
高階java必會系列三:併發程式設計
FutureTask
Introduction
FutureTask這個元件是J.U.C裡面的,但不是AQS的子類,但是這個類對執行緒處理的結果很值得我們學習和在專案中使用。
在Java中一般通過繼承Thread類或者實現Runnable介面這兩種方式來建立多執行緒,但是這兩種方式都有個缺陷,就是不能在執行完成後獲取執行的結果,在Java 1.5之後提供了Callable和Future介面,通過它們就可以在任務執行完畢之後得到任務的執行結果。
Callable 與 Runnable
Callable介面定義,執行Callable任務可以拿到一個Future物件,表示非同步計算的結果。
@FunctionalInterface
public interface Callable<V> {
/**
* 計算結果或失敗時扔出異常
* @since 1.5
* @return 計算結果
* @throws 計算失敗扔出異常
*/
V call() throws Exception;
}Runnable介面定義,由於run()方法返回值為void型別,所以在執行完任務之後無法返回任何結果。
@FunctionalInterface public interface Runnable { /** * 當一個物件實現<code>Runnable</code>介面建立一個執行緒,這個物件通過覆寫 * run方法處理執行緒邏輯,並且Thread類啟動該執行緒,執行Runnable處理執行緒邏輯 * @since 1.0 */ public abstract void run(); }
可以看到Callable是個泛型介面,泛型V就是要call()方法返回的型別。Callable介面和Runnable介面很像,都可以被另外一個執行緒執行,Callable功能更強大些,正如前面所說的,Runnable不會返回資料也不能丟擲異常,而Callable可以有返回值與可以丟擲異常。
Future
Future介面代表非同步計算的結果,通過Future介面提供的方法可以檢視非同步計算是否執行完成,或者等待執行結果並獲取執行結果,同時還可以取消執行。也就是說Future就是對於具體的Runnable或者Callable任務的執行結果進行取消、查詢是否完成、獲取結果。通常不能從執行緒中獲得方法的返回值,這時Future
Future可以監控目標執行緒呼叫call()的情況。總結來說,Future可以得到執行緒任務方法的返回值。
public interface Future<V> {
/*
* 取消非同步任務的執行。
* 如果非同步任務已經完成或者已經被取消,或者由於某些原因不能取消,則會返回false;
* 如果任務還沒有被執行,則會返回true並且非同步任務不會被執行;
* 如果任務已經開始執行了但是還沒有執行完成:
* 若mayInterruptIfRunning為true,則會立即中斷執行任務的執行緒並返回true
* 若mayInterruptIfRunning為false,則會返回true且不會中斷任務執行執行緒
*/
boolean cancel(boolean mayInterruptIfRunning);
/*
* 判斷任務是否被取消,如果任務在結束(正常執行結束或者執行異常結束)前被取消則返回true,否則返回false。
*/
boolean isCancelled();
/*
* 判斷任務是否已經完成,如果完成則返回true,否則返回false。需要注意的是:任務執行過程中發生異常、任務被取消也屬於任務已完成,也會返回true。
*/
boolean isDone();
/*
* 獲取任務執行結果:
* 如果任務還沒完成則會阻塞等待直到任務執行完成
* 如果任務被取消則會丟擲CancellationException異常
* 如果任務執行過程發生異常則會丟擲ExecutionException異常
* 如果阻塞等待過程中被中斷則會丟擲InterruptedException異常
*/
V get() throws InterruptedException, ExecutionException;
/*
* 帶超時時間的get()版本,如果阻塞等待過程中超時則會丟擲TimeoutException異常。
*/
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
} 因為Future只是一個介面,所以是無法直接用來建立物件使用的,因此就有了下面的FutureTask。
FutureTask
Future只是一個介面,不能直接用來建立物件,FutureTask是Future的實現類。
public interface RunnableFuture<V> extends Runnable, Future<V> {}
public class FutureTask<V> implements RunnableFuture<V> {
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
} 從上面兩個類結構,可以得知FutureTask最終還是執行Callable型別的任務。如果在FutureTask建構函式中傳入Runnable,會轉換成Callable型別。
FutureTask實際上實現了Runnable與Future介面,所以它既可以作為Runnable被執行緒執行,又可以作為Future得到Callable的返回值。好處:假設有個很費時的邏輯需要計算,並且返回這個計算值,同時這個值又不是馬上需要,那麼就可以使用這個組合,用另外一個執行緒計算返回值,而當前執行緒在使用這個返回值之前,可以做其他的操作,等到需要這個返回值時,才通過Future得到。
案例
@Slf4j
public class FutureExample {
/**
* Callable任務
*/
static class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
log.info("do something in callable");
Thread.sleep(5000);
return "Done";
}
}
public static void main(String[] args) throws Exception {
//1.生成執行緒池
ExecutorService executorService = Executors.newCachedThreadPool();
