
馬蜂窩大交通業務監控報警系統架構設計與實現
部門的業務線越來越多,任何一個線上執行的應用,都可能因為各種各樣的原因出現問題:比如業務層面,訂單量比上週減少了,流量突然下降了;技術層面的問題,系統出現 ERROR ,介面響應變慢了。拿大交通業務來說,一個明顯的特點是依賴很多供應商的服務,所以我們還需要關注呼叫供應商介面是否出現異常等等。
為了讓大交通下的各業務線都能夠通過報警儘早發現問題、解決問題,進而提升業務系統的服務質量,我們決定構建統一的監控報警系統。一方面在第一時間發現已經出現的系統異常,及時解決;另一方面儘早發現一些潛在的問題,比如某個系統目前來看沒有影響業務邏輯的正常運轉,但是一些操作耗時已經比較長等,這類問題如果不及時處理,將來就很可能影響業務的發展。
本文主要介紹馬蜂窩大交通業務監控報警系統的定位、整體架構設計,以及我們在落地實踐過程中的一些踩坑經驗。
架構設計與實現
我們希望監控報警系統主要具備以下三個能力:
1. 常用元件自動報警:對於各業務系統常用的框架元件(如 RPC ,HTTP 等)建立預設報警規則,來方便框架層面的統一監控。
2. 業務自定義報警:業務指標由業務開發自定義埋點欄位,來記錄每個業務和系統模組的特殊執行狀況。
3. 快速定位問題:發現問題並不是目的,解決才是關鍵。我們希望在完成報警訊息傳送後,可以讓開發者一目瞭然地發現問題出現在什麼地方,從而快速解決。
在這樣的前提下,報警中心的整體架構圖和關鍵流程如下圖所示:
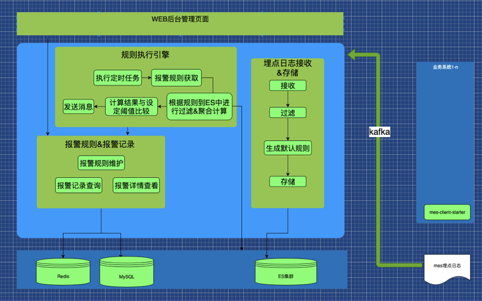
縱向來看,Kafka 左側是報警中心,右側是業務系統。
報警中心的架構共分為三層,最上層是 WEB 後臺管理頁面,主要完成報警規則的維護和報警記錄的查詢;中間層是報警中心的核心;最下面一層是資料層。業務系統通過一個叫做 mes-client-starter 的 jar 包完成報警中心的接入。
我們可以將報警中心的工作劃分為五個模組:

1. 資料收集
我們採用指標採集上報的方式來發現系統問題,就是將系統執行過程中我們關注的一些指標進行記錄和上傳。上傳的方式可以是日誌、 UDP 等等。
首先資料收集模組我們沒有重複造輪子,可是直接基於 MES (馬蜂窩內部的大資料分析工具)來實現,主要考慮下面幾個方面的原因:一來資料分析和報警在資料來源上是相似的;二來可以節省很多開發成本;同時也方便報警的接入。
那具體應該採集哪些指標呢?以大交通業務場景下使用者的一次下單請求為例,整個鏈路可能包括 HTTP 請求、Dubbo 呼叫、SQL 操作,中間可能還包括校驗、轉換、賦值等環節。一整套呼叫下來,會涉及到很多類和方法,我們不可能對每個類、每個方法呼叫都做採集,既耗時也沒有意義。
為了以最小的成本來儘可能多地發現問題,我們選取了一些系統常用的框架元件自動打點,比如 HTTP、SQL、我們使用的 RPC 框架 Dubbo ,實現框架層面的統一監控。
而對於業務來說,每個業務系統關注的指標都不一樣。對於不同業務開發人員需要關注的不同指標,比如支付成功訂單數量等,開發人員可以通過系統提供的 API 進行手動埋點,自己定義不同業務和系統模組需要關注的指標。
2. 資料儲存
對於採集上來的動態指標資料,我們選擇使用 Elasticsearch 來儲存,主要基於兩點原因:
一是動態欄位儲存。每個業務系統關注的指標可能都不一樣,每個中介軟體的關注點也不同,所以埋哪些欄位、每個欄位的型別都無法預知,這就需要一個可以動態新增欄位的資料庫來儲存埋點。Elasticsearch 不需要預先定義欄位和型別,埋點資料插入的時候可以自動新增。
二是能夠經得起海量資料的考驗。每個使用者請求進過每個監控元件都會產生多條埋點,這個資料量是非常龐大的。Elasticsearch 可以支援大資料量的儲存,具有良好的水平擴充套件性。
此外,Elasticsearch 還支援聚合計算,方便快速執行 count , sum , avg 等任務。
3. 報警規則
有了埋點資料,下一步就需要定義一套報警規則,把我們關注的問題量化為具體的資料來進行檢查,驗證是否超出了預設的閾值。這是整個報警中心最複雜的問題,也最為核心。
之前的整體架構圖中,最核心的部分就是「規則執行引擎」,它通過執行定時任務來驅動系統的執行。首先,執行引擎會去查詢所有生效的規則,然後根據規則的描述到 Elasticsearch 中進行過濾和聚合計算,最後將上一步聚合計算得結果跟規則中預先設定的閾值做比較,如果滿足條件則傳送報警訊息。
這個過程涉及到了幾個關鍵的技術點:
1). 定時任務
為了保證系統的可用性,避免由於單點故障導致整個監控報警系統失效,我們以「分鐘」為週期,設定每一分鐘執行一次報警規則。這裡用的是 Elastic Job 來進行分散式任務排程,方便操控任務的啟動和停止。
2). 「三段式」報警規則
我們將報警規則的實現定義為「過濾、聚合、比較」這三個階段。舉例來說,假設這是一個服務 A 的 ERROR 埋點日誌:
app_name=B is_error=false warn_msg=aa datetime=2019-04-01 11:12:00
app_name=A is_error=false datetime=2019-04-02 12:12:00
app_name=A is_error=true error_msg=bb datetime=2019-04-02 15:12:00
app_name=A is_error=true error_msg=bb datetime=2019-04-02 16:12:09

