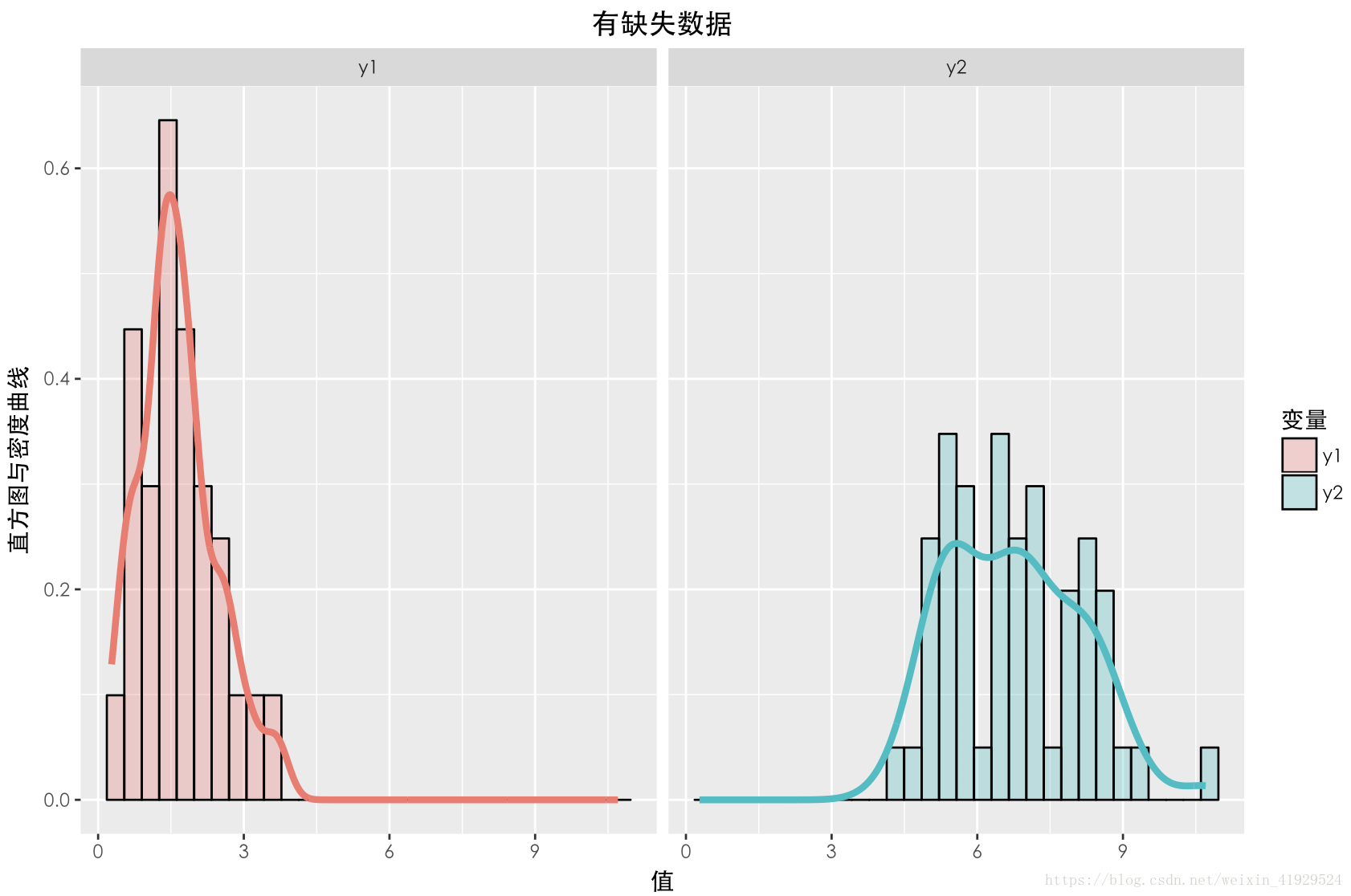
缺失資料與未缺失資料的分佈如上圖所示。可以發現與上一種情況一樣,兩個資料的期望以及分佈(無論還是),整體都有一定差異。在採用這種構造時,從構造的公式可以看出,中樣本的缺失情況與本身有關,所以這種缺失機制是:NMAR。
b) 進行t檢驗
t.test(dat_comp$y1, dat_incomp$y1)
這裡進行t檢驗(其實不是非常嚴謹,因為不一定滿足正態假設),比較缺失與否的均值,這裡p-value = ,p-value同樣非常小,說明不是MCAR,但有可能是NMAR, MAR這兩種情況。