
K-Means演算法、非負矩陣分解(NMF)與影象壓縮(Python)
K-Means演算法是最基礎的聚類演算法、也是最常用的機器學習演算法之一。 本教程中,我們利用K-Means對影象中的畫素點進行聚類,然後用每個畫素所在的簇的中心點來代替每個畫素的真實值,從而達到影象壓縮的目的。
非負矩陣分解(Non-negative Matrix Factorization, NMF)是一種對非負矩陣進行低維近似逼近的常見方法,同樣也能達到影象壓縮的目的。
0. 前言
K Means演算法比NMF演算法慢很多,尤其是當聚類數較大時,所以實驗時請耐心等待。此外,由於兩者重建影象的原理不同,所以兩者的視覺也相差很大,k Means犧牲了顏色的個數而保留了邊界和形狀,而NMF犧牲了形狀以及邊界卻儘量保留顏色。整個實驗過程中會產生一些有趣風格的影象,注意留意哦!
完整的程式碼在第4節。
1. 影象的讀取
本教程以臺灣省臺北市最高建築“臺北101”大廈的夜景圖為例,該圖的解析度為600 * 800。
點選這裡下載實驗圖片。
{kind=link}
我們需要skimage、numpy、matplotlib.pyplot這三個庫來實現影象的讀取以及顯示。
import numpy as np
import matplotlib.pyplot as plt
from skimage import io利用io.imread直接讀取影象檔案,並存入np.ndarray型別的變數d。注意:為了影象在plt中無色差地顯示,請一定要將d中的元素轉成0到1的浮點數。
d = io.imread('taibei101.jpg') d = np.array(d, dtype=np.float64) / 255
d是三維array,第一個維度代表行數,第二個維度代表列數,第三個維度代表該影象是RGB影象,每個畫素點由三個數值組成。
d.shape(600, 800, 3)呼叫plt.imshow函式便可以顯示影象。
plt.axis('off')
plt.imshow(d); plt.show()); plt.show()
2. K Means 壓縮影象
在我們的例子當中,每個畫素點都是一個數據;每個資料擁有三個特徵,分別代表R(紅色),G(綠色),B(藍色)。 K Means是一種常見的聚類方法,其思想就是讓“距離”近的資料點分在一類。這裡的“距離”就是指兩個畫素點RBG差值的平方和的根號。
Dist(P1,P2)=∥P1−P2∥2Dist(P1,P2)=∥P1−P2∥2
K Means壓縮影象的原理是,用每個聚類(cluster)的中心點(center)來代替聚類中所有畫素原本的顏色,所以壓縮後的影象只保留了KK個顏色。
假如這個600×800600×800的影象中每個畫素點的顏色都不一樣,那麼我們需要
800×600×3=1440000800×600×3=1440000
個數來表示這個影象。對於K Means壓縮之後的影象,我們只需要
800×600×1+K×3800×600×1+K×3
個數來表示。800×600×1800×600×1是因為每個畫素點需要用一個數來表示其歸屬的簇,K×3K×3是因為我們需要記錄KK箇中心點的RGB數值。所以經過K Means壓縮後,我們只需要三分之一左右的數就可以表示影象。
下面的函式KMeansImage(d, n_colors)就可以用來生成n_colors個顏色構成的影象。
from sklearn.cluster import KMeans
def KMeansImage(d, n_colors):
w, h, c = d.shape
dd = np.reshape(d, (w * h, c))
km = KMeans(n_clusters=n_colors)
km.fit(dd)
labels = km.predict(dd)
centers = km.cluster_centers_
new_img = d.copy()
for i in range(w):
for j in range(h):
ij = i * h + j
new_img[i][j] = centers[labels[ij]]
return {'new_image': new_img, 'center_colors': centers}執行以上函式,我們可以看看在不同的KK的取值之下,影象壓縮的效果。
plt.figure(figsize=(12, 9))
plt.imshow(d); plt.axis('off')
plt.show()
for i in [2, 3, 5, 10, 30]:
print('Number of clusters:', i)
out = KMeansImage(d, i)
centers, new_image = out['center_colors'], out['new_image']
plt.figure(figsize=(12, 1))
plt.imshow([centers]); plt.axis('off')
plt.show()
plt.figure(figsize=(12, 9))
plt.imshow(new_image); plt.axis('off')
plt.show()Number of clusters: 2


Number of clusters: 3
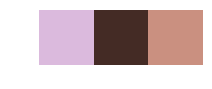

Number of clusters: 5


Number of clusters: 10
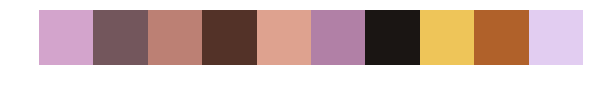

Number of clusters: 30


NMF壓縮影象
非負矩陣分解(NMF)是一個常用的對矩陣進行填充、平滑的演算法。一個著名的案例就是Netflix利用NMF來填充“使用者-電影”矩陣。這裡,我們將對三個顏色逐一進行矩陣分解。
------
你想知道自己水平如何?不如來做套資料科學、機器學習的自測題(戳這裡,以及戳這裡)
更多中美企業校招、社招機器學習、資料科學崗位面試題(看這裡)