
# [cs231n (七)神經網路 part 3 : 學習和評估 ][1]
標籤(空格分隔): 神經網路
0.回顧
cs231n (一)影象分類識別講了KNN
cs231n (二)講了線性分類器:SVM和SoftMax
cs231n (三)優化問題及方法
cs231n (四)反向傳播
cs231n (五)神經網路 part 1:構建架構
cs231n (六)神經網路 part 2:傳入資料和損失
1.引言
之前入門了一個兩層的神經網路,基本就是網路框架,現在就需要好好優化網路了,來開啟電腦開幹哈、、、麼麼噠~
2. 梯度檢驗
意不意外、驚不驚喜? 我有出現了、
其實這裡就一點:用中心化公式更好
按照定義h是一個趨近於零的數值,目前計算機的能力下:近似為1e-5
反正目前來說就是:費力(耗費計算能力)不討好!
關於梯度檢驗我們需要掌握幾點:
- 使用雙精度計算會降低誤差
- 目標函式不可導的時候也會影響梯度精度的
- 使用資料少點:笨啊,因為這樣不可導的資料點就越少啊
- 梯度檢驗期間最好是不要使用正則化
- 不要使用dropout和資料增強(augmentation)
- 等待梯度開始下降後再開始梯度檢查
- 檢查部分維度:假設其他維度是正確的
- 步長h的設定:一般是1e-4 ----> 1e-6 為什麼?
看了這張圖就知道為什麼了。

3. 做到:合理性檢查
- 特定情況下的損失值應該合理
- 是否是因為提高了正則化強度之後導致的損失值變大
- 小資料的過擬合:不要用正則化,使用20個數據應該能達到損失是零
4. 接下來檢查整個學習過程
其實就是跟蹤一些重要的引數,從而達到修改超引數的便利, 比如:每個epoch的loss
1. 損失函式
損失值跟蹤: 可以得到不同學習率下的損失值變化情況
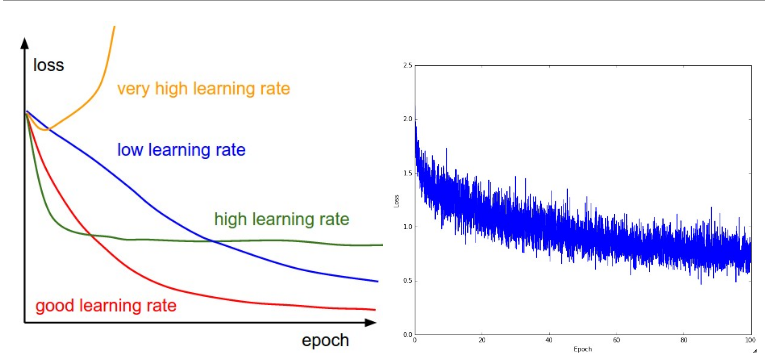
左邊:不同學習率下的loss變化,右邊:隨著epochloss的變化
loss震盪程度和batch size有關係哦,當size=1 震盪程度就會很大,當size=N也就是整個資料,那麼震盪最小
2. 訓練和驗證集精度
緊接著需要跟蹤的另一個指標就是:驗證和訓練集的準確率,看下圖

- 訓練集和驗證集之間的空隙說明:模型的過擬合程度 驗證集的準確率很低,說明模型嚴重過擬合, 此時應該增大正則化強度(正則化項、dropout、增加資料)
- 再則就是驗證曲線和訓練曲線很接近,說明模型容量太小,應該增加引數數量。
3. 權重更新
最後一個指標就是:權重值更新了的數量和全部值的比
這個比例應該在1e-3左右,如果小,說明學習率小,如如果大,說明學習率太大。
# assume parameter vector W and its gradient vector dW
param_scale = np.linalg.norm(W.ravel())
update = -learning_rate*dW # simple SGD update
update_scale = np.linalg.norm(update.ravel())
W += update # the actual update
print update_scale / param_scale # want ~1e-3
4. 層啟用數及梯度分佈情況
初始化問題,梯度消失或者nan值,解決辦法:得到網路中所有層的啟用資料及梯度分佈,觀測資料結果, 我們看一下下面的圖就知道了。
對於影象資料,我們視覺化第一層特徵。

左邊:特徵亂七八糟,網路應該是沒有收斂,學習率不當,正則化權重太低
右邊:特徵明顯,種類多,好圖。
5. 引數更新
當我們使用BP計算梯度以後,梯度就可以更新了,那麼如何更新呢?
