
JDK1.8原始碼(三)——java.util.HashMap
什麼是雜湊表?
在討論雜湊表之前,我們先大概瞭解下其他資料結構在新增,查詢等基礎操作執行效能
陣列:採用一段連續的儲存單元來儲存資料。對於指定下標的查詢,時間複雜度為O(1);通過給定值進行查詢,需要遍歷陣列,逐一比對給定關鍵字和陣列元素,時間複雜度為O(n),當然,對於有序陣列,則可採用二分查詢,插值查詢,斐波那契查詢等方式,可將查詢複雜度提高為O(logn);對於一般的插入刪除操作,涉及到陣列元素的移動,其平均複雜度也為O(n)
線性連結串列:對於連結串列的新增,刪除等操作(在找到指定操作位置後),僅需處理結點間的引用即可,時間複雜度為O(1),而查詢操作需要遍歷連結串列逐一進行比對,複雜度為O(n)
二叉樹:對一棵相對平衡的有序二叉樹,對其進行插入,查詢,刪除等操作,平均複雜度均為O(logn)。
雜湊表:相比上述幾種資料結構,在雜湊表中進行新增,刪除,查詢等操作,效能十分之高,不考慮雜湊衝突的情況下,僅需一次定位即可完成,時間複雜度為O(1),接下來我們就來看看雜湊表是如何實現達到驚豔的常數階O(1)的。
