
資料庫面試題---MySql
1、SQL的select語句完整的執行過程
SQL Select語句完整的執行順序:
1、from 子句組裝來自不同資料來源的資料; 2、where 子句基於指定的條件對記錄行進行篩選; 3、group by 子句將資料劃分為多個分組; 4、使用聚集函式進行計算; 5、使用 having 子句篩選分組; 6、計算所有的表示式; 7、select 的欄位; 8、使用 order by 對結果集進行排序。
SQL 語言不同於其他程式語言的最明顯特徵是處理程式碼的順序。在大多資料庫語言中,程式碼按編碼順序被處理。但在 SQL 語句中,第一個被處理的子句式 FROM,而不是第一齣現的 SELECT。SQL 查詢處理的步驟序號:
(6) WITH {CUBE | ROLLUP} (7) HAVING <having_condition> (8) SELECT (9) DISTINCT (9) ORDER BY <order_by_list> (10) <TOP_specification> <select_list>
以上每個步驟都會產生一個虛擬表,該虛擬表被用作下一個步驟的輸入。這些虛擬表對呼叫者(客戶端應用程式或者外部查詢)不可用。只有最後一步生成的表才會會給呼叫者。如果沒有在查詢中指定某一個子句,將跳過相應的步驟
2、SQL 之聚合函式
聚合函式是對一組值進行計算並返回單一的值的函式,它經常與 select 語句中的 group by 子句一同使用。
a. avg():返回的是指定組中的平均值,空值被忽略。
b. count():返回的是指定組中的專案個數。
c. max():返回指定資料中的最大值。
d. min():返回指定資料中的最小值。
e. sum():返回指定資料的和,只能用於數字列,空值忽略。
f. group by():對資料進行分組,對執行完 group by 之後的組進行聚合函式的運算,計算每一組的值。最後用having去掉不符合條件的組,having子句中的每一個元素必須出現在select列表中(只針對於mysql)。
3、SQL 之連線查詢(左連線和右連線的區別)
外連線: 左連線(左外連線):以左表作為基準進行查詢,左表資料會全部顯示出來,右表如果和左表匹配的資料則顯示相應欄位的資料,如果不匹配則顯示為 null。 右連線(右外連線):以右表作為基準進行查詢,右表資料會全部顯示出來,左表如果和右表匹配的資料則顯示相應欄位的資料,如果不匹配則顯示為 null。 全連線:先以左表進行左外連線,再以右表進行右外連線。
內連線:顯示錶之間有連線匹配的所有行。
4、SQL 之 sql 注入
通過在 Web 表單中輸入(惡意)SQL 語句得到一個存在安全漏洞的網站上的資料庫,而不是按照設計者意圖去執行 SQL 語句。
舉例:當執行的 sql 為 select * from user where username = “admin”or “a”=“a”時,sql 語句恆成立,引數 admin 毫無意義。
防止 sql 注入的方式: 1. 預編譯語句:如,select * from user where username = ?,sql 語句語義不會發生改變,sql 語句中變數用?表示,即使傳遞引數時為“admin or ‘a’= ‘a’”,也會把這整體當做一個字元創去查詢。 2. Mybatis 框架中的 mapper 方式中的 # 也能很大程度的防止 sql 注入($無法防止 sql 注入)。
