
Apache Pulsar——企業級訊息訂閱系統介紹
Apache Pulsar是一款由雅虎開發的類似於Kafka的企業級訊息訂閱系統,在2016將其開源,由Apach基金會孵化,現在已經成長為Apache基金會的頂級專案。Pulsar在雅虎內部已經運行了三年,服務於眾多的應用,主要有雅虎郵箱、雅虎財務系統、雅虎運動、Flickr、Gemini廣告平臺以及雅虎分散式鍵值對儲存系統Sherpa等。
Pulsar相關概念。
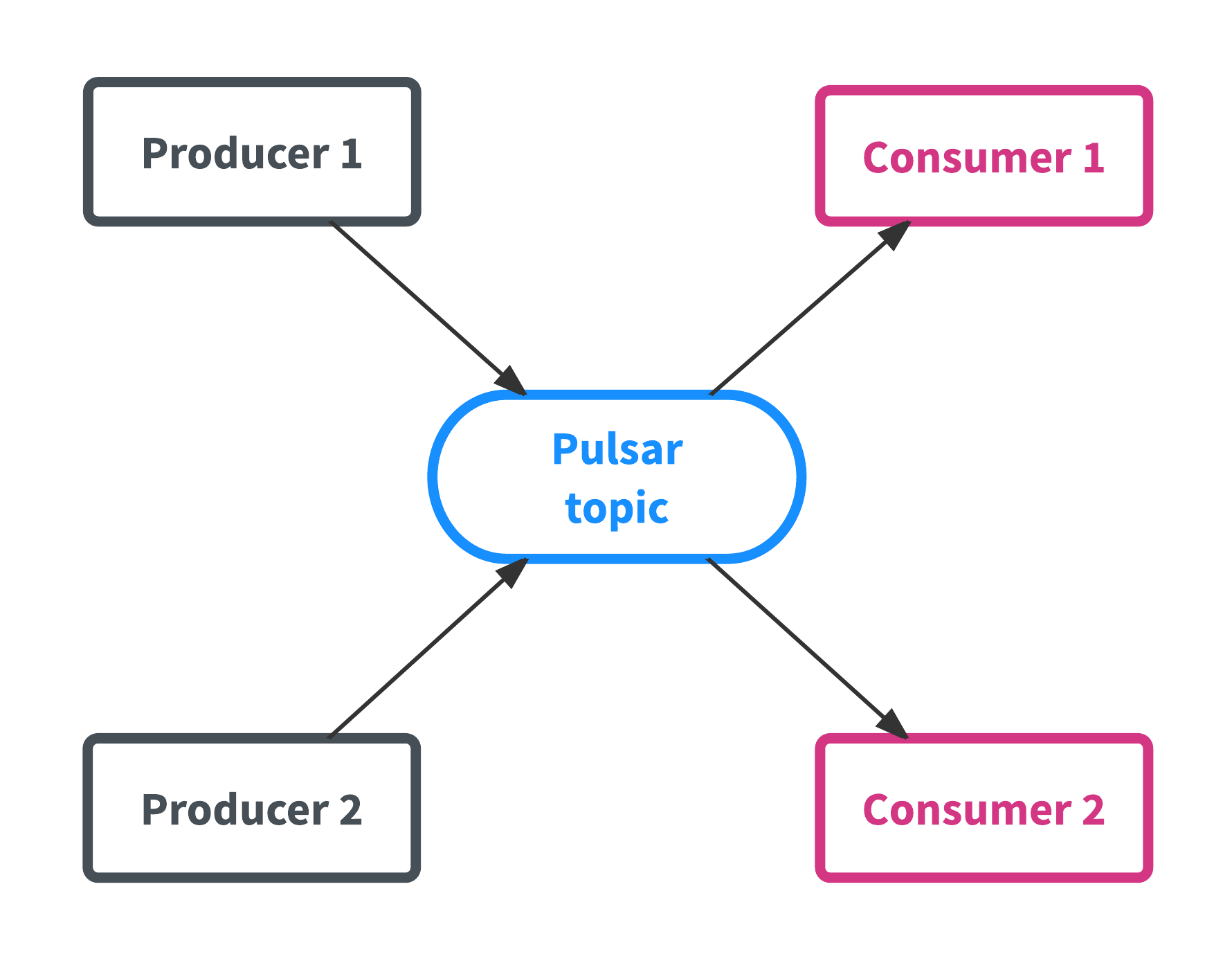
為Pulsar提供資料的應用叫做生產者,而從Pulsar消費資料的應用被稱為消費者,有時也稱為訂閱者。主題Topic是Pulsar的核心資源,這個和Kafka有點類似。主題Topic就像一個管道,生產者往裡面寫資料,而消費者消費裡面的資料。這是Pulsar的特性1,如下圖所示:
Pulsar一開始建立時就支援多租戶的使用場景。為了支援多租用的功能,Pulsar包含兩種資源,分別是“properties”和“namespaces”。property(資產)代表系統中的租戶。舉個例子,假設部署一個Pulsar叢集支援各種各樣的應用(就像Pulsar在雅虎公司一樣),在Pulsar叢集中,每一個資產代表企業中的一個團隊,一個核心功能或者一條產品線。每個屬性依次包含若干個namespace,例如一個namespace對應每個應用或者使用場景。一個namespace可以包含任意多個主題topic。總的來說,一個Pulsar叢集包含多個資產property,一個資產property包含多個namespace,一個namespace包含多個主題topic。Pulsar叢集、Property資產、Namespace和主題topic的關係圖如下圖所示:
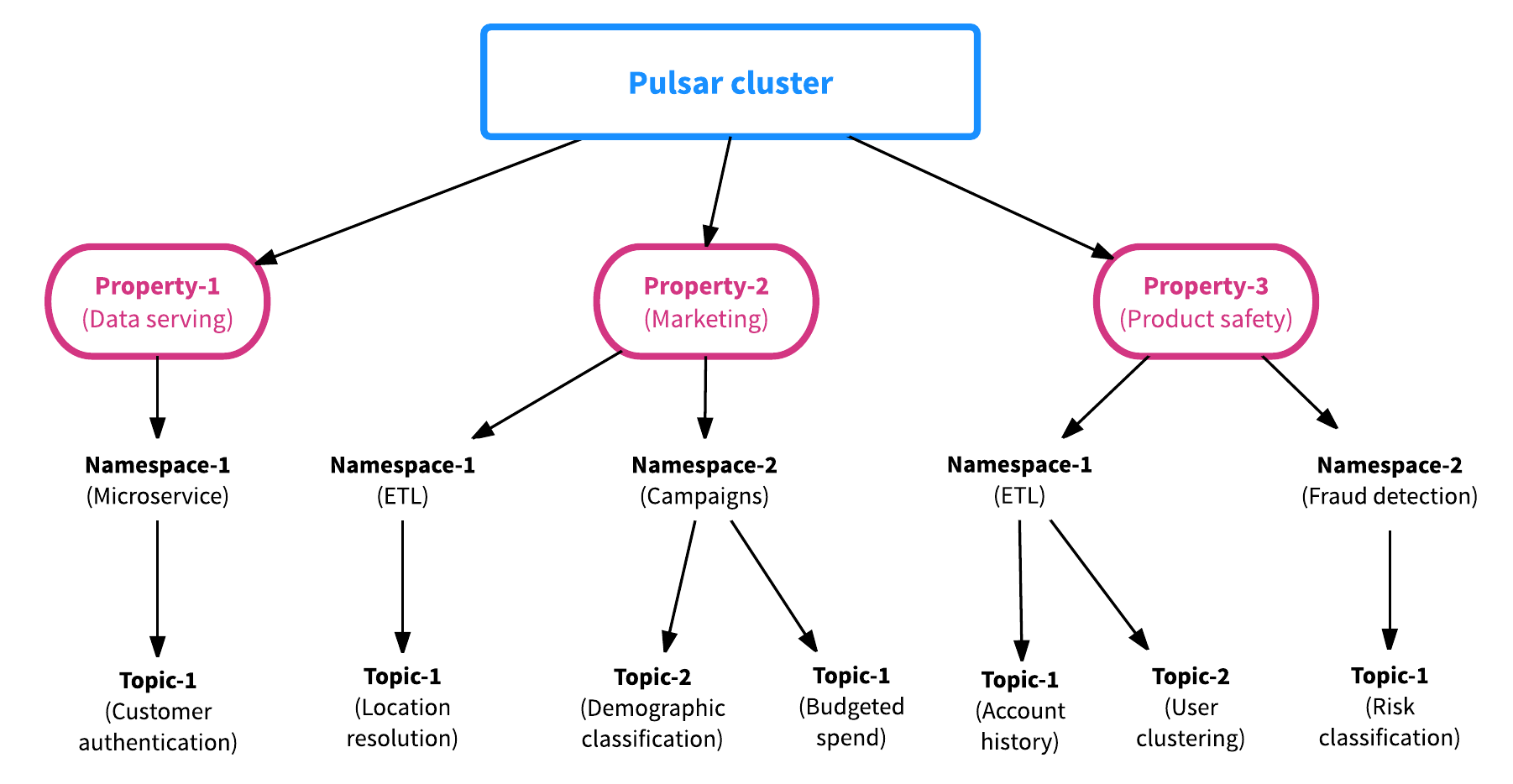