我們知道,資料結構的物理儲存結構只有兩種:順序儲存結構和鏈式儲存結構(像棧,佇列,樹,圖等是從邏輯結構去抽象的,對映到記憶體中,也這兩種物理組織形式),而在上面我們提到過,在陣列中根據下標查詢某個元素,一次定位就可以達到,雜湊表利用了這種特性,雜湊表的主幹就是陣列。
比如我們要新增或查詢某個元素,我們通過把當前元素的關鍵字 通過某個函式對映到陣列中的某個位置,通過陣列下標一次定位就可完成操作。
儲存位置 = f(關鍵字)
其中,這個函式f一般稱為雜湊函式,這個函式的設計好壞會直接影響到雜湊表的優劣。舉個例子,比如我們要在雜湊表中執行插入操作:
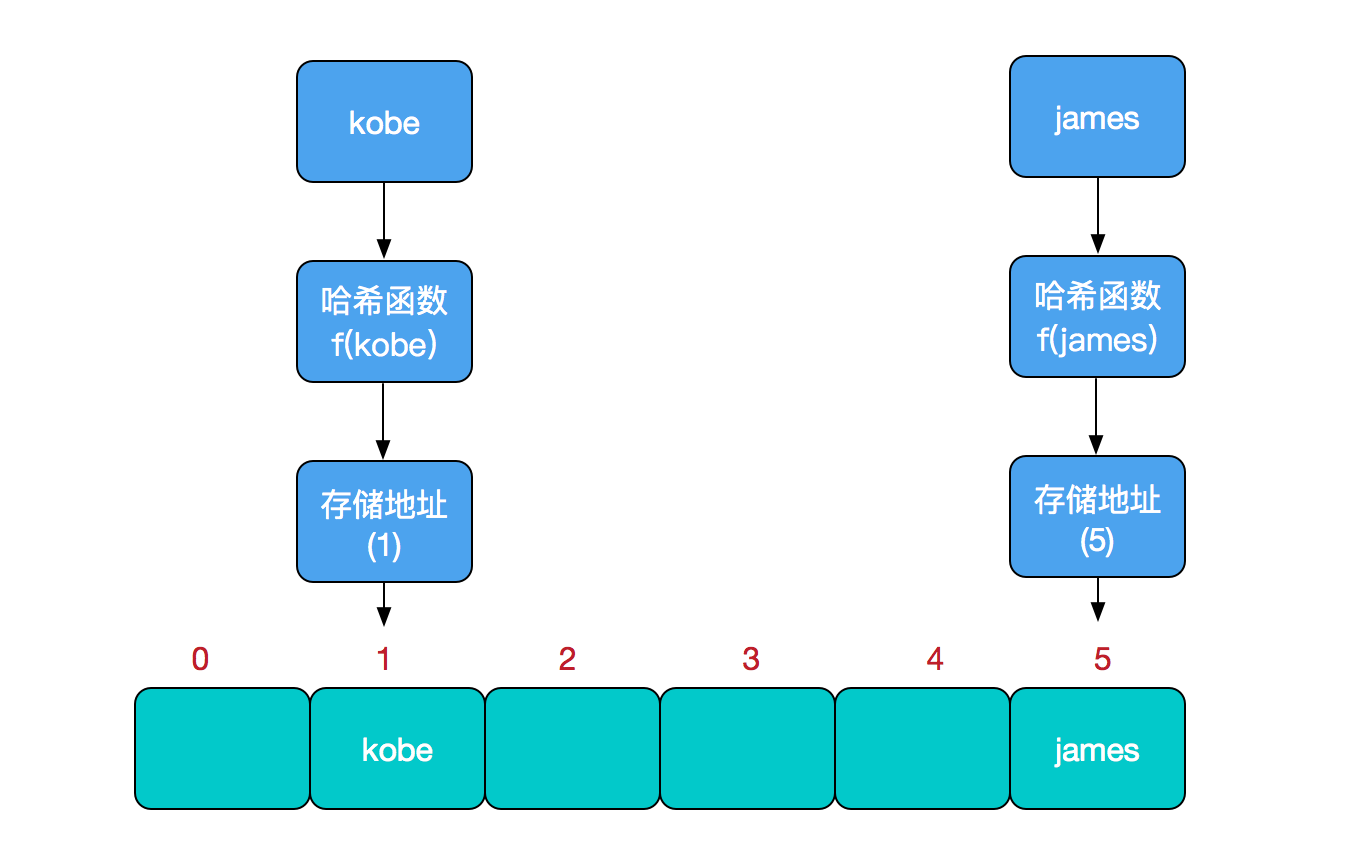
查詢操作同理,先通過雜湊函式計算出實際儲存地址,然後從陣列中對應地址取出即可。
雜湊衝突
然而萬事無完美,如果兩個不同的元素,通過雜湊函式得出的實際儲存地址相同怎麼辦?也就是說,當我們對某個元素進行雜湊運算,得到一個儲存地址,然後要進行插入的時候,發現已經被其他元素佔用了,其實這就是所謂的雜湊衝突
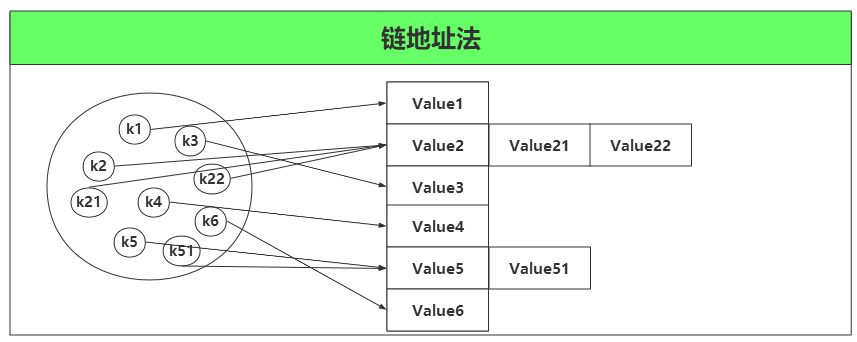
什麼是HashMap?
