
Spark Join處理流程分析
為了更好的分析Spark Join處理流程,我們選擇具有Shuffle操作的示例來進行說明,這比沒有Shuffle操作的處理流程要複雜一些。本文主要通過實現一個Join操作的Spark程式,提交執行該程式,並通過Spark UI上的各種執行資訊來討論Spark Join處理流程。
Spark Join示例程式
我們先給出一個簡單的Spark Application程式程式碼,這裡處理的資料使用了MovieLens資料集。其中,小表movies(約1.4m)、大表genome-scores(約323.5m),對這兩個表進行Join操作。具體的實現程式碼,如下所示:
def main 上面程式碼,我們直接將兩個表進行Join操作(實際更優的做法是:將小表進行Broadcast後,再進行連線操作,能夠避免昂貴低效的Shuffle操作)。我們這麼做,主要是為了使程式處理過程中能夠進行Shuffle操作,從而更深入地理解Join操作的內部處理流程。
我們通過如下命令,檢視一下輸入資料表genome-scores表在HDFS上儲存的Block情況,執行如下命令:
hdfs fsck /data/ml-20m/movies.csv -files -racks -locations -blocks
hdfs fsck /data/ml-20m/genome-scores.csv -files -racks -locations -blocks
可以看到輸入資料集的儲存情況,如下所示:
/data/ml-20m/movies.csv 1397542 bytes, 1 block(s): OK
0. BP-893796349-172.16.117.62-1504161181581:blk_1074121675_380924 len=1397542 Live_repl=3 [/default/172.16.117.64:50010, /default/172.16.117.63:50010, /default/172.16.117.65:50010]
/data/ml-20m/genome-scores.csv 323544381 bytes, 3 block(s): OK
0. BP-893796349-172.16.117.62-1504161181581:blk_1074121670_380919 len=134217728 Live_repl=3 [/default/172.16.117.63:50010, /default/172.16.117.65:50010, /default/172.16.117.64:50010]
1. BP-893796349-172.16.117.62-1504161181581:blk_1074121671_380920 len=134217728 Live_repl=3 [/default/172.16.117.65:50010, /default/172.16.117.64:50010, /default/172.16.117.63:50010]
