
Java中HashMap底層實現原理(JDK1.8)原始碼分析
在JDK1.6,JDK1.7中,HashMap採用位桶+連結串列實現,即使用連結串列處理衝突,同一hash值的連結串列都儲存在一個連結串列裡。但是當位於一個桶中的元素較多,即hash值相等的元素較多時,通過key值依次查詢的效率較低。而JDK1.8中,HashMap採用位桶+連結串列+紅黑樹實現,當連結串列長度超過閾值(8)時,將連結串列轉換為紅黑樹,這樣大大減少了查詢時間。
簡單說下HashMap的實現原理:
首先有一個每個元素都是連結串列(可能表述不準確)的陣列,當新增一個元素(key-value)時,就首先計算元素key的hash值,以此確定插入陣列中的位置,但是可能存在同一hash值的元素已經被放在陣列同一位置了,這時就新增到同一hash值的元素的後面,他們在陣列的同一位置,但是形成了連結串列,同一各連結串列上的Hash值是相同的,所以說陣列存放的是連結串列。而當連結串列長度太長時,連結串列就轉換為紅黑樹,這樣大大提高了查詢的效率。
當連結串列陣列的容量超過初始容量的0.75時,再雜湊將連結串列陣列擴大2倍,把原連結串列陣列的搬移到新的陣列中
即HashMap的原理圖是:
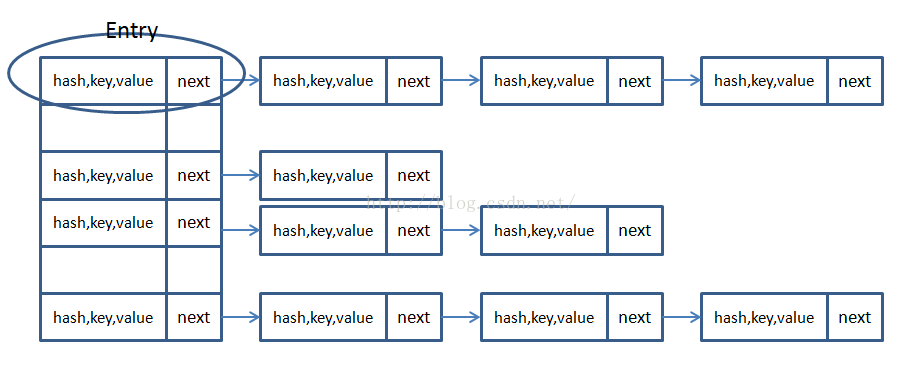
一,JDK1.8中的涉及到的資料結構
1,位桶陣列
- transient Node<k,v>[] table;//儲存(位桶)的陣列</k,v>
- //Node是單向連結串列,它實現了Map.Entry介面
- staticclass Node<k,v> implements Map.Entry<k,v> {
- finalint hash;
- finalK key;
- V value;
- Node<k,v> next;
- //建構函式Hash值 鍵 值 下一個節點
- Node(int hash, K key, V value, Node<k,v> next) {
- this.hash = hash;
- this.key = key;
- this.value = value;
- this.next = next;
- }
- publicfinal K getKey() { return key; }
- publicfinal V getValue() { return value; }
- publicfinal String toString() { return key + = + value; }
- publicfinalint hashCode() {
- return Objects.hashCode(key) ^ Objects.hashCode(value);
- }
- publicfinal V setValue(V newValue) {
- V oldValue = value;
- value = newValue;
- return oldValue;
- }
- //判斷兩個node是否相等,若key和value都相等,返回true。可以與自身比較為true
- publicfinalboolean equals(Object o) {
- if (o == this)
- returntrue;
- if (o instanceof Map.Entry) {
- Map.Entry<!--?,?--> e = (Map.Entry<!--?,?-->)o;
- if (Objects.equals(key, e.getKey()) &&
- Objects.equals(value, e.getValue()))
- returntrue;
- }
- returnfalse;
- }
- //紅黑樹
- staticfinalclass TreeNode<k,v> extends LinkedHashMap.Entry<k,v> {
- TreeNode<k,v> parent; // 父節點
- TreeNode<k,v> left; //左子樹
- TreeNode<k,v> right;//右子樹
- TreeNode<k,v> prev; // needed to unlink next upon deletion
- boolean red; //顏色屬性
- TreeNode(int hash, K key, V val, Node<k,v> next) {
- super(hash, key, val, next);
- }
- //返回當前節點的根節點
- final TreeNode<k,v> root() {
- for (TreeNode<k,v> r = this, p;;) {
- if ((p = r.parent) == null)
- return r;
- r = p;
- }
- }
二,原始碼中的資料域
載入因子(預設0.75):為什麼需要使用載入因子,為什麼需要擴容呢?因為如果填充比很大,說明利用的空間很多,如果一直不進行擴容的話,連結串列就會越來越長,這樣查詢的效率很低,因為連結串列的長度很大(當然最新版本使用了紅黑樹後會改進很多),擴容之後,將原來連結串列陣列的每一個連結串列分成奇偶兩個子連結串列分別掛在新連結串列陣列的雜湊位置,這樣就減少了每個連結串列的長度,增加查詢效率
