
Python 資料視覺化—下載資料(CSV檔案格式、JSON格式)
Python 資料視覺化-下載資料CSV檔案格式、JSON格式
- 網上下載資料,並對這些資料進行視覺化,視覺化以兩種常見格式儲存的資料:
CSV 和JSON。 - 我們將
使用Python模組csv 來處理以CSV
1、CSV檔案格式:
-
最簡單的方式是將
資料作為一系列以逗號分隔的值 (CSV)寫入檔案。2019-1-5,61,44,26,18,7,-1,56,30,9,30.34,30.27,30.15,,,,10,4,,0.00,0,,195
1.1、分析CSV檔案頭:
-
csv 模組包含在Python標準庫中,可用於分析CSV檔案中的資料行,讓我們能夠快速提取感興趣的值。import csv filename = './weather.csv' # 我再當前目錄中建立了weather.csv 檔案了 with open(filename) as f: reader = csv.reader(f) header_row = next(reader) print(header_row)-
匯入模組csv 後,我們將要使用的檔案的名稱儲存在filename 中
-
我們開啟這個檔案,並將結果檔案物件儲存在f 中
-
我們呼叫csv.reader() ,並將前面儲存的檔案物件作為實參傳遞給它,從而建立一個與該檔案相關聯的閱讀器(reader )物件
-
我們將這個閱讀器物件儲存在reader 中
-
模組csv 包含函式next() ,呼叫它並將閱讀器物件傳遞給它時,它將返回檔案中的下一行。 -
我們
只調用了next() 一次,因此得到的是檔案的第一行,其中包含檔案頭# 輸出結果如下: ['AKDT', 'Max TemperatureF', 'Mean TemperatureF', 'Min TemperatureF', 'Max Dew PointF', 'MeanDew PointF', 'Min DewpointF', 'Max Humidity', ' Mean Humidity', ' Min Humidity', ' Max Sea Level PressureIn', ' Mean Sea Level PressureIn', ' Min Sea Level PressureIn', ' Max VisibilityMiles', ' Mean VisibilityMiles', ' Min VisibilityMiles', ' Max Wind SpeedMPH', ' Mean Wind SpeedMPH', ' Max Gust SpeedMPH', 'PrecipitationIn', ' CloudCover', ' Events', ' WindDirDegrees']
-
-
注意 :檔案頭的格式並非總是一致的,空格和單位可能出現在奇怪的地方。這在原始資料檔案中很常見,但不會帶來任何問題。
1.2、列印檔案頭及其位置:
-
為讓檔案頭
資料更容易理解,將列表中的每個檔案頭及其位置打印出來:import csv filename = './weather.csv' with open(filename) as f: reader = csv.reader(f) header_row = next(reader) for index, column_header in enumerate(header_row): print(index, column_header) # 輸出結果如下: 0 AKDT 1 Max TemperatureF 2 Mean TemperatureF 3 Min TemperatureF ————snip————— 19 PrecipitationIn 20 CloudCover 21 Events 22 WindDirDegrees- 我們對列表呼叫了
