
1032 Sharing (25 分)查詢連結串列共同結點
題目
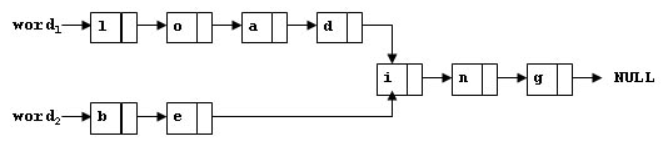
To store English words, one method is to use linked lists and store a word letter by letter. To save some space, we may let the words share the same sublist if they share the same suffix. For example, loading and being are stored as showed in Figure 1.
Figure 1
You are supposed to find the starting position of the common suffix (e.g. the position of i in Figure 1).
Input Specification:
Each input file contains one test case. For each case, the first line contains two addresses of nodes and a positive
, where the two addresses are the addresses of the first nodes of the two words, and N is the total number of nodes. The address of a node is a 5-digit positive integer, and NULL is represented by −1.
Then N lines follow, each describes a node in the format:
Address Data Next
whereAddress is the position of the node, Data is the letter contained by this node which is an English letter chosen from { a-z, A-Z }, and Next is the position of the next node.
Output Specification:
For each case, simply output the 5-digit starting position of the common suffix. If the two words have no common suffix, output -1 instead.
Sample Input 1:
11111 22222 9
67890 i 00002
00010 a 12345
00003 g -1
12345 D 67890
00002 n 00003
22222 B 23456
11111 L 00001
23456 e 67890
00001 o 00010
Sample Output 1:
67890
Sample Input 2:
00001 00002 4
00001 a 10001
10001 s -1
00002 a 10002
10002 t -1
Sample Output 2:
-1
解題思路
題目大意: 給定一堆字母,儲存在連結串列的結點中,同時給定兩個單詞的開始地址,如果兩個單詞具有相同的字尾,那麼連結串列將複用該字尾,請找出具有相同字尾的第一個結點的地址 。
解題思路: 常規的做法是把輸入的結點,按照地址進行構建單詞連結串列,然後從後往前進行比較,得到最後一個不相同的點的地址即可 。但是這種方法要考慮邊界情況,比如-1的處理,比如單詞從一開頭就是重複的等等。
但這裡可以用一種投機取巧的方法——從開始地址開始構建結點,如果結點在兩個單詞中均出現,那麼必定會被訪問兩次,那麼我們統計每個結點在構建的時候的訪問次數,第一個超過1次的結點必定為相同字尾的開始結點,這樣我們只需要從開始地址遍歷連結串列即可,時間複雜度
.
但是值得一提的是,這種做法僅適用於測試資料裡不存在2個以上的相同字尾的單詞,不然的話,會干擾到正常判斷。
/*
** @Brief:No.1032 of PAT advanced level.
** @Author:Jason.Lee
** @Date:2018-12-06
** @status: Accepted!
*/
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
struct Node{
int addr;
int next;
char key;
int times;
};
Node input[100001];
// 從index開始構建單詞連結串列
void createWordList(int index){
while(index!=-1){
input[index].times++;
index = input[index].next;
}
}
int main(){
int index1,index2,N;
while(scanf("%d%d%d",&index1,&index2,&N)!=EOF){
Node temp{-1,-1,'\0',0};
vector<Node> wordList1;
vector<Node> wordList2;
int commonNode = -1;
int index = 0;
bool always = true;
fill(input,input+100001,temp);
for(int i=0;i<N;i++){
scanf("%d %c %d",&temp.addr,&temp.key,&temp.next);
input[temp.addr] = temp;
}
if(index1!=-1&&index2!=-1){
createWordList(index1);
createWordList(index2);
index = index1;
while(index!=-1){//
if(input[index].times>1){
commonNode = input[index].addr;
break;
}
index = input[index].next;
};
}
commonNode==-1?printf("%d\n",commonNode):printf("%05d\n",commonNode);
}
return 0;
}
總結
第5個測試點輸出的應該是個小於5位整型的數,忘記了printf("%05d",commonNode)這種做法,結果一直通不過,我以為時候我這種投機取巧的做法行不通,於是又老老實實寫了一遍連結串列逆置,用的vector和reverse,結果多了一個第4個測試點超時了,不知道為啥會超時,可能是reverse的演算法或者迭代器的方式,並沒有那麼高效吧。然後改用陣列,自己寫連結串列逆置,結果還是不行,最後不得不放棄,去網上找結題報告,發現有一個童鞋跟我的思路是一樣的,為啥我不過呢?結果發現輸出出了一點bug,吐血ing……