
深度學習:YOLO系列
一、YOLO v1 (CVPR2016, oral)
(You Only Look Once: Unified, Real-Time Object Detection)
可參考文章:https://zhuanlan.zhihu.com/p/27029015
Faster R-CNN的方法目前是主流的目標檢測方法,但是速度上並不能滿足實時的要求。YOLO一類的方法慢慢顯現出其重要性,這類方法使用了迴歸的思想,利用整張圖作為網路的輸入,直接在影象的多個位置上回歸出這個位置的目標邊框,以及目標所屬的類別。
我們直接看上面YOLO的目標檢測的流程圖:
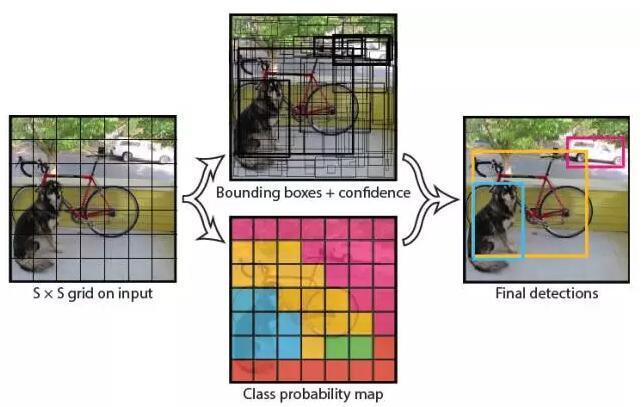
(1) 給個一個輸入影象,首先將影象劃分成7*7的網格
(2) 對於每個網格,我們都預測2個邊框(包括每個邊框是目標的置信度以及每個邊框區域在多個類別上的概率)
(3) 根據上一步可以預測出7*7*2個目標視窗,然後根據閾值去除可能性比較低的目標視窗,最後非極大值抑制NMS去除冗餘視窗即可。
可以看到整個過程非常簡單,不再需要中間的Region Proposal找目標,直接回歸便完成了位置和類別的判定。
小結:YOLO將目標檢測任務轉換成一個迴歸問題,大大加快了檢測的速度,使得YOLO可以每秒處理45張影象。而且由於每個網路預測目標視窗時使用的是全圖資訊,使得false positive比例大幅降低(充分的上下文資訊)。
7*7*30:5+5+20

檢測流程
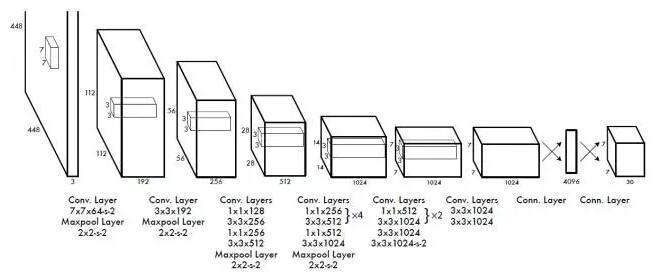
- 1、網路結構設計,預訓練 imagenet,影象resize,offset歸一化,leaky relu ,網路輸出,7*7*30張量 7*7*(2*5+20)=1470
2個bbox 的 一個(confidence)+4個座標(x,y,w,h) +20個類的概率值---------》輸出result class x ,y w,h ,predict
- 2、網路訓練:每個bbox 的是否含有物體confidence值:

對於每個類的confidence (條件概率): ![]()
- 3、loss fuction :均方和誤差, 分為三個 corrderror,iouerror,classerror ,對於三個的貢獻值不同
c帽 w帽 h帽 p帽 真實標註值

修正3個貢獻值不同:1 ![]() 修正coorderror , 2 noobji=0.5 包含物體,不包含物體,若相同 不含的confidence=0 放大含的con值,對相等的誤差,大物體的誤差對檢測的影響應小於物體小的誤差對檢測的影響
修正coorderror , 2 noobji=0.5 包含物體,不包含物體,若相同 不含的confidence=0 放大含的con值,對相等的誤差,大物體的誤差對檢測的影響應小於物體小的誤差對檢測的影響
但是YOLO也存在問題:沒有了Region Proposal機制,只使用7*7的網格迴歸會使得目標不能非常精準的定位,這也導致了YOLO的檢測精度並不是很高。
程式碼難點解析:輸出之後 7*7*30 張量後,github yolo tensorflow