enumerate()來獲取每個元素的索引及其值。
- 我們對列表呼叫了
1.3、提取並讀取資料:
-
知道需要哪些列中的資料後,我們來讀取一些資料。首先讀取每天的最高氣溫
import csv filename = './weather.csv' with open(filename) as f: reader = csv.reader(f) header_row = next(reader) highs = [] for row in reader: highs.append(row[1]) print(highs) # 輸出結果如下: ['64', '71', '64', '59', '69', '62', '61', '55', '57', '61', '57', '59', '57', '61', '64', '61', '59', '63', '60', '57', '69', '63', '62', '59', '57', '57', '61', '59', '61', '61', '66'] -
下面使用
int() 將這些字串轉換為數字,讓matplotlib能夠讀取它們import csv filename = './weather.csv' with open(filename) as f: reader = csv.reader(f) header_row = next(reader) highs = [] for row in reader: highs.append(int(row[1])) print(highs)
1.4、繪製氣溫圖表:
-
為視覺化這些氣溫資料,我們
首先使用matplotlib建立一個顯示每日最高氣溫的簡單圖形。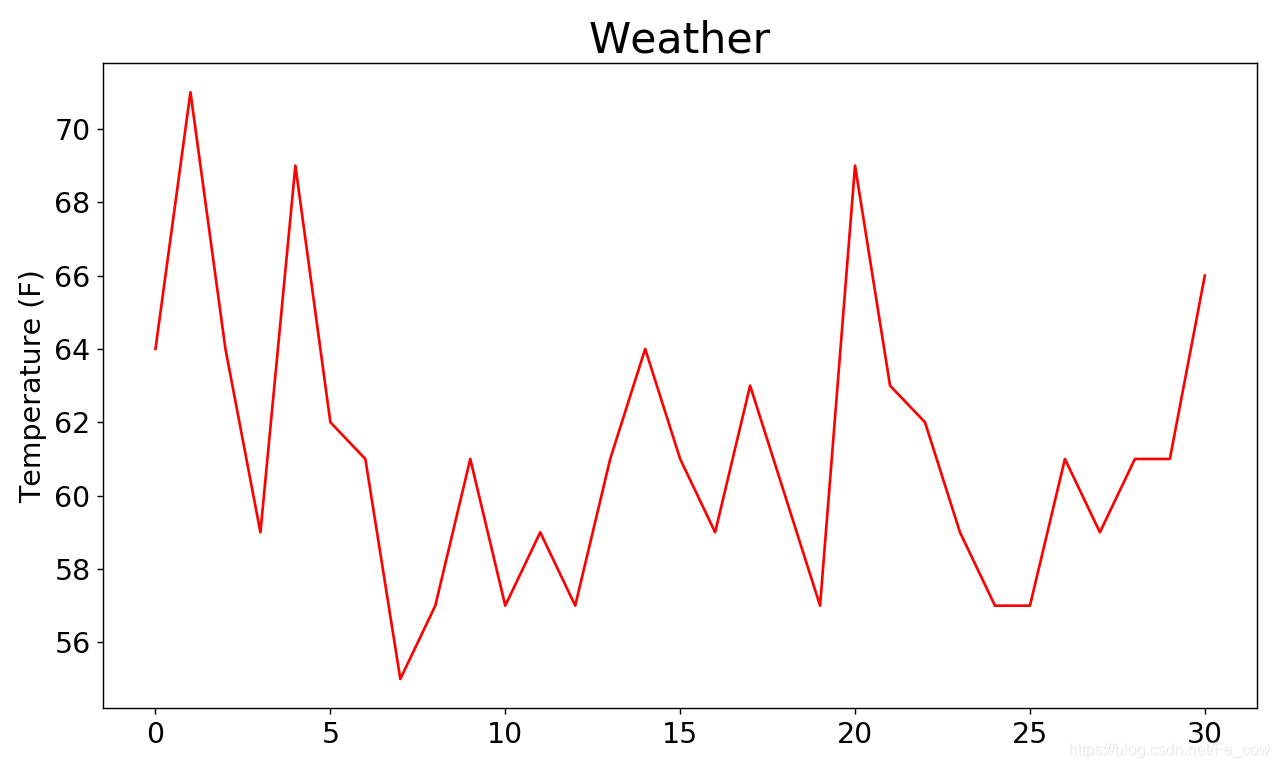
- 我們將最高氣溫列表傳給plot(),並
傳遞c='red' 以便將資料點繪製為紅色
- 我們將最高氣溫列表傳給plot(),並
1.5、模組datetime:
-
下面在圖表中新增日期,使其更有用。在天氣資料檔案中,第一個日期在第二行:
-
讀取該資料時,獲得的是一個字串,因為我們需要想辦法將字串’2014-7-1’ 轉換為一個表示相應日期的物件。
-
為建立一個表示2019年1月1日的物件,可使用模組
datetime 中的方法strptime()from datetime import datetime first_date = datetime.strptime('2019-1-1', '%Y-%m-%d') print(first_date)- 我們首先匯入了模組
datetime 中的datetime 類,然後呼叫方法strptime() ,並將包含所需日期的字串作為第一個實參 第二個實參告訴Python如何設定日期的格式方法strptime() 可接受各種實參,並根據它們來決定如何解讀日期
- 我們首先匯入了模組
-
-
模組datetime中設定日期和時間格式的實參:
實參 含義 %A 星期的名稱,如Monday %B 月份名,如January %m 用數字表示月份(01~12) %d 用數字表示月份中的一天(01~31) %Y 四位的年份,如2019 %y 二位的年份,如15 %H 24小時制的小時數(00~23) %I 12小時制的小時數(01~12) %P am或pm %M 分鐘數(00~59) %S 秒數(00~61)
1.6、再圖表中新增日期:
-
即提取日期和最高氣溫,並將它們傳遞給plot()
