
20172323 2018-2019-1 《程式設計與資料結構》課堂測試報告
20172323 2018-2019-1 《程式設計與資料結構》課堂測試報告
課程:《程式設計與資料結構》
班級: 1723
姓名: 王禹涵
學號: 20172323
實驗教師:王志強老師
測試日期:2018年12月10日
必修/選修: 必修
1.測試內容
哈夫曼編碼測試
設有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
給定一個包含26個英文字母的檔案,統計每個字元出現的概率,根據計算的概率構造一顆哈夫曼樹。
並完成對英文檔案的編碼和解碼。
要求:
(1)準備一個包含26個英文字母的英文檔案(可以不包含標點符號等),統計各個字元的概率
(2)構造哈夫曼樹
(3)對英文檔案進行編碼,輸出一個編碼後的檔案
(4)對編碼檔案進行解碼,輸出一個解碼後的檔案
(5)撰寫部落格記錄實驗的設計和實現過程,並將原始碼傳到碼雲
(6)把實驗結果截圖上傳到雲班課
2. 測試過程及結果
基本原理:
哈夫曼樹:給定n個權值作為n個葉子結點,構造一棵二叉樹,若帶權路徑長度達到最小,稱這樣的二叉樹為最優二叉樹,也稱為哈夫曼樹(Huffman Tree)。哈夫曼樹是帶權路徑長度最短的樹,權值較大的結點離根較近。
路徑: 樹中一個結點到另一個結點之間的分支構成這兩個結點之間的路徑。
路徑長度:路徑上的分枝數目稱作路徑長度。
樹的路徑長度:從樹根到每一個結點的路徑長度之和。
結點的帶權路徑長度:在一棵樹中,如果其結點上附帶有一個權值,通常把該結點的路徑長度與該結點上的權值之積稱為該結點的帶權路徑長度(weighted path length)
樹的帶權路徑長度:如果樹中每個葉子上都帶有一個權值,則把樹中所有葉子的帶權路徑長度之和稱為樹的帶權路徑長度。
具體實現:
- 第一步需要定義哈夫曼樹的結點類HuffmanNode,其中包含了每個結點的攜帶的資訊name,它的權重weight,指向它左右孩子的指標以及表示編碼的String值code。同時為了方便進行排序,聲明瞭Comparable介面
protected HuffmanNode left; protected HuffmanNode right; protected String name; protected double weight; protected String code; public HuffmanNode(String name, double weight){ this.name = name; this.weight = weight; code = ""; } public int compareTo(HuffmanNode node) { if (weight >= node.weight){ return 1; } else { return -1; } }
- 接下來構造哈夫曼樹
while(nodes.size() > 1){
Collections.sort(nodes);
Node<T> left = nodes.get(nodes.size()-1);
Node<T> right = nodes.get(nodes.size()-2);
Node<T> parent = new Node<T>(null, left.getWeight()+right.getWeight());
parent.setLeft(left);
parent.setRight(right);
nodes.remove(left);
nodes.remove(right);
nodes.add(parent);
}
return nodes.get(0);
這裡將所有的哈夫曼樹的結點都存在了一個數組之中,判斷陣列1內是否有元素,進入while迴圈之後先將陣列元素進行排序,然後取出陣列中的最小元素和次小元素(即是陣列中的末兩位)分別作為左右孩子,二者之和作為父結點元素放入陣列之中重新進行排序,直至陣列中元素為一,哈夫曼樹構造完成。緊接著是哈夫曼樹的廣度優先遍歷方法
List<Node<T>> list = new ArrayList<Node<T>>();
Queue<Node<T>> queue = new ArrayDeque<Node<T>>();
if(root != null){
queue.offer(root);
}
while(!queue.isEmpty()){
list.add(queue.peek());
Node<T> node = queue.poll();
if(node.getLeft() != null){
queue.offer(node.getLeft());
}
if(node.getRight() != null){
queue.offer(node.getRight());
}
}
return list;
基礎的哈夫曼樹構造好了,接著需要在此基礎上進行哈夫曼編碼。基本思路是,從根結點開始設二叉樹的左子樹編碼為‘0’,右子樹的編碼為‘1’,依次編碼下去直到葉結點,然後從根到每個葉結點依次寫出葉結點的編碼--哈夫曼編碼,具體實現就是在構造哈夫曼樹的同時,加上如下程式碼
left.setCode("0");
right.setCode("1");因為這裡設定的是String型,所以要加上“”,表示字串。同時遍歷方法也要相應加上“0”,“1”。當遍歷到左孩子時,加上1,遍歷到右孩子時,加上0.