5、Mysql 效能優化
1、當只要一行資料時使用 limit 1查詢時如果已知會得到一條資料,這種情況下加上 limit 1 會增加效能。因為 mysql 資料庫引 擎會在找到一條結果停止搜尋,而不是繼續查詢下一條是否符合標準直到所有記錄查詢完畢。 2、選擇正確的資料庫引擎 Mysql 中有兩個引擎 MyISAM 和 InnoDB,每個引擎有利有弊。MyISAM 適用於一些大量查詢的應用,但對於有大量寫功能的應用不是很好。甚至你只需要update 一個欄位整個表都會被鎖起來。而別的程序就算是讀操作也不行要等到當前 update 操作完成之後才能繼續進行。另外,MyISAM 對於 select count(*)這類操作是超級快的。InnoDB 的趨勢會是一個非常複雜的儲存引擎,對於一些小的應用會比 MyISAM 還慢,但是支援“行鎖”,所以在寫操作比較多的時候會比較優秀。並且,它支援很多的高階應用,例如:事物。 3. 用 not exists 代替 not in Not exists 用到了連線能夠發揮已經建立好的索引的作用,not in 不能使用索引。Not in 是最 慢的方式要同每條記錄比較,在資料量比較大的操作紅不建議使用這種方式。 4. 對操作符的優化,儘量不採用不利於索引的操作符 如:in not in is null is not null <> 等 某個欄位總要拿來搜尋,為其建立索引: Mysql 中可以利用 alter table 語句來為表中的欄位新增索引,語法為:alter table 表明add index (欄位名);
6、Mysql 資料庫架構圖

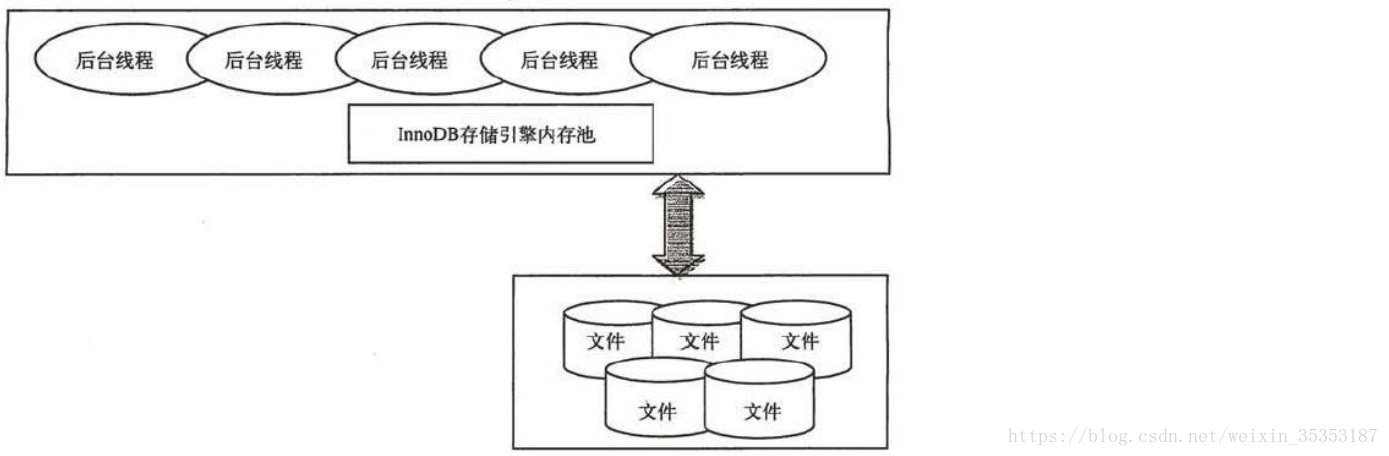
MyISAM 和 InnoDB 是最常見的兩種儲存引擎,特點如下。 MyISAM 儲存引擎 MyISAM 是 MySQL 官方提供預設的儲存引擎,其特點是不支援事務、表鎖和全文索引,對於一些 OLAP(聯機分析處理)系統,操作速度快。每個MyISAM在磁碟上儲存成三個檔案。檔名都和表名相同,副檔名分別是.frm(儲存表定義)、.MYD (MYData,儲存資料)、.MYI (MYIndex,儲存索引)。這裡特別要注意的是 MyISAM 不快取資料檔案,只快取索引檔案。InnoDB 儲存引擎 InnoDB 儲存引擎支援事務,主要面向 OLTP(聯機事務處理過程)方面的應用,其特點是行鎖設定、支援外來鍵,並支援類似於 Oracle 的非鎖定讀,即預設情況下讀不產生鎖。InnoDB 將資料放在一個邏輯表空間中(類似 Oracle)。InnoDB 通過多版本併發控制來獲得高併發性,實現了 ANSI 標準的 4 種隔離級別,預設為 Repeatable,使用一種被稱為 next-key locking 的策略避免幻讀。對於表中資料的儲存,InnoDB 採用類似 Oracle 索引組織表 Clustered 的方式進行儲存。 InnoDB 儲存引擎提供了具有提交、回滾和崩潰恢復能力的事務安全。但是對比 Myisam 的儲存引擎,InnoDB 寫的處理效率差一些並且會佔用更多的磁碟空間以保留資料和索引。InnoDB 體系架構
7、Mysql 架構器中各個模組都是什麼?
