MongoDB 執行計劃 & 優化器簡介 (上)
最近,由於工作需求去了解一下Query是如何在MongoDB內部進行處理,從而丟給儲存引擎的。裡面涉及了Query執行計劃和優化器的相關程式碼,MongoDB整體思路設計的乾淨利落,有些地方深入挖一下其實還是能有些優化點的。本文會涉及一條Query被parse之後一路走到引擎之前,都做了那些事情,分析基於MongoDB v3.4.6程式碼。由於篇幅過長,文章分為上下兩篇,分別介紹執行計劃 & 優化器和Query具體的執行器。
1. 一條Query語句都做了什麼
名詞定義:
QuerySolution執行計劃,本文也稱PlanQueryPlaner生成執行計劃模組PlanExecutor執行執行計劃模組,同時充當優化器(Optimizer)的角色
下圖主要描述了Query在執行層的邏輯,其他模組的邏輯進行了精簡:

- 1). Client按照MongoDB的網路協議,請求建立連線,並友單獨新建的thread處理所有請求。
- 2). 有些Query(如insert),本身不需要執行計劃和優化,這直接通過介面和引擎互動(通過RecordStore寫表)
- 3). Query會進行簡單的處理(標準化),並構造一些上下文資料結構變成CanonicalQuery(標準化Query)。
- 4). Plan模組會負責生成該Query的多個執行計劃,然後丟給Optimizer去選擇最優的,丟給PlanExecutor。
- 5). PlanExecutor按照執行計劃一步一步迭代,獲得最終的資料(或執行update修改資料)。
在此流程中:
Plan如果只關聯到單個或零個索引,這隻生成一個執行計劃,如果發現有多個索引或者索引有重疊,這可能生成多個執行計劃。Optimizer只在多個執行計劃時,才會介入。
2. QuerySolution 執行計劃
本文後續以MongoDB find命令為基礎,介紹執行計劃。update和delete也需要執行計劃,生成原理類似。
下面是一個標準的find查詢協議包,紅框內是涉及查詢的基本運算元如:過濾條件filter運算元、sort排序運算元、投影運算元等等,其他是查詢的一些屬性,MongoDB查詢區別於SQL,沒有那麼複雜的語法和語義解析,各個運算元被結構化的儲存到協議標準裡面,所以普通的查詢也直接可以取出。

- filter : 查詢過濾條件,類比SQL的where表示式
- projection : 投影,選擇取出的fields,類比SQL的select
- hint : 手工指定索引,可以強制指定使用某個索引
後續Plan會在這些運算元上做邏輯處理、優化再連線各個運算元,並生成一顆可以執行的樹狀資料結構。
2.1 CanonicalQuery
上述Query中各個運算元使用bson結構表示的邏輯表示式,這裡會被先標準化成CanonicalQuery。主要涉及collator和MatchExpression的生成。collator是使用者可以自定義的除了ByteComparator(逐位元組比較排序)之外的比較方法,比如內建的中文比較。collator需要和filter裡的邏輯表示式相關聯(比如$gt大於運算)。
MatchExpression是將filter運算元裡每個邏輯運算轉換成各個型別的表示式(GT,ET,LT,AND,OR...),構成一個表示式tree結構,頂層root是一個AndMatchExpression,如果含有AND、OR、NOR,tree的深度就+1. 這個表示式tree會用做以後過濾記錄。
著這個過程裡會做一些簡單的等價代換的優化:
- normalizeTree 簡化AND、OR、NOT表示式:
- 如KaTeX parse error: Expected '}', got 'EOF' at end of input: AND:[{AND:{}}]簡化成$AND:[{}]
- 如KaTeX parse error: Expected '}', got 'EOF' at end of input: AND:[{AND:[], KaTeX parse error: Expected 'EOF', got '}' at position 7: AND:[]}̲]簡化成AND:[{},{},{}…]
- 如KaTeX parse error: Expected '}', got 'EOF' at end of input: NOT:{NOT:{}},簡化成{}
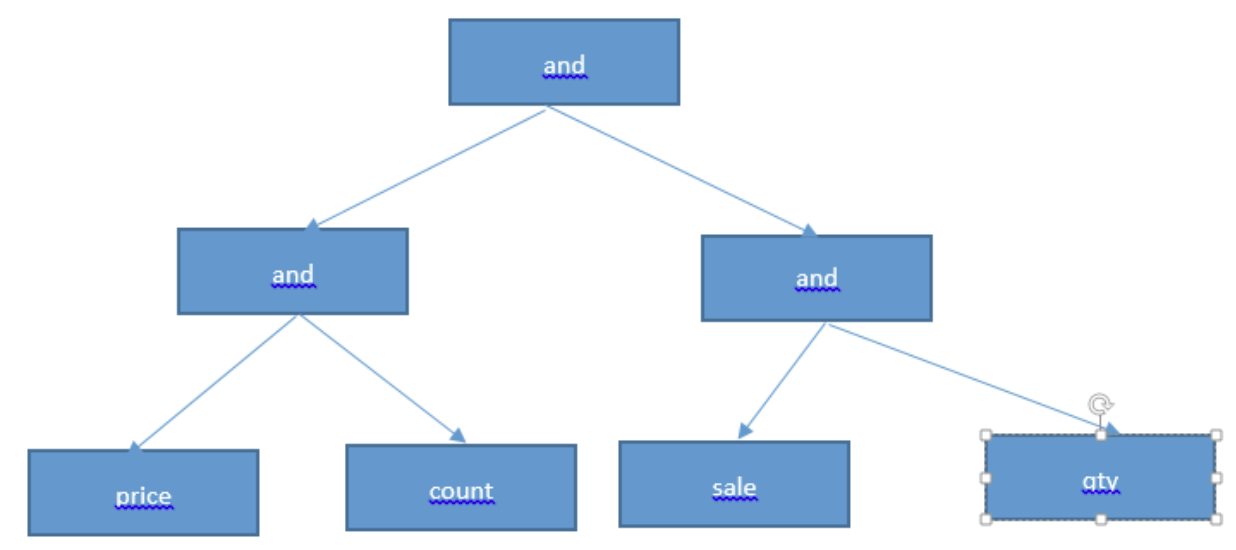 (圖片來自於網路)
(圖片來自於網路)
-
sortTree : 將AND、OR表示式簡化排序,並且擦除相同邏輯表示式
-
這裡有個點待確認,MatchExpression後會做常量替換,比如a>2+(3*4)轉換成a>14,具體程式碼沒有定位 ??
2.2 生成執行計劃 Plan
Find/Update/Delete通過.explain()函式可以列印Query生成的執行計劃, explain(“executionStats”)會列印更多的統計資訊。
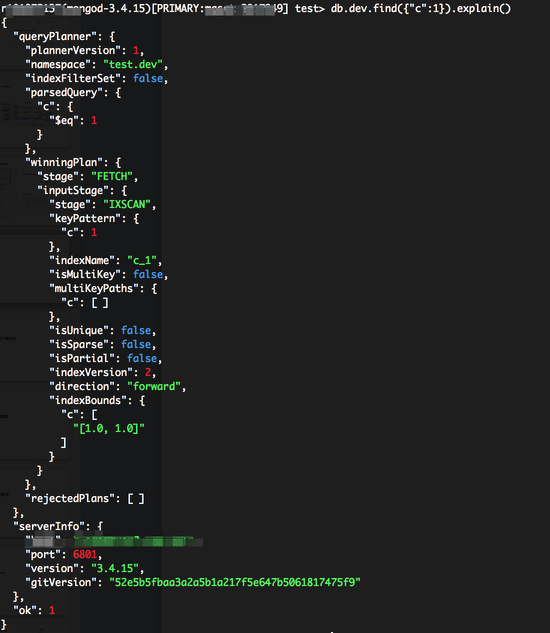
上圖中比較關鍵的資訊:
- parsedQuery : 對應filter過濾條件
- winningPlan : 最後生成的唯一的plan或者經過Optimizer選擇最優的
- stage : 執行計劃中每一個操作,後續會介紹。
- keyPattern : 用到的索引和基本屬性等