1. 隨機梯度下降
-
一般更新沿著負梯度調參
-
x += - learning_rate * dx比如 : = 0.05 -
動量更新新方法,在深度學習中總是能快速收斂
從物理角度講,想象一座高山,高度勢能是U=mgh,so:
質點所受的力與梯度的能量有關,**其實就是保守力就等於勢能的負梯度!!!**物理專業的驕傲哈哈、
而又因為: 所以有:
# 動量法
v = mu * v - learning_rate * dx # 融合速度
x += v # 融合位置
引入引數 mu和v , 前者就是動量咯,最後結論:mu = [0.5,0.9,0.95,0.99]
要注意mu不是恆定不變的,一般是從0.5慢慢提升至0.99
- Nesterov動量 理論上更有比較好的支援,實踐下比上述動量還好。
當向量位於某個位置x時,mu * v 會輕微改變引數向量,因此計算梯度時,應該計算x + mu * v就更有意義???
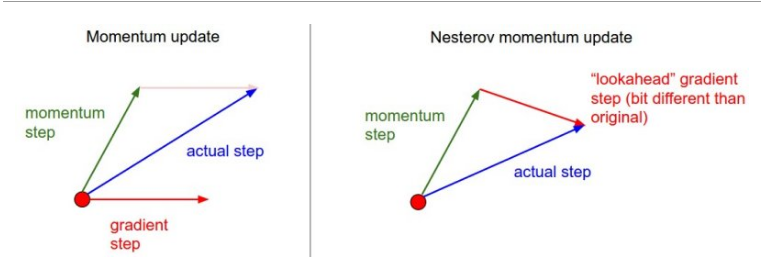
動量將會把我們帶到綠色箭頭的位置,那麼應該再向前看一些。
就知道你聽的一頭霧水!
x_ahead = x + mu * v
# 計算dx_ahead(x_ahead處的梯度)
v = mu * v - learning_rate * dx_ahead
x += v
實際中改寫x_ahead = x + mu * v就懂了。
x += -mu * v_prev + (1 + mu) * v && v_prev = v
x += v
v_prev = v # back this up
v = mu * v - learning_rate * dx # velocity update stays the same