1 連線管理與安全驗證是什麼? 每個客戶端都會建立一個與伺服器連線的執行緒,伺服器會有一個執行緒池來管理這些 連線;如果客戶端需要連線到 MYSQL 資料庫還需要進行驗證,包括使用者名稱、密碼、 主機資訊等。2 解析器是什麼? 解析器的作用主要是分析查詢語句,最終生成解析樹;首先解析器會對查詢語句的語法進行分析,分析語法是否有問題。還有解析器會查詢快取,如果在快取中有對應的語句,就返回查詢結果不進行接下來的優化執行操作。前提是快取中的資料沒有被修改,當然如果被修改了也會被清出快取。3 優化器怎麼用? 優化器的作用主要是對查詢語句進行優化操作,包括選擇合適的索引,資料的讀取方式,包括獲取查詢的開銷資訊,統計資訊等,這也是為什麼圖中會有優化器指向儲存引擎的箭頭。之前在別的文章沒有看到優化器跟儲存引擎之間的關係,在這裡我個人的理解是因為優化器需要通過儲存引擎獲取查詢的大致資料和統計資訊。4 執行器是什麼? 執行器包括執行查詢語句,返回查詢結果,生成執行計劃包括與儲存引擎的一些處理操作。
8、Mysql 儲存引擎有哪些?
1.InnoDB 儲存引擎 InnoDB 是事務型資料庫的首選引擎,支援事務安全表(ACID),支援行鎖定和外來鍵,InnoDB 是預設的 MySQL引擎。2.MyISAM 儲存引擎 MyISAM 基於 ISAM 儲存引擎,並對其進行擴充套件。它是在 Web、資料倉儲和其他應用環境下最常使用的儲存引擎之一。MyISAM 擁有較高的插入、查詢速度,但不支援事物。3.MEMORY 儲存引擎 MEMORY 儲存引擎將表中的資料儲存到記憶體中,未查詢和引用其他表資料提供快速訪問。4.NDB 儲存引擎 DB 儲存引擎是一個叢集儲存引擎,類似於 Oracle 的 RAC,但它是 Share Nothing 的架構,因此能提供更高級別的高可用性和可擴充套件性。NDB 的特點是資料全部放在記憶體中,因此通過主鍵查詢非常快。關於 NDB,有一個問題需要注意,它的連線(join)操作是在 MySQL 資料庫層完成,不是在儲存引擎層完成,這意味著,複雜的 join 操作需要巨大的網路開銷,查詢速度會很慢。5.Memory (Heap) 儲存引擎 Memory 儲存引擎(之前稱為 Heap)將表中資料存放在記憶體中,如果資料庫重啟或崩潰,資料丟失,因此它非常適合儲存臨時資料。6.Archive 儲存引擎 正如其名稱所示,Archive 非常適合儲存歸檔資料,如日誌資訊。它只支援 INSERT 和 SELECT 操作,其設計的主要目的是提供高速的插入和壓縮功能。7.Federated 儲存引擎 Federated 儲存引擎不存放資料,它至少指向一臺遠端 MySQL 資料庫伺服器上的表,非常類似於 Oracle 的透明閘道器。8.Maria 儲存引擎 Maria 儲存引擎是新開發的引擎,其設計目標是用來取代原有的 MyISAM 儲存引擎,從而成為 MySQL 預設的儲存引擎。
上述引擎中,InnoDB 是事務安全的儲存引擎,設計上借鑑了很多 Oracle 的架構思想,一般而言,在 OLTP應用中,InnoDB 應該作為核心應用表的首先儲存引擎。InnoDB 是由第三方的 Innobase Oy 公司開發,現已被Oracle 收購,創始人是 Heikki Tuuri,芬蘭赫爾辛基人,和著名的 Linux 創始人 Linus 是校友。
9、MySQL 事務介紹
MySQL 和其它的資料庫產品有一個很大的不同就是事務由儲存引擎所決定,例如 MYISAM,MEMORY,ARCHIVE都不支援事務,事務就是為了解決一組查詢要麼全部執行成功,要麼全部執行失敗。
MySQL 事務預設是採取自動提交的模式,除非顯示開始一個事務。
修改自動提交模式,0=OFF,1=ON 注意:修改自動提交對非事務型別的表是無效的,因為它們本身就沒有提交和回滾的概念,還有一些命令是會強制自動提交的,比如 DLL 命令、lock tables 等。
SET AUTOCOMMIT=OFF 或 SET AUTOCOMMIT=0
10、事務的四大特徵是什麼?
