
搭建深度學習後臺伺服器
本篇文章的原創為國外的一篇文章(一個可擴充套件的Keras深度學習REST API),連結為:
我們的Keras深度學習REST API將能夠批量處理影象,擴充套件到多臺機器(包括多臺web伺服器和Redis例項),並在負載均衡器之後進行迴圈排程。
為此,我們將使用:
- KerasRedis(記憶體資料結構儲存)
- Flask (Python的微web框架)
- 訊息佇列和訊息代理程式設計範例
本篇文章的整體思路如下:
我們將首先簡要討論Redis資料儲存,以及如何使用它促進訊息佇列和訊息代理。然後,我們將通過安裝所需的Python包來配置Python開發環境,以構建我們的Keras深度學習REST API。一旦配置了開發環境,就可以使用Flask web框架實現實際的Keras深度學習REST API。在實現之後,我們將啟動Redis和Flask伺服器,然後使用cURL和Python向我們的深度學習API端點提交推理請求。最後,我們將以對構建自己的深度學習REST API時應該牢記的注意事項的簡短討論結束。
第一部分:簡要介紹Redis如何作為REST API訊息代理/訊息佇列

圖片1:Redis可以用作我們深度學習REST API的訊息代理/訊息佇列
Redis是記憶體中的資料儲存。它不同於簡單的鍵/值儲存(比如memcached),因為它可以儲存實際的資料結構。今天我們將使用Redis作為訊息代理/訊息佇列。這包括:
- 在我們的機器上執行Redis
- 將資料(影象)按照佇列的方式用Redis儲存,並依次由我們的REST API處理
- 為新批輸入影象迴圈訪問Redis
- 對影象進行分類並將結果返回給客戶端

第二部分:安裝和配置Redis
官網做法,linux系統的安裝:

自己的安裝方法:
conda install redis開啟方式相同:
resdis-server結果:

測試和原文的命令一致。
redis-cli ping第三部分:配置Python開發環境以構建Keras REST API
文章中說需要建立新的虛擬環境來防止影響系統級別的python專案(但是我沒有建立),但是還是需要安裝rest api所需要依賴的包。以下為所需要的包。
$ pip install numpy $ pip install scipy h5py $ pip install tensorflow # tensorflow-gpu for GPU machines $ pip install keras $ pip install flask gevent $ pip install imutils requests $ pip install redis $ pip install Pillow
第四部分:實現可擴充套件的Keras REST API
首先是Keras Redis Flask REST API資料流程圖
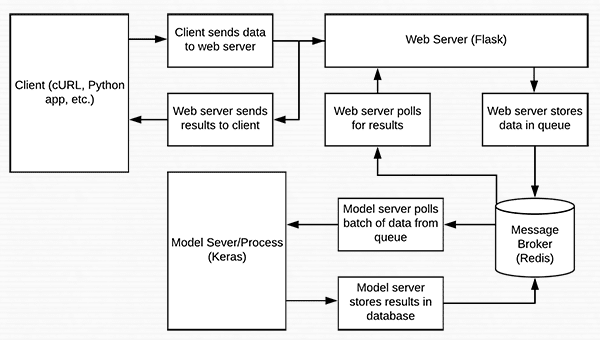
讓我們開始構建我們的伺服器指令碼。為了方便起見,我在一個檔案中實現了伺服器,但是它可以按照您認為合適的方式模組化。為了獲得最好的結果和避免複製/貼上錯誤,我建議您使用本文的“下載”部分來獲取相關的指令碼和影象。:
# import the necessary packages
from keras.applications import ResNet50
from keras.preprocessing.image import img_to_array
from keras.applications import imagenet_utils
from threading import Thread
from PIL import Image
import numpy as np
import base64
import flask
import redis
import uuid
import time
import json
import sys
import io為了簡單起見,我們將在ImageNet資料集上使用ResNet預訓練。我將指出在哪裡可以用你自己的模型交換ResNet。flask模組包含flask庫(用於構建web API)。redis模組將使我們能夠與redis資料儲存介面。從這裡開始,讓我們初始化將在run_keras_server.py中使用的常量.
