
哈夫曼編碼實現檔案的壓縮和解壓
哈夫曼編碼的概念
哈夫曼編碼是基於哈夫曼樹實現的一種檔案壓縮方式。
哈夫曼樹:一種帶權路徑最短的最優二叉樹,每個葉子結點都有它的權值,離根節點越近,權值越小(根節點權值為0,往下隨深度增加依次加一),樹的帶權路徑等於各個葉子結點的數值與其權值的乘積和。哈夫曼樹如圖:
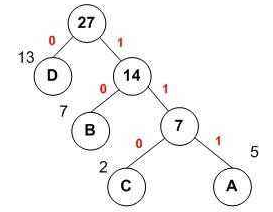
從圖中我們可以看出,資料都存放在葉子結點中,且為了達到樹的帶權路徑最短,我們把數值大的節點放在靠近根的位置,這棵樹的帶權路徑長度為:23+53+72+131=48。接下來我們為每個節點賦予哈夫曼編碼,假設從根節點出發,到左子樹獲得編碼0,到右子樹獲得編碼1,這樣我們可以得到D的編碼是0,B的編碼是10,C的編碼是110,A的編碼是111。離根越近的節點對應的編碼越短,節點的數值越大。那麼,如何把哈夫曼編碼應用在文件的壓縮上呢?我們記檔案中字元出現的次數為節點的數值,出現次數最多的字元會分配到哈夫曼樹的靠近根節點的地方,自然也就會獲得較短的哈夫曼編碼。於是我們通過這種方式,使得文件中的字元獲得不同的哈夫曼編碼,因為出現頻次高的字元對應編碼較短,所以從文件中獲取的位元組被哈夫曼編碼替換之後,會獲使得其佔用的總儲存空間變小,實現壓縮的效果。
實現哈夫曼壓縮和解壓的步驟詳解
建立哈夫曼樹:
1、使用IO流逐位元組讀取TXT文件。用一個數組(0~255,下標表示ASCII碼)來儲存不同字元出現的次數(對應位置加一)。
2、建一個節點類,儲存節點物件的資訊。將陣列每一位表示的字元和出現頻次存入建立的節點,把所有節點存入一個連結串列。
3、根據節點儲存的頻次值,對連結串列進行排序(從小到大)。
4、從連結串列中取出並刪除最小的兩個節點,建立一個他們的父節點,父節點不存字元,值為那兩個節點的和,把那兩個節點分別作為其左子節點和右子節點,最後把這個父節點存入連結串列。再次排序,取出並刪除最小的兩個節點,生成父節點,再存入…以此類推,最終生成一棵哈夫曼樹。
5、對哈夫曼樹進行遍歷,使得葉子結點獲得相應編碼,同時把字元和它對應的哈夫曼編碼存入HashMap。
哈夫曼壓縮的實現:
1、再次讀取原文件(之前第一次讀取只是為了獲取HashMap),根據HashMap中的字元與編碼的鍵值對把整個文件轉化為一串01碼(此處可以用01字串表示)。
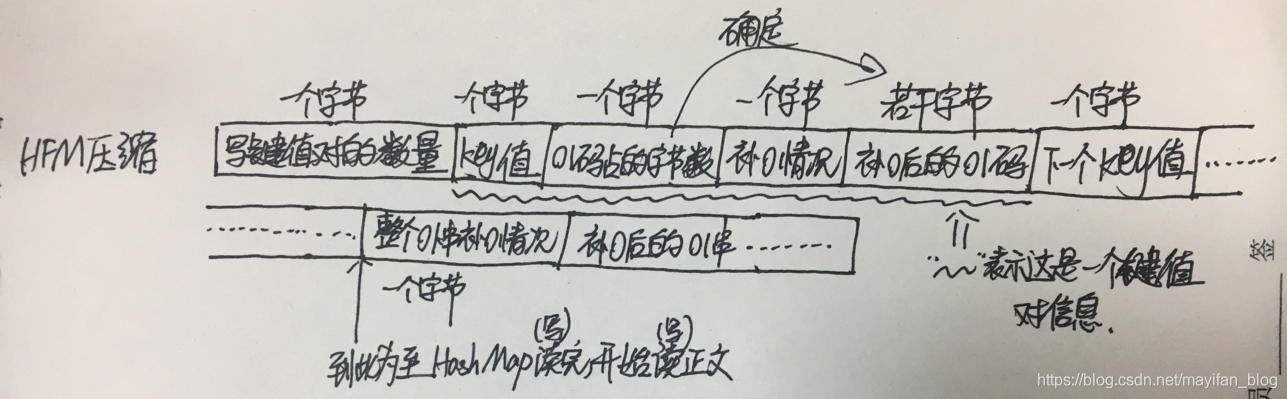
2、準備將資料寫入要壓縮的目錄。首先把HashMap寫入(如果壓縮檔案中沒有HashMap的資訊,在解壓的時候將無法還原)。HashMap包括兩個部分,一部分是key值(即字元),佔一個位元組,另一部分是01字串編碼,若轉為位元組表示,可能小於8位有可能大於8位(即長度不確定),我們在寫入時必須明確每個01串佔據的位元組個數,再者,因為我們是以位元組的形式寫資料,寫資料的時候總位數應是8的整數倍,需要對01串末尾補0。我們具體是這樣寫HashMap的:寫鍵值對的數量(佔一個位元組);寫key值(把字元轉為ASCII值寫入,佔一個位元組);寫01碼佔幾個位元組(是補0後的位元組數,此資訊佔一個位元組);寫補0情況(某位補0數,此處也佔一個位元組),寫補零後的01碼對應的若干位元組。繼續下一個鍵值對的寫入…以此類推,直到整個HashMap的鍵值對都寫完。
3、剛才寫的是編碼資訊,接下來準備把整個原文件轉換得到的01串寫入,這也是我們之後需要還原的資訊。剛才的流沒有關閉,我們是繼續寫入的。因為這依然會遇到最後一個位元組不足8位的情況,我們需要補0並記錄補0情況。先寫整個文件的補0情況(一個位元組),再把補0後的01串以每8位為一個位元組寫入壓縮檔案。
4、以上操作便實現了哈夫曼壓縮。另外需要注意的是,IO流的read()和write()方法是對位元組進行讀寫,如果寫的是int型別的資料,那麼它表示的是相應的ASCII碼值,如果寫入的是字元,也是會轉化為對應的位元組的(0~255個字元都有對應的ASCII碼,也都有對應的位元組表示)。
壓縮格式如圖
解壓的實現:
1、先讀取第一個位元組,即編碼個數,確定了我們需要讀多少組資料。
2、開始正式讀取鍵值對資訊。讀取key值,讀取01碼對應的位元組數,讀取補0情況,再讀取表示01串的位元組資料,去掉之前補的0,還原回0和1表示的字串,即字元對應的哈夫曼編碼,把讀到的字元和哈夫曼編碼儲存在一個新建的HashMap中,需要注意的是此處key值儲存為哈夫曼編碼,value值儲存為字元的資訊。以此類推,直到讀完所有鍵值對資訊。
3、讀整個檔案補0個數,讀取檔案位元組資料,去掉補的0,得到之前存入的哈夫曼編碼01字串。
4、確定希望解壓的檔案目錄。逐位讀取01字串,將讀到的位累加在一個臨時字串中,每讀一位都拿這個臨時字串和HashMap進行對照,如果有對應key值,則獲取對應字元資訊寫入流,把字串置空,繼續迴圈累加新的01串。最終讀完後,解壓目錄中便得到了我們解壓後的檔案。
程式碼實現
1、節點類:
public class Node<T> implements Comparable<Node<T>>{
private T data;
private int weight;
private Node<T> left;