HashMap本來是以空間換時間,所以填充比沒必要太大。但是填充比太小又會導致空間浪費。如果關注記憶體,填充比可以稍大,如果主要關注查詢效能,填充比可以稍小。
- publicclass HashMap<k,v> extends AbstractMap<k,v> implements Map<k,v>, Cloneable, Serializable {
- privatestaticfinallong serialVersionUID = 362498820763181265L;
- staticfinalint DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
- staticfinalint MAXIMUM_CAPACITY = 1 << 30;//最大容量
- staticfinalfloat DEFAULT_LOAD_FACTOR = 0.75f;//填充比
- //當add一個元素到某個位桶,其連結串列長度達到8時將連結串列轉換為紅黑樹
- staticfinalint TREEIFY_THRESHOLD = 8;
- staticfinalint UNTREEIFY_THRESHOLD = 6;
- staticfinalint MIN_TREEIFY_CAPACITY = 64;
- transient Node<k,v>[] table;//儲存元素的陣列
- transient Set<map.entry<k,v>> entrySet;
- transientint size;//存放元素的個數
- transientint modCount;//被修改的次數fast-fail機制
- int threshold;//臨界值 當實際大小(容量*填充比)超過臨界值時,會進行擴容
- finalfloat loadFactor;//填充比(......後面略)
HashMap的構造方法有4種,主要涉及到的引數有,指定初始容量,指定填充比和用來初始化的Map
- //建構函式1
- public HashMap(int initialCapacity, float loadFactor) {
- //指定的初始容量非負
- if (initialCapacity < 0)
- thrownew IllegalArgumentException(Illegal initial capacity: +
- initialCapacity);
- //如果指定的初始容量大於最大容量,置為最大容量
- if (initialCapacity > MAXIMUM_CAPACITY)
- initialCapacity = MAXIMUM_CAPACITY;
- //填充比為正
- if (loadFactor <= 0 || Float.isNaN(loadFactor))
- thrownew IllegalArgumentException(Illegal load factor: +
- loadFactor);
-
相關推薦
Java中HashMap底層實現原理(JDK1.8)原始碼分析
在JDK1.6,JDK1.7中,HashMap採用位桶+連結串列實現,即使用連結串列處理衝突,同一hash值的連結串列都儲存在一個連結串列裡。但是當位於一個桶中的元素較多,即hash值相等的元素較多時,通過key值依次查詢的效率較低。而JDK1.8中,HashMap採用位桶+
(轉載)Java中HashMap底層實現原理(JDK1.8)原始碼分析
近期在看一些java底層的東西,看到一篇分析hashMap不錯的文章,跟大家分享一下。 在JDK1.6,JDK1.7中,HashMap採用位桶+連結串列實現,即使用連結串列處理衝突,同一hash值的連結串列都儲存在一個連結串列裡。但是當位於一個桶中的元素較多,即hash值
Java中HashMap底層實現原理(JDK1.8)源碼分析
blank imp dash logs || 屬性 lte das ces 這幾天學習了HashMap的底層實現,但是發現好幾個版本的,代碼不一,而且看了Android包的HashMap和JDK中的HashMap的也不是一樣,原來他們沒有指定JDK版本,很多文章都是舊版本J
Java面試必問之Hashmap底層實現原理(JDK1.8)
# 1. 前言 上一篇從原始碼方面瞭解了JDK1.7中Hashmap的實現原理,可以看到其原始碼相對還是比較簡單的。本篇筆者和大家一起學習下JDK1.8下Hashmap的實現。JDK1.8中對Hashmap做了以下改動。 - 預設初始化容量=0 - 引入紅黑樹,優化資料結構 - 將連結串列頭插法改為尾插法
演算法---hash演算法原理(java中HashMap底層實現原理和原始碼解析)
散列表(Hash table,也叫雜湊表),是依據關鍵碼值(Key value)而直接進行訪問的資料結構。也就是說,它通過把關鍵碼值對映到表中一個位置來訪問記錄,以加快查詢的速度。這個對映函式叫做雜湊函式,存放記錄的陣列叫做散列表。 比如我們要儲存八十八個資料,我們為他申請了100個
Java面試必問之Hashmap底層實現原理(JDK1.7)
