
pandas的表合併操作
在上一篇文章中,我整理了pandas在資料合併和重塑中常用到的concat方法的使用說明。在這裡,將接著介紹pandas中也常常用到的join 和merge方法
merge
pandas的merge方法提供了一種類似於SQL的記憶體連結操作,官網文件提到它的效能會比其他開源語言的資料操作(例如R)要高效。
和SQL語句的對比可以看這裡
merge的引數
on:列名,join用來對齊的那一列的名字,用到這個引數的時候一定要保證左表和右表用來對齊的那一列都有相同的列名。
left_on:左表對齊的列,可以是列名,也可以是和dataframe同樣長度的arrays。
right_on:右表對齊的列,可以是列名,也可以是和dataframe同樣長度的arrays。
left_index/ right_index: 如果是True的haunted以index作為對齊的key
how:資料融合的方法。
sort:根據dataframe合併的keys按字典順序排序,預設是,如果置false可以提高表現。
merge的預設合併方法:
merge用於表內部基於 index-on-index 和 index-on-column(s) 的合併,但預設是基於index來合併。
- 1
- 2
1.1 複合key的合併方法
使用merge的時候可以選擇多個key作為複合可以來對齊合併。
- 1
1.1.1 通過on指定資料合併對齊的列
In [41]: left = pd.DataFrame({'key1' - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
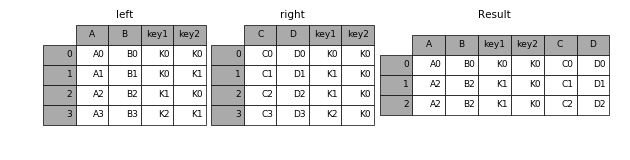
how的方法有:
left
只保留左表的所有資料
In [44]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])- 1

- 1
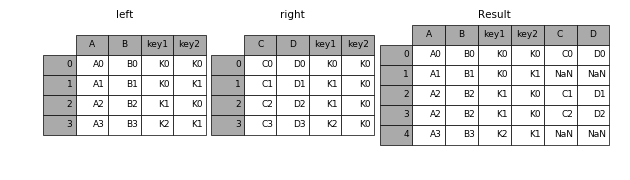
right
只保留右表的所有資料
In [45]: result = pd.merge(left, right, how='right', on=['key1', 'key2'])- 1
- 1

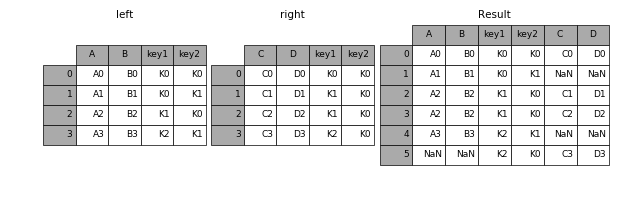
outer
保留兩個表的所有資訊
In [46]: result = pd.merge(left, right, how='outer', on=['key1', 'key2'])- 1
- 1
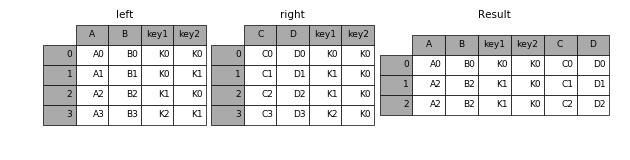
inner
只保留兩個表中公共部分的資訊
In [47]: result = pd.merge(left, right, how='inner', on=['key1', 'key2'])- 1
- 1
1.2 indicator
v0.17.0 版本的pandas開始還支援一個indicator的引數,如果置True的時候,輸出結果會增加一列 ’ _merge’。_merge列可以取三個值
- left_only 只在左表中
- right_only 只在右表中
- both 兩個表中都有
1.3 join方法
dataframe內建的join方法是一種快速合併的方法。它預設以index作為對齊的列。
1.3.1 how 引數
join中的how引數和merge中的how引數一樣,用來指定表合併保留資料的規則。
具體可見前面的 how 說明。
1.3.2 on 引數
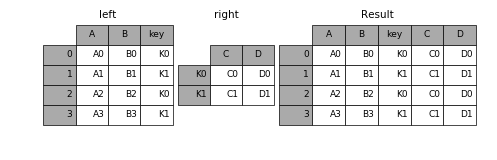
在實際應用中如果右表的索引值正是左表的某一列的值,這時可以通過將 右表的索引 和 左表的列 對齊合併這樣靈活的方式進行合併。
ex 1
In [59]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key': ['K0', 'K1', 'K0', 'K1']})
....:
In [60]: right = pd.DataFrame({'C': ['C0', 'C1'],
....: 'D': ['D0', 'D1']},
....: index=['K0', 'K1'])
....:
In [61]: result = left.join(right, on='key')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.3.3 suffix字尾引數
如果和表合併的過程中遇到有一列兩個表都同名,但是值不同,合併的時候又都想保留下來,就可以用suffixes給每個表的重複列名增加字尾。
In [79]: result = pd.merge(left, right, on='k', suffixes=['_l', '_r'])
- 1
- 2
- 1
- 2

* 另外還有lsuffix 和 rsuffix分別指定左表的字尾和右表的字尾。
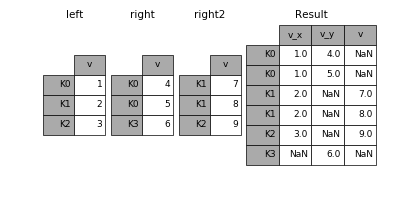
1.4 組合多個dataframe
一次組合多個dataframe的時候可以傳入元素為dataframe的列表或者tuple。一次join多個,一次解決多次煩惱~
In [83]: right2 = pd.DataFrame({'v': [7, 8, 9]}, index=['K1', 'K1', 'K2'])
In [84]: result = left.join([right, right2])- 1
- 2
- 3
- 1
- 2
- 3
1.5 更新表的nan值
1.5.1 combine_first
如果一個表的nan值,在另一個表相同位置(相同索引和相同列)可以找到,則可以通過combine_first來更新資料
1.5.2 update
如果要用一張表中的資料來更新另一張表的資料則可以用update來實現
1.5.3 combine_first 和 update 的區別
使用combine_first會只更新左表的nan值。而update則會更新左表的所有能在右表中找到的值(兩表位置相對應)。
示例程式碼參考來源——官網