
Java如何實現哈夫曼編碼
哈夫曼樹
既然是學習哈夫曼編碼,我們首先需要知道什麼是哈夫曼樹:給定n個權值作為n個葉子結點,構造一棵二叉樹,若帶權路徑長度達到最小,稱這樣的二叉樹為最優二叉樹,也稱為哈夫曼樹(Huffman Tree)。哈夫曼樹是帶權路徑長度最短的樹,權值較大的結點離根較近。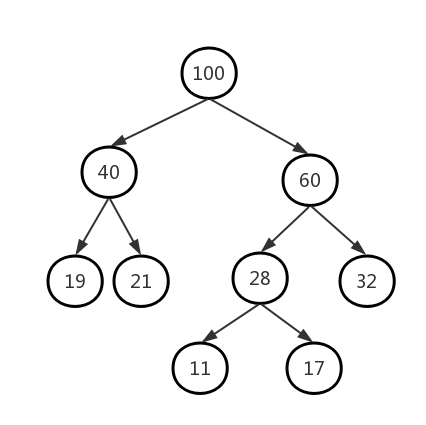
哈夫曼編碼
在日常計算機的使用中,我們一定會出現下面這種情況:假如給定a、b、c、d、e五個字元,它們在文字中出現的概率如下圖所示:
| 字元 | 概率 |
|---|---|
| a | 0.12 |
| b | 0.40 |
| c | 0.15 |
| d | 0.05 |
| e | 0.25 |
我們現在要將文字編碼成0/1序列從而使得計算機能夠進行讀取和計算。為了保證每個字元的獨一性,所以我們給予不同的的字元以不同的編碼。如果給每個字元賦予等長的編碼的話,會使得平均的編碼長度過長,影響計算時的效能,浪費計算機的資源(定長編碼的缺點)。這時我們就想到了變長編碼,理所當然的,給出現概率較大的字元賦予較短的編碼,概率較小的字元賦予較長的編碼,這樣在計算的時候不就可以節省很多時間了嗎?可這樣我們又面臨到了一個巨大的問題,我們來看下面這種情況,我們對字元進行編碼:
| 字元 | 概率 | 編碼 |
|---|---|---|
| a | 0.12 | 01 |
| b | 0.40 | 0 |
| c | 0.15 | 00 |
| d | 0.05 | 10 |
| e | 0.25 | 1 |
假設現在文字中的字元是bcd,轉換之後的0/1序列為00010,可我們要在轉換成文字的時候究竟是把第一位的0讀作b還是把前兩位的00讀作c呢?為了解決這個問題,就又有了字首碼的概念。顧名思義,字首碼的含義就是任意字元的編碼都不是其他字元編碼的字首。那麼該如何形成字首碼呢?首先我們要構造一棵二叉樹,指向左孩子的"邊"記作0,指向右孩子的點記作“1”,葉子節點為代編碼的字元,出現概率越大的字元離根的距離就越近。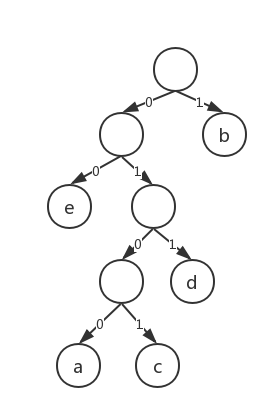
| 字元 | 概率 | 編碼 |
|---|---|---|
| a | 0.12 | 0100 |
| b | 0.40 | 1 |
| c | 0.15 | 0101 |
| d | 0.05 | 011 |
| e | 0.25 | 00 |
我們在前面提到:哈夫曼樹的帶權路徑最小,所以有哈夫曼樹構成的字首碼記作哈夫曼編碼。哈夫曼作為已知的最佳無失真壓縮演算法,滿足字首碼的性質,可以即時解碼。
哈夫曼編碼(Huffman Coding),又稱霍夫曼編碼,是一種編碼方式,哈夫曼編碼是可變字長編碼(VLC)的一種。Huffman於1952年提出一種編碼方法,該方法完全依據字元出現概率來構造異字頭的平均長度最短的碼字,有時稱之為最佳編碼,一般就叫做Huffman編碼(有時也稱為霍夫曼編碼)。
java程式碼實現
實現哈夫曼編碼的主要思路為從指定的檔案中讀出文字,首先通過遍歷獲得各個字元出現的概率,根據出現概率的大小構造二叉樹,在此基礎上進行編碼解碼。
- 首先來構造哈夫曼樹的結點類,在結點類中有老生常談的變數資料data、權重weight、指向左孩子的指標left、指向右孩子的指標right。除此之外,為了在構造了哈夫曼樹之後容易對data進行編碼,在這裡我還使用了一個變數code來儲存0/1字元。

public class Node<T> implements Comparable<Node<T>> {
private T data;
private double weight;
private Node<T> left;
private Node<T> right;
String code;
public Node(T data, double weight){
this.data = data;
this.weight = weight;
this.code = "";
}
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
public double getWeight() {
return weight;
}
public void setWeight(double weight) {
this.weight = weight;
}
public Node<T> getLeft() {
return left;
}
public void setLeft(Node<T> left) {
this.left = left;
}
public Node<T> getRight() {
return right;
}
public void setRight(Node<T> right) {
this.right = right;
}
public String getCode(){
return code;
}
public void setCode(String str){
code = str;