private Node<T> right;
public Node(T data,int weight)
{
this.data=data;
this.weight=weight;
}
/**
* 獲取節點資料
*/
public String toString()
{
return "data:"+data+" "+"weight:"+weight;
}
/**
* 節點權值比較方法
* @param o
* @return
*/
public int compareTo(Node<T> o) {
if(this.weight>o.weight)
return 1;
else if(this.weight<o.weight)
return -1;
return 0;
}
public void setData(T data)
{
this.data=data;
}
public void setWeight(int weight)
{
this.weight=weight;
}
public T getData()
{
return data;
}
public int getWeight()
{
return weight;
}
public void setLeft(Node<T> node)
{
this.left=node;
}
public void setRight(Node<T> node)
{
this.right=node;
}
public Node<T> getLeft()
{
return this.left;
}
public Node<T> getRight()
{
return this.right;
}
}
2、mian方法入口及建樹的方法
public class HFMcompression {
public static void main(String[] args)
{
HFMcompression hc = new HFMcompression();
File file = new File("E:\\workspace\\mayifan\\src\\com\\myf\\HFMcompression1223\\data1.txt");//原始檔地址
FileOperation fo = new FileOperation();
int [] a = fo.getArrays(file);
System.out.println(Arrays.toString(a)); //列印
LinkedList<Node<String>> list = hc.createNodeList(a);//把陣列的元素轉為節點並存入連結串列
for(int i=0;i<list.size();i++)
{
System.out.println(list.get(i).toString());
}
Node<String> root = hc.CreateHFMTree(list); //建樹
System.out.println("列印整棵樹、、、、");
hc.inOrder(root); //列印整棵樹
System.out.println("獲取葉子結點哈夫曼編碼");
HashMap<String,String> map = hc.getAllCode(root);//獲取字元編碼HashMap
String str = fo.GetStr(map, file);
System.out.println("轉化得到的01字串:"+str);
File fileCompress = new File("E:\\workspace\\mayifan\\src\\com\\myf\\HFMcompression1223\\data2.zip");//壓縮檔案地址
fo.compressFile(fileCompress,map,str); //生成壓縮檔案
File fileUncompress = new File("E:\\workspace\\mayifan\\src\\com\\myf\\HFMcompression1223\\data3.txt");//壓縮檔案地址
fo.uncompressFile(fileCompress,fileUncompress);//解壓檔案至fileUncompress處
}
/**
* 把獲得的陣列轉化為節點並存在連結串列中
* @param arrays
* @return
*/
public LinkedList<Node<String>> createNodeList(int[] arrays)
{
LinkedList<Node<String>> list = new LinkedList<>();
for(int i=0;i<arrays.length;i++)
{
if(arrays[i]!=0)
{
String ch = (char)i+"";
Node<String> node = new Node<String>(ch,arrays[i]); //構建節點並傳入字元和權值
list.add(node); //新增節點
}
}
return list;
}
/**
* 對連結串列中的元素排序
* @param list
* @return
