
zookeeper架構設計與基本實現機制
Zookeeper作為一個分散式協調系統提供了一項基本服務:分散式鎖服務,分散式鎖是分散式協調技術實現的核心內容。像配置管理、任務分發、組服務、分散式訊息佇列、分散式通知/協調等,這些應用實際上都是基於這項基礎服務由使用者自己摸索出來的。
1.Zookeeper在大資料系統中的常見應用
zookeeper作為分散式協調系統在大資料領域非常常用,它是一個很好的中心化管理工具。下面舉幾個常見的應用場景。
1.1.HDFS/YARN
HA(分散式鎖的應用):Master掛掉之後迅速切換到slave節點。
1.2.hbase
- HA :同上。
- 配置管理 :client需要讀寫hbase的資料首先都是連到ZK讀取root表,獲得meta表所在的region,最後找到資料所在位置。
任務釋出:regionserver掛了一臺,master需要重新分配region,會把任務放在zookeeper等regionserver來獲取
1.3.kafka
- 配置管理:broker會在zookeeper註冊並保持相關的元資料(topic,partition資訊等)更新
任務分配:給topic分配partitions和replication
2.Zookeeper有哪些操作特性
2.1.資料結構
ZooKeeper名稱空間中的Znode,兼具檔案和目錄兩種特點。既像檔案一樣維護著資料、元資訊、ACL、時間戳等資料結構,又像目錄一樣可以作為路徑標識的一部分。 每個Znode由3部分組成:
- stat狀態資訊:描述該Znode的版本, 許可權等資訊
- data:與該Znode關聯的資料(配置檔案資訊、狀態資訊、彙集位置),資料大小至多1M
- children:該Znode下的子節點
ZooKeeper中的每個節點儲存的資料要被原子性的操作。也就是說讀操作將獲取與節點相關的所有資料,寫操作也將替換掉節點的所有資料。另外,每一個節點都擁有自己的ACL(訪問控制列表),這個列表規定了使用者的許可權,即限定了特定使用者對目標節點可以執行的操作。
2.2.watch機制
ZooKeeper可以為所有的讀操作設定watch,包括:exists()、getChildren()及getData()
- 資料watch(data watches):getData和exists負責設定資料watch
孩子watch(child watches):getChildren負責設定孩子watch
2.3.節點型別
ZooKeeper中的節點有兩種,分別為臨時節點和永久節點(還可再分為有序無序)。節點的型別在建立時即被確定,並且不能改變。- 臨時節點:該節點的生命週期依賴於建立它們的會話。一旦會話(Session)結束,臨時節點將被自動刪除,當然可以也可以手動刪除。雖然每個臨時的Znode都會繫結到一個客戶端會話,但他們對所有的客戶端還是可見的。另外,ZooKeeper的臨時節點不允許擁有子節點。(分散式佇列)
永久節點:該節點的生命週期不依賴於會話,並且只有在客戶端顯示執行刪除操作的時候,他們才能被刪除。
3.這些應用是如何通過這些特性實現的
3.1.HA:
兩種方式:
- 建立兩個或多個有序臨時節點,永遠把最小值當做master
- 建立臨時節點的為master,多個slave會watch這個節點
3.2.配置管理:
儲存叢集元資料提供給client使用,體現在比如需要對HBase和Kafka操作時,都會直接連到zookeeper,zookeeper記錄了資料儲存的位置,存活的節點等元資料資訊。
3.3.任務釋出:
Master要監視/works和/tasks兩個永久節點,以便能感知到由哪些slave當前可用,當前有新任務需要分配。 分配過程:在/assign下建立當前可用的workA,找到需要分配的taskA,建立/assign/workA/taskA
4.zookeeper架構設計

zookeeper作為一個分散式協調系統,很多元件都會依賴它,那麼此時它的可用性就非常重要了,那麼保證可用性的同時作為分散式系統的它是怎麼保證擴充套件性的?問題很多,讀完接下來的內容你會有答案。
上圖來自zookeeper的官方文件,我解釋下這張圖的各個角色(observer在上圖中可以理解為特殊的follower)
| 角色 | 分工 | 數量 |
|---|---|---|
| client客戶端 | 請求發起方 | 不限 |
| observer觀察者 | 接受使用者讀寫請求,寫轉發給leader,讀直接返回(選主過程不參加投票) | 不限 |
| follower跟隨者 | 接受使用者讀寫請求,寫轉發給leader,讀直接返回(選主過程參加投票) | 奇數個(不可過多) |
| leader領導者 | 負責提議,更新系統狀態 | 1個 |