# 1. 前言 Hashmap可以說是Java面試必問的,一般的面試題會問: * Hashmap有哪些特性? * Hashmap底層實現原理(get\put\resize) * Hashmap怎麼解決hash衝突? * Hashmap是執行緒安全的嗎? * ... 今天就從原始碼角度一探究竟。筆者的原始
【JAVA】HashMap底層實現原理淺談
HashMap底層實現原理淺談 不論是實習還是正式工作,HashMap的底層實現原理一直是問地頻率最高的一個內容,今天記錄一下自己對HashMap的理解,如有不當之處,還請各位大佬指正。 一、前置名詞解釋
Java中HashMap的實現原理
轉載自作者:ZeroRen 一、Java中的hashCode和equals 1、關於hashCode hashCode的存在主要是用於查詢的快捷性,如Hashtable,HashMap等,hashCode是用來在雜湊儲存結構中確定物件的儲存地址的如果兩個物件相同,就
ReentrantLock在Java中Lock的實現原理拿鎖過程分析
import java.util.concurrent.locks.ReentrantLock; public class App { public static void main(String[] args) throws Exception {
Android中三級快取實現原理及LruCache 原始碼分析
介紹 oom異常:大圖片導致 圖片的三級快取:記憶體、磁碟、網路 下面通過一張圖來了解下三級快取原理: 程式碼: public class Davince { //使用固定執行緒池優化 private static Exec
深入理解Java中的底層阻塞原理及實現
更多 安全 posix pla static events time() 方便 原理 談到阻塞,相信大家都不會陌生了。阻塞的應用場景真的多得不要不要的,比如 生產-消費模式,限流統計等等。什麽 ArrayBlockingQueue、 LinkedBlockingQueue、
Java底層之HashMap底層實現原理
HashMap簡介 HashMap 是一個散列表,它儲存的內容是鍵值對(key-value)對映。 HashMap 繼承於AbstractMap,實現了Map、Cloneable、java.io.Serializable介面。 HashMap 的實現不是同步的,
Java集合 --- HashMap底層實現和原理
概述 文章的內容基於JDK1.7進行分析,之所以選用這個版本,是因為1.8的有些類做了改動,增加了閱讀的難度,雖然是1.7,但是對於1.8做了重大改動的內容,文章也會進行說明。 HashMap基於Map介面實現,元素以鍵值對的方式儲存,並且允許使用null 建和null值,因為ke
JAVA HashMap底層實現原理
1. HashMap概述: HashMap是基於雜湊表的Map介面的非同步實現。此實現提供所有可選的對映操作,並允許使用null值和null鍵。此類不保證對映的順序,特別是它不保證該順序恆久不變。 2. HashMap的資料結構: 在jav
就是要你懂Java中volatile關鍵字實現原理
stub string home 技術分享 訪問速度 get 地址傳遞 code 緩沖 原文地址http://www.cnblogs.com/xrq730/p/7048693.html,轉載請註明出處,謝謝 前言 我們知道volatile關鍵字的作用是保證變量在多線程之
Java中volatile關鍵字實現原理
三級 poll 解讀 內存屏障 就會 主存 發生 調用 獲得 原文地址http://www.cnblogs.com/xrq730/p/7048693.html,轉載請註明出處,謝謝 前言 我們知道volatile關鍵字的作用是保證變量在多線程之間的可見性,它是ja
HashMap底層實現原理
cati 是我 次數 max turn 索引 線程安全 出現 獲取 一、數據結構 HashMap中的數據結構是數組+單鏈表的組合,以鍵值對(key-value)的形式存儲元素的,通過put()和get()方法儲存和獲取對象。 (方塊表示Entry對象,橫排表示數組t
(轉)HashMap底層實現原理/HashMap與HashTable區別/HashMap與HashSet區別
eem 實現原理 ger 銀行 索引 target 聲明 到你 們的 ①HashMap的工作原理 HashMap基於hashing原理,我們通過put()和get()方法儲存和獲取對象。當我們將鍵值對傳遞給put()方法時,它調用鍵對象的hashCode()方法來計算has
Java中HashMap底層資料結構
HashMap也是我們使用非常多的Collection,它是基於雜湊表的 Map 介面的實現,以key-value的形式存在。在HashMap中,key-value總是會當做一個整體來處理,系統會根據hash演算法來來計算key-value的儲存位置,我們總是可以通過key快速地存、取value。下
HashMap底層實現原理詳解(轉載)
本文轉自:https://blog.csdn.net/caihaijiang/article/details/6280251 java中HashMap詳解 HashMap 和 HashSet 是 Java Collection Framework 的兩個重要成員,其中 HashMap 是