
使用Nomad構建彈性基礎架構: 工作生命週期
這是Nomad構建彈性基礎架構系列(第1部分,第2部分)中的第三部分。在本系列中,我們將探討Nomad如何處理意外故障、停機和叢集基礎架構的日常維護,通常不需要操作員干預。
在本文中,我們將介紹Nomad如何通過提供一個一致的工作流來管理整個作業生命週期,從而為您的計算基礎設施增加彈性,包括用於更新和遷移作業的健壯選項,從而幫助最小化甚至消除停機時間。
操作job的工作流
Nomad作業規範允許操作員為執行job的所有方面指定模式。這包括任務、映象、部署策略、資源、優先順序、約束、服務註冊、加密和部署工作負載所需的其他資訊。
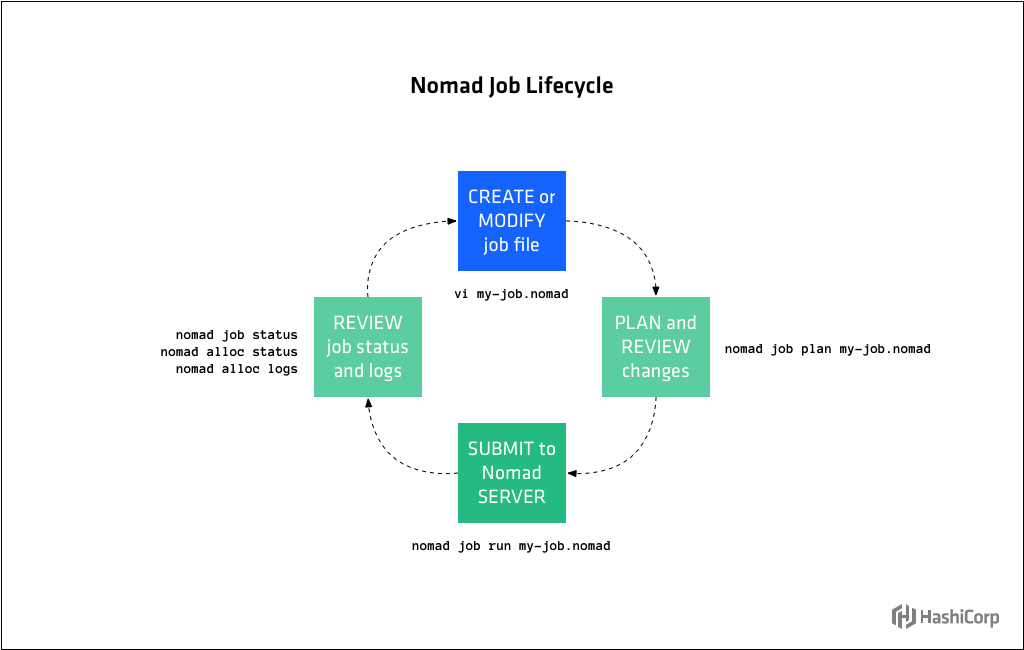
作業操作流程有四個主要步驟:
- 根據作業規範建立或修改作業檔案
- 使用Nomad伺服器計劃和檢查更改
- 將作業檔案提交給Nomad服務端
- (可選)檢查作業狀態和日誌
在更新作業時,有許多內建的更新策略可以在作業檔案中定義。更新策略可以幫助操作人員安全地管理新版本的作業。因為作業檔案定義了更新策略(藍/綠、滾動更新等),所以無論這是初始部署還是對現有作業的更新,工作流都保持不變。
update節指定Nomad在部署任務組的新版本時將使用的更新策略。如果省略,滾動更新和金絲雀將被禁用。
滾動和序列更新

在update節中,操作員指定與max_parallel併發地更新多少作業分配。將max_parallel設定為1,告訴Nomad採用序列升級策略,每次最多升級一個分配。將其設定為大於1的值將啟用並行升級,從而可以同時升級多個分配。
Nomad在更新下一個集合之前等待更新節點的健康檢查通過。使用health_check來指定確定分配健康狀況的機制。預設值是檢查,它告訴Nomad等待直到所有任務都執行並且Consul健康檢查通過。其他選項是task_states(所有任務都在執行,沒有失敗)和manual(操作員將使用HTTP API手動設定健康狀態)。
三個引數指定了在何種情況下分配被認為是健康的以及獲得這種狀態的最後期限。使用min_healthy_time指定分配在被標記為健康狀態之前必須處於健康狀態的最小時間,並解除對進一步的分配進行更新的阻塞。使用healthy_deadline來指定分配必須標記為健康的最後期限,之後分配將自動轉換為不健康的最後期限。最後,使用progress_deadline來指定分配必須被標記為健康的最後期限。最後期限從建立部署的第一個分配開始,並在部署轉換到健康狀態時重置分配。如果在進度截止日期之前沒有將分配轉換為健康狀態,則部署將被標記為失敗。
