
計算機系統結構--複習(Part 1)
適用於期末考試之前的知識點複習.
往期回顧:
Part 1(chapter 1 - chapter 5):https://blog.csdn.net/zongza/article/details/83780572
Part 2(chapter 5 - chapter 10):https://blog.csdn.net/zongza/article/details/83933327
Part 3(概念專輯):https://blog.csdn.net/zongza/article/details/84100133
Part 4(習題專輯):https://blog.csdn.net/zongza/article/details/84111578
資料下載:
計算機體系結構-量化研究方法-Hennessy&Patterson著(英文版):https://download.csdn.net/download/zongza/10787837
計算機體系結構-量化研究方法-Hennessy&Patterson著(中文版):https://download.csdn.net/download/zongza/10787840
計算機系統結構教程-第二版-張晨曦著:https://download.csdn.net/download/zongza/10787843
計算機體系結構教程-學習指導與題解:https://download.csdn.net/download/zongza/10793886
Chapter 1 Introduction
nClasses of Computers * 計算機種類
nMoore’s Law * 摩爾定律
nWhat is Computer Architecture * 兩個概念
- qclassical definition 概念性結構和功能特性
- qbroadest definition 抽象層設計
- q計算機系統結構與計算機組成、實現的關係
nAttributes of a System as seen by the Programmer 程式設計師看到的計算機屬性
計算機種類
1、巨型計算機(Supercomputer),也稱超級計算機,它採用了大規模並行處理的體系結構,CPU由數以百計、千計的處理器組成,有極強的運算處理能力,大多5使用在軍事、科研、氣象、石油勘探等領域。
2、小巨型計算機(Mini Supercomputer),與巨型機相同,但使用了更加先進的大規模積體電路與製造技術,因而體積小、成本低,甚至可以做成桌面機形式,放在使用者的辦公桌上,便於巨型機的推廣使用。
3、主機(Mainframe),或稱主幹機、大型機。
4、小型計算機(Super Minicomputer)
5、工作站(Workstation),指SGI、SUN、DEC、HP、IBM等大公司推出的具有高速運算能力和很強圖形處理功能的計算機。
6、個人計算機(Personal Computer),也稱個人電腦(PC機)或微型計算機,它們價格便宜、效能不斷提高,適合個人辦公或家庭使用。
摩爾定律:
1、積體電路晶片上所整合的電路的數目,每隔18個月就翻一番。
2、微處理器的效能每隔18個月提高一倍,而價格下降一倍。
什麼是計算機系統結構:
classical definition--程式設計師所看到的計算機的屬性,即程式設計師編寫出的能在機器上正確執行的程式所必須瞭解到的概念性結構和功能特性。
broadest definition(寬泛定義)--使用各種可行的製造工藝進行抽象層的設計,使得應用程式有效執行。


上圖為傳統的系統結構定義示例:系統結構是處在物理層和應用層之間的一層抽象。
下圖中顯示了將系統結構進行細分的若干子層次,以及定義的發展趨勢:+-到ISA到CPU IO MEM MP 到網路



