
Apache Hadoop最全生態系統介紹
阿新 • • 發佈:2019-01-29
下面詳細介紹生態系統的組成。
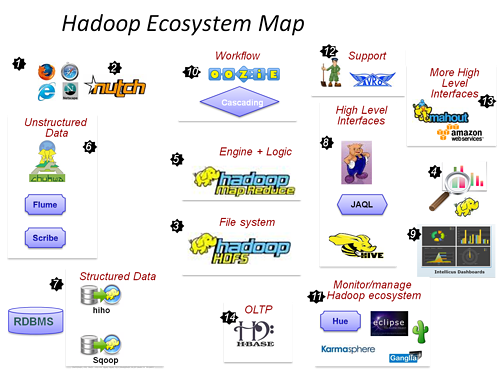
1. HDFS
HDFS(Hadoop Distributed File System,Hadoop分散式檔案系統)是Hadoop體系中資料儲存管理的基礎。它是一個高度容錯的系統,能檢測和應對硬體故障,用於在低成本的通用硬體上執行。HDFS簡化了檔案的一致性模型,通過流式資料訪問,提供高吞吐量應用程式資料訪問功能,適合帶有大型資料集的應用程式。
2. MapReduce
MapReduce是一種計算模型,用以進行大資料量的計算。Hadoop的MapReduce實現,和Common、HDFS一起,構成了Hadoop發展初期的三個元件。MapReduce將應用劃分為Map和Reduce兩個步驟,其中Map對資料集上的獨立元素進行指定的操作,生成鍵-值對形式中間結果。Reduce則對中間結果中相同“鍵”的所有“值”進行規約,以得到最終結果。MapReduce這樣的功能劃分,非常適合在大量計算機組成的分散式並行環境裡進行資料處理。
3. Hive
Hive是Hadoop中的一個重要子專案,最早由Facebook設計,是建立在Hadoop基礎上的資料倉庫架構,它為資料倉庫的管理提供了許多功能,包括:資料ETL(抽取、轉換和載入)工具、資料儲存管理和大型資料集的查詢和分析能力。Hive提供的是一種結構化資料的機制,定義了類似於傳統關係資料庫中的類SQL語言:Hive QL,通過該查詢語言,資料分析人員可以很方便地執行資料分析業務。
4. HBase
Google發表了BigTable系統論文後,開源社群就開始在HDFS上構建相應的實現HBase。HBase是一個針對結構化資料的可伸縮、高可靠、高效能、分散式和麵向列的動態模式資料庫。和傳統關係資料庫不同,HBase採用了BigTable的資料模型:增強的稀疏排序對映表(Key/Value),其中,鍵由行關鍵字、列關鍵字和時間戳構成。HBase提供了對大規模資料的隨機、實時讀寫訪問,同時,HBase中儲存的資料可以使用MapReduce來處理,它將資料儲存和平行計算完美地結合在一起。
5. Pig
Pig執行在Hadoop上,是對大型資料集進行分析和評估的平臺。它簡化了使用Hadoop進行資料分析的要求,提供了一個高層次的、面向領域的抽象語言:Pig Latin。通過Pig Latin,資料工程師可以將複雜且相互關聯的資料分析任務編碼為Pig操作上的資料流指令碼,通過將該指令碼轉換為MapReduce任務鏈,在Hadoop上執行。和Hive一樣,Pig降低了對大型資料集進行分析和評估的門檻。
6. Hadoop Common
從Hadoop 0.20版本開始,原來Hadoop專案的Core部分更名為Hadoop Common。Common為Hadoop的其他專案提供了一些常用工具,主要包括系統配置工具Configuration、遠端過程呼叫RPC、序列化機制和Hadoop抽象檔案系統FileSystem等。它們為在通用硬體上搭建雲端計算環境提供基本的服務,併為執行在該平臺上的軟體開發提供了所需的API。
7. ZooKeeper
在分散式系統中如何就某個值(決議)達成一致,是一個十分重要的基礎問題。ZooKeeper作為一個分散式的服務框架,解決了分散式計算中的一致性問題。在此基礎上,ZooKeeper可用於處理分散式應用中經常遇到的一些資料管理問題,如統一命名服務、狀態同步服務、叢集管理、分散式應用配置項的管理等。ZooKeeper常作為其他Hadoop相關專案的主要元件,發揮著越來越重要的作用。
8. Avro
Avro由Doug Cutting牽頭開發,是一個數據序列化系統。類似於其他序列化機制,Avro可以將資料結構或者物件轉換成便於儲存和傳輸的格式,其設計目標是用於支援資料密集型應用,適合大規模資料的儲存與交換。Avro提供了豐富的資料結構型別、快速可壓縮的二進位制資料格式、儲存永續性資料的檔案集、遠端呼叫RPC和簡單動態語言整合等功能。
9. Mahout