HashMap 是一個利用雜湊表原理來儲存元素的集合。遇到衝突時,HashMap 是採用的鏈地址法來解決,在 JDK1.7 中,HashMap 是由 陣列+連結串列構成的。但是在 JDK1.8 中,HashMap 是由 陣列+連結串列+紅黑樹構成,新增了紅黑樹作為底層資料結構,結構變得複雜了,但是效率也變的更高效。下面我們來具體介紹在 JDK1.8 中 HashMap 是如何實現的。

HashMap定義
HashMap 是一個散列表,它儲存的內容是鍵值對(key-value)對映,而且 key 和 value 都可以為 null。
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
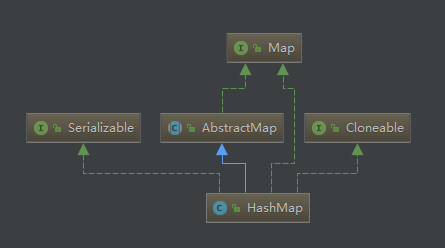
藍色實線箭頭是指Class繼承關係
綠色實線箭頭是指interface繼承關係
綠色虛線箭頭是指介面實現關係
欄位屬性


//預設 HashMap 集合初始容量為16(必須是 2 的倍數) static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 //集合的最大容量,如果通過帶參構造指定的最大容量超過此數,預設還是使用此數 static final int MAXIMUM_CAPACITY = 1 << 30; //預設的填充因子 static final float DEFAULT_LOAD_FACTOR = 0.75f; //當桶(bucket)上的結點數大於這個值時會轉成紅黑樹(JDK1.8新增) static final int TREEIFY_THRESHOLD = 8; //當桶(bucket)上的節點數小於這個值時會轉成連結串列(JDK1.8新增) static final int UNTREEIFY_THRESHOLD = 6; /**(JDK1.8新增) * 當集合中的容量大於這個值時,表中的桶才能進行樹形化 ,否則桶內元素太多時會擴容, * 而不是樹形化 為了避免進行擴容、樹形化選擇的衝突,這個值不能小於 4 * TREEIFY_THRESHOLD */ static final int MIN_TREEIFY_CAPACITY = 64;View Code
//初始化使用,長度總是 2的冪 transient Node<K,V>[] table; //儲存快取的entrySet() transient Set<Map.Entry<K,V>> entrySet; //此對映中包含的鍵值對映的數量。(集合儲存鍵值對的數量) transient int size; /** * 跟前面ArrayList和LinkedList集合中的欄位modCount一樣,記錄集合被修改的次數 * 主要用於迭代器中的快速失敗 */ transient int modCount; //調整大小的下一個大小值(容量*載入因子)。capacity * load factor int threshold; //散列表的載入因子。 final float loadFactor;View Code
①、Node<K,V>[] table
我們說 HashMap 是由陣列+連結串列+紅黑樹組成,這裡的陣列就是 table 欄位。後面對其進行初始化長度預設是 DEFAULT_INITIAL_CAPACITY= 16。
②、size
集合中存放key-value 的實時對數。
③、loadFactor
裝載因子,是用來衡量 HashMap 滿的程度,計算HashMap的實時裝載因子的方法為:size/capacity,而不是佔用桶的數量去除以capacity。capacity 是桶的數量,也就是 table 的長度length。
預設的負載因子0.75 是對空間和時間效率的一個平衡選擇,建議大家不要修改,除非在時間和空間比較特殊的情況下,如果記憶體空間很多而又對時間效率要求很高,可以降低負載因子loadFactor 的值;相反,如果記憶體空間緊張而對時間效率要求不高,可以增加負載因子 loadFactor 的值,這個值可以大於1。
④、threshold
計算公式:capacity * loadFactor。這個值是當前已佔用陣列長度的最大值。過這個數目就重新resize(擴容),擴容後的 HashMap 容量是之前容量的兩倍
建構函式
①、無參建構函式
/** * 預設建構函式,初始化載入因子loadFactor = 0.75 */ public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; }View Code
②、指定初始容量的建構函式
/** * * @param initialCapacity 指定初始化容量 * @param loadFactor 載入因子 0.75 */ public HashMap(int initialCapacity, float loadFactor) { //初始化容量不能小於 0 ,否則丟擲異常 if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); //如果初始化容量大於2的30次方,則初始化容量都為2的30次方 if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; //如果載入因子小於0,或者載入因子是一個非數值,丟擲異常 if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; //tableSizeFor()的主要功能是返回一個比給定整數大且最接近的2的冪次方整數,如給定10,返回2的4次方16. this.threshold = tableSizeFor(initialCapacity); } // 返回大於等於initialCapacity的最小的二次冪數值。 // >>> 操作符表示無符號右移,高位取0。 // | 按位或運算 static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }View Code
新增元素
