
非監督學習—K-means演算法聚類學習筆記
非監督學習: 無類別標記的
一、 K-means 演算法:
1. Clustering 中的經典演算法,資料探勘十大經典演算法之一
2. 引數k
已知引數 k ;然後將事先輸入的n個數據物件劃分為 k個聚類以便使得所獲得的聚類滿足:同一聚類中的物件相似度較高;而不同聚類中的物件相似度較小。
3. 演算法思路:以空間中k個點為中心進行聚類,對最靠近他們的物件歸類。通過迭代的方法,逐次更新各聚類中心的值,直至得到最好的聚類結果。
4. 演算法描述:
(1)任意適當選擇c個類的初始中心;
(2)在第k次迭代中,對任意一個樣本,求其到c各中心的距離,將該樣本歸到距離最短的中心所在的類;
(3)利用均值等方法更新該類的中心值;
(4)對於所有的c個聚類中心,如果利用(2)(3)的迭代法更新後,值保持不變,則迭代結束, 否則繼續迭代。
5. 演算法流程
輸入:類的數量k、 資料data[n];
(1) 選擇k個初始中心點,例如c[0]=data[0],…c[k-1]=data[k-1];
(2) 對於data[0]….data[n], 分別與c[0]…c[k-1]比較,假定與c[i]差值最少,就標記為i;
(3) 對於所有標記為i點,重新計算c[i]={ 所有標記為i的data[j]之和}/標記為i的個數;
(4) 重複(2)(3),直到所有c[i]值的變化小於給定閾值。
6. 優點:速度快,簡單
缺點:最終結果跟初始點選擇相關,容易陷入區域性最優,需直到k值
二、舉例
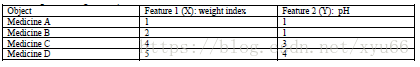
將上述四個藥片歸為兩類:
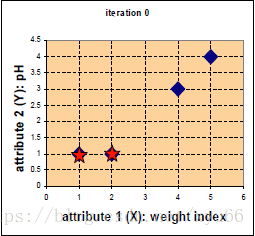
藍色為藥片,五角星為隨機選取的中心點,四個點到c1(1,1)的距離分別為0、1、3.61、5 ; 四個點到c2(2,1)的距離為1、0、2.83、4.24;


新的中心點:c1>>(1,1); c2>>(11/3,8/3) 新的圖示如下:
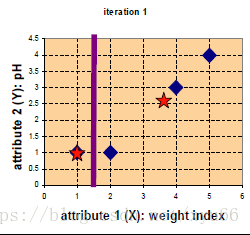

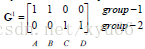



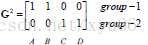
完成分類,迭代停止。(停止條件:分類不變,或分類變化小於一個值,或指定迭代次數)
三、python實現
import numpy as np def kmeans(x, k, maxIt): # maxIt是迭代次數 numPoints, numDim = x.shape # 傳入的行數 dataSet = np.zeros((numPoints, numDim + 1)) # 多新增一列,作為標記 dataSet[:,:-1] = x # 除了最後一列其他的和x一樣 centroids = dataSet[np.random.randint(numPoints, size= k), :] # 選出k個行數,作為中心點 centroids[:, -1] = range(1, k+1) iterations = 0 # 第多少次迴圈 oldCentroids = None # 舊的中心點 while not shouldstop(oldCentroids, centroids, iterations, maxIt): print("-" * 50) print("iteration: ", iterations) print("dataSet: \n", dataSet) print("centroids: \n", centroids) oldCentroids = np.copy(centroids) iterations += 1 updataLabels(dataSet, centroids) # 重新歸類label centroids = getCentroids(dataSet, k) # 更新中心點 return dataSet def shouldstop(oldCentroids, centroids, iterations, maxIt): if iterations > maxIt: # 是否到預設迭代次數 return True return np.array_equal(oldCentroids, centroids) # 比較值中心點是否相等 def updataLabels(dataSet, centroids): numPoints, numDim = dataSet.shape for i in range(0, numPoints): # 計算 