Mahout起源於2008年,最初是Apache Lucent的子專案,它在極短的時間內取得了長足的發展,現在是Apache的頂級專案。Mahout的主要目標是建立一些可擴充套件的機器學習領域經典演算法的實現,旨在幫助開發人員更加方便快捷地建立智慧應用程式。Mahout現在已經包含了聚類、分類、推薦引擎(協同過濾)和頻繁集挖掘等廣泛使用的資料探勘方法。除了演算法,Mahout還包含資料的輸入/輸出工具、與其他儲存系統(如資料庫、MongoDB 或Cassandra)整合等資料探勘支援架構。
10. X-RIME
X-RIME是一個開源的社會網路分析工具,它提供了一套基於Hadoop的大規模社會網路/複雜網路分析工具包。X-RIME在MapReduce 的框架上對十幾種社會網路分析演算法進行了並行化與分散式化,從而實現了對網際網路級大規模社會網路/複雜網路的分析。它包括HDFS儲存系統上的一套適合大規模社會網路分析的資料模型、基於MapReduce實現的一系列社會網路分析分散式並行演算法和X-RIME處理模型,即X-RIME工具鏈等三部分。
11. Crossbow
Crossbow是在Bowtie和SOAPsnp基礎上,結合Hadoop的可擴充套件工具,該工具能夠充分利用叢集進行生物計算。其中,Bowtie是一個快速、高效的基因短序列拼接至模板基因組工具;SOAPsnp則是一個重測序一致性序列建造程式。它們在複雜遺傳病和腫瘤易感的基因定位,到群體和進化遺傳學研究中發揮著重要的作用。Crossbow利用了Hadoop Stream,將Bowtie、SOAPsnp上的計算任務分佈到Hadoop叢集中,滿足了新一代基因測序技術帶來的海量資料儲存及計算分析要求。
12. Chukwa
Chukwa是開源的資料收集系統,用於監控大規模分散式系統(2000+以上的節點, 系統每天產生的監控資料量在T級別)。它構建在Hadoop的HDFS和MapReduce基礎之上,繼承了Hadoop的可伸縮性和魯棒性。Chukwa包含一個強大和靈活的工具集,提供了資料的生成、收集、排序、去重、分析和展示等一系列功能,是Hadoop使用者、叢集運營人員和管理人員的必備工具。
13. Flume
Flume是Cloudera開發維護的分散式、可靠、高可用的日誌收集系統。它將資料從產生、傳輸、處理並最終寫入目標的路徑的過程抽象為資料流,在具體的資料流中,資料來源支援在Flume中定製資料傳送方,從而支援收集各種不同協議資料。同時,Flume資料流提供對日誌資料進行簡單處理的能力,如過濾、格式轉換等。此外,Flume還具有能夠將日誌寫往各種資料目標(可定製)的能力。總的來說,Flume是一個可擴充套件、適合複雜環境的海量日誌收集系統。
14. Sqoop
Sqoop是SQL-to-Hadoop的縮寫,是Hadoop的周邊工具,它的主要作用是在結構化資料儲存與Hadoop之間進行資料交換。Sqoop可以將一個關係型資料庫(例如MySQL、Oracle、PostgreSQL等)中的資料匯入Hadoop的HDFS、Hive中,也可以將HDFS、Hive中的資料匯入關係型資料庫中。Sqoop充分利用了Hadoop的優點,整個資料匯入匯出過程都是用MapReduce實現並行化,同時,該過程中的大部分步驟自動執行,非常方便。
15. Oozie
在Hadoop中執行資料處理工作,有時候需要把多個作業連線到一起,才能達到最終目的。針對上述需求,Yahoo開發了開源工作流引擎Oozie,用於管理和協調多個執行在Hadoop平臺上的作業。在Oozie中,計算作業被抽象為動作,控制流節點則用於構建動作間的依賴關係,它們一起組成一個有向無環的工作流,描述了一項完整的資料處理工作。Oozie工作流系統可以提高資料處理流程的柔性,改善Hadoop叢集的效率,並降低開發和運營人員的工作量。
16. Karmasphere
Karmasphere包括Karmasphere Analyst和Karmasphere Studio。其中,Analyst提供了訪問儲存在Hadoop裡面的結構化和非結構化資料的能力,使用者可以運用SQL或其他語言,進行即時查詢並做進一步的分析。Studio則是基於NetBeans的MapReduce整合開發環境,開發人員可以利用它方便快速地建立基於Hadoop的MapReduce應用。同時,該工具還提供了一些視覺化工具,用於監控任務的執行,顯示任務間的輸入輸出和互動等。需要注意的是,在上面提及的這些專案中,Karmasphere是唯一不開源的工具。
17.JaqlJaql 針對半結構化大資料量的查詢語言應運而生,運用Jaql 語言,程式設計師並不需要關心 MapReduce 框架原理而只需要應用更容易理解和人性化的指令碼語言。