//hash(key)獲取Key的雜湊值,equls返回為true,則兩者的hashcode一定相等,意即相等的物件必須具有相等的雜湊碼。 public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } /** * * @param hash Key的雜湊值 * @param key 鍵 * @param value 值 * @param onlyIfAbsent true 表示不要更改現有值 * @param evict false表示table處於建立模式 * @return */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //如果table為null或者長度為0,則進行初始化 //resize()方法本來是用於擴容,由於初始化沒有實際分配空間,這裡用該方法進行空間分配,後面會詳細講解該方法 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //(n - 1) & hash:確保索引在陣列範圍內,相當於hash % n 的值 //通過 key 的 hash code 計算其在陣列中的索引:為什麼不直接用 hash 對 陣列長度取模?因為除法運算效率低 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);//tab[i] 為null,直接將新的key-value插入到計算的索引i位置 else {//tab[i] 不為null,表示該位置已經有值了 Node<K,V> e; K k; //e節點表示已經存在Key的節點,需要覆蓋value的節點 //table[i]的首個元素是否和key一樣,如果相同直接覆蓋value if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p;//節點key已經有值了,將第一個節點賦值給e //該鏈是紅黑樹 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //該鏈是連結串列 else { //遍歷連結串列 for (int binCount = 0; ; ++binCount) { //先將e指向下一個節點,然後判斷e是否是連結串列中最後一個節點 if ((e = p.next) == null) { 建立一個新節點加在連結串列結尾 p.next = newNode(hash, key, value, null); //連結串列長度大於8,轉換成紅黑樹 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } //key已經存在直接終止,此時e的值已經為 p.next if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) //修改已經存在Key的節點的value e.value = value; afterNodeAccess(e); //返回key的原始值 return oldValue; } } ++modCount;//用作修改和新增快速失敗 if (++size > threshold)//超過最大容量,進行擴容 resize(); afterNodeInsertion(evict); return null; }View Code
①、判斷鍵值對陣列 table 是否為空或為null,否則執行resize()進行擴容;
②、根據鍵值key計算hash值得到插入的陣列索引i,如果table[i]==null,直接新建節點新增,轉向⑥,如果table[i]不為空,轉向③;
③、判斷table[i]的首個元素是否和key一樣,如果相同直接覆蓋value,否則轉向④,這裡的相同指的是hashCode以及equals;
④、判斷table[i] 是否為treeNode,即table[i] 是否是紅黑樹,如果是紅黑樹,則直接在樹中插入鍵值對,否則轉向⑤;
⑤、遍歷table[i],判斷連結串列長度是否大於8,大於8的話把連結串列轉換為紅黑樹,在紅黑樹中執行插入操作,否則進行連結串列的插入操作;遍歷過程中若發現key已經存在直接覆蓋value即可;
⑥、插入成功後,判斷實際存在的鍵值對數量size是否超過了最大容量threshold,如果超過,進行擴容。
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) 此處先判斷p.hash == hash是為了提高效率,僅通過(k = e.key) == key || key.equals(k)其實也可以進行判斷,但是equals方法相當耗時!如果兩個key的hash值不同,那麼這兩個key肯定不相同,進行equals比較是扯淡的! 所以先通過p.hash == hash該條件,將桶中很多不符合的節點pass掉。然後對剩下的節點繼續判斷。
擴容
擴容(resize),我們知道集合是由陣列+連結串列+紅黑樹構成,向 HashMap 中插入元素時,如果HashMap 集合的元素已經大於了最大承載容量threshold(capacity * loadFactor),這裡的threshold不是陣列的最大長度。那麼必須擴大陣列的長度,Java中陣列是無法自動擴容的,我們採用的方法是用一個更大的陣列代替這個小的陣列
final Node<K,V>[] resize() { //將原始陣列資料快取起來 Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length;//原陣列如果為null,則長度賦值0 int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) {//如果原陣列長度大於0 if (oldCap >= MAXIMUM_CAPACITY) {//陣列大小如果已經大於等於最大值(2^30) threshold = Integer.MAX_VALUE;//修改閾值為int的最大值(2^31-1),這樣以後就不會擴容了 return oldTab; } //原陣列長度擴大1倍(此時將原陣列擴大一倍後的值賦給newCap)也小於2^30次方,並且原陣列長度大於等於初始化長度16 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // 閥值擴大1倍 //如果原陣列長度擴大一倍後大於MAXIMUM_CAPACITY後,newThr還是0 } else if (oldThr > 0) //舊容量為0,舊閥值大於0,則將新容量直接等於就閥值 //在第一次帶引數初始化時候會有這種情況 //newThr在面算 newCap = oldThr; else { //閥值等於0,oldCap也等於0(集合未進行初始化) //在預設無引數初始化會有這種情況 