//執行緒池提交Callable任務,並且得到Future
Future<String> future = executorService.submit(new MyCallable());
log.info("do something in main");
Thread.sleep(1000);
//呼叫Future.get()時,如果任務執行緒還未執行完畢,則會一直阻塞在此,等待執行緒任務完成,然後拿到結果
String result = future.get();
log.info("result:{}", result);
}
}
以上Future與以下FutureTask要實現的效果是一樣的。
@Slf4j
public class FutureTaskExample {
public static void main(String[] args) throws Exception {
FutureTask<String> futureTask = new FutureTask<String>(new Callable<String>() {
@Override
public String call() throws Exception {
log.info("do something in callable");
Thread.sleep(5000);
return "Done";
}
});
new Thread(futureTask).start();
log.info("do something in main");
// 1. 呼叫isDone()判斷任務是否結束
if(!futureTask.isDone()) {
System.out.println("Task is not done");
try {
//阻塞主執行緒一秒鐘
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
String result = futureTask.get();
log.info("result:{}", result);
}
}Fork/Join
Introduction
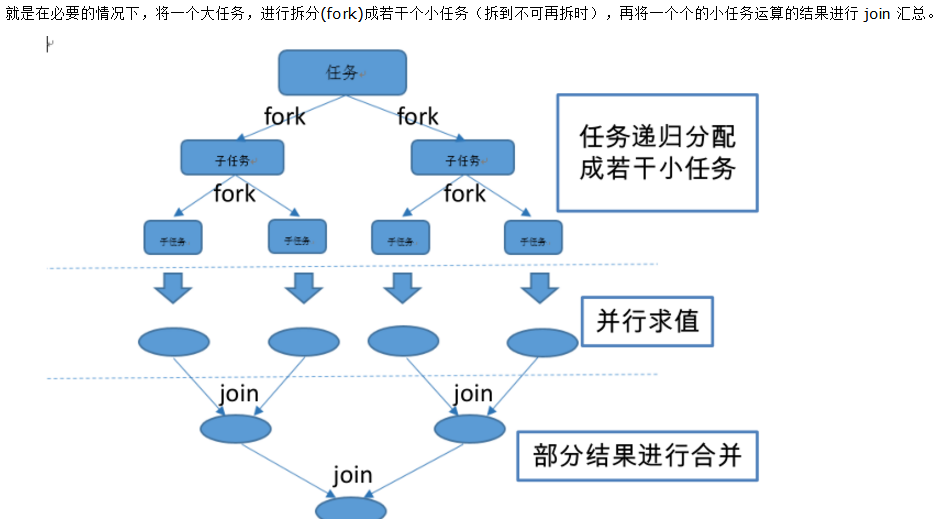
Fork/Join框架是Java7提供了的一個用於並行執行任務的框架, 是一個把大任務分割成若干個小任務,最終彙總每個小任務結果後得到大任務結果的框架。它的思想與MapReduce類似,從字面上理解,Fork即把一個大任務,切割成若干個子任務並行執行,Join即把若干個子任務結果進行合併,最後得到大任務的結果,主要採取工作竊取演算法。
工作竊取(work-stealing)演算法是指某個執行緒從其他佇列裡竊取任務來執行。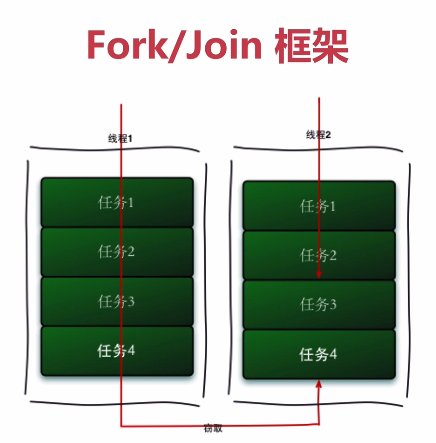
假如我們需要做一個比較大的任務,我們可以把這個任務分割為若干互不依賴的子任務,為了減少執行緒間的競爭,於是把這些子任務分別放到不同的佇列裡,併為每個佇列建立一個單獨的執行緒來執行佇列裡的任務,執行緒和佇列一一對應,比如A執行緒負責處理A佇列裡的任務。但是有的執行緒會先把自己佇列裡的任務幹完,而其他執行緒對應的佇列裡還有任務等待處理。幹完活的執行緒與其等著,不如去幫其他執行緒幹活,於是它就去其他執行緒的佇列裡竊取一個任務來執行。而在這時它們會訪問同一個佇列,所以為了減少竊取任務執行緒和被竊取任務執行緒之間的競爭,通常會使用雙端佇列,被竊取任務執行緒永遠從雙端佇列的頭部拿任務執行,而竊取任務的執行緒永遠從雙端佇列的尾部拿任務執行。
工作竊取演算法的優點是充分利用執行緒進行平行計算,並減少了執行緒間的競爭,其缺點是在某些情況下還是存在競爭,比如雙端佇列裡只有一個任務時。並且消耗了更多的系統資源,比如建立多個執行緒和多個雙端佇列。
對於Fork/Join框架而言,當一個任務正在等待它使用Join操作建立的子任務結束時,執行這個任務的工作執行緒,尋找其他並未被執行的任務,並開始執行,通過這種方式,執行緒充分利用它們的執行時間,來提高應用程式的效能。為了實現這個目標,Fork/Join框架執行的任務有一些侷限性:
1. 任務只能使用Fork、Join操作來作為同步機制,如果使用了其他同步機制,那他們在同步操作時,工作執行緒則不能執行其他任務。如:在框架的操作中,使任務進入睡眠,那麼在這個睡眠期間內,正在執行這個任務的工作執行緒,將不會執行其他任務
2. 所執行的任務,不應該執行IO操作,如讀和寫資料檔案
3. 任務不能丟擲檢查型異常,必須通過必要的程式碼處理它們
核心是兩個類:ForkJoinTask與ForkJoinPool。Pool主要負責實現,包括上面所介紹的工作竊取演算法,管理工作執行緒和提供關於任務的狀態以及它們的執行資訊;Task主要提供在任務中,執行Fork與Join操作的機制。
引用[並行流與序列流 Fork/Join框架的一張圖來說明過程
Example
我們先來看一下Fork/Join框架的演示:
@Slf4j
//Recursive遞迴的意思,把大任務不斷的拆分成小任務,即是一個遞迴拆分任務的一個過程
//RecursiveTask<T>,T表示任務的返回值
public class ForkJoinTaskExample extends RecursiveTask<Integer> {
//設定分割的閾值
public static final int threshold = 2;
private int start;
private int end;
public ForkJoinTaskExample(int start, int end) {
this.start = start;
this.end = end;
}
//任務
@Override
protected Integer compute() {
int sum = 0;
//如果任務足夠小就計算任務
boolean canCompute = (end - start) <= threshold;
if (canCompute) {
//任務足夠小的時候,直接計算,不進行分裂計算
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任務大於閾值,就分裂成兩個子任務計算
int middle = (start + end) / 2;
/**
* 下面可能會產生遞迴操作
*/
//繼續分裂任務
ForkJoinTaskExample leftTask = new ForkJoinTaskExample(start, middle);