計算機系統結構與計算機組成、實現的關係:
傳統機器級的系統結構,軟體與硬體/韌體的交接面,是機器語言、組合語言程式設計者,或編譯程式設計者看到的機器物理系統的抽象。可以看作和ISA完全劃等號,但是對於現代的CA,ISA只是他的一個子集,CA還會包括Design of CPU, memory system, I/O system, Multiprocessors
•系統結構 指的計算機系統中對各級之間介面的定義及其上下的功能分配。
•組成 指結構的邏輯實現,包括機器級內的資料流和控制流的組成以及邏輯設計等。
•實現 指組成的物理實現,著眼於器件技術和微組裝技術。
指令系統(ISA)的確定屬於系統結構
取指、取運算元、運算送結果等具體操作及其排序方式屬於組成
具體電路、器件的設計及裝配技術等屬於實現
計算機系統“從中間開始設計”方法中的中間是指什麼地方,這樣設計有什麼好處?
中間指軟硬體交介面,也就是抽象層的設計,在傳統機器語言和作業系統機器級之間,好處是軟硬可以並行設計,縮短週期。
程式設計師看到的計算機屬性:
(1) 資料表示(硬體能直接辯認和處理的資料型別)
(2) 定址規則(包括最小定址單元、定址方式及其表示)
(3) 暫存器定義(包括各種暫存器的定義、數量和使用方式)
(4) 指令集(包括機器指令的操作型別和格式、指令間的排序和控制機構等)
(5) 中斷系統(中斷的型別和中斷響應硬體的功能等)
(6) 機器工作狀態的定義和切換 (如管態和目態等)
(7) 儲存系統(主存容量、程式設計師可用的最大儲存容量等)
(8) 資訊保護(包括資訊保護方式和硬體對資訊保護的支援)
(9) I/O結構(包括I/O連線方式、處理機/儲存器與I/O裝置 間資料傳送的方式和格式以及I/O操作的狀態等)
Chapter 2 Fundamentals
nWhy Such Change in 20 years? * 效能、價格與功能
nEnd of the Uniprocessor Era ** 單核處理器時代的終結
- qSome Walls, New Moore’s Law
nSea Change in Chip Design *
nRAMP project & What is FPGA
nNew Trends in Computer Design* ->GPGPU / Xeon Phi
nAmdahl’s Law ** 阿姆達爾定律
nProcessor performance equation **
Why Such Change in 20 years? :
Performance效能:
- Technology Advances技術工藝的進步(在成本和效能上超越了較老的工藝技術)
- Computer architecture advances improves low-end 計算機體系結構的進步,改進了低端系統的效能(如RISC)
Price價格: Lower costs due to …
- Simpler development 開發更簡單(系統更小、部件更少(整合度高、功能強大))
- Higher volumes 容量更大
Function功能
- Rise of networking/local interconnection technology 聯網/區域性互聯技術的高速發展


四堵牆:
頻率牆():工藝進入超深亞微米後,線延時超過門延時而佔據主導地位;
功耗牆(Power Wall):漏流增大,功耗增大,導致晶片過熱,器件的穩定性下降,訊號噪聲增大,無法正常工作;
儲存牆(Memory Wall):通訊頻寬和延遲構成;
應用牆():每一種處理器在各自的領域內都有著很高的效能。但如果應用條件發生變化則會導致效能明顯下降,導致通用微處理器並不通用。
其他:ILP wall & Power Wall + ILP Wall + Memory Wall = Brick Wall

新摩爾定律:
- DLP比TLP帶來的平行計算的能力增長更多
- 翻倍的不再是電晶體(積體電路)和處理器速度,而是processor的數量,未來計算機硬體不會更快,但是會更寬.(比如並行處理能力)
晶片(chip)設計的鉅變(sea change):
- 越來越長:字長4,8,16,32,64...
- 越來越快:速度
- 越來越多:多核(趨勢:單核->多核->眾核群核)
晶片鉅變帶來的問題:
- 軟體上 演算法和編譯器等不能支援DLP和TLP
- 硬體上 體系結構無法支援太多的核共存在一個晶片上
RAMP和FPGA
GPU和CPU的區別:
CPU: 面向通用計算 ,大量的電晶體用於Cache和控制電路
GPU:面向計算密集型和大量資料並行化的計算, 大量的電晶體用於計算單元
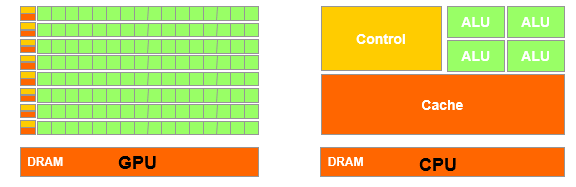
New Trends :putting all onto one chip(把cpu,gpu,io,ddr做到一個晶片上)