newCap = DEFAULT_INITIAL_CAPACITY;//陣列長度初始化為16 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//閥值等於16*0.75=12 } //計算新的閥值上限 //此時就是上面原陣列長度擴大一倍後大於MAXIMUM_CAPACITY和舊容量為0、舊閥值大於0的情況 if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } //將閥值上限設定為新閥值上限 threshold = newThr; //用於抑制編譯器產生警告資訊 @SuppressWarnings({"rawtypes","unchecked"}) //建立容器大小為newCap的新陣列 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; //將新陣列賦給table table = newTab; //如果是第一次,擴容的時候,也就是原來沒有元素,下面的程式碼不會執行,如果原來有元素,則要將原來的元素,進行放到新擴容的裡面 if (oldTab != null) { //把每個bucket都移動到新的buckets中 for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null;//元資料j位置置為null,便於垃圾回收 if (e.next == null)//陣列沒有下一個引用(不是連結串列) //直接將e的key的hash與新容量重新計算下標,新下標的元素為e newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode)//紅黑樹 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; //原索引 if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } //原索引+oldCap else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); //原索引放到bucket裡 if (loTail != null) { loTail.next = null; newTab[j] = loHead; } //原索引+oldCap放到bucket裡 if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }View Code
if ((e.hash & oldCap) == 0)如果判斷成立,那麼該元素的地址在新的陣列中就不會改變。因為oldCap的最高位的1,在e.hash對應的位上為0,所以擴容後得到的地址是一樣的,位置不會改變 ,在後面的程式碼的執行中會放到loHead中去,最後賦值給newTab[j];如果判斷不成立,那麼該元素的地址變為 原下標位置+oldCap,也就是lodCap最高位的1,在e.hash對應的位置上也為1,所以擴容後的地址改變了,在後面的程式碼中會放到hiHead中,最後賦值給newTab[j + oldCap] 舉個栗子來說一下上面的兩種情況: 設:oldCap=16 二進位制為:0001 0000 oldCap-1=15 二進位制為:0000 1111 e1.hash=10 二進位制為:0000 1010 e2.hash=26 二進位制為:0101 1010 e1在擴容前的位置為:e1.hash & oldCap-1 結果為:0000 1010 e2在擴容前的位置為:e2.hash & oldCap-1 結果為:0000 1010 結果相同,所以e1和e2在擴容前在同一個連結串列上,這是擴容之前的狀態。 現在擴容後,需要重新計算元素的位置,在擴容前的連結串列中計算地址的方式為e.hash & oldCap-1 那麼在擴容後應該也這麼計算呀,擴容後的容量為oldCap*2=32 0010 0000 newCap=32,新的計算 方式應該為 e1.hash & newCap-1 即:0000 1010 & 0001 1111 結果為0000 1010與擴容前的位置完全一樣。 e2.hash & newCap-1 即:0101 1010 & 0001 1111 結果為0001 1010,為擴容前位置+oldCap。 而這裡卻沒有e.hash & newCap-1 而是 e.hash & oldCap,其實這兩個是等效的,都是判斷倒數第五位是0,還是1。如果是0,則位置不變,是1則位置改變為擴容前位置+oldCap。
查詢元素
①、get(Object key)
通過 key 查詢 value:首先通過 key 找到計算索引,找到桶元素的位置,先檢查第一個節點,如果是則返回,如果不是,則遍歷其後面的連結串列或者紅黑樹。其餘情況全部返回 null。
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { //根據key計算的索引檢查第一個索引 if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; //不是第一個節點 if ((e = first.next) != null) { if (first instanceof TreeNode)//遍歷樹查詢元素 return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { //遍歷連結串列查詢元素 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }View Code
②、判斷是否存在給定的 key 或者 value
public boolean containsKey(Object key) { return getNode(hash(key), key) != null; } public boolean containsValue(Object value) { Node<K,V>[] tab; V v; if ((tab = table) != null && size > 0) { //遍歷陣列 for (int i = 0; i < tab.length; ++i) { //遍歷陣列中的每個節點元素 for (Node<K,V> e = tab[i]; e != null; e = e.next) { if ((v = e.value) == value || (value != null && value.equals(v))) return true; } } } return false; }View Code