confident * predict 求出最大值。過濾掉0值。 遍歷 再用過濾,非極大值抑制,求出檢測結果
![]()
---

YOLO 缺陷:
1.YOLO對相互靠的很近的物體(挨在一起且中點都落在同一個格子上的情況),還有很小的群體 檢測效果不好,這是因為一個網格中只預測了兩個框,並且只屬於一類。
2.測試影象中,當同一類物體出現的不常見的長寬比和其他情況時泛化能力偏弱。
3.由於損失函式的問題,定位誤差是影響檢測效果的主要原因,尤其是大小 物體的處理上,還有待加強
yolo v2 沒有整理完全。
二、yolo v2 YOLOv2的論文全名為YOLO9000: Better, Faster, Stronger,cvpr 2017
參考:https://zhuanlan.zhihu.com/p/35325884
在這篇文章中,作者首先在YOLOv1的基礎上提出了改進的YOLOv2,然後提出了一種檢測與分類聯合訓練方法,使用這種聯合訓練方法在COCO檢測資料集和ImageNet分類資料集上訓練出了YOLO9000模型,其可以檢測超過9000多類物體。所以,這篇文章其實包含兩個模型:YOLOv2和YOLO9000,不過後者是在前者基礎上提出的,兩者模型主體結構是一致的。YOLOv2相比YOLOv1做了很多方面的改進,這也使得YOLOv2的mAP有顯著的提升,並且YOLOv2的速度依然很快,保持著自己作為one-stage方法的優勢,YOLOv2和Faster R-CNN, SSD等模型的對比如圖1所示。這裡將首先介紹YOLOv2的改進策略,並給出YOLOv2的TensorFlow實現過程,然後介紹YOLO9000的訓練方法。近期,YOLOv3也放出來了,YOLOv3也在YOLOv2的基礎上做了一部分改進,我們在最後也會簡單談談YOLOv3所做的改進工作。
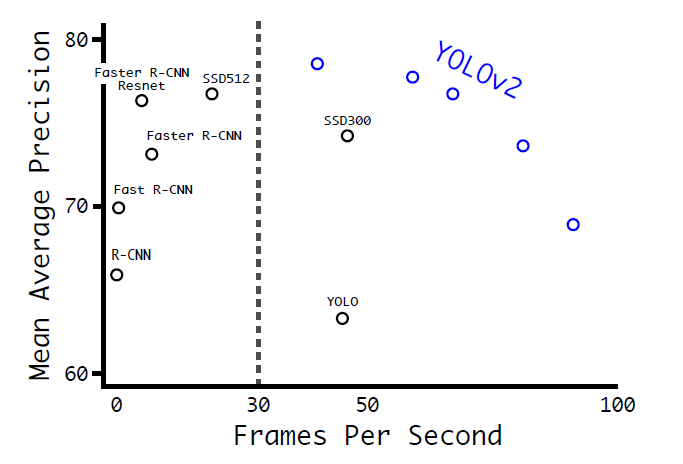
圖1:YOLOv2與其它模型在VOC 2007資料集上的效果對比
YOLOv2的改進策略
YOLOv1雖然檢測速度很快,但是在檢測精度上卻不如R-CNN系檢測方法,YOLOv1在物體定位方面(localization)不夠準確,並且召回率(recall)較低。YOLOv2共提出了幾種改進策略來提升YOLO模型的定位準確度和召回率,從而提高mAP,YOLOv2在改進中遵循一個原則:保持檢測速度,這也是YOLO模型的一大優勢。YOLOv2的改進策略如圖2所示,可以看出,大部分的改進方法都可以比較顯著提升模型的mAP。下面詳細介紹各個改進策略。
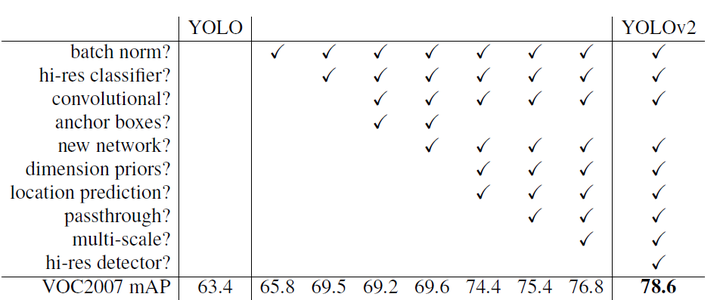
圖2:YOLOv2相比YOLOv1的改進策略
- Batch Normalization
Batch Normalization可以提升模型收斂速度,而且可以起到一定正則化效果,降低模型的過擬合。在YOLOv2中,每個卷積層後面都添加了Batch Normalization層,並且不再使用droput。使用Batch Normalization後,YOLOv2的mAP提升了2.4%。
- High Resolution Classifier
imagenet上的預訓練,在微調,影象大小。
目前大部分的檢測模型都會在先在ImageNet分類資料集上預訓練模型的主體部分(CNN特徵提取器),由於歷史原因,ImageNet分類模型基本採用大小為 的圖片作為輸入,解析度相對較低,不利於檢測模型。所以YOLOv1在採用
分類模型預訓練後,將解析度增加至
,並使用這個高解析度在檢測資料集上finetune。但是直接切換解析度,檢測模型可能難以快速適應高解析度。所以YOLOv2增加了在ImageNet資料集上使用
輸入來finetune分類網路這一中間過程(10 epochs),這可以使得模型在檢測資料集上finetune之前已經適用高解析度輸入。使用高解析度分類器後,YOLOv2的mAP提升了約4%。
- Convolutional With Anchor Boxes