ForkJoinTaskExample rightTask = new ForkJoinTaskExample(middle + 1, end);
// 執行子任務
leftTask.fork();
rightTask.fork();
// 等待任務執行結束合併其結果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
// 合併子任務
sum = leftResult + rightResult;
}
//返回結果
return sum;
}
public static void main(String[] args) {
//生成一個池
ForkJoinPool forkjoinPool = new ForkJoinPool();
// 生成一個計算任務,計算1+2+3+4+...+100
ForkJoinTaskExample task = new ForkJoinTaskExample(1, 100);
//執行一個任務,將任務放入池中,並開始執行,並用Future接收
Future<Integer> result = forkjoinPool.submit(task);
try {
log.info("result:{}", result.get());
} catch (Exception e) {
log.error("exception", e);
}
}
} 通過這個例子讓我們再來進一步瞭解ForkJoinTask,任務類繼承RecursiveTask,ForkJoinTask與一般的任務的主要區別在於它需要實現compute()方法,在這個方法裡,首先需要判斷任務是否足夠小,如果足夠小就直接執行任務。如果不足夠小,就必須分割成兩個子任務,每個子任務在呼叫fork()方法時,又會進入compute()方法,看看當前子任務是否需要繼續分割成孫任務,如果不需要繼續分割,則執行當前子任務並返回結果。使用join()方法會等待子任務執行完並得到其結果。
Main Class
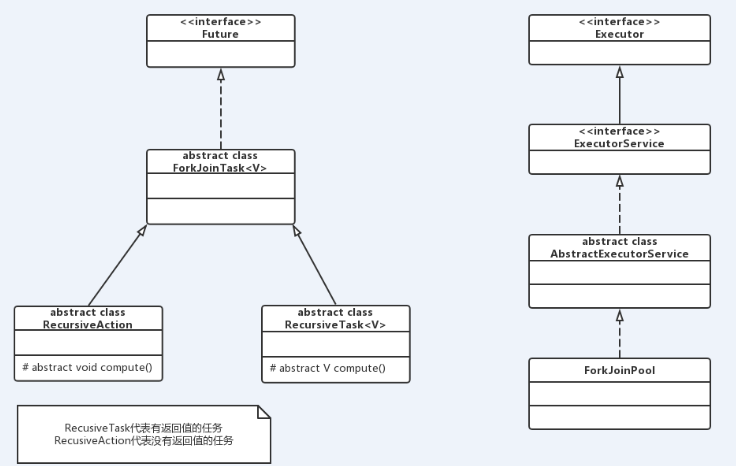
上面提到,Fork/Join框架中的兩個核心類ForkJoinTask與ForkJoinPool,並且從上面的例子可以知道,宣告ForkJoinTask後,將其加入到ForkJoinPool中,並返回一個Future物件。
* ForkJoinPool :ForkJoinTask需要通過ForkJoinPool來執行,任務分割出的子任務會新增到當前工作執行緒所維護的雙端佇列中,進入佇列的頭部。當一個工作執行緒的佇列裡暫時沒有任務時,它會隨機從其他工作執行緒的佇列的尾部獲取一個任務。
* ForkJoinTask:我們要使用ForkJoin框架,必須首先建立一個ForkJoin任務。它提供在任務中執行fork()和join()操作的機制,通常情況下我們不需要直接繼承ForkJoinTask類,而只需要繼承它的子類,Fork/Join框架提供了以下兩個子類:
* RecursiveAction:用於沒有返回結果的任務。
* RecursiveTask :用於有返回結果的任務。
Exception
ForkJoinTask在執行的時候可能會丟擲異常,但是我們沒辦法在主執行緒裡直接捕獲異常,所以ForkJoinTask提供了isCompletedAbnormally()方法來檢查任務是否已經丟擲異常或已經被取消了,並且可以通過ForkJoinTask的getException()方法獲取異常。
public abstract class ForkJoinTask<V> implements Future<V>, Serializable {
/** ForkJoinTask執行狀態 */
volatile int status; // 直接被ForkJoin池和工作執行緒訪問
static final int DONE_MASK = 0xf0000000; // mask out non-completion bits
static final int NORMAL = 0xf0000000; // must be negative
static final int CANCELLED = 0xc0000000; // must be < NORMAL
static final int EXCEPTIONAL = 0x80000000; // must be < CANCELLED
static final int SIGNAL = 0x00010000; // must be >= 1 << 16
static final int SMASK = 0x0000ffff; // short bits for tags
/**
* @Ruturn 任務是否扔出異常或被取消
*/
public final boolean isCompletedAbnormally() {
return status < NORMAL;
}
/**
* 如果計算扔出異常,則返回異常
* 如果任務被取消了則返回CancellationException。如果任務沒有完成或者沒有丟擲異常則返回null
*/
public final Throwable getException() {
int s = status & DONE_MASK;
return ((s >= NORMAL) ? null :
(s == CANCELLED) ? new CancellationException() :
getThrowableException());
}
}Analysis
ForkJoinPool
public class ForkJoinPool extends AbstractExecutorService {
/**
* ForkJoinPool,它同ThreadPoolExecutor一樣,也實現了Executor和ExecutorService介面。它使用了
* 一個無限佇列來儲存需要執行的任務,而執行緒的數量則是通過建構函式傳入,如果沒有向建構函式中傳入希
* 望的執行緒數量,那麼當前計算機可用的CPU數量會被設定為執行緒數量作為預設值。
*/
public ForkJoinPool() {
this(Math.min(MAX_CAP,Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}
//有多個構造器,這裡省略
volatile WorkQueue[] workQueues; // main registry
