Spark修煉之道(高階篇)——Spark原始碼閱讀:第十二節 Spark SQL 處理流程分析
作者:周志湖
下面的程式碼演示了通過Case Class進行表Schema定義的例子:
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
// Define the schema using a case class.
// Note: Case classes in Scala 2.10 can support only up to 22 (1)sql方法返回DataFrame
def sql(sqlText: String): DataFrame = {
DataFrame(this, parseSql(sqlText))
}其中parseSql(sqlText)方法生成相應的LogicalPlan得到,該方法原始碼如下:
//根據傳入的sql語句,生成LogicalPlan
protected[sql] def parseSql(sql: String): LogicalPlan = ddlParser.parse(sql, false)ddlParser物件定義如下:
protected[sql] val sqlParser = new SparkSQLParser(getSQLDialect().parse(_))
protected[sql] val ddlParser = new DDLParser(sqlParser.parse(_))(2)然後呼叫DataFrame的apply方法
private[sql] object DataFrame {
def apply(sqlContext: SQLContext, logicalPlan: LogicalPlan): DataFrame = {
new DataFrame(sqlContext, logicalPlan)
}
}可以看到,apply方法引數有兩個,分別是SQLContext和LogicalPlan,呼叫的是DataFrame的構造方法,具體原始碼如下:
//DataFrame構造方法,該構造方法會自動對LogicalPlan進行分析,然後返回QueryExecution物件
def this(sqlContext: SQLContext, logicalPlan: LogicalPlan) = {
this(sqlContext, {
val qe = sqlContext.executePlan(logicalPlan)
//判斷是否已經建立,如果是則拋異常
if (sqlContext.conf.dataFrameEagerAnalysis) {
qe.assertAnalyzed() // This should force analysis and throw errors if there are any
}
qe
})
}(3)val qe = sqlContext.executePlan(logicalPlan) 返回QueryExecution, sqlContext.executePlan方法原始碼如下:
protected[sql] def executePlan(plan: LogicalPlan) =
new sparkexecution.QueryExecution(this, plan)QueryExecution類中表達了Spark執行SQL的主要工作流程,具體如下
class QueryExecution(val sqlContext: SQLContext, val logical: LogicalPlan) {
@VisibleForTesting
def assertAnalyzed(): Unit = sqlContext.analyzer.checkAnalysis(analyzed)
lazy val analyzed: LogicalPlan = sqlContext.analyzer.execute(logical)
lazy val withCachedData: LogicalPlan = {
assertAnalyzed()
sqlContext.cacheManager.useCachedData(analyzed)
}
lazy val optimizedPlan: LogicalPlan = sqlContext.optimizer.execute(withCachedData)
// TODO: Don't just pick the first one...
lazy val sparkPlan: SparkPlan = {
SparkPlan.currentContext.set(sqlContext)
sqlContext.planner.plan(optimizedPlan).next()
}
// executedPlan should not be used to initialize any SparkPlan. It should be
// only used for execution.
lazy val executedPlan: SparkPlan = sqlContext.prepareForExecution.execute(sparkPlan)
/** Internal version of the RDD. Avoids copies and has no schema */
//呼叫toRDD方法執行任務將結果轉換為RDD
lazy val toRdd: RDD[InternalRow] = executedPlan.execute()
protected def stringOrError[A](f: => A): String =
try f.toString catch { case e: Throwable => e.toString }
def simpleString: String = {
s"""== Physical Plan ==
|${stringOrError(executedPlan)}
""".stripMargin.trim
}
override def toString: String = {
def output =
analyzed.output.map(o => s"${o.name}: ${o.dataType.simpleString}").mkString(", ")
s"""== Parsed Logical Plan ==
|${stringOrError(logical)}
|== Analyzed Logical Plan ==
|${stringOrError(output)}
|${stringOrError(analyzed)}
|== Optimized Logical Plan ==
|${stringOrError(optimizedPlan)}
|== Physical Plan ==
|${stringOrError(executedPlan)}
|Code Generation: ${stringOrError(executedPlan.codegenEnabled)}
""".stripMargin.trim
}
}
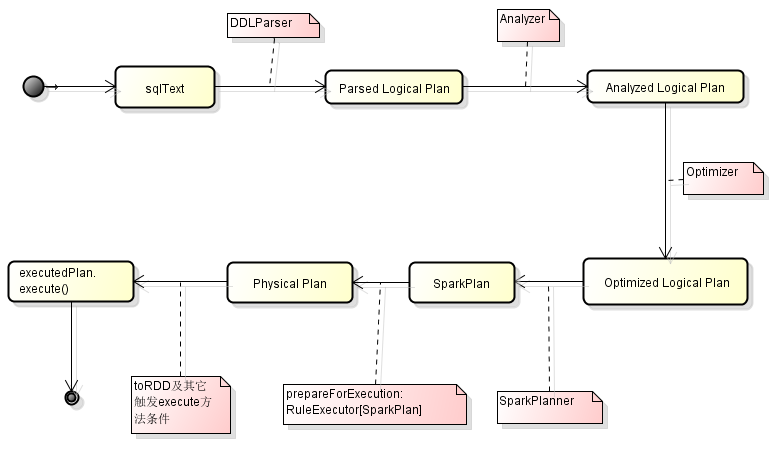
可以看到,SQL的執行流程為
1.Parsed Logical Plan:LogicalPlan
2.Analyzed Logical Plan:
lazy val analyzed: LogicalPlan = sqlContext.analyzer.execute(logical)
3.Optimized Logical Plan:lazy val optimizedPlan: LogicalPlan = sqlContext.optimizer.execute(withCachedData)
4. Physical Plan:lazy val executedPlan: SparkPlan = sqlContext.prepareForExecution.execute(sparkPlan)
可以呼叫results.queryExecution方法檢視,程式碼如下:
scala> results.queryExecution
res1: org.apache.spark.sql.SQLContext#QueryExecution =
== Parsed Logical Plan ==
'Project [unresolvedalias('name)]
'UnresolvedRelation [people], None
== Analyzed Logical Plan ==
name: string
Project [name#0]
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at createDataFrame at <console>:47
== Optimized Logical Plan ==
Project [name#0]
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at createDataFrame at <console>:47
== Physical Plan ==
TungstenProject [name#0]
Scan PhysicalRDD[name#0,age#1]
Code Generation: true
(4) 然後呼叫DataFrame的主構造器完成DataFrame的構造
class DataFrame private[sql](
@transient val sqlContext: SQLContext,
@DeveloperApi @transient val queryExecution: QueryExecution) extends Serializable (5)
當呼叫DataFrame的collect等方法時,便會觸發執行executedPlan
def collect(): Array[Row] = withNewExecutionId {
queryExecution.executedPlan.executeCollect()
}例如:
scala> results.collect
res6: Array[org.apache.spark.sql.Row] = Array([Michael], [Andy], [Justin])整體流程圖如下: