spark streaming容錯實現
阿新 • • 發佈:2018-12-08
如果Executor故障,所有未被處理的資料會丟失,解決辦法可以通過wal(hbase,hdfs/WAL)方式,將資料預先寫到hdfs或者s3
如果Driver故障,driver程式就會停止,所有executor都會失去丟失,停止計算過程,解決辦法需要配置和程式設計
1.配置diver程式自動重啟,使用特定的clustermanager實現,
2。重啟時從宕機的地方重啟。通過檢查點機制,就可以實現該功能。
//可以使用本地目錄或者hdfs
jsc.checkpoint(“d:…”)
不要使用new的方式來建立sparkstreamingcontext上下文物件,而是通過工廠的方式JavaStreamingContext().getOrCreate()方法來建立上下文物件,在建立上下文物件的時候,首先會檢查檢查點目錄,看是否job允許,沒有job允許就直接new新的。
程式碼如下:
public class JavaSparkStreamingWCApp { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setAppName("wc"); conf.setMaster("local[4]"); //建立spark應用上下文,間隔批次是2 /** * 這裡為了做到容錯,不使用new的方式來建立streamingContext物件, * 而是通過工廠的方式JavaStreamingContext.getOrCreate()方式來建立, *這種方式建立的好處是:在啟動程式的時候回首先去檢查點目錄檢查 * 如果有資料,就直接從資料中回覆,如果沒有資料,就直接new一個新的。 * 實驗:一下程式碼實現了當driver正常執行的時候,宕機, * 重啟會自動從以前的checkpoint點拿取資料,重新計算。 */ Function0<JavaStreamingContext> contextFunction = new Function0<JavaStreamingContext>() { //首次建立context物件呼叫該方法 public JavaStreamingContext call() throws Exception { JavaStreamingContext jsc = new JavaStreamingContext(conf, Seconds.apply(2)); JavaReceiverInputDStream<String> socket = jsc.socketTextStream("mini4", 9999); /*變化的程式碼放到處這裡是一個視窗函式,視窗的長度是24小時,滑塊的間隔是2秒*/ JavaDStream<Long> dsCount = socket.countByWindow(new Duration(24 * 60 * 60 * 1000), new Duration(2000)); dsCount.print(); //切記,這裡一定要寫檢查點 jsc.checkpoint("g:/log/data/spark/ck/java_spark_streaming_wc"); return jsc; } }; //失敗重新連線的時候會經過檢查點。 JavaStreamingContext jsc = JavaStreamingContext.getOrCreate("g:/log/data/spark/ck/java_spark_streaming_wc",contextFunction); jsc.start(); try { jsc.awaitTermination(); } catch (InterruptedException e) { e.printStackTrace(); } } }
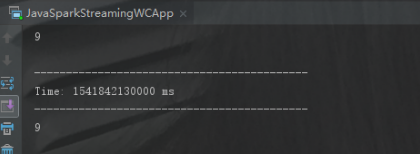
當Driver宕機後,重啟後會從checkpoint端自動獲取未讀取的資料資料。
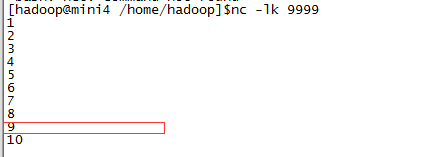
這裡是驗證上面的程式碼,mini4上使用
當輸入到8的時候將程式停止,然後mini4上不停的輸入資料,再次重啟還會從9以後開始讀取