報警規則定義如下:
-
過濾:通過若干個條件限制來圈定一個數據集。對於上面的問題,過濾條件可能是:app_name=A , is_error=true , datetime between '2019-14-02 16:12:00' and '2019-14-02 16:13:00'.
-
聚合:通過 count,avg,sum,max 等預先定義的聚合型別對上一步的資料集進行計算,得到一個唯一的數值。對於上面的問題,我們選擇 count 來計算出現 ERROR 的次數。
-
比較:把上一步得到的結果與設定的閾值比較。
對於一些複雜條件的報警,比如我們上邊提到的失敗率和流量波動,應該如何實現呢?
假設有這樣一個問題:如果呼叫的 A 服務失敗率超過 80%,並且總請求量大於 100,傳送報警通知。
我們知道,失敗率其實就是失敗的數量除以總數量,而失敗的數量和總數量可以通過前面提到的「過濾+聚合」的方式得到,那麼其實這個問題就可以通過如下的公式描述出來:
failedCount/totalCount>0.8&&totalCount>100
然後我們使用表示式引擎 fast-el 對上面的表示式進行計算,得到的結果與設定的閾值比較即可。
3) 自動建立預設報警規則
對於常用的 Dubbo, HTTP 等,由於涉及的類和方法比較多,開發人員可以通過後臺管理介面維護報警規則,報警規則會儲存到 MySQL 資料庫中,同時在 Redis 中快取。
以 Dubbo 為例,首先通過 Dubbo 的 ApplicationModel 獲取所有的 provider 和 consumer,將這些類和方法的資訊與規則模板結合(規則模板可以理解為剔除掉具體類和方法資訊的規則),創建出針對某個類下某個方法的規則。
比如:A 服務對外提供的 dubbo 介面/ order / getOrderById 每分鐘平均響應時間超過 1 秒則報警;B 服務呼叫的 dubbo 介面/ train / grabTicket /每分鐘範圍 false 狀態個數超過 10 個則報警等等。
4. 報警行為
目前在報警規則觸發後主要採用兩種方式來發生報警行為:
-
郵件報警:通過對每一類報警制定不同的負責人,使相關人員第一時間獲悉系統異常。
-
微信報警:作為郵件報警的補充。
之後我們會持續完善報警行為的策略,比如針對不同等級的問題採用不同的報警方式,使開發人員既可以迅速發現報警的問題,又不過多牽扯在新功能研發上的精力。
5. 輔助定位
為了能夠快速幫助開發人員定位具問題,我們設計了命中抽樣的功能:
首先,我把命中規則的 tracer_id 提取出來,提供一個連結可以直接跳轉到 kibana 檢視相關日誌,實現鏈路的還原。
其次,開發人員也可以自己設定他要關注的欄位,然後我會把這個欄位對應的值也抽取出來,問題出在哪裡就可以一目瞭然地看到。
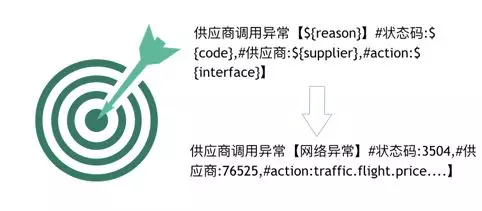
技術實現上,定義一個命中抽樣的欄位,這個欄位裡面允許使用者輸入一個或者多個 dollar 大括號。比如我們可能關注某個供應商的介面執行情況,則命中抽樣的欄位可能為下圖中上半部分。在需要傳送報警訊息的時候,提取出裡面的欄位,到 ES 中查詢對應的值,用 freemarker 來完成替換,最終傳送給開發人員的訊息是如下所示,開發人員可以快速知道系統哪裡出了問題。
踩坑經驗和演進方向
大交通業務監控報警系統的搭建是一個從 0 到 1 的過程,在整過開發過程中,我們遇到了很多問題,比如:記憶體瞬間被打滿、ES 越來越慢、頻繁 Full GC ,下面具體講一下針對以上幾點我們的優化經驗。
踩過的坑
1. 記憶體瞬間被打滿
任何一個系統,都有它能承受的極限,所以都需要這麼一座大壩,在洪水來的時候能夠攔截下來。

報警中心也一樣,報警中心對外面臨最大的瓶頸點在接收 Kafka 中傳過來的 MES 埋點日誌。上線初期出現過一次由於業務系統異常導致瞬間大量埋點日誌打到報警中心,導致系統記憶體打滿的問題。
解決辦法是評估每個節點的最大承受能力,做好系統保護。針對這個問題,我們採取的是限流的方式,由於 Kafka 消費訊息使用的是拉取的模式,所以只需要控制好拉取的速率即可,比如使用 Guava 的 RateLimiter :
messageHandler = (message) -> {
RateLimiter messageRateLimiter = RateLimiter.create(20000);
final double acquireTime = messageRateLimiter.acquire();
/**
save..
*/
}2. ES 越來越慢
由於 MES 日誌量比較大,也有冷熱之分,為了在保證效能的同時方便資料遷移,我們按照應用 + 月份的粒度建立 ES 索引,如下所示:

3. 頻繁 Full GC
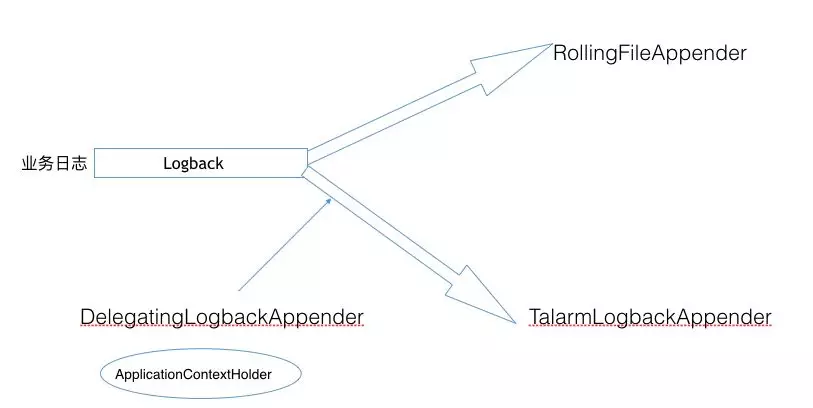
我們使用 Logback 作為日誌框架,為了能夠蒐集到 ERROR 和 WARN 日誌,自定義了一個 Appender。如果想蒐集 Spring 容器啟動之前(此時 TalarmLogbackAppender 還未初始化)的日誌, Logback 的一個擴充套件 jar 包中的 DelegatingLogbackAppender 提供了一種快取的方式,記憶體洩漏就出在這個快取的地方。
正常情況系統啟動起來之後,ApplicationContextHolder 中的 Spring 上下文不為空,會自動從快取裡面把日誌取出來。但是如果因為種種原因沒有初始化這個類 ApplicationContextHolder,日誌會在快取中越積越多,最終導致頻繁的 Full GC。
解決辦法:
1. 保證 ApplicationContextHolder 的初始化
2. DelegatingLogbackAppender 有三種模式:OFF SOFT ON ,如果需要開啟,儘量使用 SOFT模式,這時候快取被儲存在一個由 SoftReference 包裝的列表中,在系統記憶體不足的時候,可以被垃圾回收器回收掉。
近期規劃
目前這個系統還有一些不完善的地方,也是未來的一些規劃:
-
更易用:提供更多的使用幫助提示,幫助開發人員快速熟悉系統。
-
更多報警維度:目前支援 HTTP,SQL, Dubbo 元件的自動報警,後續會陸續支援 MQ,Redis 定時任務等等。
-
圖形化展示:將埋點資料通過圖形的方式展示出來,可以更直觀地展示出系統的執行情況,同時也有助於開發人員對於系統閾值的設定。
小結
總結起來,大交通業務監控報警系統架構有以下幾個特點:
-
支援靈活的報警規則配置,豐富的篩選邏輯
-
自動新增常用元件的報警,Dubbo、HTTP 自動接入報警
-
接入簡單,接入 MES 的系統都可以快速接入使用
線上生產運維主要做 3 件事:發現問題、定位問題、解決問題。發現問題,就是在系統出現異常的時候儘快通知系統負責人。定位問題和解決問題,就是能夠為開發人員提供快速修復系統的必要資訊,越精確越好。
報警系統的定位應該是線上問題解決鏈條中的第一步和入口手段。將其通過核心線索資料與資料回溯系統( tracer 鏈路等),部署釋出系統等進行有機的串聯,可以極大提升線上問題解決的效率,更好地為生產保駕護航。
不管做什麼,我們最終的目標只有一個,就是提高服務的質量。
本文作者:宋考俊,馬蜂窩大交通平臺高階研發工程師。
(題圖來源:網路)

關注馬蜂窩技術,找到更多你想要的內容