如果部署的一部分分配失敗,只要沒有超過progress_deadline, Nomad就會根據重新排程節中的引數重新排程它。這允許Nomad優雅地處理特定於某個節點的臨時錯誤。Nomad將繼續重新安排部署時間,直到progress_deadline被命中時,這個問題可能會隨著更新而發生,並且整個部署被標記為失敗。
使用auto_revert = true指定作業在部署失敗時應該自動恢復到最後的穩定版本。當作業的所有部署分配都標記為健康時,作業被標記為穩定。
下面的update節告訴Nomad每次執行滾動更新3,直到分配的所有任務都在執行,他們的Consul健康檢查通過至少10秒,然後才考慮分配是否健康。它為健康分配設定了5分鐘的最後期限,超過5分鐘後,Nomad就會標記它為不健康。而且,如果任何一個分配在10分鐘後不能恢復健康,整個部署將被標記為失敗,Nomad將自動恢復到最後一個已知的穩定部署。
job "example" {
update {
max_parallel = 3
health_check = "checks"
min_healthy_time = "10s"
healthy_deadline = "5m"
progress_deadline = "10m"
auto_revert = true
}
}
對於system作業,只強制執行max_parallel和stagger。作業以max_parallel速度更新,在下一次更新集之前等待的時間錯開了。
金絲雀部署

在開始滾動升級之前,金絲雀更新是測試作業新版本的有用方法。update節支援設定作業操作員在作業通過canary引數更改時希望Nomad建立的canaries的數量。在更新作業規範時,Nomad會建立canaries,而不會停止之前版本的分配。
這種模式允許操作人員對新作業版本有更高的信心,因為他們可以路由流量、檢查日誌等,以確定新應用程式正在正確地執行。
當canary設定為1或更多時,任何可能導致破壞性更新的作業更改都會導致Nomad建立指定數量的canaries,而不會停止之前的任何分配。一旦操作員確定canaries是健康的,就可以提升它們,Nomad將以max_parallel的速度對剩餘的分配進行滾動更新。Canary的推廣可以由操作員手動完成,也可以使用api進行自動化。