import csv from datetime import datetime from matplotlib import pyplot as plt # 從檔案中獲取日期和最高氣溫 filename = 'weather.csv' with open(filename) as f: reader = csv.reader(f) header_now = next(reader) dates, highs = [], [] for row in reader: current_date = datetime.strptime(row[0], '%Y-%m-%d') dates.append(current_date) high = int(row[1]) highs.append(high) # 根據資料繪製圖形 fig = plt.figure(dpi=128, figsize=(10, 6)) plt.plot(dates, highs, c='red') # 設定圖形的形式 plt.title('Weather', fontsize=24) plt.xlabel('', fontsize=16) fig.autofmt_xdate() plt.ylabel('Temperature (F)', fontsize=16) plt.tick_params(axis='both', which='major', labelsize=16) plt.show()-
我們建立了兩個空列表,用於儲存從檔案中提取的日期和最高氣溫,我們將包含日期資訊的
資料(row[0] )轉換為datetime 物件 -
我們將日期和最高氣溫值傳遞給
plot() -
我們呼叫了fig.autofmt_xdate() 來繪製斜的日期標籤,以免它們彼此重疊

-
1.7、涵蓋更長的時間:
-
設定好圖表後,我們來新增更多的資料,以成一幅更復雜的,匯入一個weather_2014.csv的檔案。
import csv from datetime import datetime from matplotlib import pyplot as plt # 從檔案中獲取日期和最高氣溫 filename = 'weather_2014.csv' with open(filename) as f: reader = csv.reader(f) header_now = next(reader) dates, highs = [], [] for row in reader: current_date = datetime.strptime(row[0], '%Y-%m-%d') dates.append(current_date) high = int(row[1]) highs.append(high) # 根據資料繪製圖形 fig = plt.figure(dpi=128, figsize=(10, 6)) plt.plot(dates, highs, c='red') # 設定圖形的形式 plt.title('Weather', fontsize=24) plt.xlabel('', fontsize=16) fig.autofmt_xdate() plt.ylabel('Temperature (F)', fontsize=16) plt.tick_params(axis='both', which='major', labelsize=16) plt.show()
1.8、再繪製一個數據系列:
-
我們可以在其中再新增最低氣溫資料,使其更有用
import csv from datetime import datetime from matplotlib import pyplot as plt # 從檔案中獲取日期和最高氣溫 filename = 'weather_2014.csv' with open(filename) as f: reader = csv.reader(f) header_now = next(reader) dates, highs, lows = [], [], [] for row in reader: current_date = datetime.strptime(row[0], '%Y-%m-%d') dates.append(current_date) high = int(row[1]) highs.append(high) low = int(row[3]) lows.append(low) # 根據資料繪製圖形 fig = plt.figure(dpi=128, figsize=(10, 6)) plt.plot(dates, highs, c='red') plt.plot(dates, lows, c='blue') # 設定圖形的形式 plt.title('Weather', fontsize=24) plt.xlabel('', fontsize=16) fig.autofmt_xdate() plt.ylabel('Temperature (F)', fontsize=16) plt.tick_params(axis='both', which='major', labelsize=16) plt.show()-
我們添加了空列表lows ,用於儲存最低氣溫。接下來,我們從每行的第4列(row[3] )提取每天的最低氣溫,並存儲它們
-
我們添加了一個對plot() 的呼叫,以使用藍色繪製最低氣溫
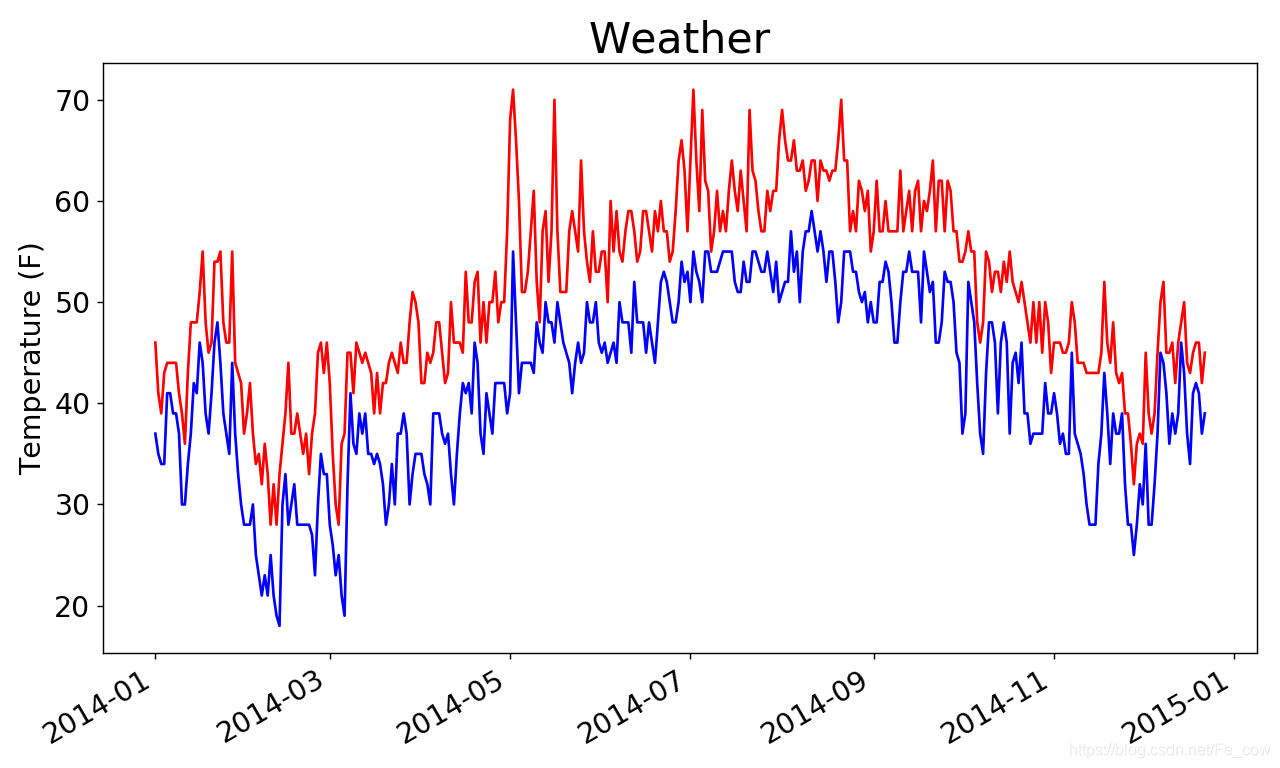
-
-
再一個圖表中包含兩個資料系列
1.9、給圖表區域著色
-
給這個圖表做最後的修飾,通過著色來呈現每天的氣溫範圍。
-
我們將
使用方法fill_between() ,它接受一個 x 值系列和兩個 y 值系列,並填充兩個 y 值系列之間的空間:import csv from datetime import datetime from matplotlib import pyplot as plt # 從檔案中獲取日期和最高氣溫 filename = 'weather_2014.csv' with open(filename) as f: reader = csv.reader(f) header_now = next(reader) dates, highs, lows = [], [], [] for row in reader: current_date = datetime.strptime(row[0], '%Y-%m-%d') dates.append(current_date) high = int(row[1]) highs.append(high) low = int(row[3]) lows.append(low) # 根據資料繪製圖形 fig = plt.figure(dpi=128, figsize=(10, 6)) plt.plot(dates, highs, c='red', alpha=0.5) plt.plot(dates, lows, c='blue', alpha=0.5) plt.fill_between(dates, highs, lows, facecolor='blue', alpha=0.1) # 設定圖形的形式 plt.title('Weather', fontsize=24) plt.xlabel('', fontsize=16) fig.autofmt_xdate() plt.ylabel('Temperature (F)', fontsize=16) plt.tick_params(axis='both', which='major', labelsize=16) plt.show()-
實參alpha 指定顏色的透明度。Alpha 值為0表示完全透明,1表示完全不透明。通過將alpha 設定為0.5,可讓紅色和藍色折線的顏色看起來更淺。
-
我們向
fill_between() 傳遞了一個 x 值系列:列表dates ,還傳遞了兩個 y 值系列:highs 和lows -
