
使用Nomad構建彈性基礎結構:重新啟動任務
Nomad是一個功能強大、靈活的排程器,適用於長期執行的服務和批處理任務。通過廣泛的驅動程式,Nomad可以排程基於容器的工作負載、原始二進位制檔案、java應用程式等等。Nomad操作簡單,易伸縮,與HashiCorp Consul(服務註冊),Vault(祕鑰管理)產品無縫整合。
Nomad為開發人員提供了自助服務基礎設施。Nomad任務使用高階宣告格式語法進行描述,該語法是版本控制的,並將基礎結構作為程式碼進行推廣。一旦任務提交給Nomad,它就負責部署和確保服務的可用性。執行Nomad的好處之一是提高了計算基礎設施的可靠性和彈性。
歡迎來到我們關於用Nomad構建彈性基礎設施的系列文章,在這裡我們將探討Nomad如何處理意外故障、停機和叢集基礎設施的日常維護,通常不需要操作員干預。
在第一篇文章中,我們將瞭解Nomad如何自動重啟失敗和無響應的任務,以及如何將反覆失敗的任務重新排程到其他節點。
Tasks and job declaration
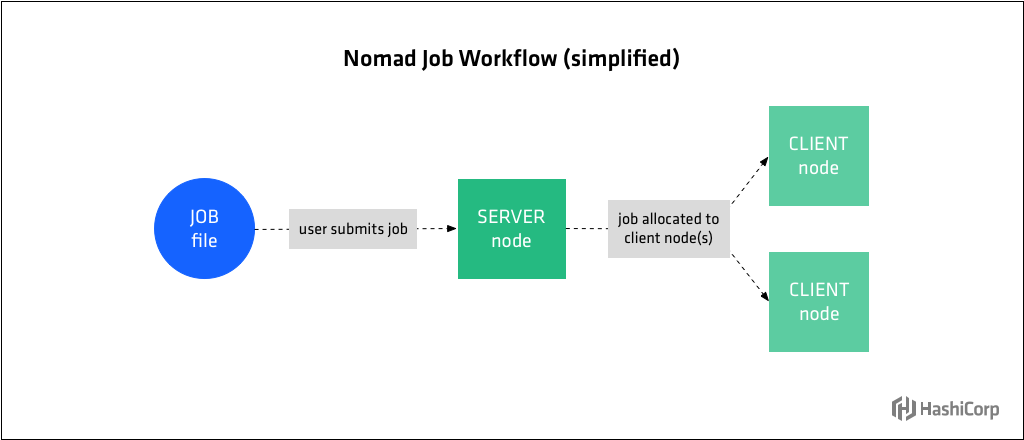
一個Nomad task是由其驅動程式在Nomad客戶端節點上執行的命令、服務、應用程式或其他工作負載。task可以是短時間的批處理作業或長時間執行的服務,例如web應用程式、資料庫伺服器或API。
Tasks是在用HCL語法的宣告性jobspec中定義的。job檔案提交給Nomad服務端,服務端決定在何處以及如何將job檔案中定義的task分配給客戶端節點。另一種概念化的理解是:job規範表示工作負載的期望狀態,Nomad服務端建立並維護實際狀態。
job定義的層次是:job→group→task。每個job檔案只有一個job,但是一個job可能有多個group,每個group可能有多個task。group包含一組要放在同一個節點上的task。
下面是一個定義Redis工作負載的簡單job檔案:
job "example" { datacenters = ["dc1"] type = "service" constraint { attribute = "${attr.kernel.name}" value = "linux" } group "cache" { count = 1 task "redis" { driver = "docker" config { image = "redis:3.2" } resources { cpu = 500 # 500 MHz memory = 256 # 256MB } } } }
job作者可以為他們的工作負載定義約束和資源。約束通過核心型別和版本等屬性限制了工作負載在節點上的位置。資源需求包括執行task所需的記憶體、網路、CPU等。
有三種類型的job:system、service和batch,它們決定排程程式Nomad將用於此job中的task。service 排程器被設計用來排程永遠不會宕機的長壽命服務。batch作業對短期效能波動的敏感性要小得多,壽命也很短,幾分鐘到幾天就可以完成。system排程器用於註冊應該在滿足作業約束的所有客戶端上執行的作業。當客戶端加入叢集或轉換到就緒狀態時也會呼叫它。
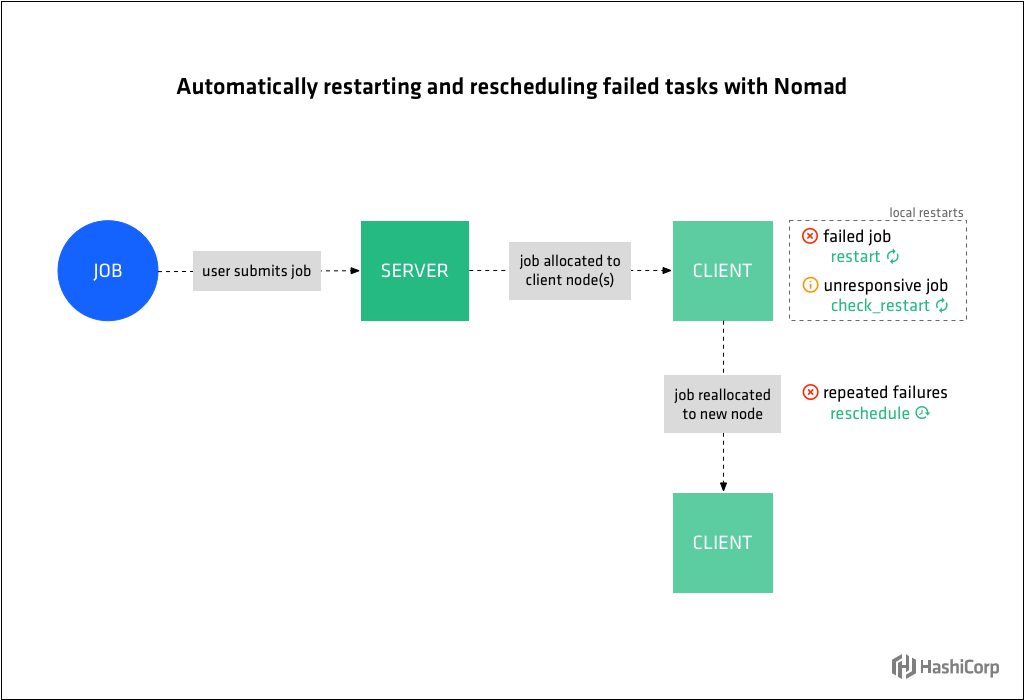
Nomad允許job作者為自動重新啟動失敗和無響應的任務指定策略,並自動將失敗的任務重新排程到其他節點,從而使任務工作負載具有彈性。
Restarting failed tasks
Task failure can occur when a task fails to complete successfully, as in the case of a batch type job or when a service fails due to a fatal error or running out of memory.
Nomad will restart failed tasks on the same node according to the directives in the restart stanza of the job file. Operators specify the number of restarts allowed with attempts, how long Nomad should wait before restarting the task with delay, the amount of time to limit attempted restarts to with interval. Use (failure) mode to specify what Nomad should do if the job is not running after all restart attempts within the given interval have been exhausted.
The default failure mode is is fail which tells Nomad not to attempt to restart the job. This is the recommended value for non-idempotent jobs which are not likely to succeed after a few failures. The other option isdelay which tells Nomad to wait the amount of time specified by intervalbefore restarting the job.
The following restart stanza tells Nomad to attempt a maximum of 2 restarts within 1 minute, delaying 15s between each restart and not to attempt any more restarts after those are exhausted. This is also the default restart policy for non-batch type jobs.
group "cache" {
...
restart {
attempts = 2
interval = "30m"
delay = "15s"
mode = "fail"
}
task "redis" {
...
}
}This local restart behavior is designed to make tasks resilient against bugs, memory leaks, and other ephemeral issues. This is similar to using a process supervisor such as systemd, upstart, or runit outside of Nomad.