dataSet[i, -1] = getLabelFromClosestCentroid(dataSet[i,:-1], centroids) # 對比距離,返回最近中心點的標記 def getLabelFromClosestCentroid(dataSetRow, centroids): label = centroids[0, -1] minDist = np.linalg.norm(dataSetRow - centroids[0,:-1]) # 返回兩個向量的距離 for i in range(1, centroids.shape[0]): dist = np.linalg.norm(dataSetRow - centroids[i,:-1]) if dist < minDist: minDist = dist label = centroids[i, -1] print("minDistance: ", minDist) return label def getCentroids(dataSet, k): result = np.zeros((k, dataSet.shape[1])) # 初始化 shape[1] 為列數 for i in range(1, k+1): # 將所有標籤相同的點找出來,求均值 oneCluster = dataSet[dataSet[:, -1] == i, :-1] # 等於某一列的所有標籤找出來 result[i - 1, :-1] = np.mean(oneCluster, axis=0) # 求均值,賦到除了最後一列的所有,axis=0 每一行所有列 result[i - 1, -1] = i # 賦標籤 return result x1 = np.array([1, 1]) x2 = np.array([2, 1]) x3 = np.array([4, 3]) x4 = np.array([5, 4]) testX = np.vstack((x1, x2, x3, x4)) # 將四個點堆成一個矩陣 result = kmeans(testX, 2, 10) print("*" * 50) print("final result:\n", result)
相關推薦
非監督學習—K-means演算法聚類學習筆記
非監督學習: 無類別標記的 一、 K-means 演算法: 1. Clustering 中的經典演算法,資料探勘十大經典演算法之一 2. 引數k 已知引數 k ;然後將事先輸入的n個數據物件劃分為 k個聚類以便使得所獲得的聚類滿足:同一聚類中的物件相似度較高;而不同聚
使用K-means演算法聚類灰度圖
github資料集: 智慧演算法的課件和參考資料以及實驗程式碼 我們可以用k-means演算法將灰度圖分成N個梯度 我們知道,一般的彩色影象指的是在RGB顏色空間下的影象,這樣的影象三個通道分別是R(red)G(green)B(blue)。而灰度圖指的是單通道的,將三通道的影象
Python之使用K-Means演算法聚類消費行為特徵資料分析(異常點檢測)
源資料(這裡僅展示10行):程式:#-*- coding: utf-8 -*- #使用K-Means演算法聚類消費行為特徵資料 import numpy as np import pandas as pd #引數初始化 inputfile = '../data/consu
機器學習--K-means演算法(聚類,無監督學習)
一、基本思想 聚類屬於無監督學習,以往的迴歸、樸素貝葉斯、SVM等都是有類別標籤y的,也就是說樣例中已經給出了樣例的分類。而聚類的樣本中卻沒有給定y,只有特徵x,比如假設宇宙中的星星可以表示成三維空間中的點集。聚類的目的是找到每個樣本x潛在的類別y,並將同類別y的樣本x
機器學習——K-means演算法(聚類演算法)
聚類 在說K-means聚類演算法之前必須要先理解聚類和分類的區別。 分類其實是從特定的資料中挖掘模式,作出判斷的過程。比如Gmail郵箱裡有垃圾郵件分類器,一開始的時候可能什麼都不過濾,在日常使用過程中,我人工對於每一封郵件點選“垃圾”或“不是垃圾”,過一段時間,Gmail就體現出
python_sklearn機器學習算法系列之K-Means(硬聚類演算法)
本文主要目的是通過一段及其簡單的小程式來快速學習python 中sklearn的K-Means這一函式的基本操作和使用,注意不是用python純粹從頭到尾自己構建K-Means,既然sklearn提供了現成的我們直接拿來用就可以了,當然K-Means原理還
吳恩達機器學習 - 無監督學習——K-means演算法 吳恩達機器學習 - 無監督學習——K-means演算法
原 吳恩達機器學習 - 無監督學習——K-means演算法 2018年06月25日 12:02:37 離殤灬孤狼 閱讀數:181