2. BP-893796349-172.16.117.62-1504161181581:blk_1074121672_380921 len=55108925 Live_repl=3 [/default/172.16.117.64:50010, /default/172.16.117.65:50010, /default/172.16.117.63:50010]
通過RDD的toDebugString()方法,列印除錯資訊:
res1: String =
(3) MapPartitionsRDD[40] at map at <console>:38 []
| MapPartitionsRDD[39] at join at <console>:38 []
| MapPartitionsRDD[38] at join at <console>:38 []
| CoGroupedRDD[37] at join at <console>:38 []
+-(2) MapPartitionsRDD[31] at map at <console>:34 []
| | MapPartitionsRDD[30] at map at <console>:34 []
| | MapPartitionsRDD[29] at filter at <console>:34 []
| | /data/ml-20m/movies.csv MapPartitionsRDD[28] at textFile at <console>:34 []
| | /data/ml-20m/movies.csv HadoopRDD[14] at textFile at <console>:34 []
+-(3) MapPartitionsRDD[27] at map at <console>:36 []
| | MapPartitionsRDD[26] at map at <console>:36 []
| | MapPartitionsRDD[25] at filter at <console>:36 []
| | /data/ml-20m/genome-scores.csv MapPartitionsRDD[24] at textFile at <console>:36 []
| | /data/ml-20m/genome-scores.csv HadoopRDD[13] at textFile at <console>:36 []
上面資訊可以非常清晰地看到,我們的Spark程式都建立了哪些RDD,以及這些RDD之間的大致順序關係。
分析Spark Join處理流程
Spark程式執行過程中,我們可以通過Web UI看到對應的DAG生成的Stage的情況,一共生成了3個Stage。為了更加清晰地瞭解各個Stage(對應的各組Task)都被排程到了哪個Executor上執行,我們通過Spark UI看一下對於該Spark程式建立Executor的具體情況,如下圖所示:
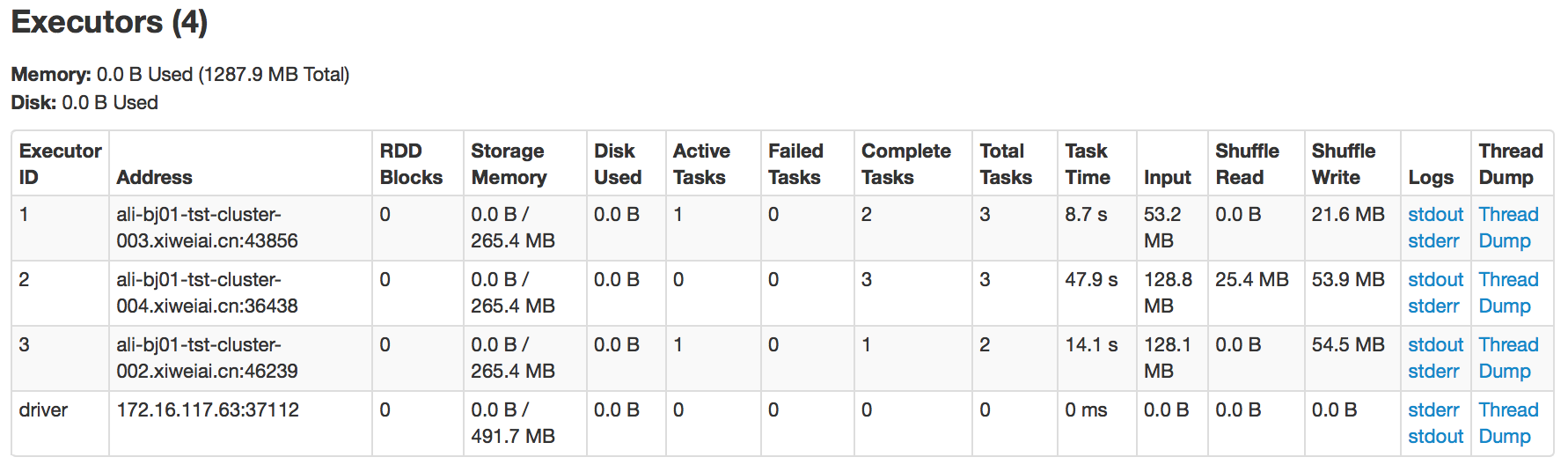