阿姆達爾定律:
What is frequent case and how much performance improved by making case faster
1:Fraction_enhanced(增強比例):計算機執行某個任務的總時間中可被改進部分的時間所佔的百分比.
2:Speedup_enhanced(增強加速比):改進部分採用改進措施後比沒有采用改進措施前效能提高倍數(舊時間/新時間)

處理器(processor)效能(performance)指標計算:

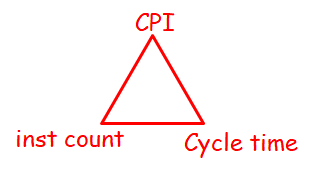
例題:在計算機系統中,某一功能的處理時間為整個系統執行時間的50%,若使該功能的處理速度加快10倍,根據Amdahl定律,這樣做可以使整個系統的效能提高____倍。若要使整個系統的效能提高1.5倍,則該功能的處理速度應加快____倍。
Chapter 3 ISA
nWhat is Instruction Set Architecture? How is it represented? * 指令集架構
nRISC vs. CISC *
nClassifying Instruction Set Architectures by the type of internal storage in a processor * 內部儲存型別
nInstruction Characteristics
nEndian order * 端序/位元組序 小端和大端 以及 對齊(alignment)
nStructure of Recent Compilers: Multi-pass structure
nMIPS Architecture & MIPS Instruction Format
什麼是ISA?How is it represented(如何表示指令)?:
a set of instructions,且每條指令都是由cpu硬體來執行的. 用二進位制的形式儲存指令集,有定長指令和不定長指令.
RISC與CISC
CISC:複雜指令集架構,追求更強大的指令,減少程式的指令條數,並交由硬體實現。
RISC:精簡指令集架構,追求更少更簡單的指令和更低的CPI
RISC設計原則:
- 簡單統一的指令格式(所有指令長度均相同),減少定址方式
- 每條指令的功能應儘可能簡單,並在一個機器週期內完成
- 只有load store可以訪存,其他操作都是在暫存器上
- 以簡單有效的方式支援高階語言
- 強調優化編譯器的作用
- 強調流水線技術
ISA的分類(分類依據:用來存放運算元的儲存單元型別):

(其中暫存器型又包括r-r型和r-m型)
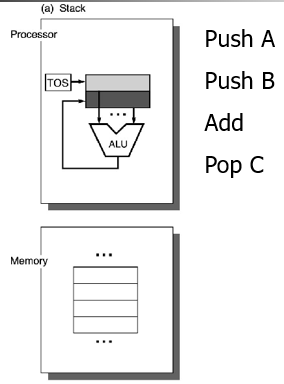
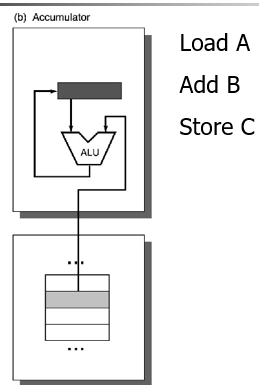


只有暫存器型沿用至今,區分GPR ISA的方法是看指令中mem address的個數和運算元(operands)的個數

ALU指令中,儲存器運算元個數和運算元個數的所有可能組合只有七種,不可能有(3,2),也就是指令有三個地址卻只需要兩個運算元.

小端序和大端序:
小端序:低位元組儲存在低地址
大端序:低位元組儲存在高地址
舉例:
var = 0x11223344,對於這個變數的最高位元組為0x11,最低位元組為0x44
(1)大端模式儲存(儲存地址為16位) (2)小端模式儲存(儲存地址為16位)
地址 資料 地址 資料
0x0004(高地址) 0x44 0x0004(高地址) 0x11
0x0003 0x33 0x0003 0x22
0x0002 0x22 0x0002 0x33
0x0001(低地址) 0x11 0x0001(低地址) 0x44