下面的更新節告訴Nomad使用1個canary執行canary的更新,一旦那個canary得到提升,就一次執行滾動更新3個來完成剩餘的分配。
job "example" {
update {
canary = 1
max_parallel = 3
}
}藍綠部署
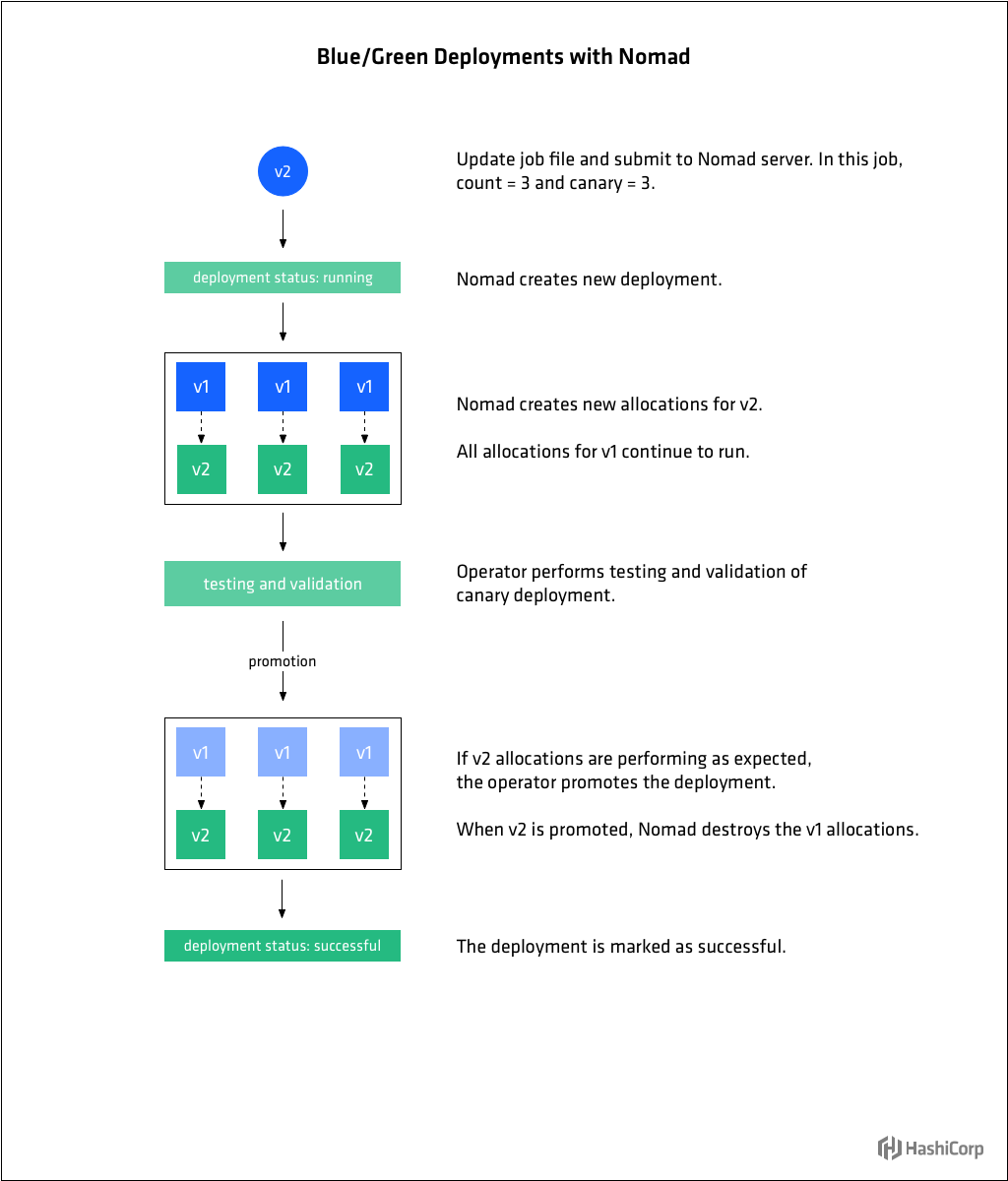
藍綠部署有其他幾個名稱,包括紅色/黑色或A/B,但概念通常是相同的。在藍綠部署中,部署的工作負載有兩個版本。每次只有一個版本是活動的,從一個版本到下一個版本的過渡階段除外。“主動”一詞往往意味著“接收流量”或“服務中”。
在Nomad中,可以通過在update節中設定canary的值來匹配組節中的count的值來啟用藍綠部署。當這些值是相同的,而不是做一個滾動升級現有的分配提交新版本的工作時,新版本組部署在現有的組旁邊。操作員可以驗證組的新版本是穩定的。當他們滿意時,組可以被提升,並且組的所有舊版本的分配都將被關閉。藍綠部署重複了升級過程中所需的資源,但由於組的原始版本未受影響,因此啟用了非常安全的部署。
下面的update節告訴Nomad在之前的分配仍在執行時,通過啟動3個canary分配(與count相同)來執行一個藍/綠更新。
group "cache" {
count = 3
update {
canary = 3
}
}Nomad的工作生命週期(包括更新)允許操作人員根據自己的情況使用最佳的更新過程,從而將對基礎設施的破壞降到最低,無論是滾動升級、金絲雀還是藍綠部署。操作人員可以混合、匹配和更改部署型別,而無需更改叢集管理工作流。
遷移任務和關閉節點
在本系列的第2部分中,我們討論了Nomad如何檢測客戶端節點何時發生故障,並自動重新排程在故障節點上執行的作業。
當你知道某個節點需要退出服務時,你可以退役,或者使用node drain命令“耗盡”它。這將切換給定節點的排幹模式。當一個節點被標記為要排干時,Nomad將不再安排該節點上的任何任務,並開始將所有現有的作業遷移到其他節點。繼續執行耗盡,直到所有的分配都遷移出節點,或者到達最後期限,此時所有的分配都被迫遷移出節點。
job作者可以使用migrate節來指定Nomad的策略,以便將任務從排幹節點遷移出去。遷移指令只適用於service型別作業,因為batch作業通常是短期的,system作業在每個客戶端節點上執行。對於計數為1的作業,不需要提供遷移節。因為作業只有一個例項,所以它將在啟動排放時立即被遷移。
使用max_parallel指定可以同時遷移的分配數。這個數字必須小於組的總數,因為count - max_parallel分配將在遷移期間保持執行。使用health_check指定確定分配健康狀態的機制。與update一樣,預設值是checks,它告訴Nomad等待直到所有任務都執行並且Consul健康檢查通過。另一個選項是task_states(所有正在執行的任務都沒有失敗)。遷移沒有手動健康檢查選項。
直到替換分配達到min_healthy_time或healthy_deadline的健康狀態時,節點排幹才會繼續。這允許大量機器被耗盡,同時確保這些節點上的作業不會導致任何停機。
下面的migrate節告訴Nomad要一次遷移一個分配,在5分鐘的期限內,只有在所有任務都執行並且相關的健康檢查持續了10秒或更長時間之後,才標記遷移後的分配是健康的。
job "example" {
migrate {
max_parallel = 1
health_check = "checks"
min_healthy_time = "10s"
healthy_deadline = "5m"
}
}migrate節是job作者用來定義他們的服務應該如何遷移的,而節點排幹最後期限是系統操作人員對一個排干時間的嚴格限制。
節點排幹是叢集維護的一個常規部分,這是由於伺服器維護和作業系統升級等原因造成的。在傳統資料中心中,操作人員需要與開發人員協調節點維護,以確保不會導致停機。相反,Nomad允許開發人員控制應用程式的遷移方式,這樣操作人員在進行叢集維護時就不需要緊密協作。
總結
在本系列使用Nomad構建彈性基礎架構的第三篇文章(第1部分、第2部分)中,我們介紹Nomad如何增加彈性的計算基礎設施提供一個一致的工作流管理整個生命週期的工作,包括可靠的部署選項更新和遷移工作,幫助最小化甚至消除停機時間。
作業的更新策略由作業檔案的update節控制。操作人員可以配置許多選項來安全地管理更新,包括:序列和並行更新、金絲雀和藍/綠部署。Nomad通過自動重新排程失敗的分配來優雅地處理部署期間的臨時問題,直到滿足部署的progress_deadline。
migrate節使job作者可以指定Nomad的策略,以便將任務從排幹節點遷移出去。這可以幫助操作人員執行叢集維護,而無需緊密協作,並在不導致停機的情況下執行許多節點的排幹。
在本系列的下一篇也是最後一篇文章中,我們將瞭解Nomad如何提供資料丟失的彈性,以及如何從中斷中恢復。