刪除元素
public V remove(Object key) { Node<K,V> e; return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value; } final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; //(n - 1) & hash找到桶的位置 if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { Node<K,V> node = null, e; K k; V v; //如果鍵的值與連結串列第一個節點相等,則將 node 指向該節點 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; //如果桶節點存在下一個節點 else if ((e = p.next) != null) { //節點為紅黑樹 if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key);//找到需要刪除的紅黑樹節點 else { do {//遍歷連結串列,找到待刪除的節點 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; //找到就停止,如果此時是第一次遍歷就找到,則node指向連結串列中第二個元素,p還是第一個元素 //第一次沒找到,第二次找到,則node指向連結串列中第三個元素,p指向第二個元素,p是找到元素節點的父節點 //所以需要遍歷的時候p和node 是不相等的,只有連結串列第一個元素就判斷相等時,p和node 相等 break; } //第一次遍歷沒找到, 此時p指向第二個元素 p = e; } while ((e = e.next) != null); } } //刪除節點,並進行調節紅黑樹平衡 if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); else if (node == p) //如果鍵的值與連結串列第一個節點相等,則將元素位置指向 node的下一個節點(連結串列的第二個節點),有可能node.next 為null tab[index] = node.next; else //如果鍵的值與連結串列第一個節點不相等,node的父節點的next指向node的next p.next = node.next; ++modCount; --size; afterNodeRemoval(node); return node; } } return null; }View Code
遍歷元素
HashMap<String, String> map = new HashMap<>(); map.put("1", "A"); map.put("2", "B"); map.put("3", "C"); map.put("4", "D"); map.put("5", "E"); map.put("6", "F"); for(String str : map.keySet()){ System.out.print(map.get(str)+" "); } for(HashMap.Entry entry : map.entrySet()){ System.out.print(entry.getKey()+" "+entry.getValue()); }View Code
重寫equals方法需同時重寫hashCode方法
各種資料上都會提到,“重寫equals時也要同時覆蓋hashcode”,我們舉個小例子來看看,如果重寫了equals而不重寫hashcode會發生什麼樣的問題
/** * Created by chenhao on 2018/9/28. */ public class MyTest { private static class Person{ int idCard; String name; public Person(int idCard, String name) { this.idCard = idCard; this.name = name; } @Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()){ return false; } Person person = (Person) o; //兩個物件是否等值,通過idCard來確定 return this.idCard == person.idCard; } } public static void main(String []args){ HashMap<Person,String> map = new HashMap<Person, String>(); Person person = new Person(123,"喬峰"); //put到hashmap中去 map.put(person,"天龍八部"); //get取出,從邏輯上講應該能輸出“天龍八部” System.out.println("結果:"+map.get(new Person(123,"蕭峰"))); } }View Code
如果我們已經對HashMap的原理有了一定了解,這個結果就不難理解了。儘管我們在進行get和put操作的時候,使用的key從邏輯上講是等值的(通過equals比較是相等的),但由於沒有重寫hashCode方法,所以put操作時,key(hashcode1)-->hash-->indexFor-->最終索引位置 ,而通過key取出value的時候 key(hashcode2)-->hash-->indexFor-->最終索引位置,由於hashcode1不等於hashcode2,導致沒有定位到一個數組位置而返回邏輯上錯誤的值null(也有可能碰巧定位到一個數組位置,但是也會判斷其entry的hash值是否相等,上面get方法中有提到。)
所以,在重寫equals的方法的時候,必須注意重寫hashCode方法,同時還要保證通過equals判斷相等的兩個物件,呼叫hashCode方法要返回同樣的整數值。而如果equals判斷不相等的兩個物件,其hashCode可以相同(只不過會發生雜湊衝突,應儘量避免)。