static final class WorkQueue {
final ForkJoinWorkerThread owner; // 工作執行緒
ForkJoinTask<?>[] array; // 任務
//傳入的是ForkJoinPool與指定的一個工作執行緒
WorkQueue(ForkJoinPool pool, ForkJoinWorkerThread owner) {
this.pool = pool;
this.owner = owner;
// Place indices in the center of array (that is not yet allocated)
base = top = INITIAL_QUEUE_CAPACITY >>> 1;
}
}
} ForkJoinPool中原始碼挺強大的,我只抽取了重要的部分進行分析。
* ForkJoinPool中維護了一組WorkQueue,也就是工作佇列,工作佇列中又維護了一個工作執行緒ForkJoinWorkerThread與一組工作任務ForkJoinTask
* WorkQueue是一個雙端佇列(Deque),即 Double Ended Queue ,Deque是一種具有佇列和棧的性質的資料結構,雙端佇列中的元素可以從兩端彈出,其限定插入和刪除操作在表的兩端進行。
* 每個工作執行緒在執行中產生新的任務(通常是因為呼叫了fork())時,會放入工作佇列的隊尾,並且工作執行緒在處理自己的工作佇列時,使用的是LIFO 方式,也就是說每次從隊尾取出任務來執行。
* 每個工作執行緒在處理自己的工作佇列同時,會嘗試竊取一個任務(或是來自於剛剛提交到 pool 的任務,或是來自於其他工作執行緒的工作佇列),竊取的任務位於其他執行緒的工作佇列的隊首,也就是說工作執行緒在竊取其他工作執行緒的任務時,使用的是 FIFO 方式。
* 在遇到 join() 時,如果需要 join 的任務尚未完成,則會先處理其他任務,並等待其完成。
* 在既沒有自己的任務,也沒有可以竊取的任務時,進入休眠。
public class ForkJoinPool extends AbstractExecutorService {
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task) {}
public <T> ForkJoinTask<T> submit(Callable<T> task) {}
public <T> ForkJoinTask<T> submit(Runnable task, T result) {}
public ForkJoinTask<?> submit(Runnable task) {}
}從上面來看,ForkJoinPool所提供的submit()方法中,有幾個過載。
ForkJoinPool自身也擁有工作佇列,這些工作佇列的作用是用來接收由外部執行緒(非 ForkJoinThread 執行緒)提交過來的任務,而這些工作佇列被稱為 submitting queue 。
ForkJoinTask
從上面的例子,我們可以知道,任務的操作,重要的是fork() 和 join(),我們可以假設這兩個的作用:
* fork():開啟一個新執行緒(或是重用執行緒池內的空閒執行緒),將任務交給該執行緒處理。
* join():等待該任務的處理執行緒處理完畢,獲得返回值。
但對我的這個假設,很明顯就不對的,當任務分解得越來越細時,所需要的執行緒數就會越來越多,而且大部分執行緒處於等待狀態。從ForkJoinPool的建構函式中,可以知道,工作執行緒的數量是指定的,或者說是按照系統預設的。
可以得出,我的假設是錯誤的,因此,並不是每個 fork() 都會促成一個新執行緒被建立,而每個 join() 也不是一定會造成執行緒被阻塞。這一點可以體現出work stealing 演算法的優勢。
public abstract class ForkJoinTask<V> implements Future<V>, Serializable {
/**
* 在當前任務正在執行的池中非同步執行此任務(如果適用)
* 或使用ForkJoinPool.commonPool()(如果不是ForkJoinWorkerThread例項)進行非同步執行
*/
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
private int doJoin() {
int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w;
return (s = status) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
(w = (wt = (ForkJoinWorkerThread)t).workQueue).
tryUnpush(this) && (s = doExec()) < 0 ? s :
wt.pool.awaitJoin(w, this, 0L) :
externalAwaitDone();
}
}fork()做的工作只有一件事,既是把任務推入當前工作執行緒的工作佇列裡。join()的工作則複雜得多,也是join()可以使得執行緒免於被阻塞的原因- 檢查呼叫
join()的執行緒是否是ForkJoinThread執行緒。如果不是(例如 main 執行緒),則阻塞當前執行緒,等待任務完成。如果是,則不阻塞。 - 檢視任務的完成狀態,如果已經完成,直接返回結果。
- 如果任務尚未完成,但處於自己的工作佇列內,則完成它。
- 如果任務已經被其他的工作執行緒偷走,則竊取這個小偷的工作佇列內的任務(以 FIFO 方式),執行,以期幫助它早日完成欲 join 的任務。
- 如果偷走任務的小偷也已經把自己的任務全部做完,正在等待需要 join 的任務時,則找到小偷的小偷,幫助它完成它的任務。
- 遞迴地執行第5步。
- 檢查呼叫
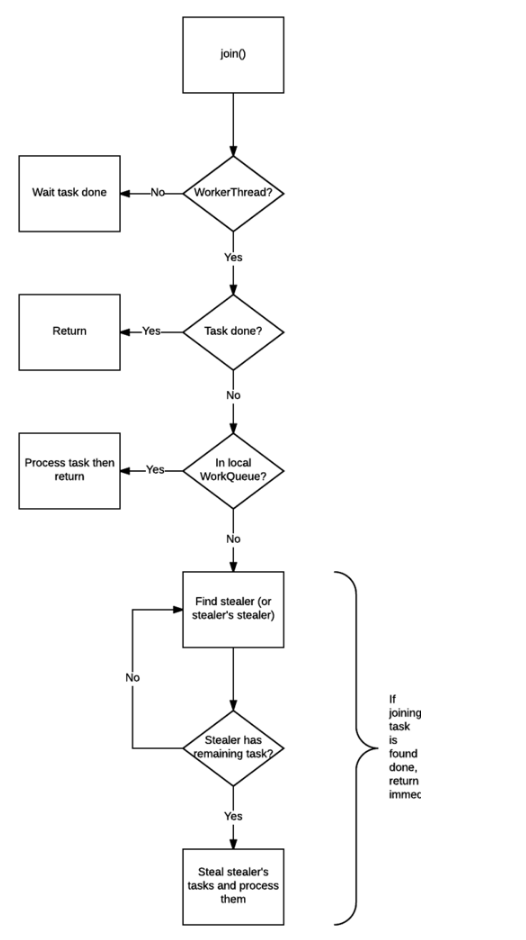
以上部分內容引用於Java 併發程式設計筆記:如何使用 ForkJoinPool 以及原理
BlockingQueue
引用一篇相關文章的一段話,初探BlockingQueue:BlockingQueue