資料庫事務 transanction 正確執行的四個基本要素。ACID,原子性(Atomicity)、一致性(Correspondence)、隔離性(Isolation)、永續性(Durability)。 原子性:整個事務中的所有操作,要麼全部完成,要麼全部不完成,不可能停滯在中間某個環節。事務在執行過程中發生錯誤,會被回滾(Rollback)到事務開始前的狀態,就像這個事務從來沒有執行過一樣。一致性:在事務開始之前和事務結束以後,資料庫的完整性約束沒有被破壞。隔離性:隔離狀態執行事務,使它們好像是系統在給定時間內執行的唯一操作。如果有兩個事務,執行在相同的時間內,執行相同的功能,事務的隔離性將確保每一事務在系統中認為只有該事務在使用系統。這種屬性有時稱為序列化,為了防止事務操作間的混淆, 必須序列化或序列化請 求,使得在同一時間僅有一個請求用於同一資料。永續性:在事務完成以後,該事務所對資料庫所作的更改便持久的儲存在資料庫之中,並不會被回滾。
11、Mysql 中四種隔離級別分別是什麼?
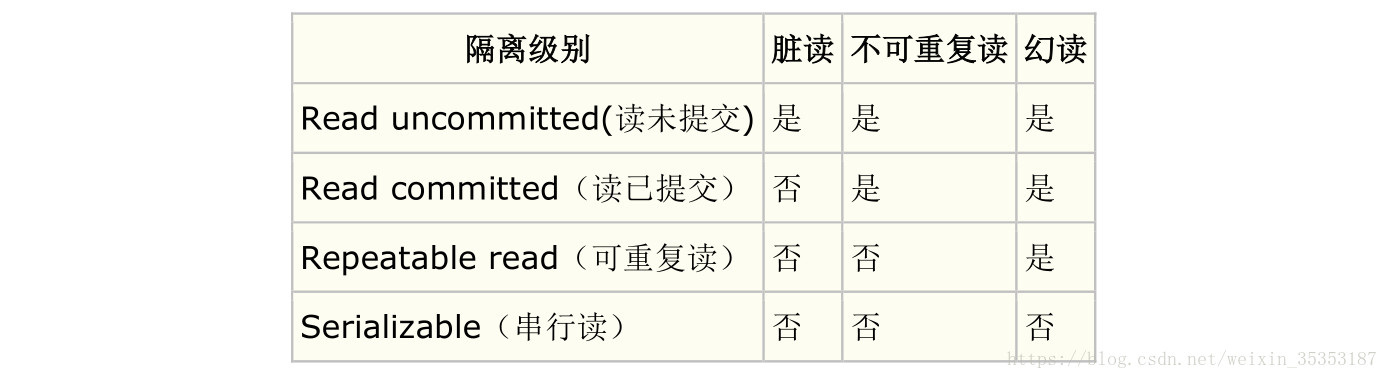
讀未提交(READ UNCOMMITTED):未提交讀隔離級別也叫讀髒,就是事務可以讀取其它事務未提交的資料。讀已提交(READ COMMITTED):在其它資料庫系統比如 SQL Server 預設的隔離級別就是提交讀,已提交讀隔離級別就是在事務未提交之前所做的修改其它事務是不可見的。可重複讀(REPEATABLE READ):保證同一個事務中的多次相同的查詢的結果是一致的,比如一個事務一開始查詢了一條記錄然後過了幾秒鐘又執行了相同的查詢,保證兩次查詢的結果是相同的,可重複讀也是 mysql 的預設隔離級別。可序列化(SERIALIZABLE):可序列化就是保證讀取的範圍內沒有新的資料插入,比如事務第一次查詢得到某個範圍的資料,第二次查詢也同樣得到了相同範圍的資料,中間沒有新的資料插入到該範圍中。
12、MySQL 怎麼建立儲存過程
MySQL 儲存過程是從 MySQL5.0 開始增加的新功能。儲存過程的優點有一籮筐。不過最主要的還是執行效率和SQL 程式碼封裝。特別是 SQL 程式碼封裝功能,如果沒有儲存過程,在外部程式訪問資料庫時,要組織很多 SQL 語句。特別是業務邏輯複雜的時候,一大堆的 SQL 和條件夾雜在程式碼中,讓人不寒而慄。現在有了 MySQL 儲存過程,業務邏輯可以封裝儲存過程中,這樣不僅容易維護,而且執行效率也高。
一、建立 MySQL 儲存過程 下面程式碼建立了一個叫 pr_add 的 MySQL 儲存過程,這個 MySQL 儲存過程有兩個 int 型別的輸入引數 “a”、“b”,返回這兩個引數的和。 1)drop procedure if exists pr_add; (備註:如果存在 pr_add 的儲存過程,則先刪掉) 2)計算兩個數之和(備註:實現計算兩個整數之和的功能)create procedure pr_add ( a int, b int ) begin declare c int; if a is null then set a = 0; end if; if b is null then set b = 0; end if; set c = a + b; select c as sum;二、呼叫 MySQL 儲存過程call pr_add(10, 20);
13、MySQL 觸發器怎麼寫?
