
大資料儲存、計算、應用、視覺化,資料的基本概述都在這裡了
未來的時代,一定是資料的時代,在未來,一切被記錄,一切被分析,資料將以資產的方式存在,相關知識如下:

一、先說各種資料儲存
資料是個很泛的概念,但是我們腦海裡第一反應的就是關係型資料庫和EXCEL這種二維表是資料。
而現在資料各種各樣特色,有文件、有圖片、有流式的音訊視訊、有日誌資料、有IM訊息資料、有索引資料、有社交應用的網狀關係資料、有地圖資料。他們對儲存訪問都有不同的要求,因而NoSQL興起了。
如KV型,先後出現了Memcached、Redis。如文件型,出現了CouchDB、MongoDB。如日誌資料,也出現了Facebook Scribe、Flume、Logstash。
即使在傳統關係型資料領域,由於大資料規模也出現了真正的分散式關係型資料庫,如GreenPlum、TiDB、OceanBase
為了多維分析,也出現了專門的列式資料庫,如HBase。

二、資料倉庫
各式各樣的資料,經由各種上層應用進行了採集和儲存。但我們一提到大資料,自然想到的就是大資料分析。大資料分析的第一步就是大資料倉庫建設。
大資料倉庫建設,必要的工作就是ETL(抽取、轉換、匯入)。抽取,這步就又細分為:資料抽取、資料清洗、資料校驗。在轉換這步,我們也需要關注資料安全脫敏,也就是說,進入大資料倉庫的資料需要分級。
不過大家一般建設大資料倉庫,首先做的第一個應用工作就是:主資料治理。所以這個第一期,需要做:主資料標準制定、主資料清洗與校驗、主資料轉換(拆分合並)、主資料複製分發、主資料訪問OpenAPI。
資料複製分發,我們可以使用訊息佇列和排程服務來工作。訊息佇列如Kafka、ZeroMQ、ActiveMQ、RabbitMQ。排程服務如ZooKeeper。
資料抽取傳輸開源專案,我能看到的Sqoop on Hadoop。可能很多資料都是直接被Spark、Storm、Presto、Hbase處理了。
三、大資料倉庫基礎架構
現在建大資料倉庫,需要的是分散式儲存和分散式計算,再也不是過去幾十臺伺服器和幾百T儲存這麼簡單的。這都是要以萬計的,這才是真正的大資料。而要建造這麼大規模的大資料倉庫,需要分散式儲存和分散式計算基礎框架支撐。
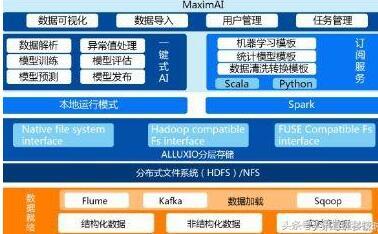
我們第一個就要提出的就是Hadoop。目前它已經成為了一個生態。Hadoop最核心是兩塊:分散式檔案系統HDFS、MapReduce。MapReduce又分為MAP(分解任務)、Reduce(合併結果)兩部分。
現在有個新玩意叫YARN,不過YARN並不是MapReduce2.0。在MapReduce中資源管理和作業管理均是由JobTracker實現的,集兩個功能於一身,而在新的Hadoop2.0架構中,MapReduce作業管理由ApplicationMaster實現,而資源管理由新增系統YARN完成。Hadoop Corona是facebook開源的下一代MapReduce框架。其基本設計動機和Apache的YARN一致。就是因為大家都在解決同一個問題,只不過不同時間段開源出來不同的解決方案專案,所以使大家大呼到底要用哪個啊。
現在又出來一個新玩意叫:Mesos。Mesos是更寬泛的資源管理框架,不僅可以管理偏重於半結構化的大資料框架,也可以管理非結構化的框架。人們也在對比Mesos和Kubernetes,其實Kubernetes只是目前聚焦於容器的管理,而Mesos野心更大,當然也抽象的更通用化,留下各種抽象介面,以管理各種資源。
有人還把ZooKeeper和YARN、Mesos比較。其實Zookeeper已經成為最基層最具體最不可或缺的真正的協調執行者了。而YARN成為了大資料處理資源管理框架,而Mesos更成為了有史以來更大整合者更通用的資源管理框架了。
四、大資料計算框架
在大資料處理領域,目前當紅炸子雞是:Spark、Storm、Flink。
Spark切的領域在MapReduce工作的領域,不過Spark大量把MAP中間結果放到記憶體中,所以顯得效能特別快。現在Spark也在往生態走,希望能夠上下游通吃,一套技術棧解決大家多種需求,所以大家又漸漸看不清楚Spark聚焦的領域了。Spark Shark,是為了VS hadoop Hive,Spark Streaming是為了VS Storm。