在YOLOv1中,輸入圖片最終被劃分為 網格,每個單元格預測2個邊界框。YOLOv1最後採用的是全連線層直接對邊界框進行預測,其中邊界框的寬與高是相對整張圖片大小的,而由於各個圖片中存在不同尺度和長寬比(scales and ratios)的物體,YOLOv1在訓練過程中學習適應不同物體的形狀是比較困難的,這也導致YOLOv1在精確定位方面表現較差。YOLOv2借鑑了Faster R-CNN中RPN網路的先驗框(anchor boxes,prior boxes,SSD也採用了先驗框)策略。RPN對CNN特徵提取器得到的特徵圖(feature map)進行卷積來預測每個位置的邊界框以及置信度(是否含有物體),並且各個位置設定不同尺度和比例的先驗框,所以RPN預測的是邊界框相對於先驗框的offsets值(其實是transform值,詳細見Faster R_CNN論文),採用先驗框使得模型更容易學習。所以YOLOv2移除了YOLOv1中的全連線層而採用了卷積和anchor boxes來預測邊界框。為了使檢測所用的特徵圖解析度更高,移除其中的一個pool層。在檢測模型中,YOLOv2不是採用
圖片作為輸入,而是採用
大小。因為YOLOv2模型下采樣的總步長為
,對於
大小的圖片,最終得到的特徵圖大小為
,維度是奇數,這樣特徵圖恰好只有一箇中心位置。對於一些大物體,它們中心點往往落入圖片中心位置,此時使用特徵圖的一箇中心點去預測這些物體的邊界框相對容易些。所以在YOLOv2設計中要保證最終的特徵圖有奇數個位置。對於YOLOv1,每個cell都預測2個boxes,每個boxes包含5個值:
,前4個值是邊界框位置與大小,最後一個值是置信度(confidence scores,包含兩部分:含有物體的概率以及預測框與ground truth的IOU)。但是每個cell只預測一套分類概率值(class predictions,其實是置信度下的條件概率值),供2個boxes共享。YOLOv2使用了anchor boxes之後,每個位置的各個anchor box都單獨預測一套分類概率值,這和SSD比較類似(但SSD沒有預測置信度,而是把background作為一個類別來處理)。
使用anchor boxes之後,YOLOv2的mAP有稍微下降(這裡下降的原因,我猜想是YOLOv2雖然使用了anchor boxes,但是依然採用YOLOv1的訓練方法)。YOLOv1只能預測98個邊界框( ),而YOLOv2使用anchor boxes之後可以預測上千個邊界框(
)。所以使用anchor boxes之後,YOLOv2的召回率大大提升,由原來的81%升至88%。
- Dimension Clusters
在Faster R-CNN和SSD中,先驗框的維度(長和寬)都是手動設定的,帶有一定的主觀性。如果選取的先驗框維度比較合適,那麼模型更容易學習,從而做出更好的預測。因此,YOLOv2採用k-means聚類方法對訓練集中的邊界框做了聚類分析。因為設定先驗框的主要目的是為了使得預測框與ground truth的IOU更好,所以聚類分析時選用box與聚類中心box之間的IOU值作為距離指標:
圖3為在VOC和COCO資料集上的聚類分析結果,隨著聚類中心數目的增加,平均IOU值(各個邊界框與聚類中心的IOU的平均值)是增加的,但是綜合考慮模型複雜度和召回率,作者最終選取5個聚類中心作為先驗框,其相對於圖片的大小如右邊圖所示。對於兩個資料集,5個先驗框的width和height如下所示(來源:YOLO原始碼的cfg檔案):
COCO: (0.57273, 0.677385), (1.87446, 2.06253), (3.33843, 5.47434), (7.88282, 3.52778), (9.77052, 9.16828)
VOC: (1.3221, 1.73145), (3.19275, 4.00944), (5.05587, 8.09892), (9.47112, 4.84053), (11.2364, 10.0071)
但是這裡先驗框的大小具體指什麼作者並沒有說明,但肯定不是畫素點,從程式碼實現上看,應該是相對於預測的特徵圖大小( )。對比兩個資料集,也可以看到COCO資料集上的物體相對小點。這個策略作者並沒有單獨做實驗,但是作者對比了採用聚類分析得到的先驗框與手動設定的先驗框在平均IOU上的差異,發現前者的平均IOU值更高,因此模型更容易訓練學習。
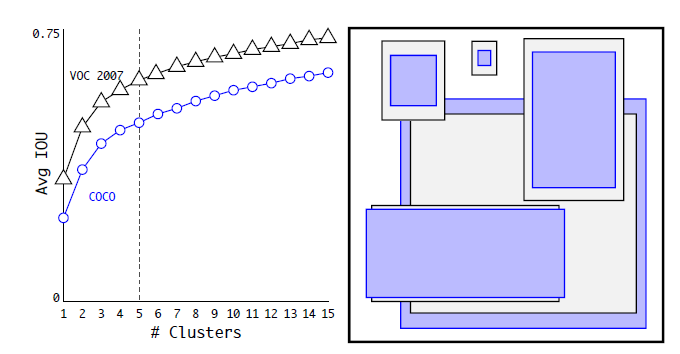
圖3:資料集VOC和COCO上的邊界框聚類分析結果