namespace是Pulsar中最基本的管理單元,在namespace這一層面,可以設定許可權,調整副本設定,管理跨叢集的訊息複製,控制訊息策略和執行關鍵操作。一個主題topic可以繼承其所對應的namespace的屬性,因此我們只需對namespace的屬性進行設定,就可以一次性設定該namespace中所有主題topic的屬性。
namespace有兩種,分別是本地的namespace和全域性的namespace:
- 本地namespace——僅對定義它的叢集可見。
- 全域性namespace——跨叢集可見,可以是同一個資料中心的叢集,也可以是跨地域中心的叢集,這依賴於是否在namespace中設定了跨叢集拷貝資料的功能。
雖然本地namespace和全域性namespace的作用域不同,但是隻要對他們進行適當的設定,都可以跨團隊和跨組織共享。一旦生產者獲得了namespace的寫入許可權,那麼它就可以往namespace中的所有topic主題寫入資料,如果某個主題不存在,則在生產者第一次寫入資料時動態建立。
之前提到過,每個namespace會一個或多個主題topic,每個主題會被多個消費者訂閱,每個訂閱者會從其所訂閱的主題topic釋出的所有訊息中檢索和接收資料。為了給每個應用增加更多的靈活性,Pulsar支援三種不同的型別的訂閱,並且它們可以在同一個主題topic中共存:
- 獨享型訂閱(Exclusive subscription)——這種型別的訂閱在任何時候都只能有一個消費者。
- 共享型訂閱(Share subscription)——多個消費者消費同一個主題topic的資料,每個消費者會接收到一小部分資料。
- 失效型訂閱(Failover subscription)——多個消費者連線到一個主題topic,但是隻有一個消費者能接收資料,其他消費者只有在當前消費者失效之後才會開始接收資料。
