
MySQL中的關鍵字用法(一)
MySQL中關鍵字的用法(一)
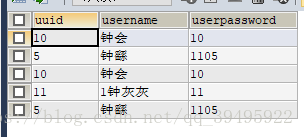
Insert:增加 insert into * values() insert into user values(‘11’,‘諸葛亮’,‘1011’); 不多解釋,向表中新增一條語句,不清楚的去看MySQL的簡單的增刪改查
Delete:刪除 delete from * where a=b; delete from user where uuid=10 不多解釋,在表中刪除一條語句,不清楚的去看MySQL的簡單的增刪改查
Update:更新
update * set a=b where a=b;
update user a set a.username
uuid=6;
不多解釋,在表中更新一條語句,不清楚的去看MySQL的簡單的增刪改查
Select:查詢 select * from a where a=b; select * from user where uuid=1; 不多解釋,在表中查詢語句,不清楚的去看MySQL的簡單的增刪改查
Where:成立條件 涉及到資料庫的帶有條件的操作,基本都要有where關鍵字,一般用於資料庫的刪除和更新命令,具體用法便是“where 判斷條件”;
查詢語句中你可以使用一個或者多個表,表之間使用逗號, 分割,並使用WHERE語句來設定查詢條件。 你可以在 WHERE 子句中指定任何條件。 你可以使用 AND 或者 OR 指定一個或多個條件。 WHERE 子句也可以運用於 SQL 的 DELETE 或者 UPDATE 命令。 WHERE 子句類似於程式語言中的 if 條件,根據 MySQL 表中的欄位值來讀取指定的資料。
where a=b;
where a.uid=b.oid and a.uid=‘1011’;
where a.uid=‘1’ or b.oid=‘1’;
Like:模糊查詢
我們知道查詢資料庫的時候用select關鍵字,我們也知道查詢的條件跟在where關鍵字後面就可以,但是如果我們現在的查詢條件比較模糊,我們想查詢字尾是"mp4"的資料或者是想查詢資料中含有“大大”的字眼的資料;這個時候準確查詢就無法滿足了,就需要用到模糊查詢like關鍵字了;
*SQL LIKE 子句中使用百分號 %字元來表示任意字元,類似於UNIX或正則表示式中的星號 。
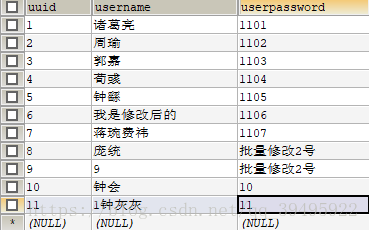
select * from user a where a.username like '鍾%'
執行前

union:聯合,合併 當多個查詢語句一起執行時,把這些查詢的資料組合到一起時會出現重複的資料,這個時候就需要這個union關鍵字來進行聯合查詢;union關鍵字就是用於連線兩個以上的 SELECT 語句的結果組合到一個結果集合中,多個 SELECT 語句會刪除重複的資料;
union是用來聯合多條語句的,如果現在有一張使用者表,每個客戶都有買東西,這個時候要查出買了多少種類的東西,這個時候要單獨用distinct關鍵字了,即
select count(distinct a.goods) from user a ;
原表:
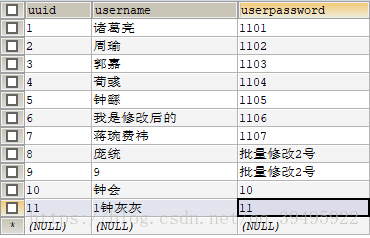
username like ‘鍾%’
union (distinct)
select * from user a where a.username like ‘%鍾%’;
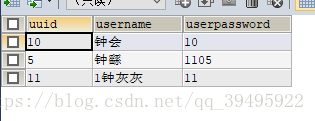
預設的union會去掉sql語句的相同的結果;union all會全部顯示;distinct與不寫結果相同;
union/union distinct 查詢後的結果是
distinct:不重複的 上滿說到了union預設是和union distinct的作用一樣,會將多個select查詢語句的結果集進行合併;如果現在只有一個select語句,比如現在要統計一張商品表的商品的種類的個數,這個時候就要查詢出種類這個欄位不重複的記錄,並計算;這個時候就要用distinct這個關鍵字了; select count(distinct goods.class) from goods;
order by desc/asc :排序 將要顯示的結果集進行排序,用order by關鍵字,末尾跟desc則是降序、跟asc則是升序;預設情況下是升序; SELECT * FROM USER WHERE id>8891 ORDER BY id DESC;
Order by是排序;desc降序;asc升序; SELECT field1, field2,…fieldN table_name1, table_name2… ORDER BY field1, [field2…] [ASC [DESC]
你可以使用任何欄位來作為排序的條件,從而返回排序後的查詢結果。 你可以設定多個欄位來排序。 你可以使用 ASC 或 DESC 關鍵字來設定查詢結果是按升序或降序排列。 預設情況下,它是按升序排列。 你可以新增 WHERE…LIKE 子句來設定條件。
group by:分組 group by關鍵字用來分組,根據一個或多個列對結果集進行分組
(count(*)計算個數的函式包含null值,count(屬性)不包括null的值, sum(屬性)求和的函式 max(屬性)用來求當前列的最大值)
我要只說這是用來分組的,可能有些模糊,可能很多人還是壓根不懂這個到底是用來幹啥的;好,那麼我就按照我的理解來給大家詳細的解釋下這個分組group by到底該怎麼用。
假如現在有這麼一個人類表,我要將這個表按照男女來分開,計算一下男生多少人,女生多少人,以表格的形式顯示出來?
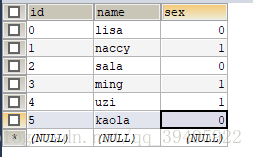
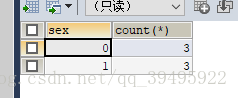
現在有這麼一個需求,我有一個客戶表,客戶分為三個等級,需要按照客戶來分類,並計算每個等級的客戶的總消費量,以表格形式呈現出來;有了前面這個例子,這個便很好來實現了,只需要把函式count(*)改成函式sum(xiaofei) 便可以了;
group by x的意思就是把所有具有相同x欄位的資料放在一起,比如上面的性別或者上面的客戶等級,按照這個分好; 那麼group by x,y的意思呢?很明顯啊,就是把所有具有x和y兩個欄位都相同的資料放在一起;
像上面兩個例子,如果我想不僅把客戶按照等級來分好,而且每個等級的按照男女來分好,並計算每個等級的男女的消費總額;這個需求該如何實現呢?這個問題便用到了上面的多條件分組; select people.level,people.sex,count(*),sum(xiaofei) from people group by level,sex; 即將具有相同的客戶等級和客戶性別的放到一組,並進行聚合函式(sum.count.avg.max);
總結:寫了一些關鍵字的用法,關鍵字的用法很重要,熟練掌握;

/************************************************************************* /*************************************************************************