通過上圖可見,為了執行我們提交的Spark程式,在Spark叢集中的3個節點上,總計啟動了3個Executor和1個Driver。其中,圖中ID為3和driver的Executor是在同一個物理節點上。我們知道,在同一個Spark程式執行過程中,可能會複用已經啟動的Executor,這裡的3個Executor在程式執行過程中都會被複用,可以在後面各個Stage執行過程中看到。
下面,分別對各個Stage的執行情況進行分析:
- Stage 0執行過程
對資料表/data/ml-20m/movies.csv,進行filter->map->map操作,對應於Stage 0,如下圖所示:
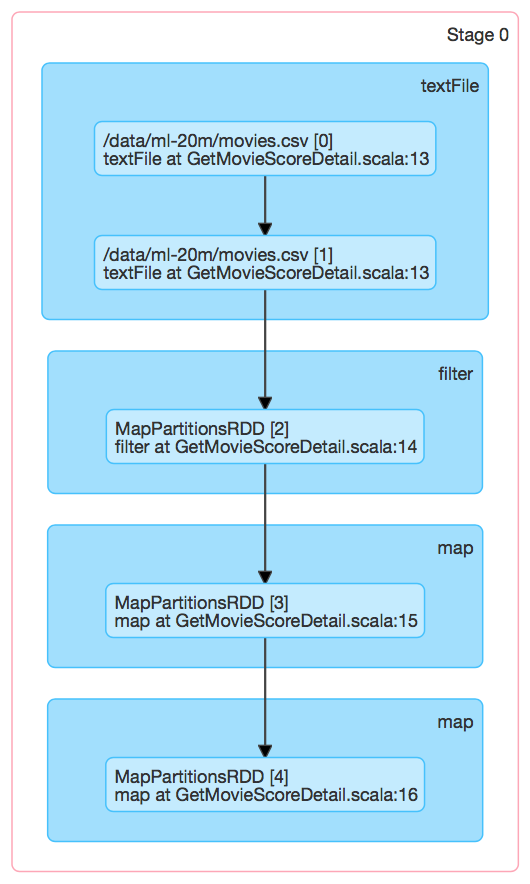
經過前面我們通過toDebugString()打印出DAG關係圖,可以知道/data/ml-20m/movies.csv具有兩個Partition,所以對應的Stage 0包含2個可排程執行的ShuffleMapTask。通過Spark Web UI可以看到,如下圖所示:

上圖中,Locality Level為NODE_LOCAL,在2個節點上各啟動了1個Executor,Stage 0包含2個ShuffleMapTask。
- Stage 1執行過程
同樣,對資料表/data/ml-20m/genome-scores.csv也進行filter->map->map操作,對應於Stage 1,如下圖所示:
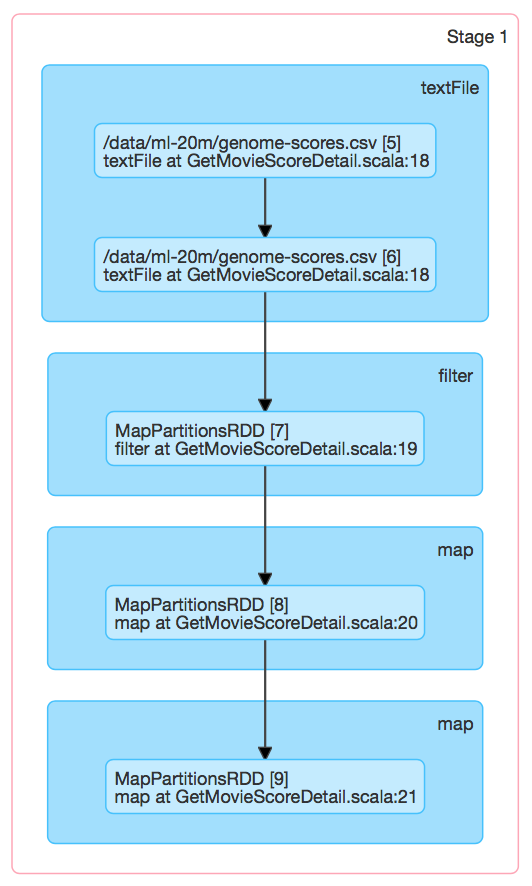
/data/ml-20m/genome-scores.csv具有3個Partition,所以同樣對於Stage 1具有3個可排程執行的ShuffleMapTask,如下圖所示:

可見,在3個節點上各啟動了1個Executor,用來執行Stage 1的ShuffleMapTask。其中,Locality Level也為NODE_LOCAL。
- Stage 2執行過程
該Stage對應的DAG圖表達,如下圖所示:
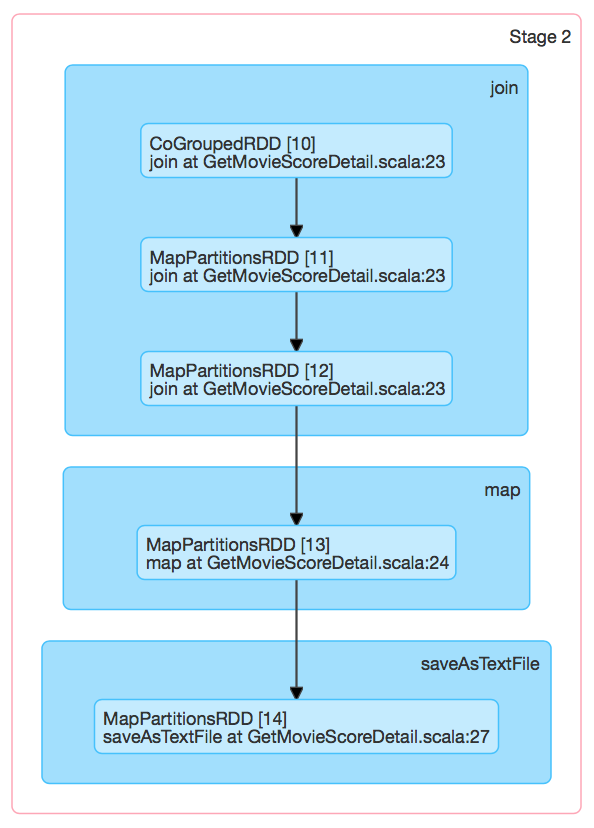
可見,Join操作實際包含了一組操作的集合:cogroup、map、map。這裡,我們通過Spark原始碼來看一下,呼叫join操作,其內部具體都做了哪些事情,我們實現的Spark程式中呼叫了帶有一個RDD引數的join方法,程式碼如下所示:
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))] = self.withScope {
join(other, defaultPartitioner(self, other))
}
繼續呼叫了另一個多了Partitioner引數的join方法,程式碼如下所示:
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] = self.withScope {
this.cogroup(other, partitioner).flatMapValues( pair =>