Storm擅長處理實時流式。比如日誌,比如網站購物的點選流,是源源不斷、按順序的、沒有終結的,所以通過Kafka等訊息佇列來了資料後,Storm就一邊開始工作。Storm自己不收集資料也不儲存資料,隨來隨處理隨輸出結果。
它們都有各自的特色,但他們都無法給你處理具體的業務應用,它們只是大規模分散式計算的通用框架,所以具體用他們的特性幹什麼,還得你自己寫。這就是大資料業務領域分析系統的事了。
不過,下面我會介紹一些技術,在特定的業務領域,能夠幫你更簡單的達成業務應用需要。
五、大資料應用技術
1、大資料搜尋:Lucene、Solr、ElasticSearch。ElasticSearch是新推出的比Solr在大規模資料情況下更好的開源解決方案。
2、大資料查詢:這裡有Hive/Impala,Hive的作用是你可以把結構化資料匯入到Hadoop中然後用簡單SQL來做查詢。你可以把Impala看做是效能更快的Hive,因為Impala不強依賴MapReduce。而Facebook開源的Presto更是能查詢多種資料來源,而且一條Presto查詢可以將多個數據源的資料進行合併。
3、大資料分析:咱們要提到去年新晉頂級Apache專案的Kylin。它創始於ebay,2014年進入apache孵化專案。Kylin不僅僅能做SQL查詢,而且能做Cube多維分析。
4、大資料探勘:這個領域包含精準推薦、機器學習/深度學習/神經網路、人工智慧。自從AlphaGo火了以後,機器學習再度火熱。Google開源了最新機器學習系統TensorFlow,微軟亞洲研究院開源了分散式機器學習工具包-DMTK,雅虎也開源了Caffe On Spark 深度學習。Mahout是Apache的一個開源專案,提供一些機器學習領域經典演算法的實現,包括聚類、分類、推薦過濾、頻繁子項挖掘。
六、資料視覺化工具
這塊有大量的視覺化開源元件,但成系統的開源的確實出色的不多。這裡面大有可玩。
Airbnb近日開源了資料探查與視覺化平臺Caravel。另外,百度推出的Echarts元件也不做,可以基於此做些系統性的工作。
七、資料平臺監控運維
這裡只看到一套完整的適用於海量日誌處理的工具:Facebook Scribe、Flume、Logstash、Kibana。但我覺得,如此複雜的大資料平臺技術棧,一套成熟的監控運維繫統,是必須要出現的。
八、最後總結:大資料平臺建設總藍圖
作為咱們日常業務,最直接的需要就是一套能分析具體業務的應用系統,但這套應用系統需要很多基礎技術架構和服務才能達成。為了讓大家有所預期,所以我把這些必備前提儲備列出來。
技術平臺建設:
1、大資料基礎架構:推薦Hadoop、HDFS、YARN;大資料計算框架:推薦Spark;大資料日誌收集推薦Flume+Logstash+Kibana。我們需要部署依賴中介軟體Zookeeper。
2、大資料倉庫平臺建設:分散式關係型TiDB、KV式Redis、文件型MongoDB、列式Hbase
3、大資料搜尋,推薦選擇Lucene、ElasticSearch;大資料查詢,推薦選擇Presto;大資料多維分析,推薦Kylin;大資料探勘,推薦挖掘開源演算法包MashOut。
大資料整理服務:
1、主資料管理:主資料標準制定、主資料清洗與校驗、主資料轉換(拆分合並)、主資料複製分發、主資料訪問OpenAPI。
2、ETL:資料抽取、資料清洗、資料校驗、資料安全脫敏
大資料分析系統建設:
1、大資料展示平臺建設
2、大資料商業應用模型建模
3、大資料應用分析系統設計與開發
看看,大資料建設很複雜,大家一定要沉住氣,一期期來做,這個週期和投入將會很大,不是設計個分析模型、開發個分析系統這麼簡單的。如果就是那樣簡單的,其實就是個披著大資料的報表系統而已
在不久的將來,多智時代一定會徹底走入我們的生活,有興趣入行未來前沿產業的朋友,可以收藏多智時代,及時獲取人工智慧、大資料、雲端計算和物聯網的前沿資訊和基礎知識,讓我們一起攜手,引領人工智慧的未來!