另外:follower和observer同時均為learner(學習者)角色,learner的分工是同步leader的狀態。
5.zookeeper的讀寫
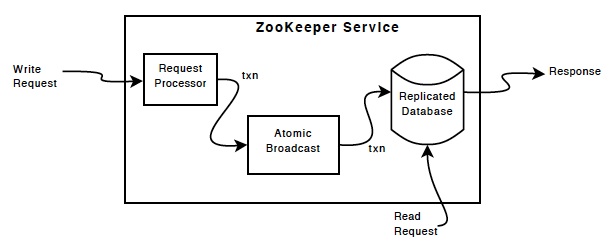 zookeeper的各個複製集節點(follower,leader,observer)都包含了叢集所有的資料且存在記憶體中,像個記憶體資料庫。更新操作會以日誌的形式記錄到磁碟以保證可恢復性,並且寫入操作會在寫入記憶體資料庫之前序列化到磁碟。
zookeeper的各個複製集節點(follower,leader,observer)都包含了叢集所有的資料且存在記憶體中,像個記憶體資料庫。更新操作會以日誌的形式記錄到磁碟以保證可恢復性,並且寫入操作會在寫入記憶體資料庫之前序列化到磁碟。
每個ZooKeeper伺服器都為客戶端服務。客戶端只連線到一臺伺服器以提交請求。讀取請求由每個伺服器資料庫的本地副本提供服務。更改服務狀態,寫請求的請求由zab協議處理。
作為協議協議的一部分,來自客戶端的所有寫入請求都被轉發到稱為leader的單個伺服器。其餘的ZooKeeper伺服器(稱為followers)接收來自領導者leader的訊息提議並同意訊息傳遞。訊息傳遞層負責替換失敗的leader並將followers與leader同步。
ZooKeeper使用自定義原子訊息傳遞協議zab。由於訊息傳遞層是原子的,當領導者收到寫入請求時,它會計算應用寫入時系統的狀態,並將其轉換為捕獲此新狀態的事務。
6.zookeeper的CAP原則
cap原則是指作為一個分散式系統,一致性,可用性,分割槽容錯性這三個方面,最多隻能任意選擇兩種。就是必定會要有取捨。
- 一致性C
Zookeeper是強一致性系統,同步資料很快。但是在不用sync()操作的前提下無法保證各節點的資料完全一致。zookeeper為了保證一致性使用了基於paxos協議且為zookeeper量身定做的zab協議。這兩個協議是什麼東西之後的文章會講。
- 可用性A(高可用性和響應能力)
Zookeeper資料儲存在記憶體中,且各個節點都可以相應讀請求,具有好的響應效能。Zookeeper保證了可用性,資料總是可用的,沒有鎖.並且有一大半的節點所擁有的資料是最新的,實時的。
- 分割槽容忍性P
有2點需要分析的
- 節點多了會導致寫資料延時非常大(需要半數以上follower寫完提交),因為需要多個節點同步.
- 節點多了Leader選舉非常耗時, 就會放大網路的問題. 可以通過引入 observer節點緩解這個問題.
zk在CAP問題上做的取捨
嚴格地意義來講zk把取捨這個問題拋給了開發者即使用者。
為了協調CA(一致性和可用性),使用者可以自己選擇是否使用Sync()操作。使用則保證所有節點強一致,但是這個操作同步資料會有一定的延遲時間。反過來若不是必須保證強一致性的場景,可不使用sync,雖然zookeeper同步的資料很快,但是此時是沒有辦法保證各個節點的資料一定是一致的,這一點使用者要注意。實際的開發中就要開發者根據實際場景來做取捨了,看更關注一致性還是可用性。
為了協調AP(一致性和擴充套件性),使用者可以自己選擇是否新增obsever以及添加個數,observer是3.3.0 以後版本新增角色,它不會參加選舉和投票過程,目的就是提高叢集擴充套件性。因為follower的數量不能過多,follower需要參加選舉和投票,過多的話選舉的收斂速度會非常慢,寫資料時的投票過程也會很久。observer的增加可以提高可用性和擴充套件性,叢集可接受client請求的點多了,可用性自然會提高,但是一致性的問題依然存在,這時又回到了上面CA的取捨問題上。
7.zookeeper的選主機制
FastLeaderElection原理
- myid
每個Zookeeper伺服器,都需要在資料資料夾下建立一個名為myid的檔案,該檔案包含整個Zookeeper叢集唯一的ID(整數)。例如某Zookeeper叢集包含三臺伺服器,hostname分別為zoo1、zoo2和zoo3,其myid分別為1、2和3,則在配置檔案中其ID與hostname必須一一對應,如下所示。在該配置檔案中,server.後面的資料即為myid
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888- zxid
類似於RDBMS中的事務ID,用於標識一次更新操作的Proposal ID。為了保證順序性,該zkid必須單調遞增。因此Zookeeper使用一個64位的數來表示,高32位是Leader的epoch,從1開始,每次選出新的Leader,epoch加一。低32位為該epoch內的序號,每次epoch變化,都將低32位的序號重置。這樣保證了zkid的全域性遞增性。
7.1.支援的領導選舉演算法