多執行緒環境中,通過佇列可以很容易實現資料共享,比如經典的“生產者”和“消費者”模型中,通過佇列可以很便利地實現兩者之間的資料共享。假設我們有若干生產者執行緒,另外又有若干個消費者執行緒。如果生產者執行緒需要把準備好的資料共享給消費者執行緒,利用佇列的方式來傳遞資料,就可以很方便地解決他們之間的資料共享問題。但如果生產者和消費者在某個時間段內,萬一發生資料處理速度不匹配的情況呢?理想情況下,如果生產者產出資料的速度大於消費者消費的速度,並且當生產出來的資料累積到一定程度的時候,那麼生產者必須暫停等待一下(阻塞生產者執行緒),以便等待消費者執行緒把累積的資料處理完畢,反之亦然。然而,在concurrent包釋出以前,在多執行緒環境下,我們每個程式設計師都必須去自己控制這些細節,尤其還要兼顧效率和執行緒安全,而這會給我們的程式帶來不小的複雜度。好在此時,強大的concurrent包橫空出世了,而他也給我們帶來了強大的BlockingQueue。(在多執行緒領域:所謂阻塞,在某些情況下會掛起執行緒(即阻塞),一旦條件滿足,被掛起的執行緒又會自動被喚醒)
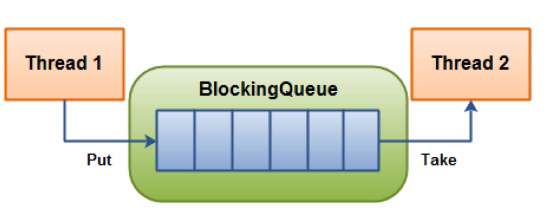
BlockingQueue即為阻塞佇列,是一個先進先出的佇列,在某些情況下,對阻塞佇列的訪問可能會造成阻塞,被阻塞的情況主要有兩種:
1. 當佇列滿時,進行入佇列操作。當一個執行緒試圖對一個已經滿了的佇列進行入隊操作時, 他將會阻塞,除非有另一個執行緒做了出佇列的操作。
2. 當佇列空時,進行出佇列操作。當一個執行緒試圖對一個空佇列進行出隊操作時,他也將會被阻塞,除非有另一個執行緒做了入隊的操作。
阻塞佇列是執行緒安全的,主要用在生產者與消費者的場景。上圖就是執行緒生產和消費的場景,負責生產的執行緒不斷的製造新物件並插入到阻塞佇列中,直到達到佇列的上限值,從而被阻塞,直到消費執行緒對佇列進行消費。同理,負責消費的執行緒不斷的從佇列中消費物件,直到這個佇列為空,這時消費執行緒將會被阻塞,除非佇列中有新的佇列被生產加入。
public interface BlockingQueue<E> extends Queue<E> {}
public interface Queue<E> extends Collection<E> {} BlockingQueue 是一個介面,繼承自 Queue,所以其實現類也可以作為 Queue 的實現來使用,而 Queue 又繼承自 Collection 介面。
BlockingQueue對插入操作、移除操作、獲取元素操作提供了四種不同的方法用於不同的場景中使用。我們使用不同的方法,都會有不同的表現。BlockingQueue 的各個實現都遵循了這些規則:
| Throws Exception | Special Value | Blocks | Times Out |
|---|---|---|---|
| insert | add(o) | offer(o) | put(o) |
| remove | remove(o) | poll() | take() |
| examine | element() | peek() | not applicable |
1. Throws Exception:丟擲異常。如果不能馬上進行,則丟擲異常。
2. Special Value:如果不能馬上進行,則返回特殊值,一般是True或False
3. Blocks:如果不能馬上進行,則操作會被阻塞,直到這個操作成功
4. Times Out:如果不能馬上進行,操作會被阻塞指定的時間。如果指定時間還未執行,則返回特殊值,一般是True或False。
對於BlockingQueue,關注點應該在它的put和take方法上,因為這兩個方法是帶阻塞的。
BlockingQueue 不接受 null 值的插入,相應的方法在碰到null 的插入時會丟擲 NullPointerException 異常。null 值在這裡通常用於作為特殊值返回(表格中的第三列),代表 poll 失敗。所以,如果允許插入 null 值的話,那獲取的時候,就不能很好地用 null 來判斷到底是代表失敗,還是獲取的值就是 null 值。
前面說了,它實現了 java.util.Collection 介面。例如,我們可以用 remove(x) 來刪除任意一個元素,但是,這類操作通常並不高效,所以儘量只在少數的場合使用,比如一條訊息已經入隊,但是需要做取消操作的時候。
BlockingQueue 的實現都是執行緒安全的,但是批量的集合操作如 addAll, containsAll, retainAll 和 removeAll 不一定是原子操作。如 addAll(c) 有可能在添加了一些元素後中途丟擲異常,此時 BlockingQueue 中已經添加了部分元素,這個是允許的,取決於具體的實現。
BlockingQueue 在生產者-消費者的場景中,是支援多消費者和多生產者的,說的其實就是執行緒安全問題。BlockingQueue 是一個比較簡單的執行緒安全容器。作為BlockingQueue的使用者,我們再也不需要關心什麼時候需要阻塞執行緒,什麼時候需要喚醒執行緒,因為這一切BlockingQueue都給你一手包辦了。
這裡補充一點,一般所說的無界佇列,並不是大小不限制的,只是它的大小是Integer.MAX_VALUE,即int型別能夠表示的最大值,也可以理解為大小是(2的31次方)-1
BlockingQueue家庭中實現類主要有以下幾個,常用的是ArrayBlockingQueue與LinkedBlockingQueue,下文將會對這兩個類作詳細介紹。其他成員將簡單介紹。
* ArrayBlockingQueue
* LinkedBlockingQueue
* DelayQueue:
* PriorityBlockingQueue
* SynchronousQueue
ArrayBlockingQueue
Introdution
有界的阻塞佇列,內部實現是一個數組,有邊界的意思是:容量是有限的,必須初始化時,指定它的容量大小,以先進先出的方式儲存資料,最新插入的物件在尾部,最先移除的物件在頭部。
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/** 佇列元素 */
final Object[] items;
/** 下一次讀取操作的位置, poll, peek or remove */
int takeIndex;
/** 下一次寫入操作的位置, offer, or add */
int putIndex;
/** 元素數量 */
int count;
/*
* Concurrency control uses the classic two-condition algorithm
* found in any textbook.