Restarting unresponsive tasks
Another common scenario is needing to restart a task that is not yet failing but has become unresponsive or otherwise unhealthy.
Nomad will restart unresponsive tasks according to the directives in the check_restart stanza. This works in conjunction with Consul health checks. Nomad will restart tasks when a health check has failed limit times. A value of 1 causes a restart on the first failure. The default, 0, disables health check based restarts.
Failures must be consecutive. A single passing check will reset the count, so services alternating between a passing and failing state may not be restarted. Use grace to specify a waiting period to resume health checking after a restart. Set ignore_warnings = true to have Nomad treat a warning status like a passing one and not trigger a restart.
The following check_restart policy tells Nomad to restart the Redis task after its health check has failed 3 consecutive times, to wait 90 seconds after restarting the task to resume health checking, and to restart upon a warning status (in addition to failure).
task "redis" {
...
service {
check_restart {
limit = 3
grace = "90s"
ignore_warnings = false
}
}
}In a traditional data center environment, restarting failed tasks is often handled with a process supervisor, which needs to be configured by an operator. Automatically detecting and restarting unhealthy tasks is more complex, and either requires custom scripts to integrate monitoring systems or operator intervention. With Nomad they happen automatically with no operator intervention required.
Rescheduling failed tasks
Tasks that are not running successfully after the specified number of restarts may be failing due to an issue with the node they are running on such as failed hardware, kernel deadlocks, or other unrecoverable errors.
Using the reschedule stanza, operators tell Nomad under what circumstances to reschedule failing jobs to another node.
Nomad prefers to reschedule to a node not previously used for that task. As with the restart stanza, you can specify the number of reschedule attempts Nomad should try with attempts, how long Nomad should wait between reschedule attempts with delay, and the amount of time to limit attempted reschedule attempts to with interval.
Additionally, specify the function to be used to calculate subsequent reschedule attempts after the initial delay with delay_function. The options are constant, exponential, and fibonacci. For service jobs, fibonacci scheduling has the nice property of fast rescheduling initially to recover from short lived outages while slowing down to avoid churn during longer outages. When using the exponential or fibonacci delay functions, use max_delay to set the upper bound for delay time after which it will not increase. Set unlimited to true or false to enable unlimited reschedule attempts or not.
To disable rescheduling completely, set attempts = 0 and unlimited = false.
The following reschedule stanza tells Nomad to try rescheduling the task group an unlimited number of times and to increase the delay between subsequent attempts exponentially, with a starting delay of 30 seconds up to a maximum of 1 hour.
group "cache" {
... reschedule {
delay = "30s"
delay_function = "exponential"
max_delay = "1hr"
unlimited = true
}
}
The reschedule stanza does not apply to system jobs because they run on every node.
As of Nomad version 0.8.4, the reschedule stanza applies during deployments.
In a traditional data center, node failures would be detected by a monitoring system and trigger an alert for operators. Then operators would need to manually intervene either to recover the failed node, or migrate the workload to another node. With the reschedule feature, operators can plan for the most common failure scenarios and Nomad will respond automatically, avoiding the need for manual intervention. Nomad applies sensible defaults so most users get local restarts and rescheduling without having to think about the various restart parameters.
Summary
In this first post in our series Building Resilient Infrastructure with Nomad, we covered how Nomad provides resiliency for computing infrastructure through automated restarting and rescheduling of failed and unresponsive tasks.
Operators specify Nomad’s local restart strategy for failed tasks with the restart stanza. When used in conjunction with Consul and the check_restart stanza, Nomad will locally restart unresponsive tasks according to the restart parameters. Operators specify Nomad’s strategy for rescheduling failed tasks with the reschedule stanza.
In the next post we’ll look at how the Nomad client enables fast and accurate scheduling as well as self-healing through driver health checks and liveliness heartbeats.
--------------------- 本文來自 HashiCorpChina 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/HashiCorpChina/article/details/81975248?utm_source=copy