- 基本的方法已經構造好了,接下來需要進行的是讀取檔案進行編碼,在指定目錄下新增一個txt檔案,裡面是需要進行編碼的文字。運用
File file = new File("此處填寫檔案路徑");
BufferedReader br = new BufferedReader(new FileReader(file));讀入檔案內的資訊。通過readline方法將資訊成行讀入,並重新拼接成字串,逐個字元進行比對,統計出現的個數及概率並進行輸出
List<String> list = new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
list.add("f");
list.add("g");
list.add("h");
list.add("i");
list.add("j");
list.add("k");
list.add("l");
list.add("m");
list.add("n");
list.add("o");
list.add("p");
list.add("q");
list.add("r");
list.add("s");
list.add("t");
list.add("u");
list.add("v");
list.add("w");
list.add("x");
list.add("y");
list.add("z");
list.add(" ");
int[] number = new int[]{0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
File file = new File("C:\\Users\\10673\\Desktop\\input.txt");
BufferedReader br = new BufferedReader(new FileReader(file));
String s;
String message = "";
while((s = br.readLine()) != null){
message += s;
}
String[] result = message.split("");
for (int n = 0;n < result.length; n++){
for (int i = 0; i < 27; i++){
if (result[n].equals(list.get(i))){
number[i] += 1;
}
}
}
List<HuffmanNode> nodeList = new ArrayList<HuffmanNode>();
DecimalFormat df = new DecimalFormat( "0.0000000");
double wei;
double sum = result.length;
for(int i = 0;i<27;i++){