}
@Override
public String toString(){
return "data:"+this.data+";weight:"+this.weight+";code: "+this.code;
}
@Override
public int compareTo(Node<T> other) {
if(other.getWeight() > this.getWeight()){
return 1;
}
if(other.getWeight() < this.getWeight()){
return -1;
}
return 0;
}
}- 緊接著我們來構建哈夫曼樹。
- createTree方法返回一個結點,也就是根結點。首先把所有的nodes結點類都儲存在一個List中,利用Collections的sort方法把結點按照權值的大小按照從大到小的順序進行排列。然後把List中的倒數第二個元素設為左孩子,倒數第一個元素設為右孩子。這個時候要注意:它們的雙親結點為以左右孩子的權值的和作為權值的構成的新的結點。然後刪去左右孩子結點,將形成的新結點加入的List中。直到List中只剩下一個結點,也就是根結點時為止。
public Node<T> createTree(List<Node<T>> nodes) { while (nodes.size() > 1) { Collections.sort(nodes); Node<T> left = nodes.get(nodes.size() - 2); left.setCode(0 + ""); Node<T> right = nodes.get(nodes.size() - 1); right.setCode(1 + ""); Node<T> parent = new Node<T>(null, left.getWeight() + right.getWeight()); parent.setLeft(left); parent.setRight(right); nodes.remove(left); nodes.remove(right); nodes.add(parent); } return nodes.get(0); }- 在構建哈夫曼樹的類中還實現了一個廣度遍歷的方法,在遍歷的時候,每遍歷到左孩子,就把結點中的code變數加上“0”,這裡的加不是簡單的數學運算,而是字串的疊加。每遍歷到右孩子,就把結點中的code變數加上“1”,這樣遍歷過一遍後,葉子結點中的code儲存的就是對應的哈夫曼編碼值。
public List<Node<T>> breadth(Node<T> root) { List<Node<T>> list = new ArrayList<Node<T>>(); Queue<Node<T>> queue = new ArrayDeque<Node<T>>(); if (root != null) { queue.offer(root); root.getLeft().setCode(root.getCode() + "0"); root.getRight().setCode(root.getCode() + "1"); } while (!queue.isEmpty()) { list.add(queue.peek()); Node<T> node = queue.poll(); if (node.getLeft() != null) node.getLeft().setCode(node.getCode() + "0"); if (node.getRight() != null) node.getRight().setCode(node.getCode() + "1"); if (node.getLeft() != null) { queue.offer(node.getLeft()); } if (node.getRight() != null) { queue.offer(node.getRight()); } } return list; } - 接下來我們首先從指定的檔案中讀取文字:
File file = new File("G:/usually/input/input1.txt");- 這裡我們還需要構造一個類對讀取的文字進行處理:chars陣列儲存的是文字中所有可能的字元,number陣列中儲存的是文字中所有字元出現的次數,這裡我所申請的number陣列的長度為27,為什麼是27呢?因為在這裡加上了空格。在num方法中利用雙迴圈對字元進行計數,在這裡不再過多贅述。
public class readtxt {
char[] chars = new char[]{'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s'
,'t','u','v','w','x','y','z',' '};
int[] number = new int[]{0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