*/
public void sortList(LinkedList<Node<String>> list)
{
for(int i=list.size();i>1;i--)
{
for(int j=0; j<i-1;j++)
{
Node<String> node1 = list.get(j);
Node<String> node2 = list.get(j+1);
if(node1.getWeight()>node2.getWeight())
{
int temp ;
temp = node2.getWeight();
node2.setWeight(node1.getWeight());
node1.setWeight(temp);
String tempChar;
tempChar = node2.getData();
node2.setData(node1.getData());
node1.setData(tempChar);
Node<String> tempNode = new Node<String>(null, 0);
tempNode.setLeft(node2.getLeft());
tempNode.setRight(node2.getRight());
node2.setLeft(node1.getLeft());
node2.setRight(node1.getRight());
node1.setLeft(tempNode.getLeft());
node1.setRight(tempNode.getRight());
}
}
}
}
/**
* 建樹的方法
* @param list
*/
public Node<String> CreateHFMTree(LinkedList<Node<String>> list)
{
while(list.size()>1)
{
sortList(list); //排序節點連結串列
Node<String> nodeLeft = list.removeFirst();
Node<String> nodeRight = list.removeFirst();
Node<String> nodeParent = new Node<String>( null ,nodeLeft.getWeight()+nodeRight.getWeight());
nodeParent.setLeft(nodeLeft);
nodeParent.setRight(nodeRight);
list.addFirst(nodeParent);
}
System.out.println("根節點的權重:"+list.get(0).getWeight());
return list.get(0);//返回根節點
}
public HashMap<String, String> getAllCode(Node<String> root)
{
HashMap<String, String> map = new HashMap<>();
inOrderGetCode("", map, root);
return map;
}
/**
* 查詢指定字元的哈夫曼編碼(中序遍歷)
* @param code
* @param st
* @param root
* @return
*/
public void inOrderGetCode(String code ,HashMap<String, String> map,Node<String> root)
{
if(root!=null)
{
inOrderGetCode(code+"0",map,root.getLeft());
if(root.getLeft()==null&&root.getRight()==null)//儲存葉子結點的哈夫曼編碼
{
System.out.println(root.getData());
System.out.println(code);
map.put(root.getData(), code);
}
inOrderGetCode(code+"1",map,root.getRight());
}
}
/**
* 中序遍歷輸出整棵樹
* @param root
* @return
*/
public void inOrder(Node<String> root)
{
if(root!=null)
{
inOrder(root.getLeft());
if(root.getData()!=null)
System.out.println(root.getData());
inOrder(root.getRight());
}
}
}
3、檔案操作類(包括檔案壓縮對外的介面和檔案解壓對外的介面):
public class FileOperation {
FileOutputStream fos;//申明檔案輸出流物件
FileInputStream fis; //申明檔案寫入流物件
/**
* 通過檔案獲取陣列的方法
* @param str
*/
public int[] getArrays(File file)
{
int[] arrays = new int[256];
try{