可通過electionAlg配置項設定Zookeeper用於領導選舉的演算法。 到3.4.10版本為止,可選項有
0 基於UDP的LeaderElection
1 基於UDP的FastLeaderElection
2 基於UDP和認證的FastLeaderElection
3 基於TCP的FastLeaderElection在3.4.10版本中,預設值為3,也即基於TCP的FastLeaderElection。另外三種演算法已經被棄用,並且有計劃在之後的版本中將它們徹底刪除而不再支援。
7.2.FastLeaderElection
FastLeaderElection選舉演算法是標準的Fast Paxos演算法實現,可解決LeaderElection選舉演算法收斂速度慢的問題。 伺服器狀態
- LOOKING 不確定Leader狀態。該狀態下的伺服器認為當前叢集中沒有Leader,會發起Leader選舉
- FOLLOWING 跟隨者狀態。表明當前伺服器角色是Follower,並且它知道Leader是誰
- LEADING 領導者狀態。表明當前伺服器角色是Leader,它會維護與Follower間的心跳
OBSERVING 觀察者狀態。表明當前伺服器角色是Observer,與Folower唯一的不同在於不參與選舉,也不參與叢集寫操作時的投票
7.2.選票資料結構
每個伺服器在進行領導選舉時,會發送如下關鍵資訊- logicClock 每個伺服器會維護一個自增的整數,名為logicClock,它表示這是該伺服器發起的第多少輪投票
- state 當前伺服器的狀態
- self_id 當前伺服器的myid
- self_zxid 當前伺服器上所儲存的資料的最大zxid
- vote_id 被推舉的伺服器的myid
vote_zxid 被推舉的伺服器上所儲存的資料的最大zxid
7.2.投票流程
自增選舉輪次
Zookeeper規定所有有效的投票都必須在同一輪次中。每個伺服器在開始新一輪投票時,會先對自己維護的logicClock進行自增操作。
- 初始化選票
每個伺服器在廣播自己的選票前,會將自己的投票箱清空。該投票箱記錄了所收到的選票。例:伺服器2投票給伺服器3,伺服器3投票給伺服器1,則伺服器1的投票箱為(2, 3), (3, 1), (1, 1)。票箱中只會記錄每一投票者的最後一票,如投票者更新自己的選票,則其它伺服器收到該新選票後會在自己票箱中更新該伺服器的選票。
- 傳送初始化選票
每個伺服器最開始都是通過廣播把票投給自己。
- 接收外部投票
伺服器會嘗試從其它伺服器獲取投票,並記入自己的投票箱內。如果無法獲取任何外部投票,則會確認自己是否與叢集中其它伺服器保持著有效連線。如果是,則再次傳送自己的投票;如果否,則馬上與之建立連線。
- 判斷選舉輪次
收到外部投票後,首先會根據投票資訊中所包含的logicClock來進行不同處理 外部投票的logicClock大於自己的logicClock。說明該伺服器的選舉輪次落後於其它伺服器的選舉輪次,立即清空自己的投票箱並將自己的logicClock更新為收到的logicClock,然後再對比自己之前的投票與收到的投票以確定是否需要變更自己的投票,最終再次將自己的投票廣播出去。 外部投票的logicClock小於自己的logicClock。當前伺服器直接忽略該投票,繼續處理下一個投票。 外部投票的logickClock與自己的相等。當時進行選票PK。
- 選票PK
選票PK是基於(self_id, self_zxid)與(vote_id, vote_zxid)的對比 外部投票的logicClock大於自己的logicClock,則將自己的logicClock及自己的選票的logicClock變更為收到的logicClock 若logicClock一致,則對比二者的vote_zxid,若外部投票的vote_zxid比較大,則將自己的票中的vote_zxid與vote_myid更新為收到的票中的vote_zxid與vote_myid並廣播出去,另外將收到的票及自己更新後的票放入自己的票箱。如果票箱內已存在(self_myid, self_zxid)相同的選票,則直接覆蓋 若二者vote_zxid一致,則比較二者的vote_myid,若外部投票的vote_myid比較大,則將自己的票中的vote_myid更新為收到的票中的vote_myid並廣播出去,另外將收到的票及自己更新後的票放入自己的票箱
- 統計選票
如果已經確定有過半伺服器認可了自己的投票(可能是更新後的投票),則終止投票。否則繼續接收其它伺服器的投票。
- 更新伺服器狀態
投票終止後,伺服器開始更新自身狀態。若過半的票投給了自己,則將自己的伺服器狀態更新為LEADING,否則將自己的狀態更新為FOLLOWING
《每日五分鐘搞定大資料》原創系列,每週不定時更新。評論不能及時回覆可直接加公眾號提問或交流,知無不答,謝謝 。