Chapter 4 Pipelining *
nConcepts and Characteristics of Pipelining * 流水線相關概念與特點
nFive steps every instruction be executed in? Fill and Drain.* 流水的5個階段;通過時間與排空時間
nStructural hazards, Data hazards and Control hazards * 結構衝突、資料衝突、控制衝突
nWhat is stall in pipeline? What happens when a instruction is stalled.
nThree Generic Data Hazards: RAW,WAR,WAW *
nHow to Avoid 3 kinds of Hazards? * 避免/解決衝突
nPerformance Issues in Pipelining. ** 效能:時空圖
關於流水線的幾個特點:

對於每個stage時長不一樣的,先把最長的那個stage(對應圖中的藍色線段)連起來,然後在每段藍色線左右補充前後的stage
流水線的相關概念和特點:
流水線:將一個重複的時序過程分解成為若干個子過程(稱為段,段數也是流水線的深度),而每個子過程都由專用功能部件實現。把多個處理過程在時間上錯開,依次通過各功能段,這樣不同子過程就能並行執行。流水線不會加速指令的執行時間而是改善整體的吞吐量.
流水線特點:
0--流水線定義
1--多條指令同時執行
2--每一個段只執行一條指令的一部分
3--指令沿著流水線流動一次的時間間隔就是一個機器週期(因此最慢的段決定了cycle大小)
流水線瓶頸:時間最長的段
流水線的五個階段:
IF(取指令)->ID(指令譯碼/取暫存器[針對分支轉移指令])->EX(執行/有效地址計算)->MEM(儲存器訪問load或store)->WB(寫到暫存器,如load或者ALU的計算結果),以RISC為例,每條指令長度4位元組,每條指令執行時間至少是5 cycles

流水線的通過時間: 從任務開始到穩定工作狀態(段被填滿)所需要的時間
流水線的排空時間:從穩定工作狀態結束到最終任務結果所需要的時間

stall時發生了什麼?
1--Instructions issued later than this instruction are stalled(在stall指令後的全都得一起stall)
2--Instructions issued earlier than this instruction must continue(在前的必須continue)
流水線的三個衝突:
1--結構衝突: 因硬體資源競爭引起的衝突


- (使用Stall解決結構衝突)
- (通過增加硬體解決結構衝突 比如指令cache和資料cache分離的方法(上圖結構衝突由於兩個指令同時需要訪問cache引起,load讀資料,I3取指令)
2--資料衝突: 指令在資料流中重疊執行時需要用到前面指令的結果產生的衝突


- (使用Stall解決資料衝突)
- (使用旁路技術解決資料衝突) [定向技術:使用流水線暫存器組直接向後面的指令傳遞結果]
定向技術檢測衝突的方法是: 當硬體檢測到前面某條指令的結果暫存器就是當前指令的源暫存器時,控制邏輯會將前面那條指令的結果直接從其產生的地方前遞到當前指令所需的位置。定向技術的實際硬體結構如下所示

注意:
load指令和其他ALU指令不同,在使用定向(解決load和其後指令的衝突)時仍有可能衝突(因為load必須得等到mem段才能得到真正的資料,其他的ALU指令可能在Ex階段就能算出結果,load必須訪存),如下,這時候需要旁路+Stall 一起用
- 旁路技術檢測衝突在load指令RAW中的應用:在當前指令的ID段檢測資料相關,可以看出只需要把load指令的結果暫存器(lw的MEM段暫存器)與load指令後的幾條指令(包含當前指令sub)的(ID段)源暫存器地址進行比較,如果在同一級(如lw與and)則可以用旁路或者在後面(如lw與or)則無需操作(因為前半週期寫後半週期讀),如果在前面(如lw與sub)則需要stall
- 如果在指令中觀察,則Lw的下一條指令只能stall+forward,下二條指令可以forward,下三條指令無需操作(無衝突)如下圖所示
做系統結構實驗的時候找到一個trick:
一般在有定向技術的情況下找RAW衝突,只需關注兩條連續的指令中第一條是LW的(類似上圖第二個),這種只能stall,如果兩條連續指令中第一條不是LW,則可以通過定向解決,比如:
ADD r1 r1 r3
SW r1 0(r2)
ADD寫r1 SW讀r1 但是ADD的EX結果可以直接傳給SW的EX(如果定向機構檢測到前一個ALU的計算結果寫入的暫存器【對應r1】就是當前ALU的源暫存器,那麼控制邏輯就選擇定向的資料作為ALU的輸入,而不採用從通用暫存器組讀出的資料)
截圖(以後補,用MIPS的模擬器)