# initialize constants used to control image spatial dimensions and
# data type
IMAGE_WIDTH = 224
IMAGE_HEIGHT = 224
IMAGE_CHANS = 3
IMAGE_DTYPE = "float32"
# initialize constants used for server queuing
IMAGE_QUEUE = "image_queue"
BATCH_SIZE = 32
SERVER_SLEEP = 0.25
CLIENT_SLEEP = 0.25我們將向伺服器傳遞float32影象,尺寸為224 x 224,包含3個通道。我們的伺服器可以處理一個BATCH_SIZE = 32。如果您的生產系統上有GPU(s),那麼您需要調優BATCH_SIZE以獲得最佳效能。我發現將SERVER_SLEEP和CLIENT_SLEEP設定為0.25秒(伺服器和客戶端在再次輪詢Redis之前分別暫停的時間)在大多數系統上都可以很好地工作。如果您正在構建一個生產系統,那麼一定要調整這些常量。
讓我們啟動我們的Flask app和Redis伺服器:
# initialize our Flask application, Redis server, and Keras model
app = flask.Flask(__name__)
db = redis.StrictRedis(host="localhost", port=6379, db=0)
model = None在這裡你可以看到啟動Flask是多麼容易。在執行這個伺服器指令碼之前,我假設Redis伺服器正在執行(之前的redis-server)。我們的Python指令碼連線到本地主機6379埠(Redis的預設主機和埠值)上的Redis儲存。不要忘記將全域性Keras模型初始化為None。接下來我們來處理影象的序列化:
def base64_encode_image(a):
# base64 encode the input NumPy array
return base64.b64encode(a).decode("utf-8")
def base64_decode_image(a, dtype, shape):
# if this is Python 3, we need the extra step of encoding the
# serialized NumPy string as a byte object
if sys.version_info.major == 3:
a = bytes(a, encoding="utf-8")
# convert the string to a NumPy array using the supplied data
# type and target shape
a = np.frombuffer(base64.decodestring(a), dtype=dtype)
a = a.reshape(shape)
# return the decoded image
return aRedis將充當伺服器上的臨時資料儲存。影象將通過諸如cURL、Python指令碼甚至是移動應用程式等各種方法進入伺服器,而且,影象只能每隔一段時間(幾個小時或幾天)或者以很高的速率(每秒幾次)進入伺服器。我們需要把影象放在某個地方,因為它們在被處理前排隊。我們的Redis儲存將作為臨時儲存。
為了將影象儲存在Redis中,需要對它們進行序列化。由於影象只是數字陣列,我們可以使用base64編碼來序列化影象。使用base64編碼還有一個額外的好處,即允許我們使用JSON儲存影象的附加屬性。
base64_encode_image函式處理序列化。類似地,在通過模型傳遞影象之前,我們需要反序列化影象。這由base64_decode_image函式處理。
預處理圖片:
def prepare_image(image, target):
# if the image mode is not RGB, convert it
if image.mode != "RGB":
image = image.convert("RGB")
# resize the input image and preprocess it
image = image.resize(target)
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
image = imagenet_utils.preprocess_input(image)
# return the processed image
return image我已經定義了一個prepare_image函式,它使用Keras中的ResNet50實現對輸入影象進行預處理,以便進行分類。在使用您自己的模型時,我建議修改此函式,以執行所需的預處理、縮放或規範化。
從那裡我們將定義我們的分類方法:
def classify_process():
# load the pre-trained Keras model (here we are using a model
# pre-trained on ImageNet and provided by Keras, but you can
# substitute in your own networks just as easily)
print("* Loading model...")