實參facecolor 指定了填充區域的顏色,我們還將alpha設定成了較小的值0.1,讓填充區域將兩個資料系列連線起來的同時不分散觀察者的注意力。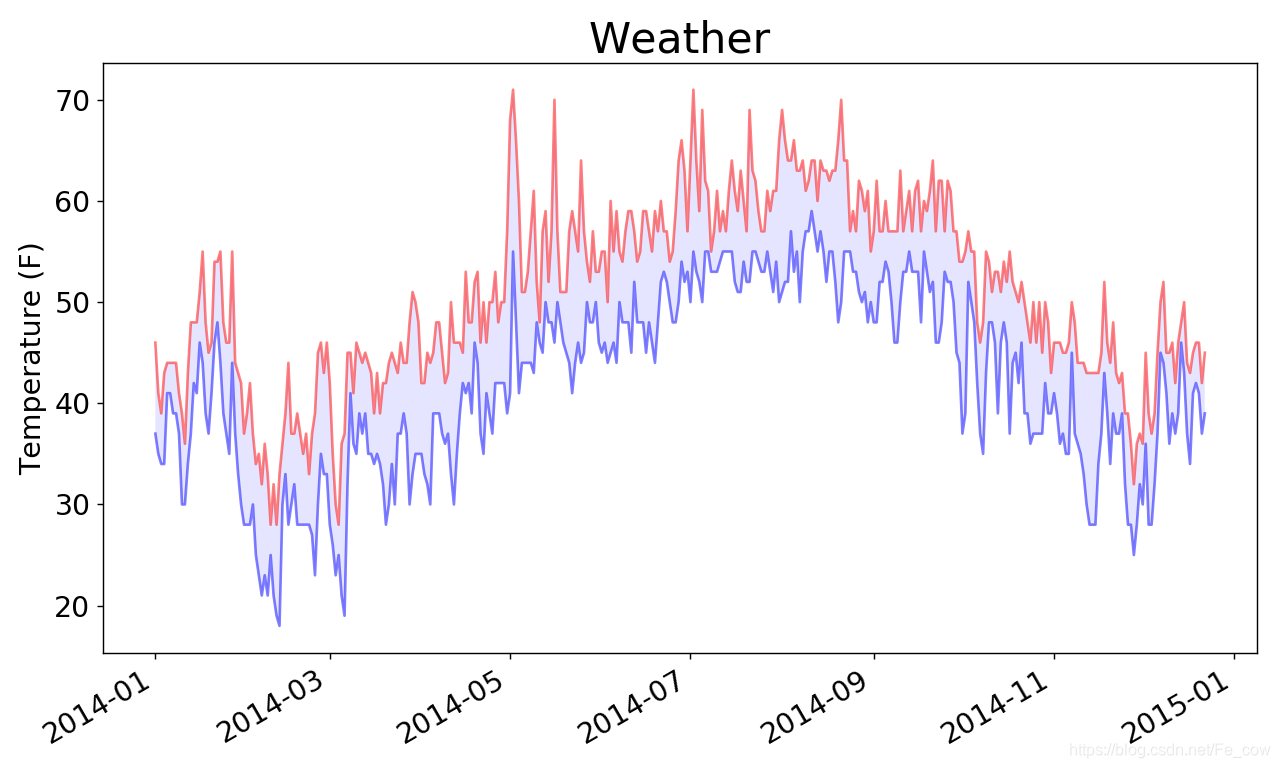
-
1.10、錯誤檢查:
-
但有些氣象站會偶爾出現故障,未能收集部分或全部其應該收集的資料。
-
缺失資料可能會引發異常,如果不妥善地處理,還可能導致程式崩潰。
--snip-- # 從檔案中獲取日期、最高氣溫和最低氣溫 filename = 'death_valley_2014.csv' with open(filename) as f: --snip---
執行這個程式時,出現一個錯誤:
C:\Users\lh9\PycharmProjects\untitled1\venv\Scripts\python.exe C:/Users/lh9/PycharmProjects/request/my_test01.py Traceback (most recent call last): File "C:/Users/lh9/PycharmProjects/request/my_test01.py", line 1457, in <module> high = int(row[1]) ValueError: invalid literal for int() with base 10: '' Process finished with exit code 1- 該traceback指出,Python無法處理其中一天的最高氣溫,因為它無法將空字串(’ ’ )轉換為整數。
-
-
再此修改:
dates, highs, lows = [], [], [] for row in reader: try: current_date = datetime.strptime(row[0], '%Y-%m-%d') high = int(row[1]) low = int(row[3]) except ValueError: print(current_date, 'missing data') else: dates.append(current_date) highs.append(high) lows.append(low)- 只要缺失其中一項資料,
Python就會引發ValueError 異常,而我們可這樣處理:列印一條錯誤訊息, 指出缺失資料的日期 - 列印錯誤訊息後,迴圈將接著處理下一行。如果獲取特定日期的所有資料時沒有發生錯誤,將執行else 程式碼塊,並將資料附加到相應列表的末尾
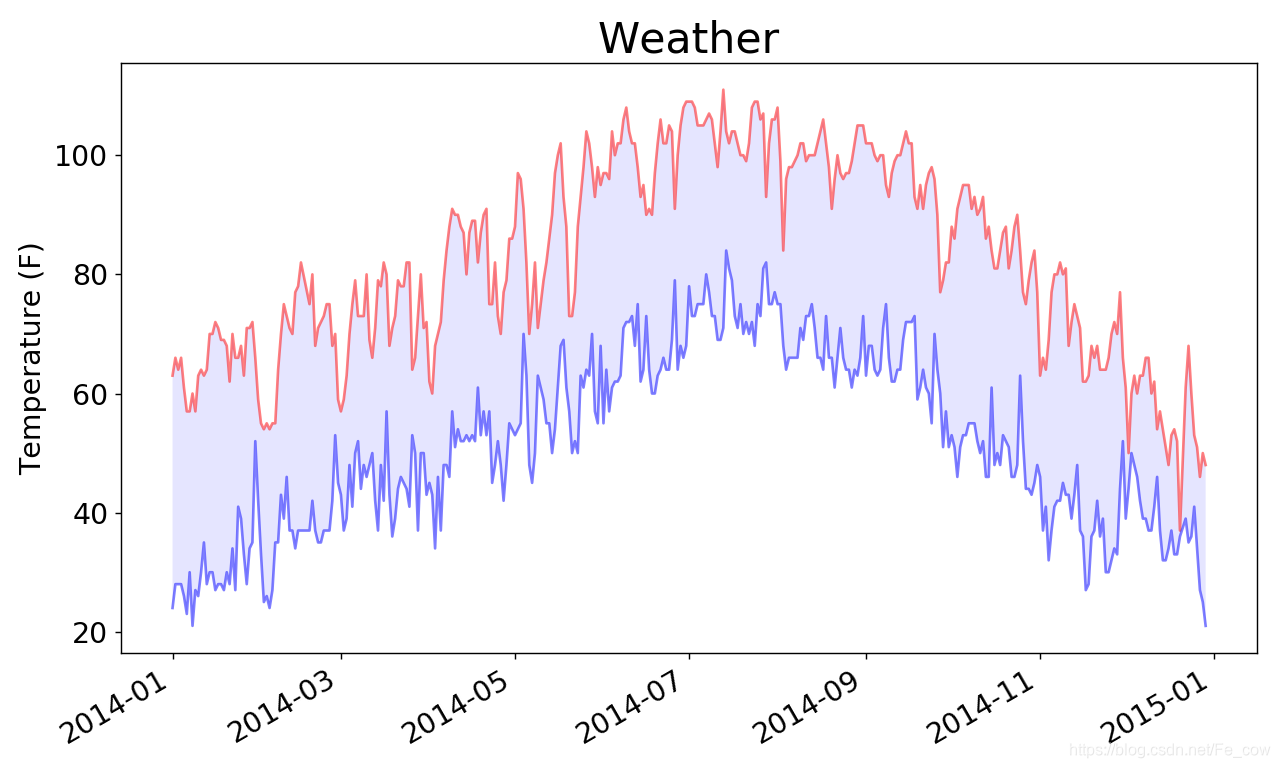
- 只要缺失其中一項資料,
2、JSON格式:
- Pygal提供了一個適合初學者使用的地圖建立工具,你將使用它來對人口資料進行視覺化,以探索全球人口的分佈情況。
2.1、下載世界人口資料:
- (http://data.okfn.org/ )提供了大量可以免費使用的資料集,這些資料就來自其中一個數據集。
2.2、提取相關的資料:
-
這個檔案實際上就是一個很長的Python列表,其中每個元素都是一個包含四個鍵的字典:國家名、國別碼、年份以及表示人口數量的值。我們只關心每個國家2010年的人口數量,因此我們首先編寫一個列印這些資訊的程式:
import json # 將資料載入到一個列表中 filename = 'population_data.json' with open(filename) as f: pop_data = json.load(f) for pop_dict in pop_data: if pop_dict['Year'] == '2010': country_name = pop_dict['Country Name'] population = pop_dict['Value'] print(country_name + ": " + population)-
