
2019最新大資料學習路線
在中國,大資料也正迅速成為行業和市場的熱點。專注與亞太及中國市場的市場調查機構泛亞諮詢釋出的調研資料顯示,目前出現在各類招聘平臺上與資料分析相關的招聘需求比去年同期相比,增長率高達67%;大資料相關高階職位的薪酬與其他同類技術職位相比平均高出43%以上。無論是世界範圍內還是在中國,大資料浪潮正在深刻改變著各行各業,而各行各業對大資料人才的需求,以及技術從業者希望躋身大資料高階人才的需求也變得越來越強烈。
但想要成為一名合格的大資料工程師,必須具備一定的技術,總結了一下:

1、必須技能10條:
01.Java高階程式設計(虛擬機器、併發)
02.Linux 基本操作
03.Hadoop(此處指
04.HBase(JavaAPI操作+Phoenix )
05.Hive
06.Kafka
07.Storm
08.Scala
09.Python
10.Spark (Core+sparksql+Spark streaming )
2、進階技能6條:
11.機器學習演算法以及mahout庫加MLlib
12.R語言
13.Lambda 架構
14.Kappa架構
15.Kylin
16.Aluxio
對於大資料技術的學習,我們老師給出了以下學習路線圖可供規劃自己的學習之路!
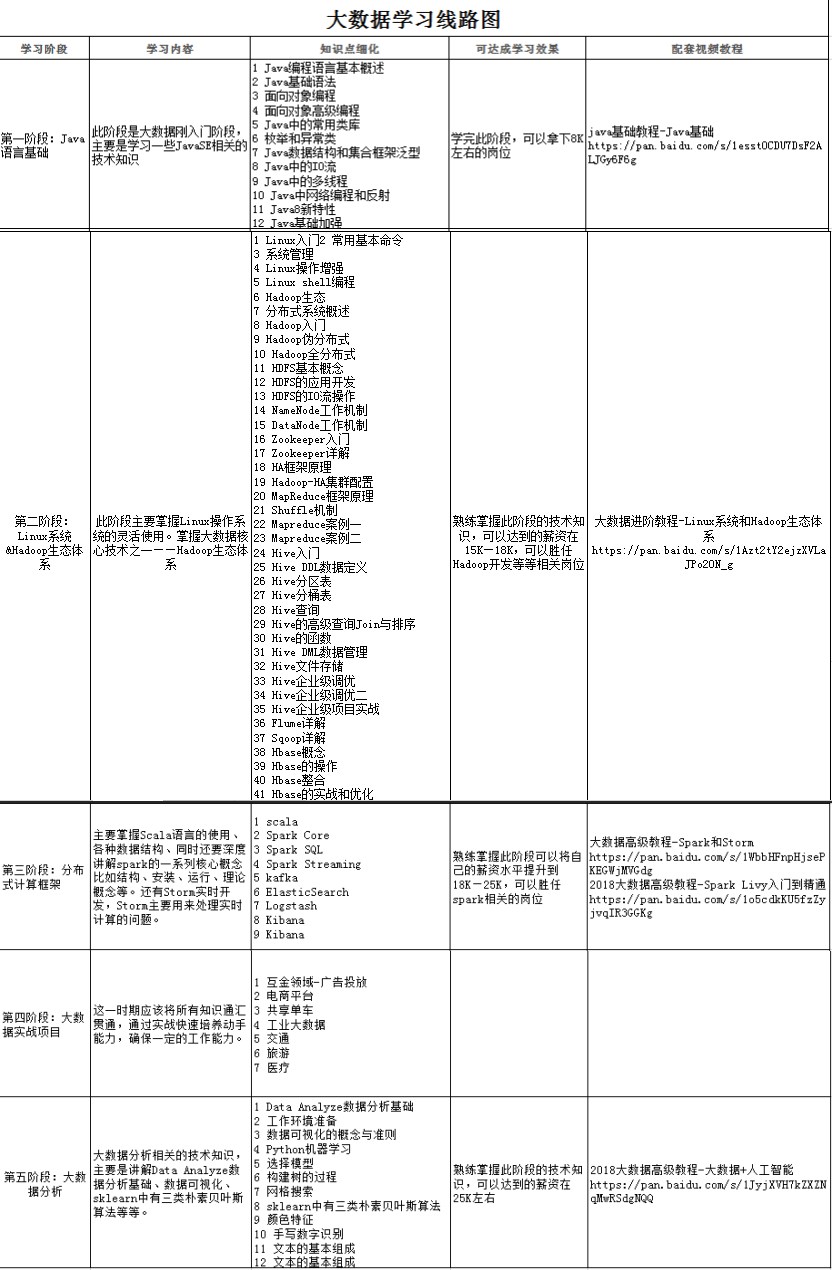
階段一、大資料基礎——java語言基礎方面
(1)Java語言基礎
Java開發介紹、熟悉Eclipse開發工具、Java語言基礎、Java流程控制、Java字串、Java陣列與類和物件、數字處理類與核心技術、I/O與反射、多執行緒、Swing程式與集合類
(2) HTML、CSS與JavaScript
PC端網站佈局、HTML5+CSS3基礎、WebApp頁面佈局、原生JavaScript互動功能開發、Ajax非同步互動、jQuery應用
(3)JavaWeb和資料庫
資料庫、JavaWeb開發核心、JavaWeb開發內幕
階段二、 Linux&Hadoop生態體系
Linux體系、Hadoop離線計算大綱、分散式資料庫Hbase、資料倉庫Hive、資料遷移工具Sqoop、Flume分散式日誌框架
階段三、 分散式計算框架和Spark&Strom生態體系
(1)分散式計算框架
Python程式語言、Scala程式語言、Spark大資料處理、Spark—Streaming大資料處理、Spark—Mlib機器學習、Spark—GraphX 圖計算、實戰一:基於Spark的推薦系統(某一線公司真實專案)、實戰二:新浪網(www.sina.com.cn)
(2)storm技術架構體系
Storm原理與基礎、訊息佇列kafka、Redis工具、zookeeper詳解、實戰一:日誌告警系統專案、實戰二:猜你喜歡推薦系統實戰
階段四、 大資料專案實戰(一線公司真實專案)
資料獲取、資料處理、資料分析、資料展現、資料應用
階段五、 大資料分析 —AI(人工智慧)
Data Analyze工作環境準備&資料分析基礎、資料視覺化、Python機器學習
1、Python機器學習2、影象識別&神經網路、自然語言處理&社交網路處理、實戰專案:戶外裝置識別分析
學習建議:如果有足夠的時間和精力,可以按照上面的學習路線圖和視訊教程進行自學。