model = ResNet50(weights="imagenet")
print("* Model loaded")classify_process函式將在它自己的執行緒中啟動,我們將在下面的__main__中看到這一點。該函式將從Redis伺服器輪詢影象批次,對影象進行分類,並將結果返回給客戶端。
在model = ResNet50(weights="imagenet")這一行中,我將這個操作與終端列印訊息連線起來——根據Keras模型的大小,載入是即時的,或者需要幾秒鐘。
載入模型只在啟動這個執行緒時發生一次——如果每次我們想要處理一個映像時都必須載入模型,那麼速度會非常慢,而且由於記憶體耗盡可能導致伺服器崩潰。
載入模型後,這個執行緒將不斷輪詢新的影象,然後將它們分類(注意這部分程式碼應該時尚一部分的繼續):
# continually poll for new images to classify
while True:
# attempt to grab a batch of images from the database, then
# initialize the image IDs and batch of images themselves
queue = db.lrange(IMAGE_QUEUE, 0, BATCH_SIZE - 1) #第79行
imageIDs = []
batch = None
# loop over the queue
for q in queue:
# deserialize the object and obtain the input image
q = json.loads(q.decode("utf-8"))
image = base64_decode_image(q["image"], IMAGE_DTYPE,
(1, IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_CHANS))
# check to see if the batch list is None
if batch is None:
batch = image
# otherwise, stack the data
else:
batch = np.vstack([batch, image])
# update the list of image IDs
imageIDs.append(q["id"])在這裡,我們首先使用Redis資料庫的lrange函式從佇列(第79行)中獲取最多的BATCH_SIZE影象。
從那裡我們初始化imageIDs和批處理(第80和81行),並開始在第84行開始迴圈佇列。
在迴圈中,我們首先解碼物件並將其反序列化為一個NumPy陣列image(第86-88行)。
接下來,在第90-96行中,我們將向批處理新增影象(或者如果批處理當前為None,我們將該批處理設定為當前影象)。
我們還將影象的id附加到imageIDs(第99行)。
讓我們完成迴圈和函式:
# check to see if we need to process the batch
if len(imageIDs) > 0: # 第102行
# classify the batch
print("* Batch size: {}".format(batch.shape))
preds = model.predict(batch)
results = imagenet_utils.decode_predictions(preds)
# loop over the image IDs and their corresponding set of
# results from our model
for (imageID, resultSet) in zip(imageIDs, results):
# initialize the list of output predictions
output = []
# loop over the results and add them to the list of
# output predictions
for (imagenetID, label, prob) in resultSet:
r = {"label": label, "probability": float(prob)}
output.append(r)
# store the output predictions in the database, using
# the image ID as the key so we can fetch the results
db.set(imageID, json.dumps(output)) #第122行
# remove the set of images from our queue
db.ltrim(IMAGE_QUEUE, len(imageIDs), -1)
# sleep for a small amount
time.sleep(SERVER_SLEEP)在這個程式碼塊中,我們檢查批處理中是否有影象(第102行)。如果我們有一批影象,我們通過模型(第105行)對整個批進行預測。從那裡,我們迴圈一個影象和相應的預測結果(110-122行)。這些行向輸出列表追加標籤和概率,然後使用imageID將輸出儲存在Redis資料庫中(第116-122行)。
我們使用第125行上的ltrim從佇列中刪除了剛剛分類的影象集。最後,我們將睡眠設定為SERVER_SLEEP時間並等待下一批影象進行分類。下面我們來處理/predict我們的REST API端點:
@app.route("/predict", methods=["POST"])
def predict():
# initialize the data dictionary that will be returned from the
# view
data = {"success": False}
# ensure an image was properly uploaded to our endpoint
if flask.request.method == "POST":
if flask.request.files.get("image"):