x += -mu * v_prev + (1 + mu) * v # position update changes form
2. 學習率退化
-
**隨epoch衰減:**一般是每5個epoch減少一半,看驗證集的錯誤率停止下降,就乘常數,降低學習率。
-
指數衰減:
-
1/t衰減:
,k:超引數,t:迭代次數
隨步數衰減的隨機失活(dropout)更受歡迎
3. 二階法
還有最優化方法是基於牛頓法的:
其中 是Hessian矩陣, 這裡是沒有學習率這個引數或者說概念的, 這個方法啊,少用。
4. 逐層層自適應學習率:Adagrad、RMSprop
Adagrad:一個由Duchi等人提出適應學習率演算法
跟蹤每個引數的平方和, 必須加平方根
接收到高梯度值的權重更新的效果被減弱,而接收到低梯度值的權重的更新效果將會增強
eps防止出現0的情況
缺點:學習率太激進,容易過早停止學習。
RMSprop 高效,且沒被髮表的適應性學習率法,Hinton coursera
就是去除了Adagrad的缺點,慢慢降低了學習率。
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
超引數decay_rate,多用[0.9,0.99,0.999]
# Assume the gradient dx and parameter vector x
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
Adam RMSProp的動量版
m = beta1*m + (1-beta1)*dx
v = beta2*v + (1-beta2)*(dx**2)
x += - learning_rate * m / (np.sqrt(v) + eps)
論文中推薦的引數值eps=1e-8, beta1=0.9, beta2=0.999