for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w)
)
}
上面程式碼中,呼叫了最核心的cogroup方法,如下所示:
def cogroup[W](other: RDD[(K, W)], partitioner: Partitioner)
: RDD[(K, (Iterable[V], Iterable[W]))] = self.withScope {
if (partitioner.isInstanceOf[HashPartitioner] && keyClass.isArray) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
val cg = new CoGroupedRDD[K](Seq(self, other), partitioner)
cg.mapValues { case Array(vs, w1s) =>
(vs.asInstanceOf[Iterable[V]], w1s.asInstanceOf[Iterable[W]])
}
}
這裡面建立了CoGroupedRDD,所以可以直接分析CoGroupedRDD的實現。根據前面我們實現的Spark程式,應該存在Shuffle過程,所以CoGroupedRDD與Stage 0和Stage 1中的兩個RDD之間,必然應該存在ShuffledDependency依賴關係,通過CoGroupedRDD類的程式碼驗證,如下所示:
override def getDependencies: Seq[Dependency[_]] = {
rdds.map { rdd: RDD[_] =>
if (rdd.partitioner == Some(part)) {
logDebug("Adding one-to-one dependency with " + rdd)
new OneToOneDependency(rdd)
} else {
logDebug("Adding shuffle dependency with " + rdd)
new ShuffleDependency[K, Any, CoGroupCombiner](
rdd.asInstanceOf[RDD[_ <: Product2[K, _]]], part, serializer)
}
}
}
在我們示例程式實際執行過程中,執行了建立ShuffleDependency的分支,在這裡一共生成了2個ShuffleDependency。現在,我們需要知道CoGroupedRDD是如何計算的,也就是需要知道在呼叫join操作過程中如何進行Shuffle操作的,檢視CoGroupedRDD的compute方法,基於依賴的ShuffleDependency進行計算,計算過程程式碼如下所示:
val rddIterators = new ArrayBuffer[(Iterator[Product2[K, Any]], Int)]
for ((dep, depNum) <- dependencies.zipWithIndex) dep match {