FileInputStream fis = new FileInputStream(file);
int ascii=0;
while((ascii=fis.read())!=-1)
{
arrays[ascii]++;
}
fis.close();
}catch(IOException e){
e.printStackTrace();
}
return arrays;
}
/**
* 讀取檔案獲取01碼
*/
public String GetStr(HashMap map,File file)
{
String str=""; //定義字串儲存01碼
try{
FileInputStream fis = new FileInputStream(file);
int value=0;
while((value=fis.read())!=-1)
{
str+=map.get((char)value+""); //取單字元對應的01碼,累加到字串中
}
fis.close();
}catch(IOException e)
{
e.printStackTrace();
}
return str;
}
/**
* 寫HashMap到檔案(寫入編碼個數+第一個key+第一個value所佔位元組數+value最後一個位元組的補0情況+第一個value的若干位元組+下一個key+。。。。)
*/
public void writeHashMap(HashMap<String, String> map ,File file)
{
int size = map.size(); //獲取編碼的個數,即HashMap中的鍵值對個數
String temp=""; //存放臨時8位01字串
int value=0; //存放01字串轉化得到的ASCII值
try{
fos = new FileOutputStream(file);
fos.write(size); //寫HashMap長度
Set<String> keySet = map.keySet(); //獲取HashMap存放key的容器
java.util.Iterator<String> it = keySet.iterator();//通過容器獲取迭代器
while(it.hasNext()) //迭代判斷,有下一個key
{
String key = it.next(); //取出下一個key
String code = map.get(key); //取出code
fos.write(key.charAt(0)); //寫key值
int a = code.length()/8;//能存滿的位元組數
int b = code.length()%8;//剩餘的位數
int c =1; //值對應的儲存的位元組數
if(b==0) //無剩餘位
{
c=a;
fos.write(c); //寫code的位元組數
fos.write(0); //寫補0數,為0個
for(int i=0;i<a;i++) //寫code值
{
temp="";
for(int j=0;j<8;j++)
{
temp+=code.charAt(i*8+j);
}
value=StringToInt(temp);
fos.write(value); //逐一把code的每一位寫出去
}
}
else
{
c=a+1;
fos.write(c); //寫code的位元組數
fos.write(8-b); //寫補0數
for(int i=0;i<8-b;i++) //補0
{
code+="0";
}
for(int i=0;i<c;i++)
{
temp="";
for(int j=0;j<8;j++)
{
temp+=code.charAt(8*i+j);
}
value=StringToInt(temp);
fos.write(value); //逐一寫code,包括補的0
}
}
}
}catch(IOException e){
e.printStackTrace();
}
}
/**
* 把文件轉化為的HFM編碼寫入檔案
*/
public void writeHFMcode(String HFMcode)
{
int len = HFMcode.length(); //獲取HFMcode長度
int a = len/8; //求出完整的位元組的數目
int b = len%8; //求出剩餘的位數
String temp = ""; //臨時存放8位資料
int value = 0; //存放8位01轉化得到的值
try
{
if(b==0) //無不足八位的部分,不需要補0
{
fos.write(0); //寫補0數
for(int i=0;i<a;i++)
{
temp="";
for(int j=0;j<8;j++)
{
temp+=HFMcode.charAt(i*8+j);
}
value=StringToInt(temp);
fos.write(value); //寫HFMcode
}
}
else //需要補0
{
int c = 8-b; //計算補0數
fos.write(c); //寫補0數
for(int i=0;i<c;i++) //補0
{
HFMcode+="0";
}
