
Spark Streaming 容錯機制分析
Spark容錯級別
Driver級別的容錯
在Driver級別的容錯具體為DAG生成的模板,即DStreamGraph,RecevierTracker中儲存的元資料資訊和JobScheduler中儲存的Job進行的進度情況等資訊,只要通過checkpoint就可以了,每個Job生成之前進行checkpoint,在Job生成之後再進行checkpoint,如果出錯的話就從checkpoint中恢復。
Executor級別的容錯
在Executor級別的容錯具體為接收資料的安全性和任務執行的安全性。在接收資料安全性方面,一種方式是Spark Streaming接收到資料預設為MEMORY_AND_DISK_2的方式,在兩臺機器的記憶體中,如果一臺機器上的Executor掛了,立即切換到另一臺機器上的Executor,這種方式一般情況下非常可靠且沒有切換時間。另外一種方式是WAL(Write Ahead Log),在資料到來時先通過WAL機制將資料進行日誌記錄,如果有問題則從日誌記錄中恢復,然後再把資料存到Executor中,再進行其他副本的複製。WAL這種方式對效能有影響,在生產環境中不常用,一般使用Kafka儲存,Spark Streaming接收到資料丟失時可以從Kafka中回放。在任務執行的安全性方面,靠RDD的容錯。
Spark Streaming 容錯機制
容錯的概念
容錯 指的是一個系統在部分模組出現故障時還能否持續的對外提供服務,一個高可用的系統應該具有很高的容錯性;對於一個大的集群系統來說,機器故障、網路異常等都是很常見的,Spark這樣的大型分散式計算叢集提供了很多的容錯機制來提高整個系統的可用性
引入
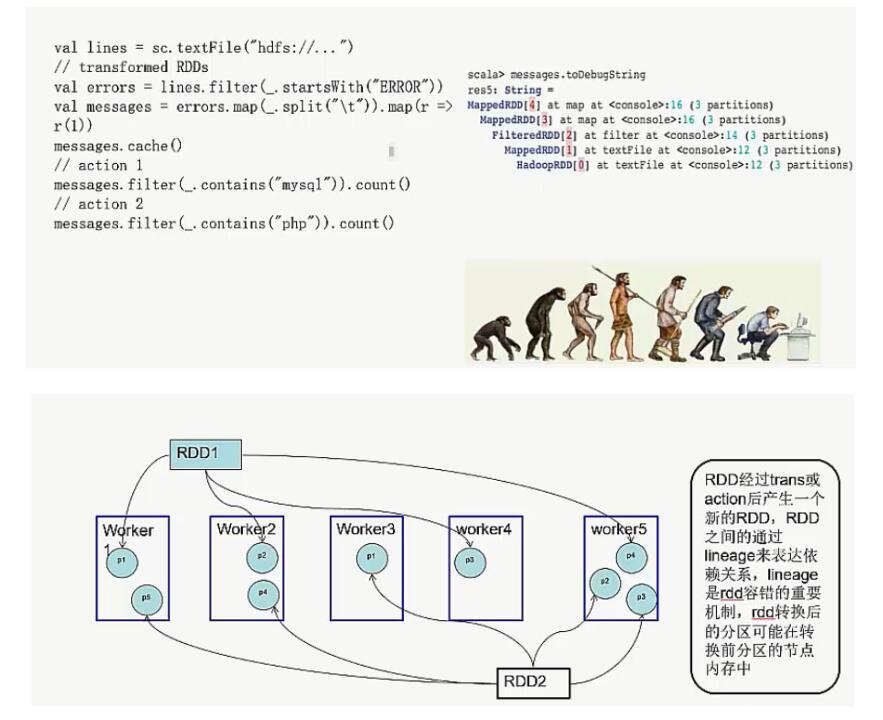
面向大規模資料分析,資料檢查點操作成本很高,需要通過資料中心的網路連線在機器之間複製龐大的資料集,而網路頻寬往往比記憶體頻寬低得多,同時還需要消耗更多的儲存資源。 因此,Spark選擇記錄更新的方式。但是,如果更新粒度太細太多,那麼記錄更新成本也不低。因此,RDD只支援粗粒度轉換,即只記錄單個塊上執行的單個操作,然後將建立RDD的一系列變換序列(每個RDD都包含了他是如何由其他RDD變換過來的以及如何重建某一塊資料的資訊。因此RDD的容錯機制又稱“血統(Lineage)”容錯)記錄下來,以便恢復丟失的分割槽。 Lineage本質上很類似於資料庫中的重做日誌(Redo Log),只不過這個重做日誌粒度很大,是對全域性資料做同樣的重做進而恢復資料。
容錯原理
在容錯機制中,如果一個節點宕機了,而且運算窄依賴,則只要把丟失的父RDD分割槽重算即可,不依賴於其他節點。而寬依賴需要父RDD的所有分割槽都存在,重算就很昂貴了。可以這樣理解開銷的經濟與否:在窄依賴中,在子RDD的分割槽丟失、重算父RDD分割槽時,父RDD相應分割槽的所有資料都是子RDD分割槽的資料,並不存在冗餘計算。在寬依賴情況下,丟失一個子RDD分割槽重算的每個父RDD的每個分割槽的所有資料並不是都給丟失的子RDD分割槽用的,會有一部分資料相當於對應的是未丟失的子RDD分割槽中需要的資料,這樣就會產生冗餘計算開銷,這也是寬依賴開銷更大的原因。因此如果使用Checkpoint運算元來做檢查點,不僅要考慮Lineage是否足夠長,也要考慮是否有寬依賴,對寬依賴加Checkpoint是最物有所值的,可以節約大量的系統資源。
基於RDD的容錯機制
Spark Streaming的容錯機制是基於RDD的容錯機制
主要表現為:
1.checkpoint
