
深度學習:影象處理概述
阿新 • • 發佈:2018-12-12
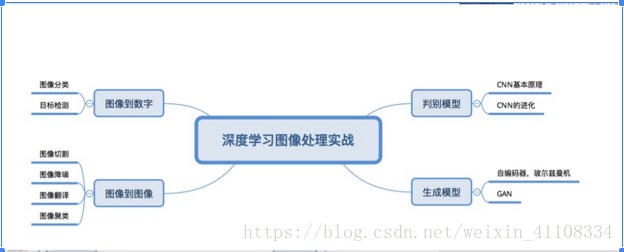
一、影象分類 cnn
二、影象-目標檢測 rcnn YOLO演算法根式實現了快速實時的物體檢測
三、影象切割 U型網路粉墨登場 加入了maxpooling的反過程升維取樣
四、以圖搜圖 聚類
五、降噪 和恢復影象 gan 對抗學習
六、影象風格遷移 cycleGan 影象翻譯
七、在噪聲裡生成圖片來 依然是GAN,而且是最基礎的卷積GAN (DCGAN)就可以給你幹出來
計算機視覺:典型的技術路線是:目標分割 ——>目標檢測 ——>目標識別 ——>目標跟蹤
粗略的理解:
目標分割:畫素級的對前景與背景進行分類,將背景剔除;
目標檢測:定位目標,確定目標位置及大小;
目標識別:定性目標,確定目標是什麼;
目標跟蹤:追蹤目標運動軌跡。
舉個栗子,如:需要對視訊中的小明進行跟蹤,處理過程將經歷如下過程:
(1)首先,採集第一幀視訊影象,因為人臉部的膚色偏黃,因此可以通過顏色特徵將人臉與背景分割出來(目標分割);
(2)分割出來後的影象有可能不僅僅包含人臉,可能還有部分環境中顏色也偏黃的物體,此時可以通過一定的形狀特徵將影象中所有的人臉準確找出來,確定其位置及範圍(目標檢測);
(3)接下來需將影象中的所有人臉與小明的人臉特徵進行對比,找到匹配度最好的,從而確定哪個是小明(目標識別);
(4)之後的每一幀就不需要像第一幀那樣在全圖中對小明進行檢測,而是可以根據小明的運動軌跡建立運動模型,通過模型對下一幀小明的位置進行預測,從而提升跟蹤的效率(目標跟蹤)