我們首先匯入了模組json ,以便能夠正確地載入檔案中的資料,然後,我們將資料儲存在pop_data 中
-
函式json.load() 將資料轉換為Python能夠處理的格式,這裡是一個列表。
rab World: 357868000 Caribbean small states: 6880000 East Asia & Pacific (all income levels): 2201536674 --snip-- Zimbabwe: 12571000
-
2.3、將字串轉換為數字值:
-
為處理這些人口資料,我們需要將表示人口數量的字串轉換為數字值,為此我們使用函式int():
-
我們先將字串轉換為浮點數,再將浮點數轉換為整數:
import json # 將資料載入到一個列表中 filename = 'population_data.json' with open(filename) as f: pop_data = json.load(f) for pop_dict in pop_data: if pop_dict['Year'] == '2010': country_name = pop_dict['Country Name'] population = int(float(pop_dict['Value'])) print(country_name + ": " + str(population))- 函式float() 將字串轉換為小數,而函式int() 丟棄小數部分,返回一個整數
Arab World: 357868000 Caribbean small states: 6880000 East Asia & Pacific (all income levels): 2201536674 --snip-- Zimbabwe: 12571000
2.4、獲取兩個字母的國別碼
-
首先安裝
pip install pygal_maps_world -
再程式碼檔案中新增
from pygal_maps_world.i18n import COUNTRIESfrom pygal_maps_world.i18n import COUNTRIES def get_country_code(country_name): """根據指定的國家, 返回pygal使用的兩個字母的國別碼""" for code, name in COUNTRIES.items(): if name == country_name: return code # 如果沒有找到指定的國家, 就返回None return None print(get_country_code('Andorra')) print(get_country_code('United Arab Emirates')) print(get_country_code('Afghanistan'))-
get_country_code() 接受國家名,並將其儲存在形參country_name 中,我們遍歷COUNTRIES 中的國家名—國別碼對
-
如果找到指定的國家名,就返回相應的國別碼,在迴圈後面,我們在沒有找到指定的國家名時返回None
ad ae af -
完善這個獲取兩個字母的國別碼:
import json from pygal_maps_world.i18n import COUNTRIES def get_country_code(country_name): """根據指定的國家, 返回pygal使用的兩個字母的國別碼""" for code, name in COUNTRIES.items(): if name == country_name: return code # 如果沒有找到指定的國家, 就返回None return None # 將資料載入到一個列表中 filename = 'population_data.json' with open(filename) as f: pop_data = json.load(f) for pop_dict in pop_data: if pop_dict['Year'相關推薦