MySQL 包含對觸發器的支援。觸發器是一種與表操作有關的資料庫物件,當觸發器所在表上出現指定事件時,將呼叫該物件,即表的操作事件觸發表上的觸發器的執行。
在 MySQL 中,建立觸發器語法如下:CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW trigger_stmt其中:trigger_name:標識觸發器名稱,使用者自行指定;trigger_time:標識觸發時機,取值為 BEFORE 或 AFTER;trigger_event:標識觸發事件,取值為 INSERT、UPDATE 或 DELETE;tbl_name:標識建立觸發器的表名,即在哪張表上建立觸發器;trigger_stmt:觸發器程式體,可以是一句 SQL 語句,或者用 BEGIN 和 END 包含的多條語句。 由此可見,可以建立 6 種觸發器,即:BEFORE INSERT、BEFORE UPDATE、BEFORE DELETE、AFTER INSERT、AFTER UPDATE、AFTER DELETE。 另外有一個限制是不能同時在一個表上建立 2 個相同型別的觸發器,因此在一個表上最多建立 6 個觸發器。
14、MySQL 語句優化
一、where 子句中可以對欄位進行 l null 值判斷嗎?
可以,比如 select id from t where num is null 這樣的 sql 也是可以的。但是最好不要給資料庫留 NULL,儘可能的使用 NOT NULL 填充資料庫。不要以為 NULL 不需要空間,比如:char(100) 型,在欄位建立時,空間就固定了,不管是否插入值(NULL 也包含在內),都是佔用 100 個字元的空間的,如果是 varchar 這樣的變長欄位,null 不佔用空間。可以在 num 上設定預設值 0,確保表中 num 列沒有 null 值,然後這樣查詢:select id from t where num= 0。
二、select * from admin left join log on admin.admin_id = log.admin_id where 0 log.admin_id>10 如何優化? ?
優化為: select * from (select * from admin where admin_id>10) T1 lef join log on T1.admin_id = log.admin_id。 使用 JOIN 時候,應該用小的結果驅動大的結果(left join 左邊表結果儘量小如果有條件應該放到左邊先處理,right join 同理反向),同時儘量把牽涉到多表聯合的查詢拆分多個 query(多個連表查詢效率低,容易到之後鎖表和阻塞)。
三、limit 的基數比較大時使用 between
例如:select * from admin order by admin_id limit 100000,10 優化為:select * from admin where admin_id between 100000 and 100010 order by admin_id。
四、儘量避免在列上做運算,這樣導致索引失效
例如:select * from admin where year(admin_time)>2014 優化為: select * from admin where admin_time> '2014-01-01′
15、MySQL 中文亂碼問題完美解決方案
解決亂碼的核心思想是統一編碼。我們在使用 MySQL 建資料庫和建表時應儘量使用統一的編碼,強烈推薦的是 utf8 編碼,因為該編碼幾乎可以相容世界上所有的字元。 資料庫在安裝的時候可以設定預設編碼,在安裝時就一定要設定為 utf8 編碼。設定之後再建立的資料庫和表如果不指定編碼,預設都會使用 utf8 編碼,省去了很多麻煩。
資料庫軟體安裝好之後可以通過如下命令檢視預設編碼: 1、查詢資料庫軟體使用的預設編碼格式show variables like “%colla%”; show varables like “%char%”
16、如何提高 MySQL 的安全性