- indexBounds : 要掃描索引的邊界,這裡是等值。
- rejectedPlans : 被Optimizer放棄的執行計劃,結構和上述類似。
在生成執行計劃之前,這裡有一些短路的優化。針對Oplog掃描場景(oplogReplay)和_id主鍵查詢做了特例化,如果是oplogReplay則直接生成按ts欄位的CollectionScan。如果是主鍵等值查詢,則生成IDHack,直接查詢主鍵。生成執行的過程,本質上是通過Query的查詢條件去匹配對應collection上的索引,然後根據相關性生成不同索引組合的不同執行路徑,每一個索引規則都可能對應一個執行計劃,或者是全表掃描CollectionScan 這裡選取索引有個規則:
1). 如果查詢帶_id主鍵索引,這直接選主鍵索引
2). 優先走覆蓋索引,即查詢條件帶該索引,並且projection運算元下只選擇該field的資料(不用二次fetch資料)
3). 如果既有唯一索引和普通索引,則優先使用該唯一索引(此處猜測應該是唯一索引命中概率更高,因為同一條記錄只出現一次)
4). 如果都是唯一索引,則first win(此處測試應該是按index name做了排序)
5). 如果都是普通索引或者索引之間有覆蓋,則會根據多個索引生成多個執行路徑,並生成多個執行計劃。
所以生成執行計劃其實就是 匹配各個索引,然後按照這個索引的訪問方式,生成訪問資料的各個步驟,最終得到資料 。如果最終生成了多個Plan,則讓Optimizer去選。
3 Plan Optimizer
優化器是一個很大的話題,各個傳統資料庫和NewSQL在這個地方都下了不少功夫,甚至說優化器的好壞直接決定了查詢效能。本文不在這裡介紹過多的優化器知識,涵蓋太廣。MongoDB使用了一種類似CBO(cost based optimizer)的優化策略(同類型的還有RBO和HBO)。但和傳統的MySQL的CBO有些不太一樣,MySQL會採集一些引擎層索引的stats資訊,如條數、cardinality(稀疏度)等,然後根據stats估算執行計劃代駕。MongoDB Optimizer在評估時會touch資料,獲得一個執行時資訊再去結合估算,進行Plan的打分,得分最高的就是最優的。
Optimizer分為logical邏輯優化和physical物理優化,邏輯優化在上面CanonicalQuery時已經做了,這裡只涉及物理優化。Optimizer會把所有的Plan都執行一小部分資料,在執行終會統計掃描次數、獲得結果次數等stats指標,然後根據該指標進行score計算,核心的幾個步驟如下:
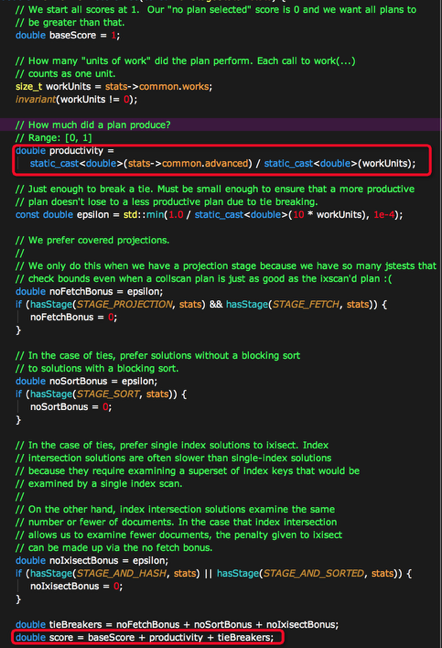
- 如果執行過程中遇到了IS_EOF(Exector的一個表示,表示該步驟結束了,沒有資料量),則score變成一個很大的值。