機器學習實踐(十七)—sklearn之無監督學習-K-means演算法
一、無監督學習概述 什麼是無監督學習 之所以稱為無監督,是因為模型學習是從無標籤的資料開始學習的。 無監督學習包含演算法 聚類 K-means(K均值聚類) 降維
聚類分析(K-means 層次聚類和基於密度DBSCAN演算法三種實現方式)
之前也做過聚類,只不過是用經典資料集,這次是拿的實際資料跑的結果,效果還可以,記錄一下實驗過程。 首先: 確保自己資料集是否都完整,不能有空值,最好也不要出現為0的值,會影響聚類的效果。 其次: 想好要用什麼演算法去做,K-means,層次聚類還是基於密
K-means 和 K-medoids演算法聚類分析
1 聚類是對物理的或者抽象的物件集合分組的過程,聚類生成的組稱為簇,而簇是資料物件的集合。 (1)簇內部的任意兩個物件之間具有較高的相似度。(2)屬於不同的簇的兩個物件間具有較高的相異度。 2 相異度可以根據描述物件的屬性值來計算,最常用的度
K-means均值聚類演算法的原理與實現
轉自:http://blog.csdn.net/xiaolewennofollow/article/details/45541159 K-均值聚類演算法的原理與實現 聚類是一種無監督的學習,它將相似的物件歸到同一個簇中,聚類方法幾乎可以應用於所有物件,簇內的物件越相似,聚類的效果越好,本文主要介紹K-均值聚
無監督學習——K-means演算法
筆記: 核心步驟: 那我們就實現這兩個函式就行啦: findClosestCentroids.m(把每個點染色): function idx = fi
Python_sklearn機器學習庫學習筆記(五)k-means(聚類)
# K的選擇:肘部法則 如果問題中沒有指定K的值,可以通過肘部法則這一技術來估計聚類數量。肘部法則會把不同K值的 成本函式值畫出來。隨著K值的增大,平均畸變程度會減小;每個類包含的樣本數會減少,於是樣本 離其重心會更近。但是,隨著K值繼續增大,平均畸變程度的改善效果會不斷減
基於K-means Clustering聚類算法對電商商戶進行級別劃分(含Octave仿真)
fprintf highlight 初始 load ogre max init 金額 定時 在從事電商做頻道運營時,每到關鍵時間節點,大促前,季度末等等,我們要做的一件事情就是品牌池打分,更新所有店鋪的等級。例如,所以的商戶分入SKA,KA,普通店鋪,新店鋪這4個級別,對於
K-均值(K-means)聚類算法
簡單 read 原理 包含 append 添加 url 學習 readlines 聚類是一種無監督的學習,它將相似的對象歸到同一個簇中。 這篇文章介紹一種稱為K-均值的聚類算法,之所以稱為K-均值是因為它可以發現k個不同的簇,且每個簇的中心采用簇中所含值的均值計算而成。 聚
全面了解R語言中的k-means如何聚類?
聚類下面將在iris數據集上演示k-means聚類的過程。先從iris數據集中移除Species屬性,然後再對數據集iris調用函數kmeans,並將聚類結果存儲在變kmeans.result中。在下面的代碼中,簇的數目設置為3。iris2 <- irisiris2$Species <- NULL
機器學習--K-means演算法
概述 聚類(K-mean)是一種典型的無監督學習。 採用距離作為相似性的評價指標,即認為兩個物件的距離越近,其相似度就越大。 該演算法認為類簇是由距離靠近的物件組成的,因此把得到緊湊且獨立的簇作為最終目標。 核心思想 通過迭代尋找k個類簇的一種劃分方案,使得用這k個類簇的均值來代
TF-IDF + K-Means 中文聚類例子 - scala
Demo僅供參考 使用spark1.6 import java.io.{BufferedReader, InputStreamReader} import java.util.Arrays import org.ansj.splitWord.analysis.ToAnaly
機器學習——K-Means演算法
Unsupervised Learning task learning a distribution from sample(GMM/VAE) clustering(PAC) feature learning 按照演算法目的,無監督演算法大體可分為上述三類,
K-means 影象聚類
import numpy as np import tensorflow as tf from tensorflow.contrib.factorization import KMeans # 本程式碼演示K均值的用法, tensorflow版本必須大於等於V1.1.0 #