上面舉例的都是RAW,另外還有WAR和WAW衝突(但是在MIPS中也就是五段流水線裡只會出現RAW):



3--控制衝突: 流水線遇到分支指令或者其他改變PC值的指令所遇到的衝突


有兩個解決思路:1-更早得決定branch是否該被選中(MIPS在ID段zero test) 2-更早得計算好分支轉移的地址(MIPS在ID段算轉移PC)
(如上右圖將分支地址計算放在了ID階段,MIPS中的branch test都是通過檢測register的值是否為0,因此把zero test也一起移動到ID段(如前所示,Id段可以讀暫存器)這樣一旦決定轉移分支就不用等到10指令的MEm走完)這樣只需一個stall(若跳轉,36的IF需要等10的ID出結果),相比之前的三個stall(若跳轉,36的IF需要等10的MEM出結果),減少了penalty,具體如下圖所示。

減少分支延遲(控制衝突)的四種方法總結:
(2,3統稱為分支預測,是一種靜態預測,【下一章會有動態分支預測,這裡靜態是指預測操作是預先訂好的,一定成功或者一定失敗,動態則是可以根據之前的分支實際執行情況動態選擇本次分支是成功還是失敗】):
- stall一直到mem段出結果
- 假設分支一定not taken(也就是不跳轉,接著執行下面一條指令),如果真實結果是跳轉則squash(擠壓,可以理解為指令作廢,就是上面的idle)
- 假設分支一定 taken,同樣需要一個stall等ID出轉移地址結果,在五段流水線中,如果最後not taken,還需要轉回到i+1,需要暫存器存i+1地址,相比方法2完全沒有好處
- 延遲分支,使用編譯器進行指令靜態排程(調到延遲槽中)【下一章會有指令動態排程】,MIPS用的是隻有一條指令的延遲槽,這種方法和2實際上幾乎沒區別的,只不過槽裡那條指令不會被squash,也可以不是i+1(填充鹽池槽的指令選擇如下二圖所示)


幾種方法的共同特點:都屬於靜態方法,對分支的處理方式在程式執行過程中固定不變,要麼總是預測成功,要麼總是預測失敗。
延遲分支幾種排程策略和優缺點:

注意:
對於分支預測,無論是靜態方法還是動態方法都是硬體和軟體共同作用的結果!靜態是說預測是提前預定好的,動態可以自我調整
對於排程,靜態是指通過編譯器在編譯階段進行的排程,動態是指通過硬體在執行過程中進行的排程
三種衝突的解決方法總結:

流水線效能指標:


例題1:


加速比(一定大於1):

效率:
效率相當於每一段的加速比,所以可以用總的加速比除以段數




帶有stall的流水線效能:
(比如:CPI,如果流水線無stall那麼cpi一定是1,因為每個時鐘週期流出一條指令)

例題2:
加速比除了用總時間比值也可以用平均時間(=時鐘週期*平均CPI)的比值來計算
假設非流水線實現的時鐘週期時間為1ns,ALU和分支指令需要4個時鐘週期,訪問儲存器指令需5個時鐘週期,
上述指令在程式中出現的相對頻率分別是:40%、20%和40%。
在基本的流水線中,假設由於時鐘扭曲和暫存器建立延遲等原因,流水線要在其時鐘週期時間上附加0.2ns的額外開銷。
現忽略任何其他延遲因素的影響,請問:相對於非流水實現而言,基本的流水線執行指令的加速比是多少?