* 它採用一個 ReentrantLock 和相應的兩個 Condition 來實現。
*/
/** Main lock guarding all access */
final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
/** 指定大小 */
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
/**
* 指定容量大小與指定訪問策略
* @param fair 指定獨佔鎖是公平鎖還是非公平鎖。非公平鎖的吞吐量比較高,公平鎖可以保證每次都是等待最久的執行緒獲取到鎖;
*/
public ArrayBlockingQueue(int capacity, boolean fair) {}
/**
* 指定容量大小、指定訪問策略與最初包含給定集合中的元素
* @param c 將此集合中的元素在構造方法期間就先新增到佇列中
*/
public ArrayBlockingQueue(int capacity, boolean fair,
Collection<? extends E> c) {}
}從上面的類結構,可以知道:
1. ArrayBlockingQueue 在生產者放入資料和消費者獲取資料,都是共用同一個鎖物件,由此也意味著兩者無法真正並行執行。按照實現原理來分析,ArrayBlockingQueue完全可以採用分離鎖,從而實現生產者和消費者操作的完全並行執行。Doug Lea之所以沒這樣去做,也許是因為ArrayBlockingQueue的資料寫入和獲取操作已經足夠輕巧,以至於引入獨立的鎖機制,除了給程式碼帶來額外的複雜性外,其在效能上完全佔不到任何便宜。
2. 通過建構函式得知,引數fair控制物件的內部鎖是否採用公平鎖,預設採用非公平鎖。
3. items、takeIndex、putIndex、count等屬性並沒有使用volatile修飾,這是因為訪問這些變數(通過方法獲取)使用都是在鎖塊內,並不存在可見性問題,如size()
4. 另外有個獨佔鎖lock用來對出入隊操作加鎖,這導致同時只有一個執行緒可以訪問入隊出隊。
Put()
我們通過原始碼,分析一下Put方法的實現:
/** 進行入隊操作 */
public void put(E e) throws InterruptedException {
//e為null,則丟擲NullPointerException異常
checkNotNull(e);
//獲取獨佔鎖
final ReentrantLock lock = this.lock;
/**
* lockInterruptibly()
* 獲取鎖定,除非當前執行緒為interrupted
* 如果鎖沒有被另一個執行緒佔用並且立即返回,則將鎖定計數設定為1。
* 如果當前執行緒已經儲存此鎖,則保持計數將遞增1,該方法立即返回。
* 如果鎖被另一個執行緒保持,則當前執行緒將被禁用以進行執行緒排程,並且處於休眠狀態
*
*/
lock.lockInterruptibly();
try {
//空佇列
while (count == items.length)
//進行條件等待處理
notFull.await();
//入隊操作
enqueue(e);
} finally {
//釋放鎖
lock.unlock();
}
}
/** 真正的入隊 */
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
//獲取當前元素
final Object[] items = this.items;
//按下一個插入索引進行元素新增
items[putIndex] = x;
// 計算下一個元素應該存放的下標,可以理解為迴圈佇列
if (++putIndex == items.length)
putIndex = 0;
count++;
//喚起消費者
notEmpty.signal();
}這裡由在操作共享變數前加了鎖,所以不存在記憶體不可見問題,加過鎖後獲取的共享變數都是從主記憶體獲取的,而不是在CPU快取或者暫存器裡面的值,釋放鎖後修改的共享變數值會重新整理會主記憶體中。
另外這個佇列是使用迴圈陣列實現,所以計算下一個元素存放下標時候有些特殊。另外insert後呼叫 notEmpty.signal();是為了啟用呼叫notEmpty.await();阻塞後放入notEmpty條件佇列中的執行緒。
Take()
我們通過原始碼,分析一下take方法的實現:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
//這裡有些特殊
if (itrs != null)
//保持佇列中的元素和迭代器的元素一致
itrs.elementDequeued();
notFull.signal();
return x;
} 從上面分析可以知道,其實Put操作與Take操作很相似。但是有一點我在上面程式碼中標識了,繼續深入瞭解:
//該類的迭代器,所有的迭代器共享資料,佇列改變會影響所有的迭代器
transient Itrs itrs = null; //其存放了目前所建立的所有迭代器。
/**
* 迭代器和它們的佇列之間的共享資料,允許佇列元素被刪除時更新迭代器的修改。
*/
class Itrs {
void elementDequeued() {
// assert lock.getHoldCount() == 1;
if (count == 0)
//佇列中數量為0的時候,佇列就是空的,會將所有迭代器進行清理並移除
queueIsEmpty();
//takeIndex的下標是0,意味著佇列從尾中取完了,又回到頭部獲取
else if (takeIndex == 0)
takeIndexWrapped();
}
/**
* 當佇列為空的時候做的事情
* 1. 通知所有迭代器佇列已經為空
* 2. 清空所有的弱引用,並且將迭代器置空
*/
void queueIsEmpty() {}
/**
* 將takeIndex包裝成0
* 並且通知所有的迭代器,並且刪除已經過期的任何物件(個人理解是置空物件)
* 也直接的說就是在Blocking佇列進行出隊的時候,進行迭代器中的資料同步,保持佇列中的元素和迭代器的元素是一致的。
*/
void takeIndexWrapped() {}
}分析到這裡,就有個疑問了,這個迭代器到底是什麼時候生成的呢?而且他在出隊時,是判斷了迭代器不為空的時候才進行操作,而肯定會存在一種情況,那就是迭代器是空的,並未建立,則不進行操作。
通過在原始碼奔走,我找到了相關內容,如下,還是在我們的ArrayBlockingQueue的原始碼中:
//從這裡知道,在ArrayBlockingQueue物件中呼叫此方法,才會生成這個物件
//那麼就可以理解為,只要並未呼叫此方法,則ArrayBlockingQueue物件中的Itrs物件則為空
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
Itr() {
//這裡就是生產它的地方
//count等於0的時候,建立的這個迭代器是個無用的迭代器,可以直接移除,進入detach模式。
//否則就把當前佇列的讀取位置給迭代器當做下一個元素,cursor儲存下個元素的位置。
if (count == 0) {
// assert itrs == null;
cursor = NONE;