1.如果 MySQL 客戶端和伺服器端的連線需要跨越並通過不可信任的網路,那麼需要使用 ssh 隧道來加密該連線的通訊。 2.使用 set password 語句來修改使用者的密碼,先“mysql -u root”登陸資料庫系統,然後“mysql> update mysql.user set password=password(’newpwd’)”,最後執行“flush privileges”。 3.MySQL 需要提防的攻擊有,防偷聽、篡改、回放、拒絕服務等,不涉及可用性和容錯方面。對所有的連線、查詢、其他操作使用基於 ACL(ACL(訪問控制列表)是一種路由器配置和控制網路訪問的一種有力的工具,它可控制路由器應該允許或拒絕資料包通過,可監控流量,可自上向下檢查網路的安全性,可檢查和過濾資料和限制不必要的路由更新,因此讓網路資源節約成本的 ACL 配置技術在生活中越來越廣泛應用。)即訪問控制列表的安全措施來完成。 4.設定除了 root 使用者外的其他任何使用者不允許訪問 mysql 主資料庫中的 user 表; 5.使用 grant 和 revoke 語句來進行使用者訪問控制的工作; 6.不要使用明文密碼,而是使用 md5()和 sha1()等單向的哈系函式來設定密碼; 7.不要選用字典中的字來做密碼; 8.採用防火牆可以去掉 50%的外部危險,讓資料庫系統躲在防火牆後面工作,或放置在 DMZ(DMZ 是英文“demilitarized zone”的縮寫,隔離區,它是為了解決安裝防火牆後外部網路的訪問使用者不能訪問內部網路伺服器的問題,而設立的一個非安全系統與安全系統之間的緩衝區。)區域中; 9.從因特網上用 nmap 來掃描 3306 埠,也可用 telnet server_host 3306 的方法測試,不允許從非信任網路中訪問資料庫伺服器的 3306 號 tcp 埠,需要在防火牆或路由器上做設定; 10.服務端要對 SQL 進行預編譯,避免 SQL 注入攻擊,例如 where id=234,別人卻輸入 where id=234 or 1=1。 11.在傳遞資料給 mysql 時檢查一下大小; 12.應用程式連線到資料庫時應該使用一般的使用者帳號,開放少數必要的許可權給該使用者; 13.學會使用 tcpdump 和 strings 工具來檢視傳輸資料的安全性,例如 tcpdump -l -i eth0 -w -src or dst port 3306 strings。以普通使用者來啟動 mysql 資料庫服務; 14.確信在 mysql 目錄中只有啟動資料庫服務的使用者才可以對檔案有讀和寫的許可權; 15.不許將 process 或 super 許可權付給非管理使用者,該 mysqladmin processlist 可以列舉出當前執行的查詢文字;super 許可權可用於切斷客戶端連線、改變伺服器執行引數狀態、控制拷貝複製資料庫的伺服器; 16.如果不相信 dns 服務公司的服務,可以在主機名稱允許表中只設置 ip 數字地址; 17.使用 max_user_connections 變數來使 mysqld 服務程序,對一個指定帳戶限定連線數; 18.grant 語句也支援資源控制選項; 19.啟動 mysqld 服務程序的安全選項開關,–local-infile=0 或 1,若是 0 則客戶端程式就無法使用 local load data 了,賦權的一個例子 grant insert(user) on mysql.user to ‘user_name’@'host_name’;若使用–skip-grant-tables 系統將對任何使用者的訪問不做任何訪問控制,但可以用 mysqladmin flush-privileges 或 mysqladmin reload來開啟訪問控制;預設情況是 show databases 語句對所有使用者開放,可以用–skip-show-databases 來關閉掉。 23.碰到 error 1045(28000) access denied for user ‘root’@'localhost’ (using password:no)錯誤時,你需要重 新 設 置 密 碼 , 具 體 方 法 是 : 先 用 – skip-grant-tables 參 數 啟 動 mysqld , 然 後 執 行 mysql -u rootmysql,mysql>update user set password=password(’newpassword’) where user=’root’;mysql>flush privileges;,最後重新啟動 mysql 就可以了。