Python 資料視覺化—下載資料(CSV檔案格式、JSON格式)
Python 資料視覺化-下載資料CSV檔案格式、JSON格式 網上下載資料,並對這些資料進行視覺化,視覺化以兩種常見格式儲存的資料:CSV 和JSON。 我們將使用Python模組csv 來處理以CSV 1、CSV檔案格式: 最簡單的方式是將資料作
讀書筆記--python資料視覺化--001_讀取CSV檔案資料
#-*- coding: UTF-8 -*- ''' ################################################# # Author : 餘歡 # Date : Dec 26, 2015 2:25:39 PM
資料視覺化-------------------------------------下載資料學習(一)
下載資料,並進行視覺化分析,以下學習兩種格式的資料:1.CSV,對應的使用Python模組的CSV模組來處理CSV檔案,2.json.對應使用json模組處理資料。 1.CSV檔案格式 CSV檔案是一系列的以逗號分割的資料,這樣利於程式提取資料。來做一個關於天氣的資料分析 import
Python資料視覺化之資料密度分佈
Python資料視覺化(一) 之資料密度分佈 資料密度分佈是資料的主要特徵之一,Python中有幾種方法可以對資料密度進行視覺化。在此利用小鼠胚胎幹細胞基因表達譜作為例子: 1. 利用直方圖(histgram) Histogram 為最常用的檢
【每週一本書】之《資料視覺化與資料探勘》:基於Tableau和SPSS Modeler圖形介面
資料猿導讀】 大資料時代正在改變著我們的生活、工作和思維,要讓大資料發揮出最大價值,最重要的手段
推薦好輪子【Echarts資料視覺化】圖表外掛 相容ie6、7、8
前幾天在網上找一些圖表外掛,無意間發現的一個外掛,開源來自百度商業前端資料視覺化團隊。簡單的貼一些他的簡介:官網:http://echarts.baidu.com/echarts2/index.html介紹ppt:http://echarts.baidu.com/echart
【D3.js資料視覺化系列教程】(二十五)--載入csv檔案
csv檔案由csv資料生成的圓環! 1. 載入csv資料用到d3.csv函式,第一個引數是地址,第二個引數是個回撥函式d3.csv("http://localhost:8080/spring/D3da
【13】Caffe學習系列:資料視覺化環境(python介面)配置
caffe程式是由c++語言寫的,本身是不帶資料視覺化功能的。只能藉助其它的庫或介面,如opencv, python或matlab。更多人會使用python介面來進行視覺化,因為python出了個比較強大的東西:ipython notebook, 現在的最新版本改名叫jupyter notebook
python pandas+matplotlib 簡化資料視覺化
一、pandas中的繪圖函式 1.series繪製圖像 # 準備一個Series s = Series(np.random.randn(10),index=np.arange(10,110,10)) # 最簡單的畫個圖 s.plot() plt.show() 2.Data
Python資料處理 | (三) Matplotlib資料視覺化
本篇部落格所有示例使用Jupyter NoteBook演示。 Python資料處理系列筆記基於:Python資料科學手冊電子版 下載密碼:ovnh 示例程式碼 下載密碼:02f4 目錄 一、Matplotlib常用技巧 1.匯入