nextIndex = NONE;
prevTakeIndex = DETACHED;
} else {
final int takeIndex = ArrayBlockingQueue.this.takeIndex;
prevTakeIndex = takeIndex;
nextItem = itemAt(nextIndex = takeIndex);
cursor = incCursor(takeIndex);
if (itrs == null) {
itrs = new Itrs(this);
} else {
itrs.register(this); // in this order
itrs.doSomeSweeping(false);
}
prevCycles = itrs.cycles;
// assert takeIndex >= 0;
// assert prevTakeIndex == takeIndex;
// assert nextIndex >= 0;
// assert nextItem != null;
}
}
}LinkedBlockingQueue
Introduction
基於連結串列的阻塞佇列,同ArrayListBlockingQueue類似,其內部也維持著一個數據緩衝佇列(該佇列由一個連結串列構成),當生產者往佇列中放入一個數據時,佇列會從生產者手中獲取資料,並快取在佇列內部,而生產者立即返回;只有當佇列緩衝區達到最大值快取容量時(LinkedBlockingQueue可以通過建構函式指定該值),才會阻塞生產者佇列,直到消費者從佇列中消費掉一份資料,生產者執行緒會被喚醒,反之對於消費者這端的處理也基於同樣的原理。
LinkedBlockingQueue之所以能夠高效的處理併發資料,還因為其對於生產者端和消費者端分別採用了獨立的鎖來控制資料同步,這也意味著在高併發的情況下生產者和消費者可以並行地操作佇列中的資料,以此來提高整個佇列的併發效能。
作為開發者,我們需要注意的是,如果構造一個LinkedBlockingQueue物件,而沒有指定其容量大小,LinkedBlockingQueue會預設一個類似無限大小的容量(Integer.MAX_VALUE),這樣的話,如果生產者的速度一旦大於消費者的速度,也許還沒有等到佇列滿阻塞產生,系統記憶體就有可能已被消耗殆盡了。
LinkedBlockingQueue是一個使用連結串列完成佇列操作的阻塞佇列。連結串列是單向連結串列,而不是雙向連結串列。
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
//佇列的容量,指定大小或為預設值Integer.MAX_VALUE
private final int capacity;
//元素的數量
private final AtomicInteger count = new AtomicInteger();
//佇列頭節點,始終滿足head.item==null
transient Node<E> head;
//佇列的尾節點,始終滿足last.next==null
private transient Node<E> last;
/** Lock held by take, poll, etc */
//出隊的鎖:take, poll, peek 等讀操作的方法需要獲取到這個鎖
private final ReentrantLock takeLock = new ReentrantLock();
/** Wait queue for waiting takes */
//當佇列為空時,儲存執行出隊的執行緒:如果讀操作的時候佇列是空的,那麼等待 notEmpty 條件
private final Condition notEmpty = takeLock.newCondition();
/** Lock held by put, offer, etc */
//入隊的鎖:put, offer 等寫操作的方法需要獲取到這個鎖
private final ReentrantLock putLock = new ReentrantLock();
/** Wait queue for waiting puts */
//當佇列滿時,儲存執行入隊的執行緒:如果寫操作的時候佇列是滿的,那麼等待 notFull 條件
private final Condition notFull = putLock.newCondition();
//傳說中的無界佇列
public LinkedBlockingQueue() {}
//傳說中的有界佇列
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
//傳說中的無界佇列
public LinkedBlockingQueue(Collection<? extends E> c){}
/**
* 連結串列節點類
*/
static class Node<E> {
E item;
/**
* One of:
* - 真正的繼任者節點
* - 這個節點,意味著繼任者是head.next
* - 空,意味著沒有後繼者(這是最後一個節點)
*/
Node<E> next;
Node(E x) { item = x; }
}
}通過其建構函式,得知其可以當做無界佇列也可以當做有界佇列來使用。
這裡用了兩把鎖分別是takeLock與putLock、兩個Condition分別是notEmpty與notFull,它們是這樣搭配的:
* 如果要獲取(take)一個元素,需要獲取 takeLock 鎖,但是獲取了鎖還不夠,如果佇列此時為空,還需要佇列不為空(notEmpty)這個條件(Condition)。
* 如果要插入(put)一個元素,需要獲取 putLock 鎖,但是獲取了鎖還不夠,如果佇列此時已滿,還需要佇列不是滿的(notFull)這個條件(Condition)。
注意:從上面的建構函式中,這裡會初始化一個空的頭結點,那麼第一個元素入隊的時候,佇列中就會有兩個元素。讀取元素時,也總是獲取頭節點後面的一個節點。count 的計數值不包括這個頭節點。
Put()
通過原始碼分析,透析put()方法的流程
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/**
* 將指定元素插入到此佇列的尾部,如有必要,則等待空間變得可用。
*/
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
// 如果你糾結這裡為什麼是 -1,可以看看 offer 方法。這就是個標識成功、失敗的標誌而已。
int c = -1;
//包裝成node節點
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
//獲取鎖定
putLock.lockInterruptibly();
try {
/** 如果佇列滿,等待 notFull 的條件滿足。 */
while (count.get() == capacity) {
notFull.await();
}
//入隊
enqueue(node);
//原子性自增
c = count.getAndIncrement();
// 如果這個元素入隊後,還有至少一個槽可以使用,呼叫 notFull.signal() 喚醒等待執行緒。
// 哪些執行緒會等待在 notFull 這個 Condition 上呢?