for(int i=0;i<a+1;i++)
{
temp="";
for(int j=0;j<8;j++)
{
temp+=HFMcode.charAt(i*8+j);
}
value=StringToInt(temp);
fos.write(value); //寫HFMcode
}
}
fos.close(); //寫完關閉資源
}
catch(IOException e)
{
e.printStackTrace();
}
}
/**
* 把01字串轉化為ASCII碼
* @param temp
* @return
*/
public int StringToInt(String temp)
{
int value=0;
for(int i=0;i<8;i++)
{
int x = temp.charAt(i)-48;
if(x==1) //為1則累加入value
{
value+=Math.pow(2,7-i); //表示2的(7-i)次方
}
}
return value;
}
/**
* 把數值轉化為01字串
* @param value
*/
public String IntToString(int value)
{
String temp1=""; //存放反的字串
String temp=""; //存放正的字串
while(value>0) //逐漸取出各個二進位制位數,字串為反向的
{
temp1+=value%2;
value=value/2;
}
for(int i=temp1.length()-1;i>=0;i--)
{
temp+=temp1.charAt(i);
}
return temp;
}
/**
* 把數值轉化為01字串,數值範圍在0~255,01串不超過8位
* @param value
*/
public String IntToStringEight(int value)
{
String temp1=""; //存放反的字串
String temp=""; //存放正的字串
int add=0;
while(value>0) //逐漸取出各個二進位制位數,字串為反向的
{
add++;
temp1+=value%2;
value=value/2;
}
add=8-add;
for(int i=0;i<add;i++)//添0至8位
{
temp1+="0";
}
for(int i=temp1.length()-1;i>=0;i--) //反向的字串獲取正向的字串
{
temp+=temp1.charAt(i);
}
return temp;
}
/**
* 對外部的介面,實現把壓縮後的資料和資訊寫入壓縮檔案
* @param fileCompress
*/
public void compressFile(File fileCompress,HashMap<String, String> map,String HFMcode)
{
writeHashMap(map, fileCompress); //寫HashMap的資料
writeHFMcode(HFMcode); //繼續寫HFMcode 01字串
}
/**
* 解壓獲取HashMap
* @param fileCompress
*/
public HashMap<String, String> readHashMap(File fileCompress)
{
HashMap<String, String> mapGet = new HashMap<>();
try
{
fis=new FileInputStream(fileCompress);
int keyNumber = fis.read(); //讀取key的數量
String key = ""; //HashMap的鍵值對
String code= ""; //未去0的字串
String codeRZ="";//去0的字串
int length=0; //表示還原後的字串的理論長度,解決字串前面的0的問題
int byteNum=1; //當前code佔了幾個位元組
int addZero=0; //補0數
int value=0; //臨時儲值
int zeroLength=0;//code沒有1的時候的字串長度
for(int i=0;i<keyNumber;i++)
{
key = (char)fis.read()+""; //獲取key值
byteNum=fis.read(); //獲取code的位元組數
addZero=fis.read(); //讀取補0數量
if(addZero==0) //沒有補0,是整位元組數
{
for(int k=byteNum-1;k>=0;k--)
{
value+=fis.read()*(Math.pow(2, k*8));
}
code=IntToString(value);//把數值轉為01code
value=0;//清零
length=8*byteNum-code.length();//計算在前面要補多少0
if(code.length()==0) //若code內數字都為0,只要去掉尾部即可
{
zeroLength=length-addZero; //計算有多少個0
for(int k=0;k<zeroLength;k++)