1. HDFS
HDFS(Hadoop Distributed File System,Hadoop分散式檔案系統)是Hadoop體系中資料儲存管理的基礎。它是一個高度容錯的系統,能檢測和應對硬體故障,用於在低成本的通用硬體上執行。HDFS簡化了檔案的一致性模型,通過流式資料訪問,提供高吞吐量應用程式資料訪問功能,適合帶有大型資料集的應用程式。
2. MapReduce
MapReduce是一種計算模型,用以進行大資料量的計算。Hadoop的MapReduce實現,和Common、HDFS一起,構成了Hadoop發展初期的三個元件。MapReduce將應用劃分為Map和Reduce兩個步驟,其中Map對資料集上的獨立元素進行指定的操作,生成鍵-值對形式中間結果。Reduce則對中間結果中相同“鍵”的所有“值”進行規約,以得到最終結果。MapReduce這樣的功能劃分,非常適合在大量計算機組成的分散式並行環境裡進行資料處理。
3. Hive
Hive是Hadoop中的一個重要子專案,最早由Facebook設計,是建立在Hadoop基礎上的資料倉庫架構,它為資料倉庫的管理提供了許多功能,包括:資料ETL(抽取、轉換和載入)工具、資料儲存管理和大型資料集的查詢和分析能力。Hive提供的是一種結構化資料的機制,定義了類似於傳統關係資料庫中的類SQL語言:Hive QL,通過該查詢語言,資料分析人員可以很方便地執行資料分析業務。
4. HBase
Google發表了BigTable系統論文後,開源社群就開始在HDFS上構建相應的實現HBase。HBase是一個針對結構化資料的可伸縮、高可靠、高效能、分散式和麵向列的動態模式資料庫。和傳統關係資料庫不同,HBase採用了BigTable的資料模型:增強的稀疏排序對映表(Key/Value),其中,鍵由行關鍵字、列關鍵字和時間戳構成。HBase提供了對大規模資料的隨機、實時讀寫訪問,同時,HBase中儲存的資料可以使用MapReduce來處理,它將資料儲存和平行計算完美地結合在一起。
5. Pig
Pig執行在Hadoop上,是對大型資料集進行分析和評估的平臺。它簡化了使用Hadoop進行資料分析的要求,提供了一個高層次的、面向領域的抽象語言:Pig Latin。通過Pig Latin,資料工程師可以將複雜且相互關聯的資料分析任務編碼為Pig操作上的資料流指令碼,通過將該指令碼轉換為MapReduce任務鏈,在Hadoop上執行。和Hive一樣,Pig降低了對大型資料集進行分析和評估的門檻。
6. Hadoop Common
從Hadoop 0.20版本開始,原來Hadoop專案的Core部分更名為Hadoop Common。Common為Hadoop的其他專案提供了一些常用工具,主要包括系統配置工具Configuration、遠端過程呼叫RPC、序列化機制和Hadoop抽象檔案系統FileSystem等。它們為在通用硬體上搭建雲端計算環境提供基本的服務,併為執行在該平臺上的軟體開發提供了所需的API。
7. ZooKeeper
在分散式系統中如何就某個值(決議)達成一致,是一個十分重要的基礎問題。ZooKeeper作為一個分散式的服務框架,解決了分散式計算中的一致性問題。在此基礎上,ZooKeeper可用於處理分散式應用中經常遇到的一些資料管理問題,如統一命名服務、狀態同步服務、叢集管理、分散式應用配置項的管理等。ZooKeeper常作為其他Hadoop相關專案的主要元件,發揮著越來越重要的作用。
8. Avro
Avro由Doug Cutting牽頭開發,是一個數據序列化系統。類似於其他序列化機制,Avro可以將資料結構或者物件轉換成便於儲存和傳輸的格式,其設計目標是用於支援資料密集型應用,適合大規模資料的儲存與交換。Avro提供了豐富的資料結構型別、快速可壓縮的二進位制資料格式、儲存永續性資料的檔案集、遠端呼叫RPC和簡單動態語言整合等功能。
9. Mahout
Mahout起源於2008年,最初是Apache Lucent的子專案,它在極短的時間內取得了長足的發展,現在是Apache的頂級專案。Mahout的主要目標是建立一些可擴充套件的機器學習領域經典演算法的實現,旨在幫助開發人員更加方便快捷地建立智慧應用程式。Mahout現在已經包含了聚類、分類、推薦引擎(協同過濾)和頻繁集挖掘等廣泛使用的資料探勘方法。除了演算法,Mahout還包含資料的輸入/輸出工具、與其他儲存系統(如資料庫、MongoDB 或Cassandra)整合等資料探勘支援架構。