public String txtString(File file){
StringBuilder result = new StringBuilder();
try{
BufferedReader br = new BufferedReader(new FileReader(file));//構造一個BufferedReader類來讀取檔案
String s = null;
while((s = br.readLine())!=null){//使用readLine方法,一次讀一行
result.append(System.lineSeparator()+s);
num(s);
}
br.close();
}catch(Exception e){
e.printStackTrace();
}
return result.toString();
}
public void num(String string){
for(int i = 0;i<27;i++){
int temp = 0;
for(int j = 0;j<string.length();j++){
if(string.charAt(j) == chars[i])
temp++;
}
number[i] += temp;
}
}
public int[] getNumber(){
return number;
}
public char[] getChars(){
return chars;
}
}- 呼叫上面readtxt中的方法對文字進行處理,定義兩個陣列獲得文字中出現的字元和字元出現的次數。
readtxt read = new readtxt();
String temp = read.txtString(file);
int[] num = read.getNumber();
char[] chars = read.getChars();- 利用一個迴圈把對應的data值和weight權重值構造成結點加入到list中。
for(int i = 0;i<27;i++){
System.out.print(chars[i]+":"+num[i]+" ");
list.add(new Node<String>(chars[i]+"",num[i]));
}- 構建哈夫曼樹並得到根結點。
HuffmanTree huffmanTree = new HuffmanTree();
Node<String> root = huffmanTree.createTree(list);- 呼叫哈夫曼樹中廣度遍歷方法,在建立兩個新的list用來儲存遍歷之後的字元以及相對應的哈夫曼編碼。
list2=huffmanTree.breadth(root);
for(int i = 0;i<list2.size();i++){
if(list2.get(i).getData()!=null) {
list3.add(list2.get(i).getData());
list4.add(list2.get(i).getCode());
}
}- 對從指定文字中讀出的資料進行遍歷,並與list3中的字元進行比較,如若相等,則轉換為對應的變碼。直至遍歷結束,哈夫曼編碼完成。
for(int i = 0;i<temp.length();i++){
for(int j = 0;j<list3.size();j++){
if(temp.charAt(i) == list3.get(j).charAt(0))
result += list4.get(j);
}
}- 在解碼的過程中我在這裡選擇了用一個list5把已編碼完成的字串分開來儲存,然後對list5在進行遍歷,從list5中取出一位元素temp2與list4中對應的編碼進行比對,如果沒有相同的,再從list5中讀取一位加到temp2的後面,如果有,則清空temp2。每次找到相同的,就把對應的字元加到temp3的後面,直至整個list5遍歷結束,temp3即為解碼後的結果。
for(int i = 0;i<result.length();i++){
list5.add(result.charAt(i)+"");
}
while (list5.size()>0){
temp2 = temp2+"" +list5.get(0);
list5.remove(0);
for(int i=0;i<list4.size();i++){
if (temp2.equals(list4.get(i))) {
temp3 = temp3+""+list3.get(i);
temp2 = "";
}
}
}- 寫入檔案,大功告成!
File file2 =new File("G:/usually/input/input2.txt");
Writer out =new FileWriter(file2);
out.write(temp3);
out.close();最後得到的結果:

完整程式碼
我有一個微信公眾號,經常會分享一些Java技術相關的乾貨;如果你喜歡我的分享,可以用微信搜尋“Java團長”或者“javatuanzhang”關注。