關於python中幾種資料視覺化圖形
python中我們一般用的最多的是matplotlib圖形庫,本人在寫文章,做報告時,深感matplotlib圖形比較單一化,這裡介紹幾種關於python的圖形庫 (1)seaborn 是基於matplotlib的高階版,主要針對的資料探勘和機器學習的變數特徵選取,可以用非常短小的程式碼就可
Python資料視覺化之密度圖的繪製
密度圖表現與資料值對應的邊界或域物件的一種理論圖形表示方法。一般用於呈現連續變數。 *摘自百度百科* 在電腦科學當中,資料的視覺化常常被提起。近日,在影象處理當中,需要統計圖片中的人流密度並繪製相應密度圖,於是小小研究一番。效果如下: 所有程式碼儲存在Github上。 首
【python學習筆記】45:認識Matplotlib和pyecharts資料視覺化
學習《Python3爬蟲、資料清洗與視覺化實戰》時自己的一些實踐。 Matplotlib資料視覺化 資料準備 import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv("E:/Data/p
python基礎之資料視覺化matplotlib
資料視覺化圖示的繪製需要安裝matplotlib庫,安裝方法:cmd下pip install matplotlib,以及numpy庫,安裝法法:cmd下pip install numpy。使用numpy生產影象繪製需要的資料,如果已經有了資料可以讀取資料到陣
資料視覺化:CSV格式,JSON格式
1、下載CSV格式資料,進行視覺化 csv.reader()建立一個與檔案有關聯的閱讀器(reader)物件,reader處理檔案中的第一行資料,並將每一項資料都儲存在列表中 head_row = next(reader) 返回檔案的下一行,CSV檔案第一行為標頭檔案 datetime.strptime
python之資料視覺化
各種圖形簡介 線性圖:plt.plot(x,y,*argv) 條形圖:plt.bar(x,y)x和y的長度應相等 水平條形圖:plt.barh(x,y)x軸成垂直,y軸水平而已 條形圖高度表示某專案內的資料個數,由於分組資料具有連續性,直方圖的各矩形通常是連續排列,而條形圖則是分開排
python --資料視覺化
python --資料視覺化 一、python -- pyecharts庫的使用 pyecharts--> 生成Echarts圖示的類庫 1、安裝: pip install pyecharts pip install pyecharts_snapshot &nbs
python --資料視覺化(二)
一、NumPy 1、簡介: 官網連結:http://www.numpy.org/ NumPy是Python語言的一個擴充程式庫。支援高階大量的維度陣列與矩陣運算,此外也針對陣列運算提供大量的數學函式庫 2、基本功能: 快速高效的多維陣列物件ndarray 用於對陣列執行元素級計算以及直
Python資料視覺化的四種簡易方法
摘要: 本文講述了熱圖、二維密度圖、蜘蛛圖、樹形圖這四種Python資料視覺化方法。 資料視覺化是任何資料科學或機器學習專案的一個重要組成部分。人們常常會從探索資料分析(EDA)開始,來深入瞭解資料,並且建立視覺化確實有助於讓問題更清晰和更容易理解,尤其是對於那些較大的高維度資料集。在專
Python進行資料視覺化分析快速教程例項
Jupyter Notebook介紹 Jupyter Notebook是一個互動式筆記本,支援執行 40 多種程式語言。IPython notebook 是一個基於 IPython REPL 的 web 應用,安裝 IPython 後在終端輸入 ipython notebook 即可啟動服務。j
-