# read the image in PIL format and prepare it for
# classification
image = flask.request.files["image"].read()
image = Image.open(io.BytesIO(image))
image = prepare_image(image, (IMAGE_WIDTH, IMAGE_HEIGHT))
# ensure our NumPy array is C-contiguous as well,
# otherwise we won't be able to serialize it
image = image.copy(order="C")
# generate an ID for the classification then add the
# classification ID + image to the queue
k = str(uuid.uuid4())
d = {"id": k, "image": base64_encode_image(image)}
db.rpush(IMAGE_QUEUE, json.dumps(d))稍後您將看到,當我們釋出到REST API時,我們將使用/predict端點。當然,我們的伺服器可能有多個端點。我們使用@app。路由修飾符以第130行所示的格式在函式上方定義端點,以便Flask知道呼叫什麼函式。我們可以很容易地得到另一個使用AlexNet而不是ResNet的端點,我們可以用類似的方式定義具有關聯函式的端點。你懂的,但就我們今天的目的而言,我們只有一個端點叫做/predict。
我們在第131行定義的predict方法將處理對伺服器的POST請求。這個函式的目標是構建JSON資料,並將其傳送回客戶機。如果POST資料包含影象(第137和138行),我們將影象轉換為PIL/Pillow格式,並對其進行預處理(第141-143行)。
在開發這個指令碼時,我花了大量時間除錯我的序列化和反序列化函式,結果發現我需要第147行將陣列轉換為C-contiguous排序(您可以在這裡瞭解更多)。老實說,這是一個相當大的麻煩事,但我希望它能幫助你站起來,快速跑。
如果您想知道在第99行中提到的id,那麼實際上是使用uuid(通用唯一識別符號)在第151行生成的。我們使用UUID來防止hash/key衝突。
接下來,我們將影象的id和base64編碼附加到d字典中。使用rpush(第153行)將這個JSON資料推送到Redis db非常簡單。
讓我們輪詢伺服器以返回預測:
# keep looping until our model server returns the output
# predictions
while True:
# attempt to grab the output predictions
output = db.get(k)
# check to see if our model has classified the input
# image
if output is not None:
# add the output predictions to our data
# dictionary so we can return it to the client
output = output.decode("utf-8")
data["predictions"] = json.loads(output)
# delete the result from the database and break
# from the polling loop
db.delete(k)
break
# sleep for a small amount to give the model a chance
# to classify the input image
time.sleep(CLIENT_SLEEP)
# indicate that the request was a success
data["success"] = True
# return the data dictionary as a JSON response
return flask.jsonify(data)我們將持續迴圈,直到模型伺服器返回輸出預測。我們開始一個無限迴圈,試圖得到157-159條預測線。從這裡,如果輸出包含預測,我們將對結果進行反序列化,並將結果新增到將返回給客戶機的資料中。我們還從db中刪除了結果(因為我們已經從資料庫中提取了結果,不再需要將它們儲存在資料庫中),並跳出了迴圈(第163-172行)。
否則,我們沒有任何預測,我們需要睡覺,繼續投票(第176行)。如果我們到達第179行,我們已經成功地得到了我們的預測。在本例中,我們向客戶機資料新增True的成功值(第179行)。注意:對於這個示例指令碼,我沒有在上面的迴圈中新增超時邏輯,這在理想情況下會為資料新增一個False的成功值。我將由您來處理和實現。最後我們稱燒瓶。jsonify對資料,並將其返回給客戶端(第182行)。這就完成了我們的預測函式。
為了演示我們的Keras REST API,我們需要一個__main__函式來實際啟動伺服器:
# if this is the main thread of execution first load the model and
# then start the server
if __name__ == "__main__":
# load the function used to classify input images in a *separate*
# thread than the one used for main classification
print("* Starting model service...")
t = Thread(target=classify_process, args=())
t.daemon = True
t.start()
# start the web server
print("* Starting web service...")
app.run()第186-196行定義了__main__函式,它將啟動classify_process執行緒(第190-192行)並執行Flask應用程式(第196行)。
第五部分:啟動可伸縮的Keras REST API