wei = ((double) number[i]/sum);
System.out.println(list.get(i) + "出現" + number[i] + "次,概率為" + df.format(wei));
nodeList.add(new HuffmanNode(list.get(i),number[i]));
}
Collections.sort(nodeList);
HuffmanTree huffmanTree = new HuffmanTree();
HuffmanNode node = huffmanTree.createTree(nodeList);
List<HuffmanNode> inlist = new ArrayList<HuffmanNode>();
inlist = huffmanTree.breadth(node);以上程式碼並不是特別的複雜,我構造了一個字元列表,用以與得到的字串進行比對,當某個字元比對成功之後,相應位置的陣列的值加一,這樣就可以統計到每個字元出現的次數。再然後計算得到每個字元出現的概率,將這些字元及其權重儲存在HuffmanNode的列表中,通過此就可以呼叫哈夫曼樹的構造方法。剩下的幾個方法,就是將哈夫曼樹的結點逐個進行編碼解碼,並輸出到指定的檔案之中
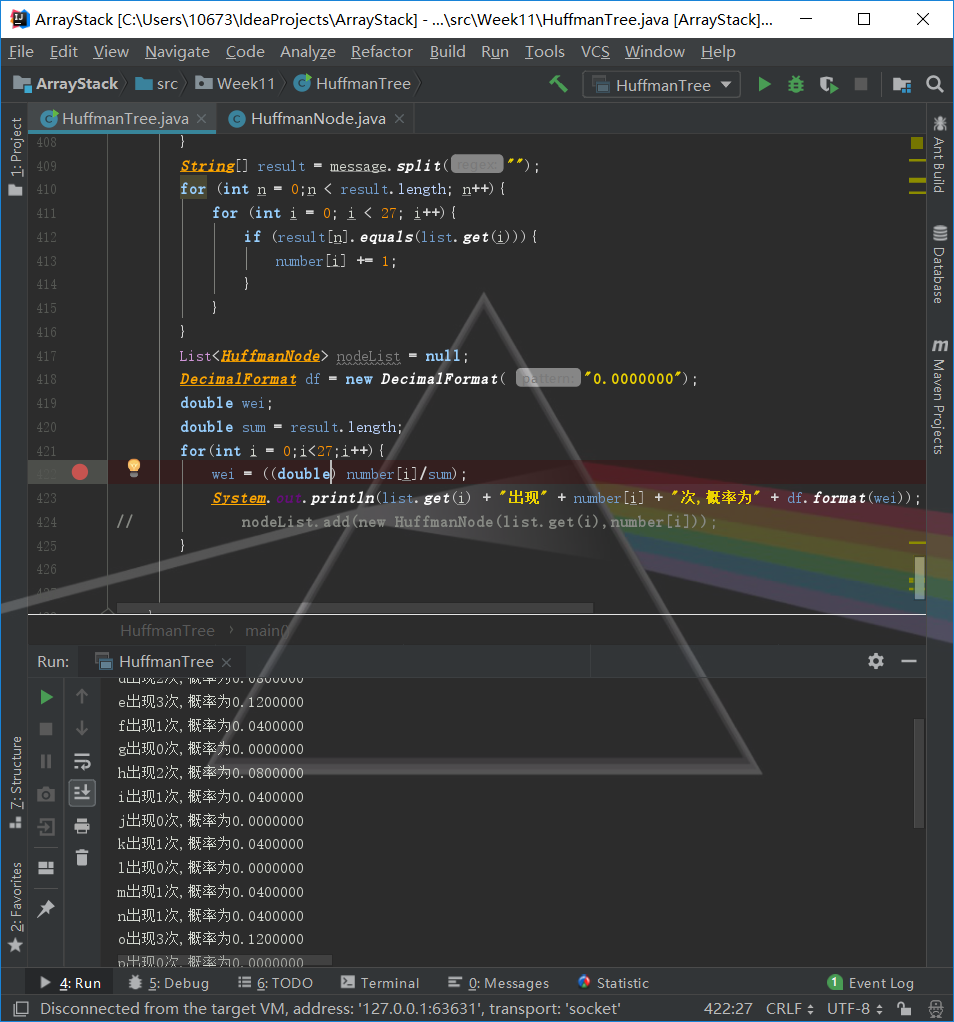
執行結果如圖所示
[](https://img2018.cnblogs.com/blog/1332964/201812/1332964-20181211214511138-1894899771.png
{kind=link}
3. 程式碼連結
4. 測試過程中遇到的問題和解決過程
問題1:運用除法計算字元出現的概率時,運算結果全部為0,如圖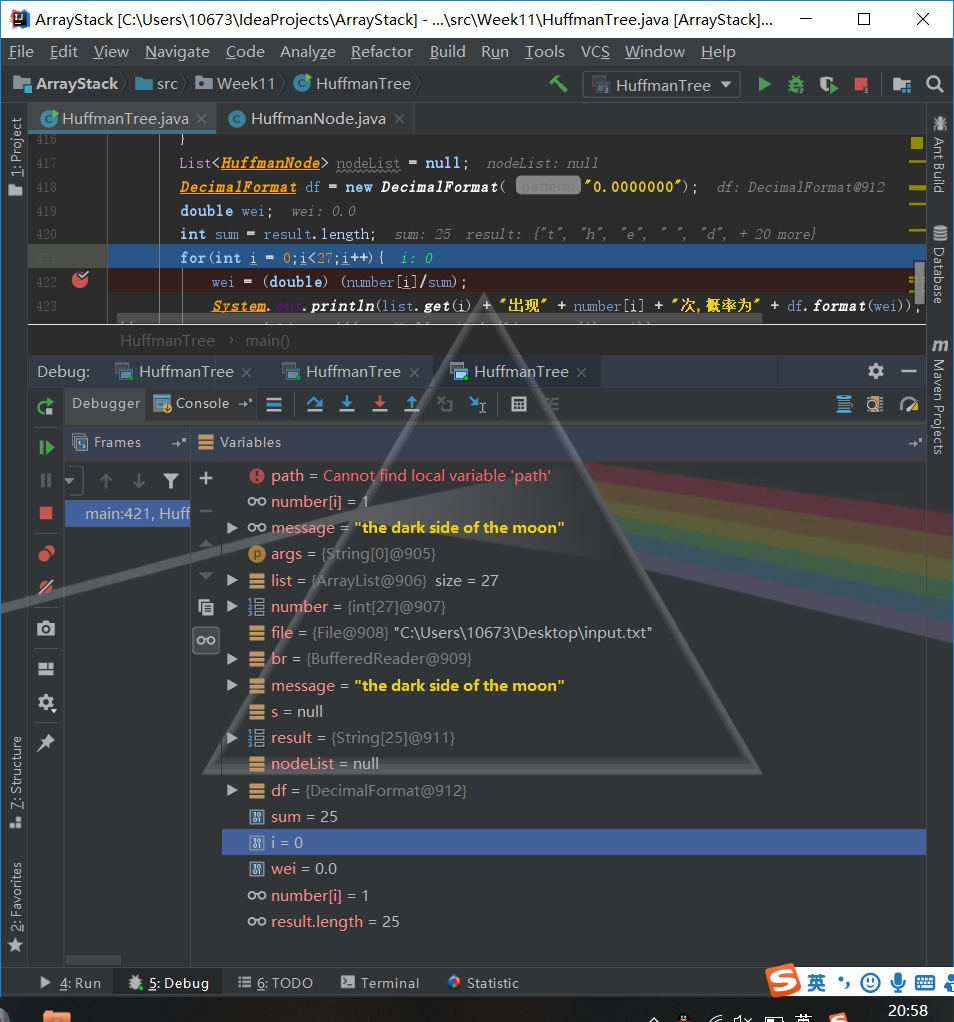
問題1解決方案:最開始以為是顯示的只有小數點後一位,所以很多資料比較小,四捨五入之後就只剩下0.0,查閱資料重新控制double型別小數點後位數的方法DecimalFormat df = new DecimalFormat( "0.00"); //設定double型別小數點後位數格式
double d1 = 2.1;
System.out.println(df.format(d1)); //將輸出2.10
輸出之後發現概率全部都為0.這裡運用到的方法是number[i]/sum,sum是總的字元個數,number[i]依次是每個字元的出現次數。
問題就出在這個除法上,因為這是兩個整型數相除,所以得到的依然會是一個整型數,即便再把它轉換成double型別,最終出來的也是0.0,所以應該在相除之前就將兩個除數轉換為double型別,這樣得出的結果就是正確的
參考資料
- [哈夫曼樹的java實現](https://blog.csdn.net/jdhanhua/article/details/6621026)