2 .基於血統(lineage)的高度容錯機制
3 .出錯了之後會從出錯的位置從新計算,而不會導致重複計算
Lineage機制
利用記憶體加快資料載入,在眾多的其它的In-Memory類資料庫或Cache類系統中也有實現,Spark的主要區別在於它處理分散式運算環境下的資料容錯性(節點實效/資料丟失)問題時採用的方案。
為了保證RDD中資料的魯棒性,RDD資料集通過所謂的血統關係(Lineage)記住了它是如何從其它RDD中演變過來的。
相比其它系統的細顆粒度的記憶體資料更新級別的備份或者LOG機制,RDD的Lineage記錄的是粗顆粒度的特定資料轉換(Transformation)操作(filter, map, join etc.)行為。當這個RDD的部分分割槽資料丟失時,它可以通過Lineage獲取足夠的資訊來重新運算和恢復丟失的資料分割槽。這種粗顆粒的資料模型,限制了Spark的運用場合,但同時相比細顆粒度的資料模型,也帶來了效能的提升。
RDD在Lineage依賴方面分類
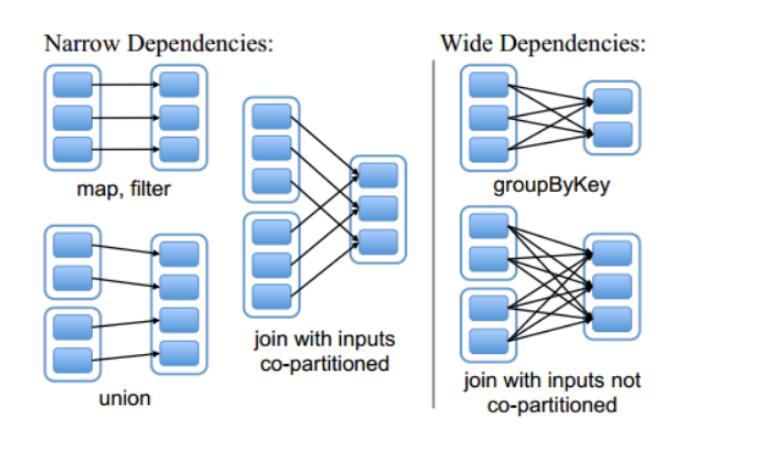
Narrow Dependencies與Wide Dependencies用來解決資料容錯時的高效性。
Narrow Dependencies
某個具體的RDD,其分割槽partition a最多子Rdd中一個分割槽partition b依賴,此種情況只有Map任務, 是不需要傳送shuffle過程的, 窄依賴又分為1:1和N:1兩種。
Narrow Dependencies是指父RDD的每一個分割槽最多被一個子RDD的分割槽所用,表現為一個父RDD的分割槽對應於一個子RDD的分割槽或多個父RDD的分割槽對應於一個子RDD的分割槽,也就是說一個父RDD的一個分割槽不可能對應一個子RDD的多個分割槽。
Wide Dependencies
或稱為為ShuffleDependency,與Hadoop MR的Shuffle的資料依賴相似,寬依賴需要計算所有父RDD對應分割槽的資料,然後在節點之間進行shuffle。
Wide Dependencies是指子RDD的分割槽依賴於父RDD的多個分割槽或所有分割槽,也就是說存在一個父RDD的一個分割槽對應一個子RDD的多個分割槽。對與Wide Dependencies,這種計算的輸入和輸出在不同的節點上,lineage方法對與輸入節點完好,而輸出節點宕機時,通過重新計算,這種情況下,這種方法容錯是有效的,否則無效,因為無法重試,需要向上其祖先追溯看是否可以重試(這就是lineage,血統的意思),Narrow Dependencies對於資料的重算開銷要遠小於Wide Dependencies的資料重算開銷。
如圖
分散式資料集容錯方式
在RDD計算,通過checkpoint進行容錯,做checkpoint有兩種方式:
資料檢查點(checkpoint data)和記錄資料的更新(logging the updates)
使用者可以控制採用哪種方式來實現容錯,預設是logging the updates方式,通過記錄跟蹤所有生成RDD的轉換(transformations)也就是記錄每個RDD的lineage(血統)來重新計算生成丟失的分割槽資料。
Tast執行任務失敗解決方案

開始Checkpoint 詳解
檢查點機制-checkpoint
什麼是檢查點機制
Spark Streaming 週期性地把應用資料儲存到諸如HDFS 或Amazon S3 這樣的可靠儲存系統中以供恢復時使用的機制叫做檢查點機制
舉例