if (c + 1 < capacity)
notFull.signal();
} finally {
//解鎖
putLock.unlock();
}
// 如果 c == 0,那麼代表隊列在這個元素入隊前是空的(不包括head空節點),
// 那麼所有的讀執行緒都在等待 notEmpty 這個條件,等待喚醒,這裡做一次喚醒操作
if (c == 0)
signalNotEmpty();
}
/** 連結節點在佇列末尾 */
private void enqueue(Node<E> node) {
// assert putLock.isHeldByCurrentThread();
// assert last.next == null;
// 入隊的程式碼非常簡單,就是將 last 屬性指向這個新元素,並且讓原隊尾的 next 指向這個元素
//last.next = node;
//last = node;
// 這裡入隊沒有併發問題,因為只有獲取到 putLock 獨佔鎖以後,才可以進行此操作
last = last.next = node;
}
/**
* 等待PUT訊號
* 僅在 take/poll 中呼叫
* 也就是說:元素入隊後,如果需要,則會呼叫這個方法喚醒讀執行緒來讀
*/
private void signalNotFull() {
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
notFull.signal();//喚醒
} finally {
putLock.unlock();
}
}
}Take
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
//首先,需要獲取到 takeLock 才能進行出隊操作
takeLock.lockInterruptibly();
try {
// 如果佇列為空,等待 notEmpty 這個條件滿足再繼續執行
while (count.get() == 0) {
notEmpty.await();
}
//// 出隊
x = dequeue();
//count 進行原子減 1
c = count.getAndDecrement();
// 如果這次出隊後,佇列中至少還有一個元素,那麼呼叫 notEmpty.signal() 喚醒其他的讀執行緒
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
/**
* 出隊
*/
private E dequeue() {
// assert takeLock.isHeldByCurrentThread();
// assert head.item == null;
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC
head = first;
E x = first.item;
first.item = null;
return x;
}
/**
* Signals a waiting put. Called only from take/poll.
*/
private void signalNotFull() {
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
notFull.signal();
} finally {
putLock.unlock();
}
}
}與 ArrayBlockingQueue 對比
ArrayBlockingQueue是共享鎖,粒度大,入隊與出隊的時候只能有1個被執行,不允許並行執行。LinkedBlockingQueue是獨佔鎖,入隊與出隊是可以並行進行的。當然這裡說的是讀和寫進行並行,兩者的讀讀與寫寫是不能並行的。總結就是LinkedBlockingQueue可以併發讀寫。ArrayBlockingQueue和LinkedBlockingQueue間還有一個明顯的不同之處在於,前者在插入或刪除元素時不會產生或銷燬任何額外的物件例項,而後者則會生成一個額外的Node物件。這在長時間內需要高效併發地處理大批量資料的系統中,其對於GC的影響還是存在一定的區別。
DelayQueue
DelayQueue是一個無界阻塞佇列,只有在延遲期滿時才能從中提取元素。該佇列的頭部是延遲期滿後儲存時間最長的Delayed元素。
存放到DelayDeque的元素必須繼承Delayed介面。Delayed介面使物件成為延遲物件,它使存放在DelayQueue類中的物件具有了啟用日期,該介面強制執行下列兩個方法:
1. CompareTo(Delayed o):Delayed介面繼承了Comparable介面,因此有了這個方法
2. getDelay(TimeUnit unit):這個方法返回到啟用日期的剩餘時間,時間單位由單位引數指定
使用場景
1. 關閉空閒連線。伺服器中,有很多客戶端的連線,空閒一段時間之後需要關閉之。
2. 快取。快取中的物件,超過了空閒時間,需要從快取中移出。
3. 任務超時處理。在網路協議滑動視窗請求應答式互動時,處理超時未響應的請求。
PriorityBlockingQueue
SynchronousQueue
它是一個特殊的佇列,它的名字其實就蘊含了它的特徵 – - 同步的佇列。為什麼說是同步的呢?這裡說的並不是多執行緒的併發問題,而是因為當一個執行緒往佇列中寫入一個元素時,寫入操作不會立即返回,需要等待另一個執行緒來將這個元素拿走;同理,當一個讀執行緒做讀操作的時候,同樣需要一個相匹配的寫執行緒的寫操作。這裡的 Synchronous 指的就是讀執行緒和寫執行緒需要同步,一個讀執行緒匹配一個寫執行緒,同理一個寫執行緒匹配一個讀執行緒。
不像ArrayBlockingQueue、LinkedBlockingDeque之類的阻塞佇列依賴AQS實現併發操作,SynchronousQueue直接使用CAS實現執行緒的安全訪問。
較少使用到 SynchronousQueue 這個類,不過它線上程池的實現類 ScheduledThreadPoolExecutor 中得到了應用。
public class SynchronousQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
//內部棧
static final class TransferStack<E> extends Transferer<E> {}
//內部佇列
static final class TransferQueue<E> extends Transferer<E> {}
public SynchronousQueue() {this(false);}
public SynchronousQueue(boolean fair) {
transferer = fair ?
new TransferQueue<E>() : new TransferStack<E>();
}
}