case oneToOneDependency: OneToOneDependency[Product2[K, Any]] @unchecked =>
val dependencyPartition = split.narrowDeps(depNum).get.split
// Read them from the parent
val it = oneToOneDependency.rdd.iterator(dependencyPartition, context)
rddIterators += ((it, depNum))
case shuffleDependency: ShuffleDependency[_, _, _] =>
// Read map outputs of shuffle
val it = SparkEnv.get.shuffleManager
.getReader(shuffleDependency.shuffleHandle, split.index, split.index + 1, context)
.read()
rddIterators += ((it, depNum))
}
上述的compute方法實現了對CoGroupedRDD的某一個Partition的計算處理,實際會執行ShuffleDependency這個case分支,它會通過ShuffleManager來讀取依賴的上游2個RDD的計算結果,從而得到CoGroupedRDD的某個Partition依賴於上游RDD的計算結果,通過(Iterator[Product2[K, Any]], Int)對的方式表達,表示計算CoGroupedRDD需要上游RDD結果迭代器(it)和對應的依賴編號(depNum)。
Stage 2可排程執行的是一組ResultTask,每個ResultTask處理最終結果的一個Partition,該Partition執行上述程式碼後,已經將Stage 1執行過程的計算結果(map輸出)讀取到對應的Reduce端,也就是說屬於該Partition的所有map輸出結果都已經讀取過來了。而且,我們應該知道,具有相同的key的記錄,一定會在Shuffle過程中讀取到同一個Executor中(同一個ResultTask中),可以想到下面需要進行實際的Join操作流程了,具體程式碼如下所示:
val map = createExternalMap(numRdds)
for ((it, depNum) <- rddIterators) {
map.insertAll(it.map(pair => (pair._1, new CoGroupValue(pair._2, depNum))))
}
context.taskMetrics().incMemoryBytesSpilled(map.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(map.diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(map.peakMemoryUsedBytes)