· 資料庫 checkpoint 過程中一般把記憶體中的變化進行持久化到物理頁, 這時候就可以斬斷依賴鏈, 就可以把 redo 日誌刪掉了, 然後更新下檢查點,
· hdfs namenode 的元資料 editlog, Secondary namenode 會把 edit log 應用到 fsimage, 然後刷到磁碟上, 也相當於做了一次 checkpoint, 就可以把老的 edit log 刪除了。
· spark streaming 中對於一些 有狀態的操作, 這在某些 stateful 轉換中是需要的,在這種轉換中,生成 RDD 需要依賴前面的 batches,會導致依賴鏈隨著時間而變長。為了避免這種沒有盡頭的變長,要定期將中間生成的 RDDs 儲存到可靠儲存來切斷依賴鏈, 必須隔一段時間進行一次進行一次 checkpoint。
·
· cache 和 checkpoint 是有顯著區別的, 快取把 RDD 計算出來然後放在記憶體中, 但是RDD 的依賴鏈(相當於資料庫中的redo 日誌), 也不能丟掉, 當某個點某個 executor 宕了, 上面cache 的RDD就會丟掉, 需要通過 依賴鏈重放計算出來, 不同的是, checkpoint 是把 RDD 儲存在 HDFS中, 是多副本可靠儲存,所以依賴鏈就可以丟掉了,就斬斷了依賴鏈, 是通過複製實現的高容錯。但是有一點要注意, 因為checkpoint是需要把 job 重新從頭算一遍, 最好先cache一下, checkpoint就可以直接儲存快取中的 RDD 了, 就不需要重頭計算一遍了, 對效能有極大的提升。
檢查點機制的作用
檢查點本質:通過將RDD寫入Disk做檢查點。
控制發生失敗時需要重算的狀態數
Spark Streaming通過lineage重算,檢查點機制則可以控制需要在lineage中回溯多遠提供驅動器程式容錯
如果流計算應用中的驅動器程式崩潰了,你可以重啟驅動器程式,並讓驅動器程式從檢查點 恢復,這樣SparkStreaming就可以讀取之前執行的程式處理資料的進度,並從那裡繼續。
即是 是為了通過Lineage做容錯的輔助,lineage過長會造成容錯成本過高,這樣就不如在中間階段做檢查點容錯,如果之後節點出現問題而丟失分割槽,從做檢查點的RDD開始重做lineage,就會減少開銷
checkpoint 兩種型別的資料
Metadata(元資料) checkpointing - 儲存定義了 Streaming 計算邏輯至類似 HDFS 的支援容錯的儲存系統。用來恢復 driver,元資料包括:
配置 - 用於建立該 streaming application 的所有配置
DStream 操作 - DStream 一些列的操作
未完成的 batches - 那些提交了 job 但尚未執行或未完成的 batches RDD Data checkpointing - 儲存已生成的RDDs至可靠的儲存
metadata checkpointing 主要用來恢復 driver;而 RDD資料的 checkpointing 對於
stateful 轉換操作是必要的。
對於window和stateful操作必須checkpoint(Spark Streaming會檢查並給出提示)
通過StreamingContext的checkpoint來指定目錄,預設按照batch Duration來做checkpoint
通過DStream的checkpoint指定當前DStream的間隔時間間隔必須是slide interval的倍數。
檢查點機制-checkpoint的形式