10. X-RIME
X-RIME是一個開源的社會網路分析工具,它提供了一套基於Hadoop的大規模社會網路/複雜網路分析工具包。X-RIME在MapReduce 的框架上對十幾種社會網路分析演算法進行了並行化與分散式化,從而實現了對網際網路級大規模社會網路/複雜網路的分析。它包括HDFS儲存系統上的一套適合大規模社會網路分析的資料模型、基於MapReduce實現的一系列社會網路分析分散式並行演算法和X-RIME處理模型,即X-RIME工具鏈等三部分。
11. Crossbow
Crossbow是在Bowtie和SOAPsnp基礎上,結合Hadoop的可擴充套件工具,該工具能夠充分利用叢集進行生物計算。其中,Bowtie是一個快速、高效的基因短序列拼接至模板基因組工具;SOAPsnp則是一個重測序一致性序列建造程式。它們在複雜遺傳病和腫瘤易感的基因定位,到群體和進化遺傳學研究中發揮著重要的作用。Crossbow利用了Hadoop Stream,將Bowtie、SOAPsnp上的計算任務分佈到Hadoop叢集中,滿足了新一代基因測序技術帶來的海量資料儲存及計算分析要求。
12. Chukwa
Chukwa是開源的資料收集系統,用於監控大規模分散式系統(2000+以上的節點, 系統每天產生的監控資料量在T級別)。它構建在Hadoop的HDFS和MapReduce基礎之上,繼承了Hadoop的可伸縮性和魯棒性。Chukwa包含一個強大和靈活的工具集,提供了資料的生成、收集、排序、去重、分析和展示等一系列功能,是Hadoop使用者、叢集運營人員和管理人員的必備工具。
13. Flume
Flume是Cloudera開發維護的分散式、可靠、高可用的日誌收集系統。它將資料從產生、傳輸、處理並最終寫入目標的路徑的過程抽象為資料流,在具體的資料流中,資料來源支援在Flume中定製資料傳送方,從而支援收集各種不同協議資料。同時,Flume資料流提供對日誌資料進行簡單處理的能力,如過濾、格式轉換等。此外,Flume還具有能夠將日誌寫往各種資料目標(可定製)的能力。總的來說,Flume是一個可擴充套件、適合複雜環境的海量日誌收集系統。
14. Sqoop
Sqoop是SQL-to-Hadoop的縮寫,是Hadoop的周邊工具,它的主要作用是在結構化資料儲存與Hadoop之間進行資料交換。Sqoop可以將一個關係型資料庫(例如MySQL、Oracle、PostgreSQL等)中的資料匯入Hadoop的HDFS、Hive中,也可以將HDFS、Hive中的資料匯入關係型資料庫中。Sqoop充分利用了Hadoop的優點,整個資料匯入匯出過程都是用MapReduce實現並行化,同時,該過程中的大部分步驟自動執行,非常方便。
15. Oozie
在Hadoop中執行資料處理工作,有時候需要把多個作業連線到一起,才能達到最終目的。針對上述需求,Yahoo開發了開源工作流引擎Oozie,用於管理和協調多個執行在Hadoop平臺上的作業。在Oozie中,計算作業被抽象為動作,控制流節點則用於構建動作間的依賴關係,它們一起組成一個有向無環的工作流,描述了一項完整的資料處理工作。Oozie工作流系統可以提高資料處理流程的柔性,改善Hadoop叢集的效率,並降低開發和運營人員的工作量。
16. Karmasphere
Karmasphere包括Karmasphere Analyst和Karmasphere Studio。其中,Analyst提供了訪問儲存在Hadoop裡面的結構化和非結構化資料的能力,使用者可以運用SQL或其他語言,進行即時查詢並做進一步的分析。Studio則是基於NetBeans的MapReduce整合開發環境,開發人員可以利用它方便快速地建立基於Hadoop的MapReduce應用。同時,該工具還提供了一些視覺化工具,用於監控任務的執行,顯示任務間的輸入輸出和互動等。需要注意的是,在上面提及的這些專案中,Karmasphere是唯一不開源的工具。
17.JaqlJaql 針對半結構化大資料量的查詢語言應運而生,運用Jaql 語言,程式設計師並不需要關心 MapReduce 框架原理而只需要應用更容易理解和人性化的指令碼語言。
18.Nutch 是一個開源Java 實現的搜尋引擎。它提供了我們執行自己的搜尋引擎所需的全部工具。包括全文搜尋和Web爬蟲。