Chapter 5 ILP - 1
nWhat is Instruction-Level Parallelism (ILP) and the 2 approaches to exploit ILP * 指令級並行,靜態與動態
nWhat is Basic Block * 基本塊
nData Dependence (True dependence), Name Dependence (Anti-dependence, Output dependence) , Control Dependencies * 相關(與衝突的關係)
nUnrolled Loop and Minimizes Stalls * 迴圈展開
nDynamic Branch Prediction * 動態分支預測
- qBranch History Table, Correlated Branch Prediction, Tournament Predictors,Branch Target Buffers 分支目標緩衝 *
什麼是ILP?提高ILP的兩種方法?
當指令之間不存在相關,他們在流水線中可以重疊起來並行執行,這種潛在的並行性稱為指令級並行。
重疊執行指令以提高效能,兩種方法:動態方法(改變硬體)軟體方法(編譯器排程)

什麼是BB?
除入口和出口外沒有其他分支(branch)的線性指令序列,BB內部的指令可能相互依賴(dependent),所以開發ILP更多是在BB之間。
比如迴圈級並行(loop-level parallelism):
for (i=1; i<=1000; i=i+1)
x[i] = x[i] + s //(一個迴圈中的不同迴圈體並行執行)其中每個迴圈體就是一個BB,共有1000個BB,ILP就是使得這1000個BB能平行計算,這個具體方法叫迴圈展開(unrolling loop)。
- 動態迴圈展開:動態分支預測(上一章的分支預測是一種靜態的)
- 靜態迴圈展開:編譯器靜態排程指令(後面還會介紹一種動態排程)
相關與衝突的關係
相關:兩條指令之間存在某種依賴關係
衝突:在具體流水線中,由於相關的存在,使得指令流中下一條指令不能在指定的時鐘週期開始執行
兩者之間的關係:
相關性是程式的固有屬性; 衝突是流水線的特性;
相關性的存在只預示著存在有衝突的可能性。
相關的分類
資料相關:後面的指令使用了前面指令的結果
一般都是能引起RAW衝突的相關

ILP的宗旨就是隻在會影響結果的時候保留指令執行順序,其他情況下儘可能改變順序提高並行性

名相關:兩條指令使用相同的暫存器名,而兩者之間沒有資料流動
包括反相關,一般都是能引起WAR衝突的

和輸出相關,一般都是能引起WAW衝突的

反相關的解決方法:一般可以通過暫存器重新命名,也可以編譯器靜態排程和硬體方法。
控制相關:由分支指令引起的相關
一般都是能引起控制衝突的相關

上圖紅字的意思是: 指令排程的時候不能跨越分支指令,也就是BNE之前的指令不能排程到BNe之後(一個特例是分支延遲中可以放在BNE的延遲槽,見後)
迴圈展開:




1 由上可見,BB內的指令排程能帶來的ILP提升有限(雖然減少了總的cycles,但是其中真正想執行的指令只佔3/7,剩下的四個都是為了分支轉移)
2 同時右圖中DADDUI之所以能插到L和ADD之間的stall中是因為他和L,ADD均不存在衝突!(可能有人會想他可能與L有WAR,實際上MIPS的五段流水線是不可能產生除了RAW之外的資料衝突的,原因見前,就算想衝突,L和DADDUI之間也得起碼隔著兩個拍才行(這樣L的mem才能和DADDUI的ID衝突上))
3 此外還可以將BNE移動到S之前的一個stall中,此時S處於BNE的延遲槽中,不屬於(S)跨越分支指令(BNE)的情況
由1 啟發我們需要在BB之間進行排程,這種就是迴圈展開要做的:


重要!->總迴圈次數n=1000,假設每次迴圈展開成k=4個(如上左圖所示,減少了迴圈控制和分支開銷)然後進行暫存器重新命名(避免衝突)和指令排程(如上右圖所示,減少了空轉週期提高效率)
實際上是先進行n mod k個loop,然後再展開成k個的大loop,對這個大loop再迴圈n/k次,n越大,就會有越多的時間花在迴圈展開後的大loop上
迴圈展開的優點和限制:
限制:
- 迴圈展開成大loop時,若k過大,指令cache的miss rate會增加
- 因為用到了重新命名,暫存器可能不夠
優點:
- 降低整體開銷(通過二外的迴圈展開)
- 減少了branch的開銷
動態分支預測:
動態相比靜態的區別是使用從早期執行(earlier run)中收集的概要資訊預測分支,並根據上次執行(last run)修改預測
branch history table
1-bit的BHT存在的問題:
- 最後一次預測錯誤不可避免,因為前面分支總是成功
- 第一次預測錯誤是源於上次程式的執行,因為上一次程式最後一次分支不成功(可通過2-bit解決,見下圖)

Correlated Branch Prediction
2-bit的BHT存在的問題:
- 如果不止一個分支(branch)存在,前面的分支可能會影響後面的分支(稱為相關分支,見下左圖,只有b1 b2都是Not Taken,b3才能Taken)可以通過相關分支預測器解決(見下右圖)


注意:2-bitBHT相當於(0,2)的相關分支預測器
例題:
一個(2,2)的分支預測器如下:求預測結果

上圖中address是不同分支的地址,GBH記錄了上一次run的時候兩個相關分支的taken情況,根據add和GBH定位到對應的具體狀態為01,則說明這次run的預測是Not Taken
Tournament Predictors

其中selector 長得類似(0,2)的predictor:


Branch Target Buffers
BTB的思想借鑑了指令cache,他是預先把已知的是branch的指令地址和預測地址都存起來,然後將當前PC值逐一與表中的指令地址比較,若相等則說明當前PC指向的指令是一條分支指令,此後系統不再抓取PC對應的指令而是fetch與之對應的predicted PC指向的指令,如下圖所示:


以下部分為Part2 請轉連結:
Chapter 5 ILP - 2
nBranch Target Buffers 分支目標緩衝 *
nConcept and Advantages of Dynamic Scheduling * 動態排程
- qScoreboard 記分牌
- qTomasulo
- qSpeculation 前瞻執行
- qTomasulo with ReOrder Buffer 再定序緩衝
nSuperscalar and VLIW * 超標量與超長指令字
Chapter 6 Limits to ILP and SMT
nWhat are Limits to ILP
nWhat is instruction window? 指令視窗
nWhat is Thread Level Parallelism (TLP) or MultiThreading * 執行緒級並行,多執行緒
nWhat is Data Level Parallelism? 資料級並行
How to switch Multi Threads **
- qfine grain 細粒度切換
- qcoarse grain 粗粒度切換
nWhat is Simultaneous multithreading * 同時多執行緒
nKnow something about Power5
Chapter 7 Memory Hierarchy - 1
nLevels of the Memory Hierarchy * 儲存系統的層次結構
nThe Principle of Locality: Temporal Locality and Spatial Locality * 區域性性原理
nWhere can a block be placed: Fully associative, direct mapped, n-way set associative * 映像規則
nHow is a block found in the upper level? 查詢演算法
nWhich block should be replaced on a miss? 替換演算法:Random、LRU、FIFO
nWrite Policy: Write-Through and Write-Back; Write allocate and No-write allocate * 寫策略:寫直達與寫回,按寫分配與不按寫分配
nWhat and Why a write buffer 寫快取
Chapter 7 Memory Hierarchy - 2
nCache Measures: Average memory-access time ** Cache效能:平均訪問時間,命中與失效
- q= Hit time + Miss rate x Miss penalty *
- q= Hit timeL1+ Miss rateL1x (Hit timeL2+ Miss rateL2x Miss penaltyL2)
nBasic Cache Optimizations
nThree Major Categories of Cache Misses: Compulsory, Capacity and Conflict * 強制、容量與衝突不命中
nWhat is virtual address space 虛存空間
nHow page table works 頁表
nTranslation Look-Aside Buffer (TLB)地址變換後備快取
Chapter 8 I/O Systems
nWhat is a bus? Types of Buses
nDisk Drive Performance
nReliability, Availability and Dependability of the Storage Device * <