要測試我們的Keras深度學習REST API,請確保使用本文的“下載”部分下載原始碼示例影象。從這裡,讓我們啟動Redis伺服器,如果它還沒有執行:
redis-server然後,在另一個終端中,讓我們啟動REST API Flask伺服器:
python run_keras_server.py 另外,我建議在向伺服器提交請求之前,等待您的模型完全載入到記憶體中。現在我們可以繼續使用cURL和Python測試伺服器。
第七部分:使用cURL訪問Keras REST API
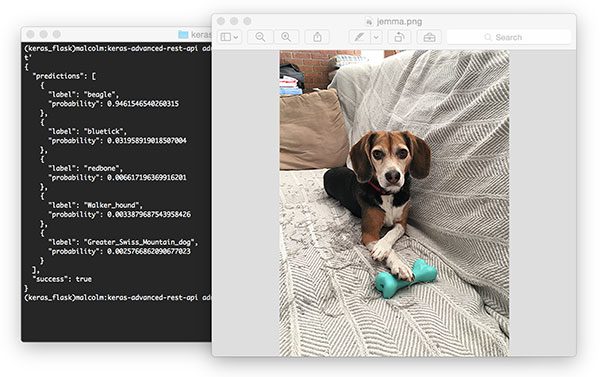
使用cURL來測試我們的Keras REST API伺服器。這是我的家庭小獵犬Jemma。根據我們的ResNet模型,她被歸類為一隻擁有94.6%自信的小獵犬。
curl -X POST -F [email protected] 'http://localhost:5000/predict'你會在你的終端收到JSON格式的預測:
{
"predictions": [
{
"label": "beagle",
"probability": 0.9461546540260315
},
{
"label": "bluetick",
"probability": 0.031958919018507004
},
{
"label": "redbone",
"probability": 0.006617196369916201
},
{
"label": "Walker_hound",
"probability": 0.0033879687543958426
},
{
"label": "Greater_Swiss_Mountain_dog",
"probability": 0.0025766862090677023
}
],
"success": true
}第六部分:使用Python向Keras REST API提交請求
如您所見,使用cURL驗證非常簡單。現在,讓我們構建一個Python指令碼,該指令碼將釋出影象並以程式設計方式解析返回的JSON。
讓我們回顧一下simple_request.py
# import the necessary packages
import requests
# initialize the Keras REST API endpoint URL along with the input
# image path
KERAS_REST_API_URL = "http://localhost:5000/predict"
IMAGE_PATH = "jemma.png"我們在這個指令碼中使用Python請求來處理向伺服器提交資料。我們的伺服器執行在本地主機上,可以通過埠5000訪問端點/predict,這是KERAS_REST_API_URL變數(第6行)指定的。
我們還定義了IMAGE_PATH(第7行)。png與我們的指令碼在同一個目錄中。如果您想測試其他影象,請確保指定到您的輸入影象的完整路徑。
讓我們載入影象併發送到伺服器:
# load the input image and construct the payload for the request
image = open(IMAGE_PATH, "rb").read()
payload = {"image": image}
# submit the request
r = requests.post(KERAS_REST_API_URL, files=payload).json()
# ensure the request was sucessful
if r["success"]:
# loop over the predictions and display them
for (i, result) in enumerate(r["predictions"]):
print("{}. {}: {:.4f}".format(i + 1, result["label"],
result["probability"]))
# otherwise, the request failed
else:
print("Request failed")我們在第10行以二進位制模式讀取影象並將其放入有效負載字典。負載通過請求傳送到伺服器。在第14行釋出。如果我們得到一個成功訊息,我們可以迴圈預測並將它們列印到終端。我使這個指令碼很簡單,但是如果你想變得更有趣,你也可以使用OpenCV在影象上繪製最高的預測文字。
第七部分:執行簡單的請求指令碼
編寫指令碼很容易。開啟終端並執行以下命令(當然,前提是我們的Flask伺服器和Redis伺服器都在執行)。
python simple_request.py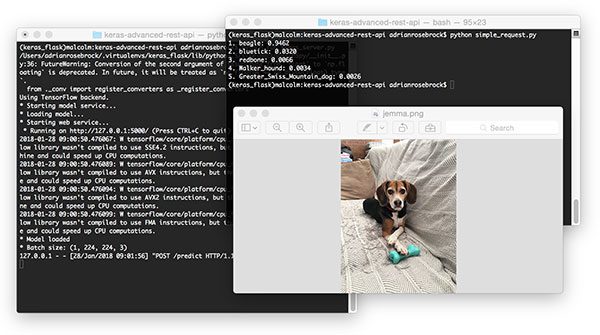
使用Python以程式設計方式使用我們的Keras深度學習REST API的結果
第八部分:擴充套件深度學習REST API時的注意事項
如果您預期在深度學習REST API上有較長一段時間的高負載,那麼您可能需要考慮一種負載平衡演算法,例如迴圈排程,以幫助在多個GPU機器和Redis伺服器之間平均分配請求。
記住,Redis是記憶體中的資料儲存,所以我們只能在佇列中儲存可用記憶體中的儘可能多的影象。
使用float32資料型別的單個224 x 224 x 3影象將消耗602112位元組的記憶體。
假設一臺記憶體為16GB的伺服器,這意味著我們可以在佇列中儲存大約26500個影象,但在這一點上,我們可能希望新增更多的GPU伺服器來更快地消耗佇列。
第九部分:然而,有一個微妙的問題。。。
根據您如何部署深度學習REST API,將classify_process函式保持在與web API其餘程式碼相同的檔案中存在一個微妙的問題。大多數web伺服器,包括Apache和nginx,都允許多個客戶機執行緒。如果你保持classify_process在同一個檔案中預測的觀點,那麼你可能載入多個模型,如果您的伺服器軟體認為有必要建立一個新執行緒來服務的客戶機請求,每一個新執行緒,將會建立一個新檢視,因此一種新的模式將被載入。
解決方案是將classify_process轉移到一個完全獨立的程序中,然後與Flask web伺服器和Redis伺服器一起啟動它。
最後,本人這裡有一些flask和rest api的視訊講解資源,需要的話可以聯絡我