{
codeRZ+="0";
}
}
else //code值不為0,補充前面的0,去掉後面的0
{
for(int k=0;k<length;k++)
{
codeRZ+="0";
}
for(int k=0;k<code.length()-addZero;k++)
{
codeRZ+=code.charAt(k);
}
}
}
else //有補0
{
for(int k=byteNum-1;k>=0;k--)
{
value+=fis.read()*(Math.pow(2, k*8));
}
code=IntToString(value);//把數值轉為01code
value=0;//清0
length=8*byteNum-code.length();//計算在前面要補多少0
if(code.length()==0) //若code內數字都為0,只要去掉尾部即可
{
zeroLength=length-addZero; //計算有多少個0
for(int k=0;k<zeroLength;k++)
{
codeRZ+="0";
}
}
else //code值不為0,補充前面的0,去掉後面的0
{
for(int k=0;k<length;k++)
{
codeRZ+="0";
}
for(int k=0;k<code.length()-addZero;k++) //不要後面的0
{
codeRZ+=code.charAt(k);
}
}
}
mapGet.put(codeRZ , key ); //把讀取到的鍵值對存入建立的HashMap
codeRZ=""; //清空
}
}
catch(IOException e)
{
e.printStackTrace();
}
return mapGet;
}
/**
* 獲取壓縮檔案中的資料,還原哈夫曼編碼01串
*/
public String readHFMStr()
{
String str1=""; //存放獲取到的直接的01字串
String str=""; //存放去掉補0的字串
int value=0;
String temp="";
try{
int addZero = fis.read(); //讀取整個檔案的補0個數
while((value=fis.read())!=-1)
{
temp=IntToStringEight(value); //把每個位元組的資料轉化為八位的01
str1+=temp;
}
if(addZero!=0) //有補0,獲取補0前的字串
{
for(int i=0;i<str1.length()-addZero;i++) //補0的部分不賦值
str+=str1.charAt(i)+"";
return str;
}
fis.close();
}
catch(IOException e)
{
e.printStackTrace();
}
return str1;
}
/**
* 寫入檔案的儲存路徑(寫檔案)
* @param str
* @param mapGet
* @param fileCompress
*/
public void writeFile(String str , HashMap<String, String> mapGet,File fileCompress)
{
try
{
fos = new FileOutputStream(fileCompress); //獲取檔案輸出流
int len = str.length();//獲取01串的長度
String temp=""; //臨時存放段的01字串
for(int i=0;i<len;i++)
{
temp+=str.charAt(i);
if(mapGet.containsKey(temp))
{
fos.write(mapGet.get(temp).charAt(0)); //一個字元的字串轉字元然後寫出
temp="";
}
}
fos.close();
}
catch(IOException e)
{
e.printStackTrace();
}
}
/**
* 對外部的介面,實現解壓檔案,獲取HashMap和檔案內容
* @param fileCompress,壓縮檔案目錄
* @param fileUncompress,解壓到的目錄
*/
public void uncompressFile(File fileCompress,File fileUncompress)
{
HashMap<String, String> mapGet = readHashMap(fileCompress); //獲取雜湊表
String str = readHFMStr(); //獲取01字串
writeFile(str,mapGet,fileUncompress); //寫檔案到儲存路徑
}
}
壓縮、解壓效果
1、壓縮檔案所佔記憶體小於原檔案,解壓後的檔案和原檔案大小相同。如圖data1是原檔案,data2是壓縮檔案,data3的解壓後的檔案。我們可以發現壓縮後的壓縮包所佔記憶體3KB<5KB。

2、原檔案和解壓後的檔案的內容展示:
data1.txt:

data3.txt:

解壓後txt的資訊和原檔案完全一致。