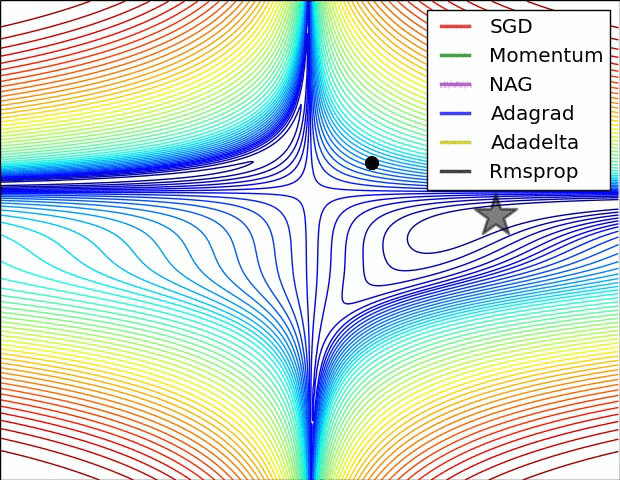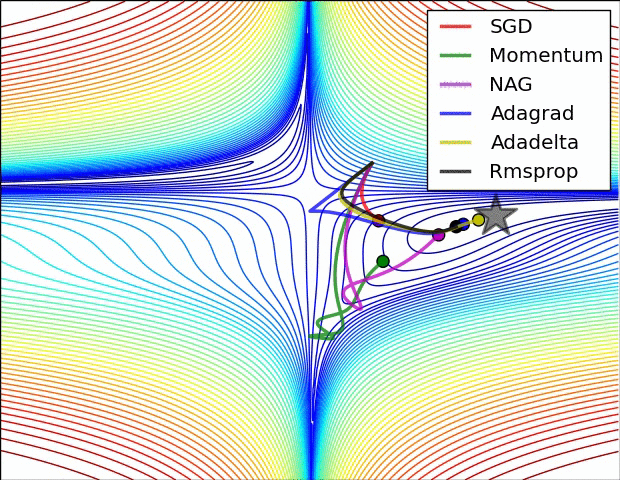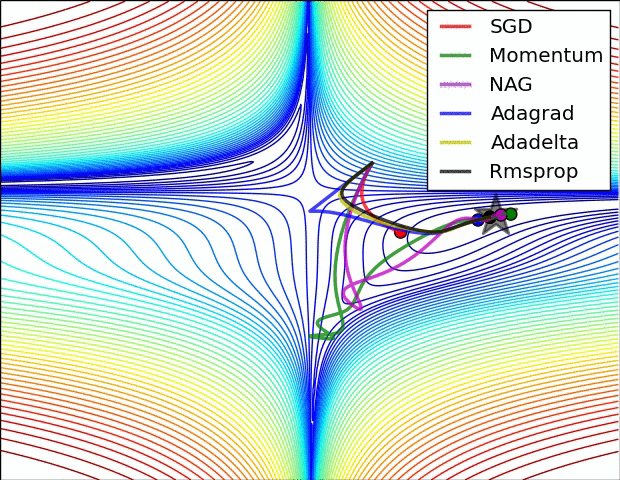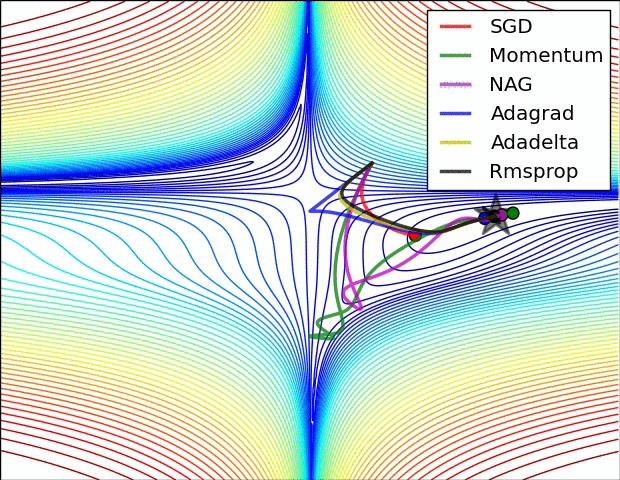
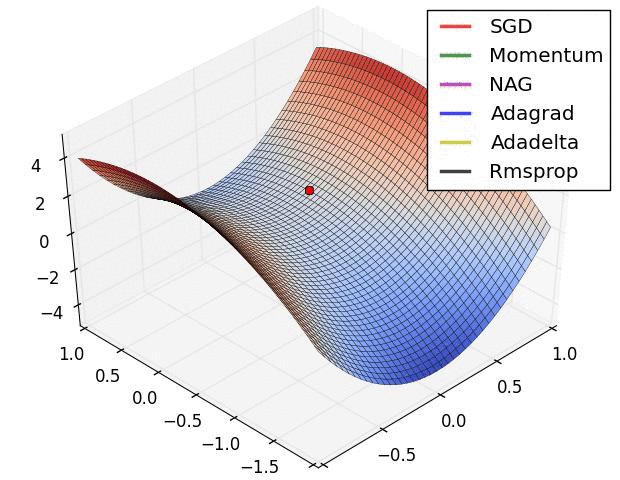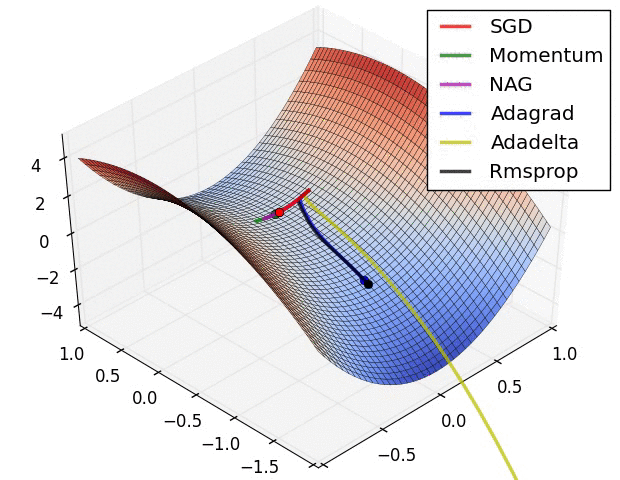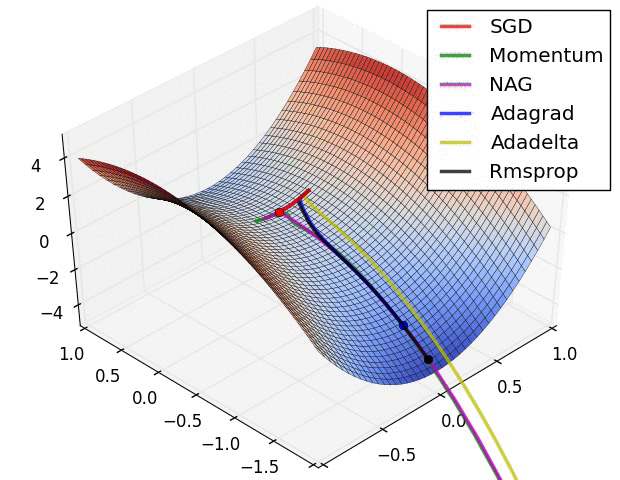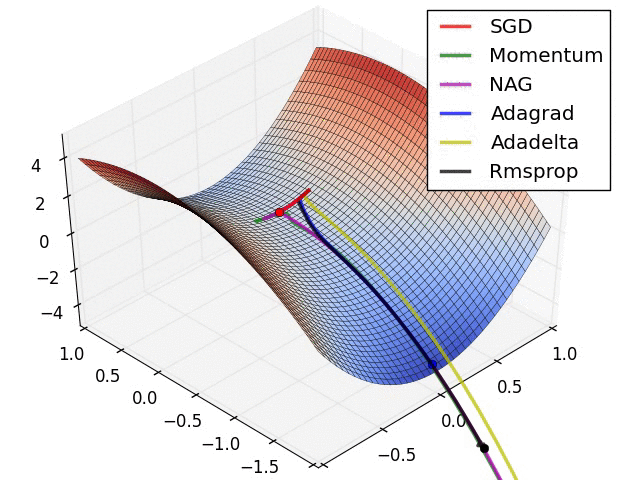
RMSProp更新, 方法中的分母項, 所以動量類的可以繼續前進
6. 超引數優化
總結一下:
- 初始化學習率
- 學習率衰減
- 正則化強度
交叉驗證最好使用一個驗證集
超引數的範圍:learning_rate = 10 ** uniform(-6, 1) dropout=uniform(0,1)
隨機選擇好於網路搜尋
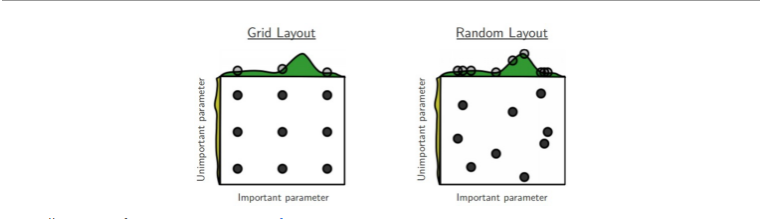
大範圍搜尋——————>>>貝葉斯超引數優化
7. 評估(整合模型)
提升準確率的辦法: 訓練獨立幾個模型,然後平均結果
模型設定多個記錄位點: 記錄網路值。
跑引數平均值:也可以提上幾個百分點,對網路的權重進行備份。
8. 總結
訓練網路:
- 小批量梯度檢查
- 小批量期間得到100%準確率
- 跟蹤損失準確率以及第一層權重視覺化
- 權重更新方法:SGD+Nesterov動量法,Adam法
- 學習率衰減
- 隨機搜尋超引數
- 整合模型(比賽得獎的幾乎都用了整合)
9. 附錄拓展