Pulsar提供三種不同型別的訂閱subscriptions。subscription提供一個最重要的功能就是解耦訊息的生產和消費。通過支援不同型別的subscription,無需增加開發的複雜度就可以增強應用的彈性。下圖展現了三種不同型別的訂閱:

資料分割槽
topic主題中的資料有時會很小,小到幾KB,有時會很大,大道幾十TB。這意這意味著主題topic需要具備在某些情況下保持穩定的低吞吐量,在另一些情況下保持非常高的吞吐量的能力,這取決於使用者的數量。因此,當一個主題需要高吞吐率而例外一個主題需要低吞吐率時,會發生什麼呢?為了解決該問題Pulsar允許你當將一個主題topic中的資料分成不同的區域然後儲存在不同的機器中。這就是Pulsar的分割槽功能。
對於處理跨多個節點的大量資料,使用分割槽是一個非常普通的做法,同時還可以實現高吞吐率。預設情況下,建立的主題topic是沒有分割槽的,但是建立有分割槽的主題topic也很容易,使用簡單的CLI命令或者通過呼叫API,並且指定分割槽數量即可。
當你建立有分割槽的主題時,Pulsar自動將資料分割槽,確保消費者和生產者與分割槽無關。對一個還沒分割槽但是已經寫入資料的主題進行分割槽之後,無需對原來的程式碼進行修改,即可繼續將資料寫入該主題topic。也就是說分割槽和應用無關
Pulsar使用一個叫做broker的程序來處理主題的分割槽,Pulsar叢集中的每個節點都執行一個自己的broker程序,下圖顯示了broker節點如何如果處理分割槽的細節。
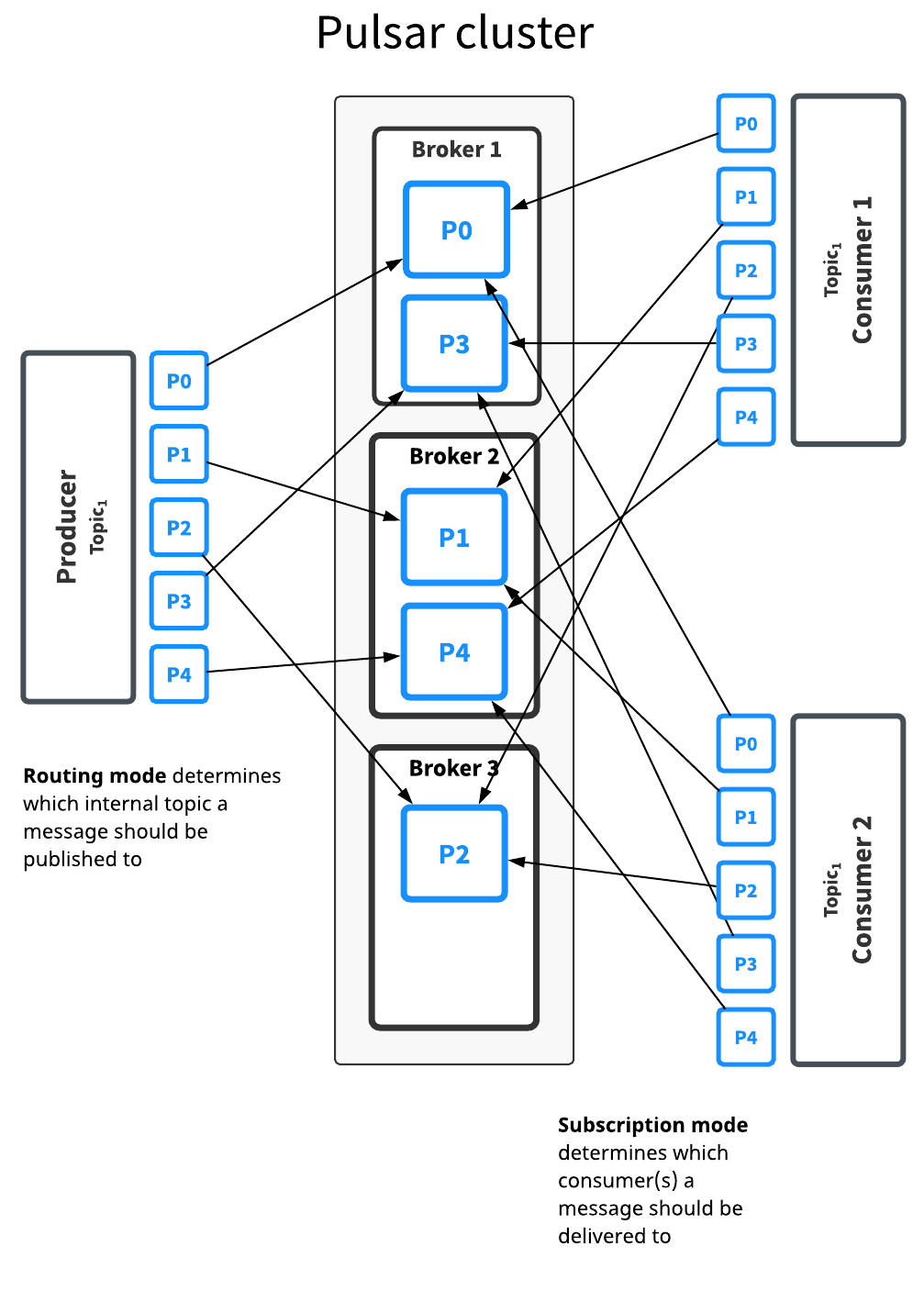
應用程式無需修改程式碼即可使用分割槽的優點,Pulsar還額外提供了一些hooks讓資料在不同分割槽和不同消費者之間的分佈能達到最佳的效果。Pulsar提供四種不同的路由策略,根據你選擇的路由策略決定資料是如何路由到指定的分割槽。四種分割槽策略如下:
- Single partitioning(單一分割槽):生產者隨機獲取一個分割槽,並將資料寫入到該分割槽。該模式和無分割槽主題提供一樣的保證,但是對多個生產者寫入資料到主題topic的場景非常有用。
- Round robin partitioning(輪詢排程分割槽):在該應用場景,生產者將資料均勻的分佈到所有的分割槽,第一條訊息寫入到第一個分割槽,第二條訊息寫入到第二個分割槽,以此類推。
- Hash partitioning(雜湊分割槽):在該應用場景下是如何選擇分割槽接入資料的呢?每條訊息都有一個key,然後對key呼叫雜湊函式生成一個雜湊值,根據該值來選擇訊息要寫入的分割槽。雜湊分割槽保證訊息的按照key的順序分佈。
- Custom partitioning(自定義分割槽):生產者使用自定義的函式接收訊息並生成分割槽號,下次直接寫入對應的分割槽中,自定義分割槽模式保證應用程式完全控制分割槽邏輯。
資料永續性
一旦Pulsar broker接收並確認資料是來自生成者寫入到主題topic中的,它需要保證資料在任何情況下都不丟失,不像其他的訊息管理系統,Pulsar使用Apache BookKeeper提供的低延遲持久化儲存特性保證資料的永續性。一旦Pulsar接收到資料,它會資料傳送到多個BookKeeper節點,接收到資料的BookKeeper節點會資料寫入到記憶體和預寫日誌(write-ahead log)中。在對資料確認之前會強制將日誌寫入到持久化儲存裝置中。通過將資料寫入到儲存裝置中,即使出現斷電的情況,資料也不會丟失。只有當資料寫入到大多數的BookKeeper節點中,Pulsar才會傳送確認訊息給生產者。
關注本人的公眾號獲取更多關於大資料和機器學習方面的知識