- 如果執行的運算元裡面不包含PROJECTION、AND_HASH、FETCH、SORT等高階操作,則增加少量
Bounes加分。 - 計算productivity,該值由
fetched/workUnits得來是一個小於1的百分比,即獲得有效的記錄數/總共掃描的記錄數。意義就是掃了一部分資料之後,有效資料的佔比。佔比越大,證明索引被讀取的價值就越高。
所以最後score為:
score = 1 + productivity + noFetchBonus + noSortBonus + noIxisectBonus + isEOFBonus
選出的Plan會進入PlanCache下次同樣QueryShape的語句,會命中cache。這裡cache即使命中了,也不是完全無代價,是要去碰資料再去evaluate一次,如果猜測準確,則繼續使用cached plan。
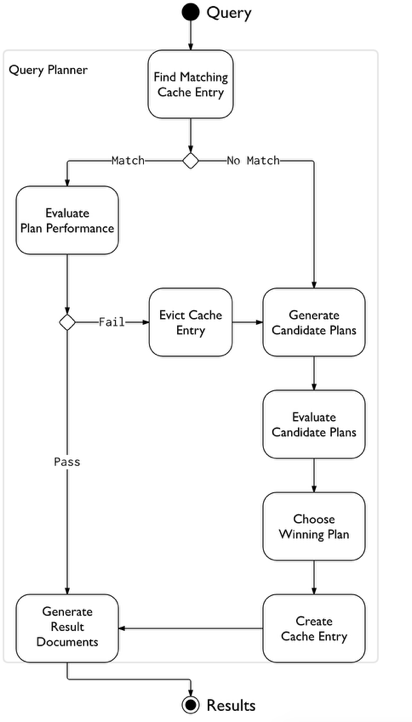
4. 優化器的一點想法
1). Optimizer採用touch資料的方式,預設配置下,最少掃描100次結果,最大掃描max(10000, colletion_total_records * 0.3)次索引,在某些命中率很低的場景下,對IO和資料量的影響還是很大。雖然後PlanCache能減少同一QueryShape的開銷,但是PlanCache邏輯中本身同樣也要touch小部分資料,開銷還是有的。而且如果PlanCache的結果有可能已經不在適合當前查詢,比如資料的分佈已經有了不小的變化,這時候是需要等到觸發replan的條件或者DDL的invalidate cache。
當然這麼做也有自己的道理,實現相對簡單,儲存引擎和server之間不用互訪Index的分佈資料,也省去了維護cardinality準確性的代價。
2). 現在優化器score機制本質上還是Produtivity影響最大,該指標反應的Index掃描和Index讀取效率方面。其實還有很多方面可以考慮,比如Index 的記憶體佔用開銷,掃描時btree遍歷比較的cpu開銷(int型別一定比string型別小,不過Mongo的Index是無型別的),也應該計算在讀取開銷內。或者是類似MySQL 8 的新機制,如果page在buffer pool已經存在,則優先選,這樣可以選擇儘量都在記憶體裡已經存在的Index,減少IO的開銷。
One More Thing~
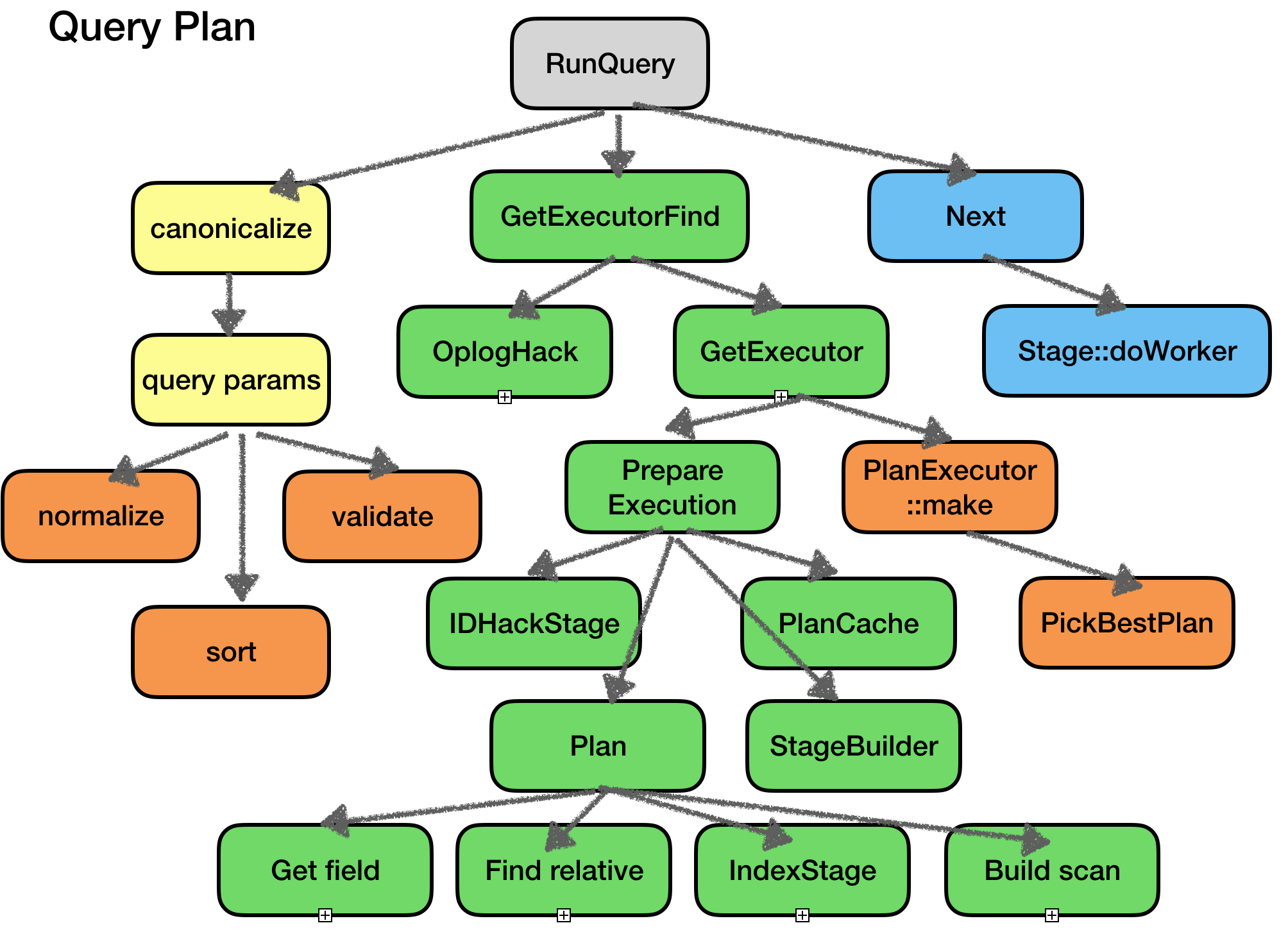
喜歡擼程式碼的朋友可以根據下圖只接索引程式碼,有針對性的去看細節:
橙色的是Optimizer相關的,綠色是執行計劃相關的,藍色時執行器相關的(後面文章會介紹)