new InterruptibleIterator(context,
map.iterator.asInstanceOf[Iterator[(K, Array[Iterable[_]])]])
首先建立一個ExternalAppendOnlyMap儲存結構,然後遍歷上面得到的rddIterators,將該Partition依賴的RDD結果記錄insert到ExternalAppendOnlyMap中。ExternalAppendOnlyMap能夠對具有相同key的一組記錄執行merge操作,最終得到一個按相同key進行連線操作的結果。上面程式碼,通過建立的InterruptibleIterator就可以迭代出Join後的結果。當然,這裡Join完的結果還不是最終我們需要的結果,通過在RDD的join和cogroup方法中還需要對這裡得到的結果進行後續處理,才得到我們Spark程式最終需要的Join結果。
下面,看一下Stage 2對應的3個ResultTask的執行情況,如下圖所示:

示例圖中的Task還在執行中,執行過程中需要進行Shuffle讀取操作。
Stage 2對應DAG圖中,最後一步是saveAsTextFile,上面計算得到的結果就是Join操作的最終結果,結果由Spark程式執行過程中的各個BlockManager來管理,結果或者儲存在記憶體中,或者儲存在磁碟上,我們這個示例程式結果都存放在記憶體中,當呼叫saveAsTextFile方法時,會直接將Join結果寫入到HDFS指定檔案中。
總結
基於提供的Spark程式示例,我們從原始碼的角度,將對應的RDD及其作用於RDD之上的操作,以及對應的順序關係,通過如下RDD DAG圖來更加清晰地表現出來,如下圖所示:
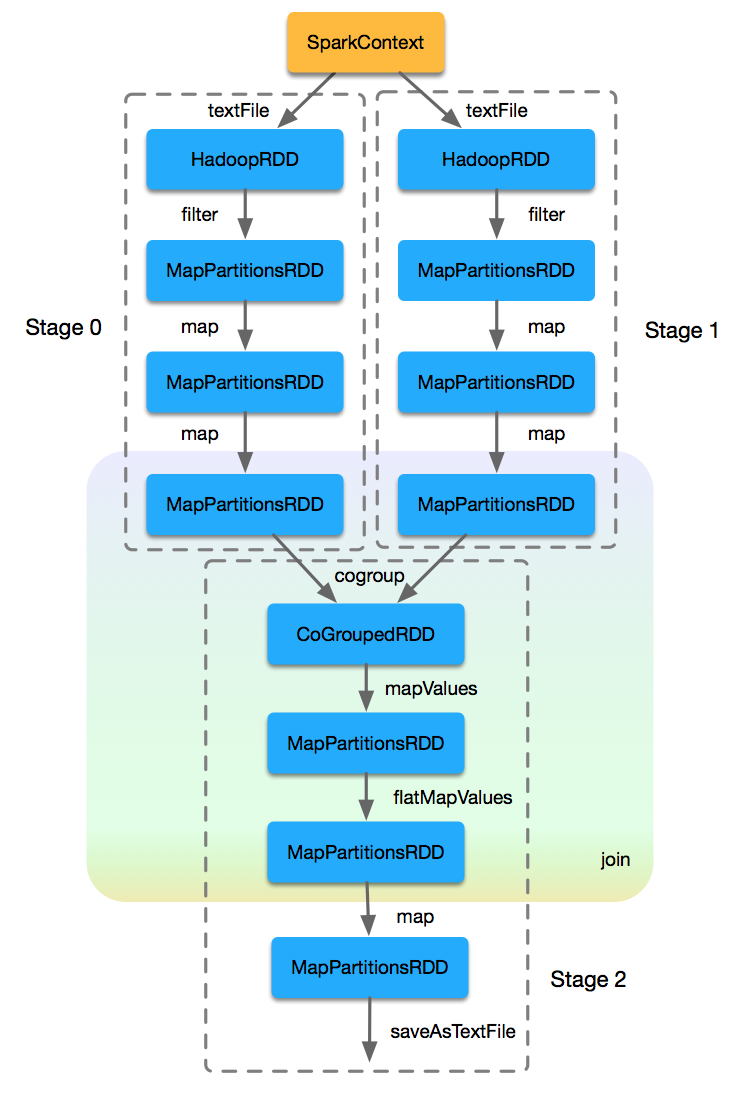
根據每個RDD對應的Partition情況,將上圖細化到Partition級別,我們能夠看出每個RDD的各個Partition之間是如何關聯的,如下圖所示:
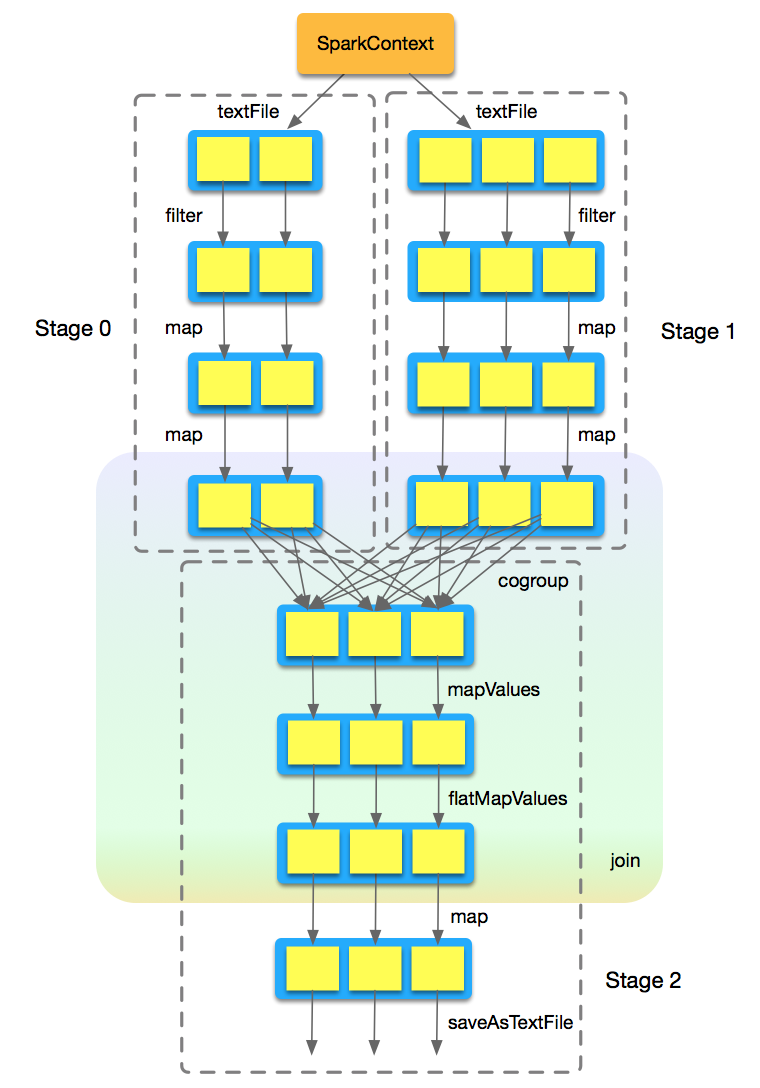
在我們示例程式的Join過程中,一定存在Shuffle處理,最終處理流程可以在上圖中各個RDD的各個Partition之間表現出來。擴充套件一點思考,假如沒有Join過程沒有發生Shuffle處理,那麼在cogroup處理中就不會建立ShuffleDependency,而是會建立對應的OneToOneDependency。那麼上圖中,處理完成Stage 0、Stage 1後得到的RDD的各個Partition,已經使用相同的Partitioner基於記錄的Key對資料進行了Partition操作。所以,在生成Stage 2中的RDD的某個Partition時,與上游Stage 0、Stage 1中每個RDD中某個(而不是某些,不是與RDD中各個Partition都有關係)Partition是一對一的關係,這一計算起來就簡單多了。