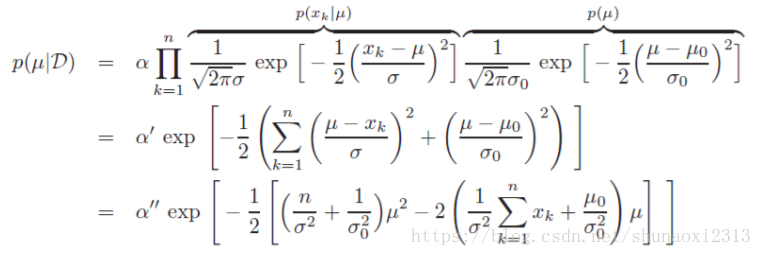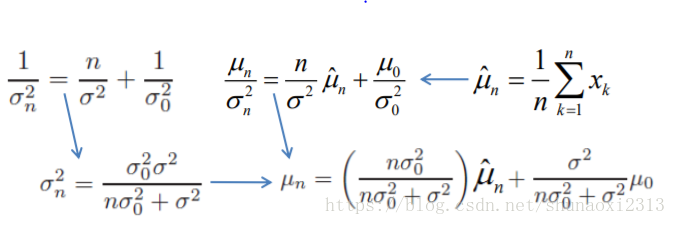最大似然和貝葉斯引數估計
阿新 • • 發佈:2018-12-12
引數估計是指已知分類器結構或函式形式,從訓練樣本中估計引數。以貝葉斯分類為例,假定概率密度分佈符合一維高斯分佈,則引數估計的任務就是根據訓練樣本估計μ和σ。常用的引數估計方法有最大似然估計和貝葉斯引數估計法。
最大似然估計
假設引數為確定值,根據似然度最大進行最優估計。
給定樣本資料下標代表類別。假設每類樣本獨立同分布(萬年不變的假設),用來估計,即給每個類列一個判別函式,用該類的樣本來估計該類判別函式的引數。
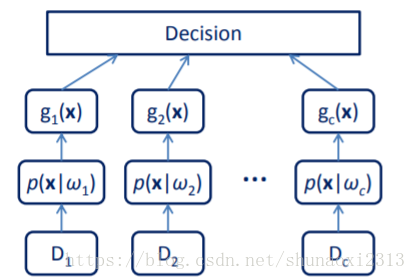
這裡需要理解一點:做貝葉斯決策時,最關鍵的是求概率密度函式,從而獲得每個類的判別函式(見上圖)。即估計中帶有的引數,它們分佈在另一個線性空間。注意區分特徵空間和引數空間。
為了估計引數,需要如下幾個步驟:
- 求似然(Likelihood)
注意,上面這個式子針對的已經是具體的類別了,不要問引數去哪了。另外,這裡的n代表樣本數目,要和前面的類別數目c區分開。這個式子很好理解,即出現我們當前觀測到的樣本概率,求使它最大化的引數即可。 - 最大化似然
這個梯度是在p維引數空間求解,即 - 求解梯度。可求解析解或梯度下降。(常用Log-Likelihood,易求解)
這裡插一句高斯分佈最大似然估計的結果(因為比較常用),具體推導不做說明。
一維情況:
多維情況:
貝葉斯引數估計
引數被視為隨機變數,估計其後驗分佈
貝葉斯引數估計和最大似然一樣,要用一類的資料估計引數的分佈。它假定已知和,來預測。為求,帶入具體類別w後即轉換為求。由公式:
把和聯絡起來,便與求解。公式第二步到第三步是因為測試樣本x和訓練樣本D的選取是獨立的(要是這樣的話,p(x|D)豈不是直接就可以寫成p(x)了?想了一下,覺得寫成p(x|D)並不重要,重要的是引出引數θ的後驗概率,從而將其與類條件概率密度聯絡起來)。
以高斯密度函式為例,考慮一維情況。為了預測,寫成:
是常數項。因為(假設已知),,公式展開:
與μ無關的因子都被歸入中。可見仍符合高斯分佈,對照形式可得
當n趨於無窮大,等於。由