checkpoint 的形式是將類 Checkpoint的例項序列化後寫入外部儲存,值得一提的是,有專門的一個執行緒來做將序列化後的 checkpoint 寫入外部儲存的操作。類 Checkpoint 包含以下資料:
除了 Checkpoint 類,還有 CheckpointWriter 類用來匯出 checkpoint,
CheckpointReader 用來匯入

checkpoint 檢查點機制-checkpoint的侷限
Spark Streaming 的 checkpoint 機制看起來很美好,卻有一個硬傷。
前面提到最終刷到外部儲存的是類 Checkpoint 物件序列化後的資料。那麼在 Spark Streaming application 重新編譯後,再去反序列化 checkpoint 資料就會失敗。這個時候就必須新建 StreamingContext。
針對這種情況,在我們結合 Spark Streaming + kafka 的應用中,需要自行維護了消費的
offsets,這樣一來即使重新編譯 application,還是可以從需要的 offsets 來消費資料。對於其他的情況需要大家根據實際需求自行處理
Driver節點容錯
如果你想讓你的 application能從driver失敗中恢復,你的application要滿足: 若 application 為首次重啟,將建立一個新的 StreamContext 例項
如果 application 是從失敗中重啟,將會從 checkpoint 目錄匯入 checkpoint 資料來重新建立 StreamingContext 例項

除呼叫 getOrCreate 外, 你還需要編寫在驅動器程式崩潰時重啟驅動器程序的程式碼。
在 yarn 模式下,driver 是執行在 ApplicationMaster 中,若 ApplicationMaster 掛掉,
yarn 會自動在另一個節點上啟動一個新的 ApplicationMaster。Spark standalone模式下:
./bin/spark-submit --deploy-mode cluster --supervise --master spark://... App.jar
Worker節點容錯
為了應對工作節點失敗的問題,Spark Streaming 使用與Spark 的容錯機制相同的方法,根據不同的輸入源,分兩種情況:
使用可靠輸入源—如HDFS
由於輸入資料是可靠的,所有資料都可以重新計算,因此不會丟失資料 使用基於網路接收的輸入源—例如Kafka、Flume等
接收到的資料會在叢集的不同節點間複製(預設複本數為2)
一個工作節點失效,在恢復時可以從另一個工作節點的資料中重新計算
如果是接收資料的工作節點失效,那就可能丟失資料(資料已經收到但是還未複製到其他節 點,也沒有處理完是失效了)
處理保證所有轉換操作為精確一次保證(Spark Streaming 工作節點的容錯保障)
輸出操作在把結果儲存到外部儲存時,寫結果的任務可能因故障而執行多次,一些資料可能 也就被寫了多次
可以使用事務操作來寫入外部系統(即原子化地將一個RDD分割槽一次寫入),或者設計冪等 的更新操作(即多次運行同一個更新操作仍生成相同的結果)。比如Spark Streaming 的saveAs...File 操作會在一個檔案寫完時自動將其原子化地移動到最終位置上,以此確保每個輸出檔案只存在一份。
checkpoint 正確使用簡單舉例

使用很簡單, 就是設定一下 checkpoint 目錄,然後再rdd上呼叫 checkpoint 方法, action 的時候就對資料進行了 checkpoint。